一、带标签的数据很难获得
机器学习中,比如监督学习需要带有标签的训练样本才能得到模型,然而在以下几种场景中去获取带有标签的数据是很难的:
- 自动驾驶场景:对自动驾驶汽车收集的高清地图数据或实时摄像头数据进行标注,需要标记行人、车辆、交通标志、道路障碍物等,这是一个极度繁琐且昂贵的过程,需要专门团队花费大量时间精细检查和标记每一个像素级别的对象。
- 情感分析:对文本进行情感倾向标注(如积极、消极或中立)是一项复杂的任务,因为情感往往是微妙且主观的,而且受文化背景、语境和个人表达习惯影响很大。这导致大规模高质量的情感标注数据集构建困难。
- 医疗影像诊断:医学影像数据(如CT扫描、MRI图像)的标注通常需要医学专家的专业知识才能完成,例如识别肿瘤、病变区域等。这一过程耗时费力,且要求高度专业性和准确性,所以很难快速积累大量的带标签数据。
二、主动学习的定义
主动学习(Active Learning)是一种旨在通过最少的人工标注工作获得最优模型性能的学习策略。相比于传统的机器学习方法,主动学习不是简单地使用预先标记好的大型数据集进行训练,而是让算法本身参与到数据选择的过程中来,优先选择最有价值样本标注标签。
说人话:“主动学习是一个帮我将无标签数据标注上标签的模型,还没完!重点在于它可以选择对学习最为有价值的未标注数据。”
主动学习中有一些特有的用词,在这里用一个表格来解释说明一下:
| 术语 | 解释 |
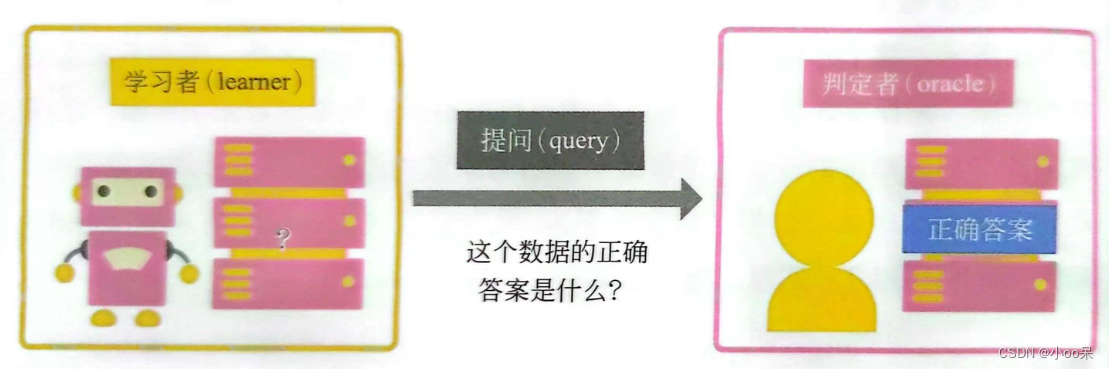
| 学习者 (Learner) | 主动学习模型,负责训练和根据策略选择需要标注的样本。 |
| 判定者 (Oracle) | 能够提供准确标签信息的权威来源,可以是人类专家或自动化系统。 |
| 提问 (Querying) | 学习者根据策略选择样本并请求判定者为其标注的过程。 |
| 未标注数据池 (Unlabeled Pool) | 存储待筛选和可能被选中进行标注的大量数据集合。 |
| 已标注数据集 (Labeled Dataset) | 存储已经被判定者正确标注过的数据,用于模型训练。 |
| 查询策略 (Query Strategy) | 决定从未标注数据池中选取哪些样本进行提问的具体方法。 |
三、主动学习的过程
主动学习的过程通常可以分为以下几个步骤:
- 初始化:首先,从大量未标记的数据中随机选择一小部分来进行手动标记。
- 训练:然后,使用这些标记的数据来训练模型。
- 选择:模型对剩下的未标记的数据进行预测并为其打分,通常这个分数反映了模型对该样本的不确定性或者信息量。然后选择分数最高的一部分样本,也就是模型最需要学习的样本。
- 查询:将这些被选中的样本提交给专家进行标记。
- 更新:将新标记的样本加入到训练集中,并使用更新后的训练集来重新训练模型。
- 循环迭代:重复第3步到第5步,直到达到预设的条件,例如循环次数、模型性能或者标注预算。
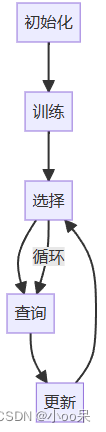
主动学习的核心就是在第3步,如何选择最需要学习的样本,不同的主动学习算法会有不同的选择策略。
四、常见的样本选择策略
如上所说,如何去选择一个最需要学习的样本,给它打上标签非常关键。这里只详细介绍一个策略。
(1)最低置信度策略的思想
最低置信度(Least Confidence)是一种常见的样本选择策略,用于确定下一步应该优先标注哪些未标注样本。这种策略假设模型对某个样本的预测越不确定,那么这个样本就可能越重要,因为它有可能提供更多的信息帮助模型改进。
具体来说,对于一个多分类问题,最低置信度策略计算每个未标注样本属于任一类别预测的概率,并选择其中模型预测信心最小的样本作为下一个请求标注的对象。计算方式通常是找到模型输出的概率向量中最大概率值对应的索引,然后取1减去这个最大概率值,得到的就是模型对该样本预测的不确信度。
(2)手写字体识别举例
假设模型正在对数字手写体识别任务进行训练,对于一个未标注的手写数字图片,模型可能输出 [0.1, 0.2, 0.3, 0.15, 0.25] 这样的概率分布,表示模型认为该图片分别是0, 1, 2, 3, 4的概率。此时,模型对这个样本预测的最大概率为0.3(属于类别2的概率),那么不确信度为1 - 0.3 = 0.7。若这是所有样本中最大的不确信度,则该样本会被选作下一个请求专家标注的样本。
通过这种方式,最低置信度策略可以优先挑选那些模型最难确定类别的样本,从而期望通过获取它们的真实标签来最大程度地提升模型性能。
——逻辑回归)


项目方舟框架(ArkUI)之Web组件)

)
)


)
)








及其影响。描述Python中的垃圾回收机制。Python中的类变量和实例变量有什么区别)