简介:基于百度搜索引擎的PYthon3爬虫程序的网页采集器,小白和爬虫学习者都可以学会。运行爬虫程序,输入关键词,即可将所搜出来的网页内容保存在本地。
知识点:requests模块的get方法
一、此处需要安装第三方库requests:
在Pycharm平台终端或者命令提示符窗口中输入以下代码即可安装
pip install requests二、抓包分析及编写Python代码
1、打开百度搜索进行抓包分析
- 打开百度搜索的网站
- 按下F12键,打开开发者界面
- 此时由于翻译页面没有数据传输,属于静态页面,开发者界面也就没有任何数据传输的情况
- 在输入框中输入要查找的关键词--周杰伦,回车
- 在开发者界面中可以看到有数据正在进行传输(百度搜索是局部刷新,也就是Ajax框架的异步加载)
- 找到第一个出现的信息,点击,查看Header信息。
- 这里只需要用到两部分内容,一个的请求的url地址,一个是user-agent(用户识别)信息。
- 查看url部分,我们可以看到wd=一堆乱码(对链接的构成不清楚的同学可以百度一下)。其实wd是query,也就是查询的关键词的key,一堆乱码其实就是周杰伦(也就是query的值)。百度采用了编码方式,对其进行乱码产生混淆避免他人破解。
所以在wd的值采用键盘读取关键词再复制给wd,即可搜索输入的关键词。
- 继续在header后面向下查找user-agent,其位置在:

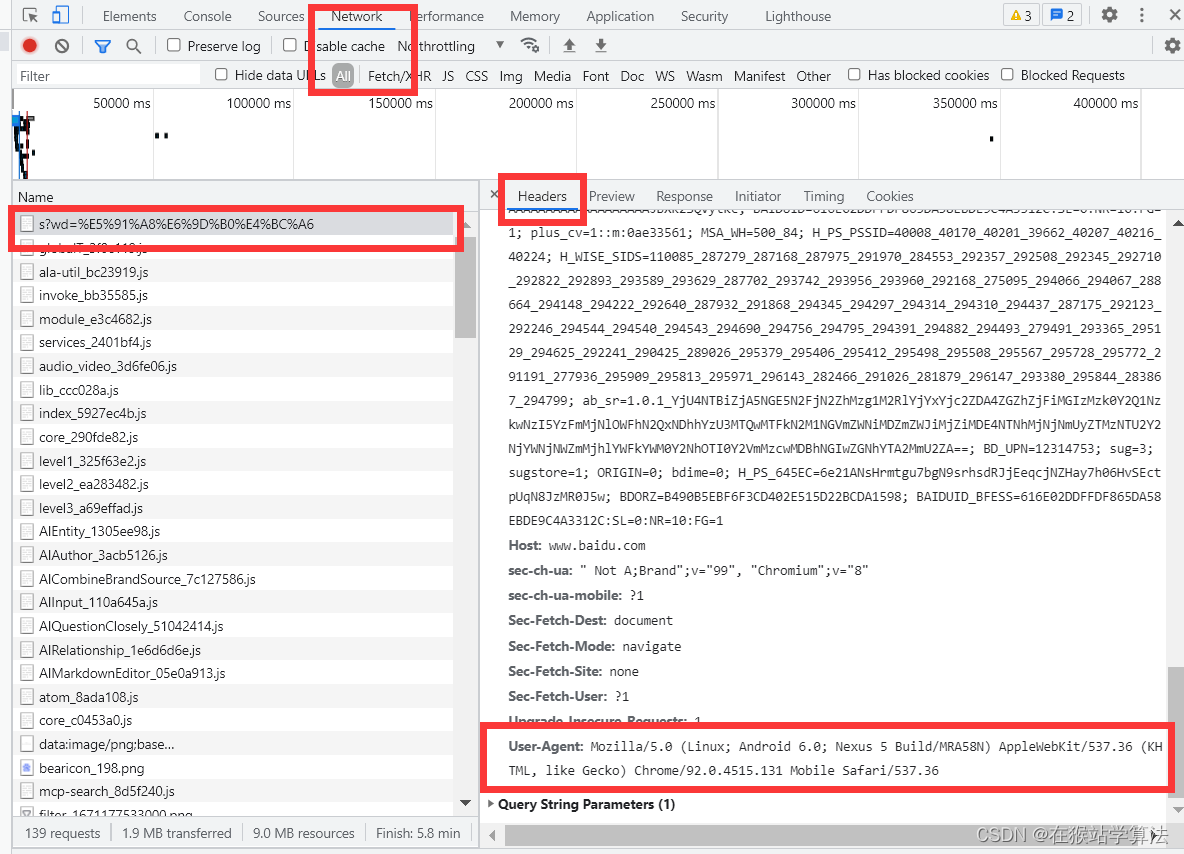
2、编写请求模块
- requests请求模块有get方法和post方法,此处使用的是get方法。(不清楚的可以百度一下)
- get方法里面包含多个参数(不写的话requests模块会有默认的参数),里面需要自己写明三个参数。分别为url(访问地址),header(请求头),data(请求数据)。此处由于我们不需要携带data,则我们只需要准备好url和user-agent即可。
- 需要对url的query的值通过键盘消息输入,代码为:
keyword = input('请输入关键词:')
url= f'https://www.baidu.com/s?wd={keyword}'- 对user-agent只需要以字典格式封装到header中即可,代码为:
headers = {'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}- 将url和header放入get方法中, 代码如下:
response = requests.get(url=url, headers=headers)3、将采集到的网页保存到本地
通过以上部分,已经获得了所查关键词的网页内容。这里进行将获得的网页内容保存到本地。
- 只需要进行写入文件,以html格式保存即可。代码如下:
with open(keyword+'baidu.html', 'w', encoding='utf-8') as f:f.write(response.text)print(f"已下载...{keyword}")三、所有代码如下:
# get方法是客户端向服务器发送请求,将服务器中的信息获取下来
# 网页采集器:基于百度,编写出python爬虫程序,实现输入关键词搜索,将信息获取到本地。
# 1、导入requests请求模块
import requests
# 2、打开百度网页(也可以是其他网站),复制其链接
# 链接中被采用了其他方式进行编码:wd=为链接中的query属性,后面的乱码其实就是输入的查找的关键词
# https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
# 3、在键盘中输入关键词,读取键盘消息
keyword = input('请输入关键词:')
# 4、输入url
url= f'https://www.baidu.com/s?wd={keyword}'
# 5、编写请求头,防止验证时服务器识别出是机器的操作
# user-agent就是服务器响应时识别是否为认为操作的验证方式
# 如果不写,requests模块会使用默认的user-agent,服务器容易识别出来
# 这里,我们是百度页面抓包分析,找到user-agent的值
headers = {'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Mobile Safari/537.36'}
response = requests.get(url=url, headers=headers)
# print(response.text)
# 4、将查找到的信息下载到本地
with open(keyword+'.html', 'w', encoding='utf-8') as f:f.write(response.text)print(f"已下载...{keyword}")运行以上代码即可(注:运行代码时,需要保证处于联网状态。因为requests模块会对服务器进行请求,服务器会响应数据。需要联网,才能传输数据)
基于以上内容, 可以基于360搜索(或其他搜索网站)进行编写PYthon3网页采集器爬虫程序。
注:此贴只用于学习交流,禁止商用。

——编码信道数学模型)



缓存双写一致性策略)

)

)
)



|Day39(动态规划))




