【CV论文精读】EarlyBird: Early-Fusion for Multi-View Tracking in the Bird’s Eye View
0.论文摘要
多视图聚合有望克服多目标检测和跟踪中的遮挡和漏检挑战。多视图检测和3D对象检测中的最新方法通过将所有视图投影到地平面并在鸟瞰视图(BEV)中执行检测,实现了巨大的性能飞跃。在本文中,我们研究了BEV中的跟踪是否也能带来多目标多摄像机(MTMC)跟踪的下一个性能突破。多视图跟踪中的大多数当前方法在每个视图中执行检测和跟踪任务,并使用基于图的方法来执行跨每个视图的行人关联。这种空间关联已经通过在BEV中检测每个行人一次来解决,只留下时间关联的问题。对于时间关联,我们展示了如何为每个检测学习强再识别(re-ID)特征。结果表明,BEV中的早期融合实现了较高的检测和跟踪精度。EarlyBird优于最先进的方法,并在Wildtrack上将当前最先进的方法提高了+4.6 MOTA和+5.6 IDF1
1.研究背景
行人的检测和跟踪已经成为视频监控、自动驾驶汽车和体育分析中众多应用的基本问题。尽管单目多目标跟踪(MOT)取得了一些进展,但遮挡仍然是该研究领域面临的最大挑战之一。遮挡会导致检测丢失和轨迹碎片化,从而限制检测和跟踪质量。然而,像体育分析这样的实际情况需要在高度混乱或拥挤的场景中进行检测。对于这些情况,具有重叠视野的多个摄像机可能可用。从多个视图观察场景有助于克服这些遮挡,因为隐藏在一个相机中的对象在另一个相机中可以看到。接下来的挑战是从多个相机视图中聚合信息。
在早期的方法中,多视图检测是用晚期的融合方法解决的[44]:首先,在单个视图中检测行人,然后将该检测投影到3D空间或主要是地平面,在那里它与其他视图的投影相关联。最近的方法[21,22]利用早期融合策略,首先将所有视图的表示投影到公共地平面或鸟瞰视图,然后执行检测。与以前的后期融合方法相比,这些早期融合探测器[21,22]显著提高了检测质量。
后期融合方法通常具有这样的优点,即它们需要较少的硬件,因为处理可以独立执行,并且投影到3D的信息比完整图像更稀疏。早期融合方法具有可以端到端训练的优点,而后期融合通常分别优化检测和多视图关联。鸟瞰(BEV)空间中检测的一个挑战是透视变换产生的失真。几种方法[21,27,39]试图克服这个问题。
我们把我们的方法建立在[22]上,但是添加基于ResNet-18的BEV解码器,并为解码的特征提供更大的感受野,允许模型将信息从失真阴影聚合到实际位置。我们主要关注跟踪任务,但我们的模型在检测任务中也取得了有竞争力的结果。
虽然早期融合已被证明是更强的检测方法,但多视图中的跟踪仍然使用后期融合方法进行[8,20]:获得第一个2D检测。其次,关联每个时间步长的检测,最后,跨时间步长关联检测。其他方法[18,29]在一个视图中切换顺序和第一个关联,然后跨视图匹配这些轨迹。不管排序如何,该跟踪流水线中的任何阶段都会遭受由前一阶段引入的不准确性,即,稍后需要在关联阶段补偿错过的2D检测。我们的方法结合了前两个步骤,并在最新的多视图检测器上直接在BEV架构中执行检测[21]。
对于跟踪,我们采用FairMOT[46]引入的思想,同时为BEV空间中的每个检测学习重新识别(re-ID)特征。这种方法允许我们跳过空间关联的第一步,因为我们学习的检测器已经解决了这个问题。时间域中的关联首先用基于外观的重新识别特征来执行,其次用卡尔曼滤波器[24]作为基于运动的模型来执行。我们称这种架构为EarlyBird。这是一个在线、端到端、可训练的跟踪架构,大大提高了跟踪技术的水平。
我们的贡献如下:
1)我们在鸟瞰视图中引入了早期融合跟踪,具有简单但强大的re-ID关联策略。
2)我们为BEV特征引入了更健壮的解码器架构,改善了我们的跟踪结果和检测。
3)在我们的实验中,我们定性和定量地验证了我们的方法相对于最近相关方法的有效性,并通过+4.6 MOTA和+5.6 IDF1提高了Wildtrack上跟踪的最新水平。
2.相关工作
2.1 Multi-View Object Detection
使用多摄像机设置是解决严重遮挡下行人检测困难的普遍解决方案。这种设置利用同步和校准的摄像机从不同角度观察同一区域。然后,多视图检测系统将这些具有重叠视场的图像进行集成,以执行行人检测。在深度学习带来进步之前,对象的概率建模[9,36]是主要焦点。平均场推断[1,13]和条件随机场(CRF)[1,35]等技术通常用于聚合来自多个视图的信息。然而,这些技术通常需要额外的计算或深度学习模型中不固有的特定设计。
MVDet[22]提出了一种基于卷积的端到端可训练方法,该方法将编码的图像特征从每个视图投影到公共接地平面,产生了显著的改进,并使其成为所有后续方法的基础架构,包括我们的方法。[22]不是仅将每个视图的稀疏检测投影到地平面,而是首先将编码器应用于输入图像,并通过透视变换将所有特征投影到地平面。透视变换投影在3D中描绘实际位置的地平面上的区域的图像特征,导致地平面中类似于实际对象的阴影的失真[21]。
其他方法[21,27,39]试图克服透视变换的这些缺点:[21]在BEV空间中使用具有可变形注意力的投影感知转换器来将这些阴影聚集回原始位置。[27]使用来自2D检测的感兴趣区域,并将这些区域分别投影到地平面上的估计足部位置。另一种方法[39]旨在通过在不同高度使用多个堆栈同形性来近似完整的3D投影,从而克服透视变换的缺点。[32]没有关注模型方面,而是试图改善数据方面的检测。这种方法增加了3D圆柱形物体的额外遮挡。这种数据增强使得该方法更难总是依赖于多个摄像机,从而有助于避免过度拟合。
我们的方法建立在MVDet[22]的基础上,因为它是早期融合多视图对象检测的坚实而直接的基线,我们可以通过我们的跟踪方法进行扩展。
2.2 Multi-Target Multi-Camera Tracking
有很多关于单摄像机跟踪的文献,我们将在后面讨论单镜头跟踪器,但在这一节中,我们讨论多目标多摄像机(MTMC)跟踪的相关工作。大多数MTMC追踪器假设摄像机之间有重叠的视野(FOV)。弗勒特等人。[13]使用重叠FOV将目标建模为概率占用图(POM),并在跟踪过程中将占用概率与颜色和运动属性相结合。作为改进[2],将POMs中的跟踪公式化为整数规划问题,并使用k-最短路径(KSP)算法计算最优解。MTMC跟踪问题也可以看作是一个图问题。超图[20]或多商品网络流[26,38]用于模拟视图之间的对应关系,然后用最小成本[20,38]或分支和价格算法[26]求解。
近年来,一种两阶段方法变得流行[18]:首先生成每个摄像机内所有目标的局部轨迹,然后在所有摄像机中匹配属于同一目标的局部轨迹。对于第一步,在单个摄像机内生成局部轨迹被称为单摄像机MOT,这已经被深入研究过[3,7,11,42,43,46,47]。由于目标检测技术令人印象深刻的进步,检测跟踪[3,11,37,43,47]近年来已成为多目标跟踪的主流方法。对于第二步,已经提出了各种交叉视图数据关联方法来匹配不同摄像机之间的局部轨迹。
一些工作[10,23]使用极上几何形状的属性来寻找基于地平面上位置的对应关系。除了接地层位置[44]之外,还增加了外观特征作为关联的线索。当前最先进的模型[8,29]翻转了前两个步骤:首先将2D检测投影到3D接地层,然后用re-ID节点特征构建图形。然后,使用图神经网络进行链路预测,首先在空间和时间上分配节点[8],或者在同一步骤中进行这两种分配[29]。虽然所有当前的方法[3,8,37,46,47]都是根据检测结果进行评估,以考虑检测的不准确性,但LMGP[29]是根据地面真实边界框进行评估的,因此无法与任何最近的工作进行比较。我们的方法不同于所有以前的工作,更类似于下一节中涉及的一次性跟踪器。我们的方法与最新方法[8,29]的想法相同,首先在我们的探测器中进行空间关联,然后在地平面上进行关联。
2.3 One-Shot Tracking
单视图多对象跟踪器的一个特例是单镜头跟踪器。这些跟踪器在一个步骤中执行检测和跟踪,从而减少了推理时间。与两步跟踪器相比,它们的性能通常较低。预测的特征可以是重新识别的特征[41,42,46]或运动线索[3,11,47]。基于re-ID的方法的第一个例子是TrackRCNN[41],它在Mask R-CNN[17]的顶部添加了re-ID特征提取,并为每个提议回归边界框和reID特征。
类似地,JDE[42]是建立在YOLOv3[33]之上的,FairMOT是建立在CenterNet[48]之上的。与其他产品相比,FairMOT的优势在于它是无锚定的,这意味着检测不是基于边界框,而是基于单个检测点,从而更好地分离re-ID特征。D&T在[11]中被提出作为基于运动的跟踪器,它从相邻帧中获取输入,并预测边界框之间的帧间偏移。Tracktor[3]直接利用边界框回归头来传播区域建议的同一性,从而消除框关联。与其他方法不同,CenterTrack[47]预测三元组输入的对象中心偏移:当前帧、最后一帧和最后一帧检测的热图。以前的热图允许此方法匹配任何地方的对象,即使框重叠。然而,基于运动的方法仅关联相邻帧中的对象,而不重新初始化丢失的轨迹,因此难以处理遮挡。
因此,在我们的方法中,我们将FairMOT[46]中的联合检测和重新识别提取的概念引入MTMC跟踪。虽然训练图像的re-ID特征是众所周知的任务[19,41,42,46],但将强re-ID特征投射到BEV是我们将在这项工作中研究的。
3.核心思想 EarlyBird
我们在图2中提供了EarlyBird的全面概述。它从输入图像开始,输入图像被增强并馈送到编码器网络,以产生我们的图像特征。图像特征的输入图像的大小向下采样4。来自所有摄像机的图像特征随后被投影到地平面并堆叠到BEV空间中。在接下来的步骤中,然后在垂直维度上缩减BEV空间。BEV特征最终通过解码器网络馈送。图像特征和BEV特征都有单独的中心和偏移检测头,但共享一个用于重新识别预测的头。
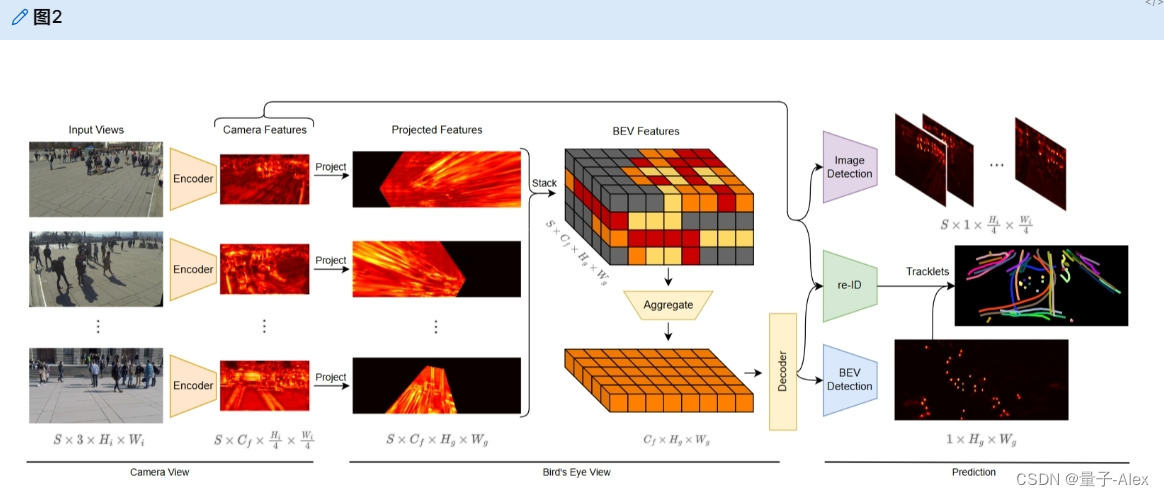
图二。我们方法的概述。输入视图被编码,并且产生的相机特征被投影到地平面。然后堆叠和聚集投影的特征以产生BEV特征。对于图像特征,预测框中心以指导BEV中的占用检测。此外,我们训练一个由摄像机特征和BEV特征引导的re-ID特征。然后,检测及其相应的重新识别特征被用于将检测关联到轨迹中。
3.1 Encoder
我们的方法假设来自 S S S相机的同步RGB输入图像,输入大小为3 × H i H_i Hi × W i W_i Wi。我们使用网络的三个块,用ResNet或Swin Transformer model网络对图像的特征进行编码,每个块将输入下采样2。我们的目标是仅将图像缩小4倍,因此我们上采样并连接每层的输出特征,直到我们得到 C f C_f Cf × H f H_f Hf × W f W_f Wf的输出,其中 H f = H i / 4 H_f = H_i/4 Hf=Hi/4, W f = W i / 4 W_f = W_i/4 Wf=Wi/4, C f = 128 C_f = 128 Cf=128。
3.2 Projection
投影是这种方法的核心部分,因为它在图像视图和BEV视图之间提供了无参数链接。在[22]之后,我们使用透视投影将图像特征投影到地平面。使用针孔相机模型[15],3D位置(x,y,z)和2D图像像素坐标(u,v)之间的平移通过以下方式计算:
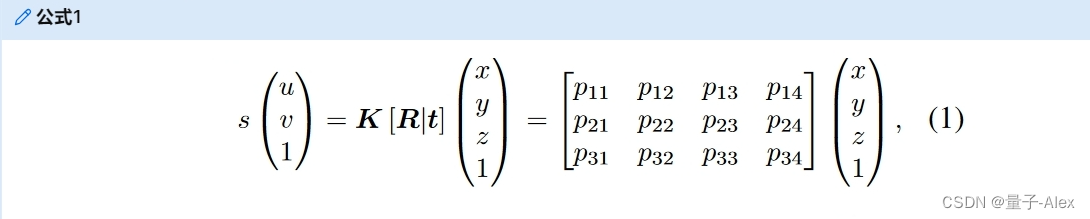
其中s是实值比例因子, P = K [ R ∣ t ] P = K [R|t] P=K[R∣t]是3 × 4透视变换矩阵,K是内在相机矩阵, [ R ∣ t ] [R|t] [R∣t]是3 × 4外在参数矩阵。等式(1)描述了对应于3D世界中的每个像素(u,v)的光线。在我们的方法中,我们选择将所有像素投影到地平面z=0,然后投影可以简化为:

其中 P 0 \mathbf{P}_0 P0表示没有 P \mathbf{P} P的第三列的3 × 3透视变换矩阵。我们应用公式(2)以投影 P 0 ( s ) \mathbf{P^{(s)}_0} P0(s)将来自所有 S S S摄像机的特征投影到预定尺寸 [ H g , W g ] [H_g,W_g] [Hg,Wg]的地平面网格。地平面网格的大小取决于观察和注释区域的大小。每个网格位置代表一个10 cm × 10 cm的区域,由于内存问题,注释网格进一步下采样4。来自S相机的所有带有C通道的堆叠特征图为我们提供了尺寸为 S × C f × H g × W g S × C_f × H_g × W_g S×Cf×Hg×Wg的BEV特征。
3.3 Aggregation & Decoder
聚合阶段的目标是将来自所有S摄像机的特征组合成单个特征,即减少BEV特征图的S维。我们沿着通道维度连接所有特征图,如 S × C f × H g × W g → ( S ⋅ C f ) × H g × W g S × C_f × H_g × W_g → (S · C_f ) × H_g × W_g S×Cf×Hg×Wg→(S⋅Cf)×Hg×Wg,产生高维BEV特征图。通过两次2D卷积,我们将这种高维BEV特征减少到我们期望的信道大小 C g = 128 C_g=128 Cg=128。
聚合后,我们将BEV特征输入ResNet-18解码器。解码器的目标是引入接地层的大感受野。透视投影引入的失真导致行人特征从它们在地平面上的实际位置展开。其他方法[21,27,32,39]认为这种失真对检测精度和所有提出的复杂解决方案有害,如可变形transformers[21]或ROI投影[27]。我们的解码器提供了一种简单的解决方案来聚合接地层上的位置和识别特征。
在ResNet的每一层中,BEV特征被下采样2。然后,我们使用金字塔网络架构将每一层的输出上采样到前一个较大输出的大小。然后,将两个特征在通道维度上连接,并应用2D卷积。特征金字塔产生解码输出,其形状与 C f × H g × W g C_f × H_g × W_g Cf×Hg×Wg的输入相同,但每个网格位置的感受野要高得多。
3.4 Heads & Losses
为了获得POM的最终预测,我们在BEV特征图上使用预测头。检测架构遵循CenterNet[48],我们添加了一个中心检测头,将特征减少到 1 × H g × W g 1 × H_g × W_g 1×Hg×Wg,以在地平面上产生热图或POM。我们添加了另一个用于偏移预测的头,这有助于更准确地预测位置,因为它减轻了来自地面网格的量化误差。偏移量有一个(x,y)分量,形状为 1 × H g × W g 1 × H_g × W_g 1×Hg×Wg。每个头通过应用3 × 3卷积(Cg=128通道)来实现,随后是激活层和1 × 1卷积到最终目标尺寸。中心磁头用Focal Loss训练,偏移头用L1损失训练。
我们还为图像特征添加了检测头,用于预测2D边界框的中心和估计边界框底部中心的脚位置,帮助图像特征每个行人的位置。根据FairMOT[46],我们添加了一个不确定性项,以便在对单任务损失求和之前自动平衡它们。
re-ID head旨在生成可以区分单个行人的特征。理想情况下,不同行人之间的亲和力应该小于同一行人之间的亲和力。为了存档,我们通过分类任务和度量学习任务来学习reID特征。首先,我们应用一个磁头,该磁头在具有 C i d = 64 C_{id}=64 Cid=64的地平面 C i d , g × H g × W g C_{id,g} × H_g × W_g Cid,g×Hg×Wg上产生re-ID特征,并且还产生图像特征 C i d , f × H f × W f C_{id,f} × H_f × W_f Cid,f×Hf×Wf。然后,我们在两个平面的中心检测位置提取特征。我们创建了一个具有线性层的类同一性分布,我们用交叉熵损失来训练该分布。如前所述,透视变换会在地平面上引入强烈的失真。因此,我们从图像视图来监督重新识别特征。除了交叉熵损失之外,我们还应用了SupCon损失[25],它将属于同一类身份的特征拉在一起,同时将来自不同类的样本的特征分开。
在推理时,我们采用BEV中心头预测的POM,并通过简单的3 × 3最大池操作执行非最大抑制(NMS),如[47]所示。然后,我们仅提取超过某个阈值0.4的检测。我们还提取估计的行人中心的身份嵌入。在下一节中,我们将讨论如何使用re-ID功能将检测到的框与时间相关联。
我们采用MOTDT[7]描述的分层在线数据关联方法,但我们只跟踪鸟瞰的行人中心,而不是方框。我们的第一步是根据初始的时间步长
随着每个后续时间步长的处理,我们使用两阶段匹配策略将检测到的中心连接到现有的轨迹
在第一阶段,我们使用卡尔曼滤波器[24]和重新识别特征的组合来实现初始跟踪结果。具体来说,我们使用卡尔曼滤波器来预测下一帧中的轨迹线位置,并计算预期中心和检测中心之间的马氏距离(Dm),类似于DeepSORT[43]。然后,我们使用公式 D = λ D r + ( 1 − λ ) D m D = λD_r + (1 − λ)D_m D=λDr+(1−λ)Dm将Mahalanobis距离与在re-ID特征上计算的余弦距离组合成奇异距离度量(D),其中 λ λ λ是在我们的实验中设置为0.98的预定加权参数。如果Mahalanobis距离超过某个阈值,则手动将其设置为无穷大,这与JDE协议[42]一致,并防止跟踪显示不可信运动的轨迹。然后,我们使用匹配阈值 τ 1 = 0.4 τ_1=0.4 τ1=0.4的匈牙利算法来结束第一个匹配阶段。
第二阶段包括尝试根据未检测到的盒子和轨迹的中心距离来匹配它们各自的盒子和轨迹,匹配阈值 τ 2 = 2.5 m τ_2 = 2.5 m τ2=2.5m。我们在每个时间步不断更新轨迹的外观特征,以考虑外观的潜在变化。任何不匹配的中心都被分类为新轨迹,不匹配的轨迹被保留10个时间步长,以便于识别,如果它们以后再次出现的话。
5.数据集和评估指标
5.1 Wildtrack Dataset
Wildtrack[5]是一个真实世界的数据集,使用七个同步和校准的摄像机捕获,重叠的视野面积为12米× 36米。行人的活动是在公共环境中进行的,没有脚本。注释在量化为480 × 1440网格的地平面上提供,产生2.5厘米× 2.5厘米的网格单元。每帧平均行人人数为20人,每个位置覆盖3.74个摄像头。每张相机图像以1080 × 1920像素的分辨率录制,帧速率为2 fps,共覆盖35分钟。
5.2 MultiviewX Dataset
MultiviewX[22]是在游戏引擎中生成的合成数据集,是Wildtrack数据集的合成副本。MultiviewX包含由6个具有重叠视野的虚拟摄像机生成的视图。捕获的区域为16米× 25米,略小于Wildtrack数据集的区域。为了注释,接地层被量化为大小为640 × 1000的网格,其中每个网格代表相同的2.5 cm × 2.5 cm正方形。每帧平均行人人数为40人,而4.41个摄像头覆盖每个位置。相机分辨率(1080 × 1920)、帧速率(2 fps)和长度(400帧)等于Wildtrack。
5.3 Detection Metrics
与评估预测边界框的单目视图检测系统不同,多视图检测系统评估投影地平面占用图。因此,与地面实况的比较不是用并集上的交集(IoU)计算的,而是用[5]中提出的欧几里得距离计算的。如果检测在距离r=0.5 m(大致相当于人体半径)内,则被归类为真阳性。根据之前的工作[5,22],我们使用多目标检测精度(MODA)作为主要性能指标,因为它解释了归一化的遗漏检测和误报。此外,我们报告了多目标检测精度(MODP),精度,和召回率
5.4 Tracking Metrics
为了跟踪,还在接地层中计算度量。我们报告了常见的MOT度量[4]和身份感知度量[34],正赋值的阈值设置为r=1 m,以标准化多目标跟踪精度(MOTP)。考虑的主要指标是多目标跟踪精度(MOTA)和IDF1。MOTA会考虑遗漏检测、错误检测和身份转换。IDF1测量遗漏检测、误报和身份切换。此外,我们还报告了大部分被跟踪(MT)和大部分丢失(ML)。这些被报告为测试集中存在的唯一行人总数的百分比。
6.实验设计与实验结果
6.1 Implementation Details
图像的输入大小为720 × 1280像素。对于训练时的增强,我们遵循[14,21]:我们在【0.8,1.2】的比例范围内对RGB输入应用随机调整大小和裁剪,并相应地调整相机固有K。此外,我们向摄像机外部的平移向量t添加一些噪声,以避免过度拟合解码器。我们使用Adam优化器训练检测器,该优化器具有最大学习速率为 1 0 − 3 10^{−3} 10−3的单周期学习速率调度器。我们训练50个时期,并取决于编码器的大小,批量大小为1-2,但在更新权重以具有16的有效批量大小之前,在多个批量上累积梯度。编码器和解码器网络用ImageNet-1K上预先训练的权重初始化。所有的实验都是用一个RTX 3090 GPU
6.2 Main Results
6.2.1 Detection
在逐检测跟踪范式中,良好的检测是良好跟踪结果的基础。虽然我们的方法并不专注于改善检测,但我们仍然需要接近最先进的技术才能获得有竞争力的结果。表1将我们的方法的检测性能与以前的方法进行了比较。我们首先将我们的结果与基线MVDet[22]进行比较,因为我们的方法是基于它的。结果表明,我们的解码器架构和扩增变化改善了MVDet。其他以检测为中心的方法[21,27,39]也扩展了MVDet,并在Wildtrack上获得了比较结果,但我们的方法在MultiviewX上具有竞争结果。目前最先进的MVTT[27]是一种两阶段检测方法,仍然可以添加到我们的单阶段方法中,以进一步改善结果。
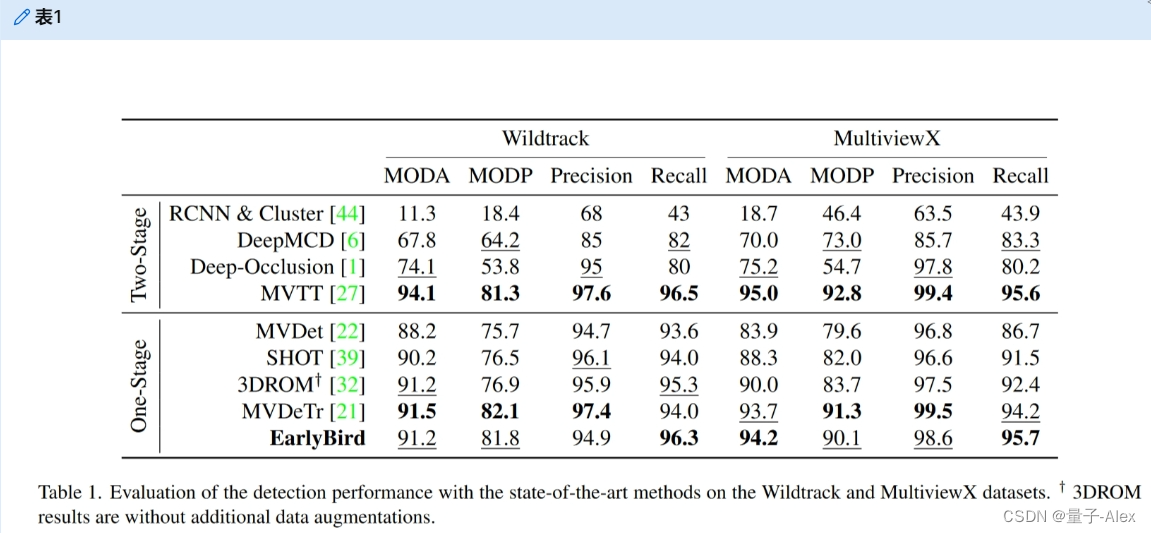
表1。在Wildtrack和MultiviewX数据集上使用最先进的方法评估检测性能。3DROM结果不含额外的数据扩充。
6.2.2 Tracking
在表2中,我们将我们的方法与最先进的方法进行比较。我们的方法远远优于当前所有的方法。与当前性能最好的方法ReST[8]相比,我们将IDF1提高了5.6个百分点,将MOTA提高了4.6个百分点。所有其他方法[5,8,29,30,45]都是从2D检测开始的,为了比较跟踪方法,您还需要考虑检测质量。对于这些方法中的大多数,我们不能直接比较检测质量,但ReST[8]使用来自MVDeTr[21]的检测,其性能非常接近我们的检测器(参见表1)。ReST和EarlyBird遵循类似的方法:在地平面上进行空间关联,然后在时间上关联。然而,ReST仅将2D的检测投影到地平面,并将它们与图形求解器相关联。相反,我们将完整的输入图像特征空间投影到地平面,并将其与解码器相关联。我们的结果表明,在相似的检测质量下,我们的方法优于ReST,这表明了我们的早期融合方法相对于基于图形的后期融合的优势。
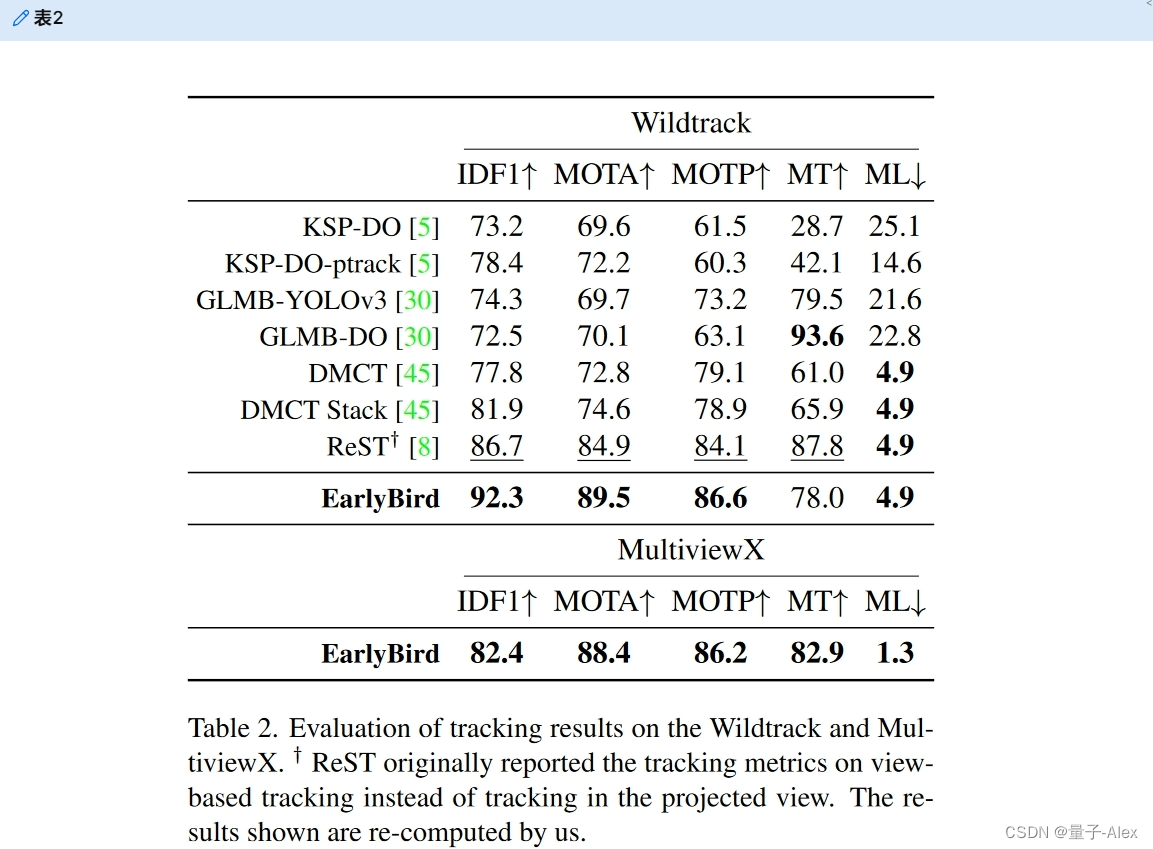
表二。在Wildtrack和MultiviewX上评估跟踪结果。 † † † ReST最初报告的跟踪指标是基于视图的跟踪,而不是投影视图中的跟踪。显示的结果由我们重新计算。
6.3 Ablations Studies
6.3.1 Influence of Method Components
接下来,我们将方法中引入的每个组件与基线进行比较,如表3所示,基线由MVDet[22]和最小的附加物组成,以执行跟踪,即在BEV空间中添加一个ReID头。基线结果遭受强烈的过度拟合,下一步中增加的增强主要避免了这一点。我们通过缩放和裁剪来增加输入图像,以避免编码器中的过拟合,并将传递噪声添加到地平面的投影中,以避免预测头中的过拟合。为了更好的增强,我们引入了基于具有特征金字塔的ResNet-18的更大的解码器。这些添加为我们提供了最强大的检测结果之一,但由于跟踪是我们的主要关注点,我们添加了视图中心和重新识别损失。这两个损失应用于图像特征,应该有助于指导这些特征。虽然2D中心检测单独降低了我们的检测性能,但在re-ID丢失的情况下使用它给了我们最终的SOTA结果。
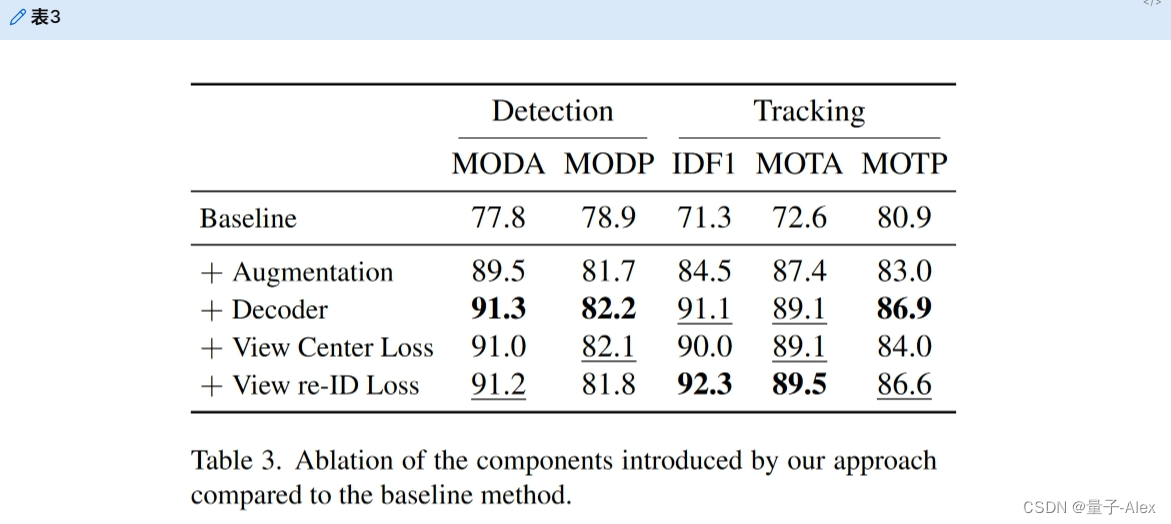
表3。与基线方法相比,我们的方法引入的成分的消融。
6.3.2 Influence of the Encoder Network
编码器提取投影到地平面的RGB图像的特征。虽然所有类似的基于检测的方法[21,22,27,32]都使用ResNet-18编码器,但这些方法不需要对身份特征进行编码。因此,我们用更大的编码器和基于Transformer model的编码器来尝试我们的方法,见表4.消融结果表明,ResNet-18的烧蚀性能最好。ResNet-50在检测和跟踪性能方面可能略好,但较小的ResNet-18在主要指标MODA和MOTA方面优于它,并在IDF1方面具有竞争力。因此,我们使用ResNet-18报告所有其他结果。
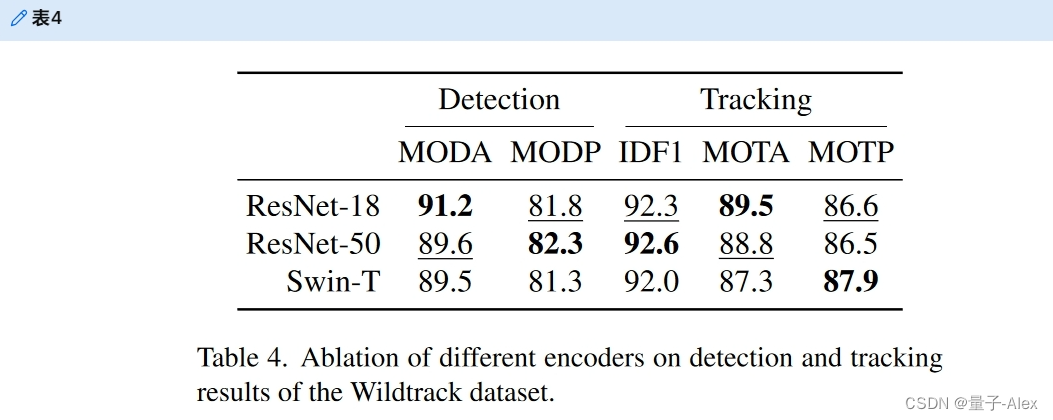
表4。不同编码器对Wildtrack数据库检测与跟踪结果的影响
6.4 Qualitative Results
在图3中,我们将模型的输出绘制在Wildtrack的测试集上。在图3a中,我们将POM的预测与作为单个时间步长的热图的地面实况进行比较。地面真相中的每一点都代表BEV中的一个行人。场景的中心挤满了行人,在这个高重叠区域的预测几乎是完美的。行人越靠一边,预测就越不准确。这种不准确可能是由于摄像机的失真增加,边界区域的视图重叠减少。

图3b示出了用于跟踪的类似结果。我们显示了Wildtrack的完整测试集的地平面上的所有轨迹,其中每个颜色和线条代表一个身份所走的路径。场景中心的轨迹几乎被完美地预测。但是,左上角和右上角的轨道是分段或切换的轨道。这种不准确可能是由于接地层外的检测和识别特征不太准确或缺失。
7 研究结论
7.1 Limitations
我们方法的第一个限制是对高质量3D注释和相机校准的要求。虽然这很容易用合成数据归档,但对于真实世界的数据来说成本很高。因此,我们无法评估一些较旧的数据集(CAMPUS[44],PETS09[12]),其中大多数后期融合模型只能使用2D注释和接地层单应性。此外,我们的方法需要同步摄像机。由于我们将所有相机提升到相同的3D空间,时差应该最小,这样移动的对象就不会投影到3D中的不同位置。后期融合MTMC跟踪方法可以解释时间域中更多的漂移。我们的方法也有更高的硬件要求。虽然后期融合方法可以分散处理每个相机,集中融合信息,但我们的方法可以同时处理所有相机图像。因此,它需要在一台机器上使用更多的内存和计算资源。
7.2 Ethical Impact
跟踪方法总是有被用于非法监视的风险。专注于行人跟踪的方法尤其必须面对这种批评。数据集Wildtrack[5]因缺少被记录人员的同意而受到批评[16]。不幸的是,只有使用该数据集才能与最先进的数据集进行良好的比较,尽管现在可以使用MultiviewX[22]进行合成复制。我们是第一个在这个合成数据集上评估跟踪的人,以降低跟踪的伦理影响。
7.3 Future Work
对于检测部分,我们和其他当前方法[21,27,39]的最大挑战是投影变换引起的失真。可以探索从2D提升到3D空间的其他方法用于多视图检测,即Simple-BEV[14]、Lift-SplatShot[31]或BEVFormer[28]。大多数当前方法仅使用当前帧进行检测。使用更多的时间帧可以提高检测性能[28]。使用更多的时间上下文也可以提高跟踪质量,像CenterTrack[47]这样的方法可以用于通过运动线索进行跟踪。这项工作中使用的行人数据集大约有400个时间戳,以现代计算机视觉标准来看这是相对较小的,并且检测和跟踪精度已经饱和。对更大数据集的需求是显而易见的,交通监控中具有类似MTMC问题的数据集[18,40]可以弥合这一差距。
7.4 Conclusion
本文通过多视点高精度跟踪,说明了EarlyBird对人群的捕获。早期融合所有视图和鸟瞰视图中的跟踪大大改善了MTMC跟踪。我们将单镜头跟踪应用于多视角跟踪,提出了一种在线、无锚跟踪器。我们提出了在BEV中有效训练重新识别特征的方法,并消除了我们的每一项跟踪改进。我们希望EarlyBird能够激发earlyfusion多视图跟踪中的功能工作,并相信EarlyBird以及我们建议的未来工作在解决多视图跟踪问题方面取得了重大进展。
11 引用文献
- [1] Pierre Baqu ́ e, Franc ̧ois Fleuret, and Pascal Fua. Deep occlusion reasoning for multi-camera multi-target detection. In ICCV, pages 271–279, 2017. 2, 5
- [2] Jerome Berclaz, Francois Fleuret, Engin Turetken, and Pascal Fua. Multiple object tracking using k-shortest paths optimization. IEEE TPAMI, 33(9):1806–1819, 2011. 2
- [3] Philipp Bergmann, Tim Meinhardt, and Laura Leal-Taixe. Tracking without bells and whistles. In CVPR, pages 941951, 2019. 3
- [4] Keni Bernardin and Rainer Stiefelhagen. Evaluating multiple object tracking performance: the clear mot metrics.EURASIP Journal on Image and Video Processing, 2008:110, 2008. 6
- [5] Tatjana Chavdarova, Pierre Baqu ́ e, St ́ ephane Bouquet, Andrii Maksai, Cijo Jose, Timur Bagautdinov, Louis Lettry, Pascal Fua, Luc Van Gool, and Fran ̧ cois Fleuret. Wildtrack: A multi-camera hd dataset for dense unscripted pedestrian detection. In CVPR, pages 5030–5039, 2018. 5, 6, 7, 8
- [6] Tatjana Chavdarova and Fran ̧ cois Fleuret. Deep multicamera people detection. In 2017 16th IEEE international conference on machine learning and applications (ICMLA), pages 848–853. IEEE, 2017. 5
- [7] Long Chen, Haizhou Ai, Zijie Zhuang, and Chong Shang. Real-time multiple people tracking with deeply learned candidate selection and person re-identification. In ICME, pages 1–6. IEEE, 2018. 3, 5
- [8] Cheng-Che Cheng, Min-Xuan Qiu, Chen-Kuo Chiang, and Shang-Hong Lai. Rest: A reconfigurable spatial-temporal graph model for multi-camera multi-object tracking. arXiv preprint arXiv:2308.13229, 2023. 2, 3, 5, 7
- [9] Adam Coates and Andrew Y Ng. Multi-camera object detection for robotics. In 2010 IEEE International Conference on Robotics and Automation, pages 412–419. IEEE, 2010. 2
- [10] Ran Eshel and Yael Moses. Homography based multiple camera detection and tracking of people in a dense crowd. In CVPR, pages 1–8. IEEE, 2008. 3
- [11] Christoph Feichtenhofer, Axel Pinz, and Andrew Zisserman. Detect to track and track to detect. In ICCV, pages 30383046, 2017. 3
- [12] James Ferryman and Ali Shahrokni. Pets2009: Dataset and challenge. In 2009 Twelfth IEEE international workshop on performance evaluation of tracking and surveillance, pages 1–6. IEEE, 2009. 8
- [13] Francois Fleuret, Jerome Berclaz, Richard Lengagne, and Pascal Fua. Multicamera people tracking with a probabilistic occupancy map. IEEE TPAMI, 30(2):267–282, 2007. 2
- [14] Adam W. Harley, Zhaoyuan Fang, Jie Li, Rares Ambrus, and Katerina Fragkiadaki. Simple-BEV: What really matters for multi-sensor bev perception? In IEEE International Conference on Robotics and Automation (ICRA), 2023. 6, 8
- [15] Richard Hartley and Andrew Zisserman. Multiple view geometry in computer vision. Cambridge university press, 2003. 4
- [16] Jules. Harvey, Adam. LaPlace. Exposing.ai, 2021. 8
- [17] Kaiming He, Georgia Gkioxari, Piotr Doll ́ ar, and Ross Girshick. Mask r-cnn. In ICCV, pages 2961–2969, 2017. 3
- [18] Fabian Herzog, Junpeng Chen, Torben Teepe, Johannes Gilg, Stefan H ̈ ormann, and Gerhard Rigoll. Synthehicle: Multivehicle multi-camera tracking in virtual cities. In WACV Worksh., pages 1–11, January 2023. 2, 3, 8
- [19] Fabian Herzog, Xunbo Ji, Torben Teepe, Stefan H ̈ ormann, Johannes Gilg, and Gerhard Rigoll. Lightweight multibranch network for person re-identification. In ICIP, pages 1129–1133. IEEE, 2021. 3
- [20] Martin Hofmann, Daniel Wolf, and Gerhard Rigoll. Hypergraphs for joint multi-view reconstruction and multi-object tracking. In CVPR, pages 3650–3657, 2013. 2
- [21] Yunzhong Hou and Liang Zheng. Multiview detection with shadow transformer (and view-coherent data augmentation). In ACM MM, 2021. 1, 2, 4, 5, 6, 7, 8
- [22] Yunzhong Hou, Liang Zheng, and Stephen Gould. Multiview detection with feature perspective transformation. In ECCV, 2020. 1, 2, 4, 5, 6, 7, 8
- [23] Weiming Hu, Min Hu, Xue Zhou, Tieniu Tan, Jianguang Lou, and Steve Maybank. Principal axis-based correspondence between multiple cameras for people tracking. IEEE TPAMI, 28(4):663–671, 2006. 3
- [24] Rudolph Emil Kalman. A new approach to linear filtering and prediction problems. Journal of Basic Engineering, 1960. 2, 5
- [25] Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. Advances in neural information processing systems, 33:18661–18673, 2020. 5
- [26] Laura Leal-Taix ́ e, Gerard Pons-Moll, and Bodo Rosenhahn. Branch-and-price global optimization for multi-view multitarget tracking. In CVPR, pages 1987–1994. IEEE, 2012. 2
- [27] Wei-Yu Lee, Ljubomir Jovanov, and Wilfried Philips. Multiview target transformation for pedestrian detection. In WACV Worksh., pages 90–99, 2023. 1, 2, 4, 5, 7, 8
- [28] Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Yu Qiao, and Jifeng Dai. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In ECCV, pages 118, 2022. 8
- [29] Duy MH Nguyen, Roberto Henschel, Bodo Rosenhahn, Daniel Sonntag, and Paul Swoboda. Lmgp: Lifted multicut meets geometry projections for multi-camera multi-object tracking. In CVPR, pages 8866–8875, 2022. 2, 3, 7
- [30] Jonah Ong, Ba-Tuong Vo, Ba-Ngu Vo, Du Yong Kim, and Sven Nordholm. A bayesian filter for multi-view 3d multiobject tracking with occlusion handling. IEEE TPAMI, 44(5):2246–2263, 2020. 5, 7
- [31] Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. In ECCV, pages 194–210. Springer, 2020. 8
- [32] Rui Qiu, Ming Xu, Yuyao Yan, Jeremy S Smith, and Xi Yang. 3d random occlusion and multi-layer projection for deep multi-camera pedestrian localization. In ECCV, pages 695–710. Springer, 2022. 2, 4, 5, 8
- [33] Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018. 3
- [34] Ergys Ristani, Francesco Solera, Roger Zou, Rita Cucchiara, and Carlo Tomasi. Performance measures and a data set for multi-target, multi-camera tracking. In ECCV, pages 17–35. Springer, 2016. 6
- [35] Gemma Roig, Xavier Boix, Horesh Ben Shitrit, and Pascal Fua. Conditional random fields for multi-camera object detection. In ICCV, pages 563–570, 2011. 2
- [36] Aswin C Sankaranarayanan, Ashok Veeraraghavan, and Rama Chellappa. Object detection, tracking and recognition for multiple smart cameras. Proceedings of the IEEE, 96(10):1606–1624, 2008. 2
- [37] Jenny Seidenschwarz, Guillem Bras ́ o, V ́ıctor Castro Serrano, Ismail Elezi, and Laura Leal-Taix ́ e. Simple cues lead to a strong multi-object tracker. In CVPR, pages 13813–13823, 2023. 3
- [38] Horesh Ben Shitrit, J ́ er ˆ ome Berclaz, Fran ̧ cois Fleuret, and Pascal Fua. Multi-commodity network flow for tracking multiple people. IEEE TPAMI, 36(8):1614–1627, 2013. 2
- [39] Liangchen Song, Jialian Wu, Ming Yang, Qian Zhang, Yuan Li, and Junsong Yuan. Stacked homography transformations for multi-view pedestrian detection. In CVPR, pages 60496057, 2021. 1, 2, 4, 5, 7, 8
- [40] Zheng Tang, Milind Naphade, Ming-Yu Liu, Xiaodong Yang, Stan Birchfield, Shuo Wang, Ratnesh Kumar, David Anastasiu, and Jenq-Neng Hwang. Cityflow: A city-scale benchmark for multi-target multi-camera vehicle tracking and re-identification. In CVPR, pages 8797–8806, 2019. 8
- [41] Paul Voigtlaender, Michael Krause, Aljosa Osep, Jonathon Luiten, Berin Balachandar Gnana Sekar, Andreas Geiger, and Bastian Leibe. MOTS: Multi-object tracking and segmentation. In CVPR, 2019. 3
- [42] Zhongdao Wang, Liang Zheng, Yixuan Liu, Yali Li, and Shengjin Wang. Towards real-time multi-object tracking. In ECCV, pages 107–122. Springer, 2020. 3, 6
- [43] Nicolai Wojke, Alex Bewley, and Dietrich Paulus. Simple online and realtime tracking with a deep association metric. In ICIP, pages 3645–3649. IEEE, 2017. 3, 5
- [44] Yuanlu Xu, Xiaobai Liu, Yang Liu, and Song-Chun Zhu. Multi-view people tracking via hierarchical trajectory composition. In CVPR, pages 4256–4265, 2016. 1, 3, 5, 8
- [45] Quanzeng You and Hao Jiang. Real-time 3d deep multicamera tracking. arXiv preprint arXiv:2003.11753, 2020. 5, 7
- [46] Yifu Zhang, Chunyu Wang, Xinggang Wang, Wenjun Zeng, and Wenyu Liu. FairMot: On the fairness of detection and reidentification in multiple object tracking. IJCV, 129:30693087, 2021. 2, 3, 5
- [47] Xingyi Zhou, Vladlen Koltun, and Philipp Kr ̈ ahenb ̈ uhl. Tracking objects as points. In ECCV, pages 474–490. Springer, 2020. 3, 5, 8
- [48] Xingyi Zhou, Dequan Wang, and Philipp Kr ̈ ahenb ̈ uhl. Objects as points. In arXiv preprint arXiv:1904.07850, 2019. 3, 4
)




: 将物理知识融合到深度学习中)



只出现一次的数字III)


)






)