
目录
〇、导言
一、Base LLM 与 Instruction Tuned LLM
二、如何提出有效的问题 ?
1. 明确问题:
2. 简明扼要:
3. 避免二义性:
4. 避免绝对化的问题:
5. 利用引导词:
6. 检查语法和拼写:
7. 追问细节:
三、如何将提问的内容进行应用?
1. API 的基本使用
2. 格式化输出 ?
3. 角色扮演 ?
4. (应用) 十词成文助记单词
5. (应用) AI 脑图生成器(Chat MindMap)
四、总结
〇、导言
随着人工智能技术的迅猛发展,大语言模型(LLM)以微软 OpenAI 为代表,初次问世,为新一次的 AI 革命打响了第一枪。在短短的几个月内,GPT-3.5 和 GPT-4 的加持下,New Bing、Copilot、Cursor 等产品也相继问世,推动了产品开发的新思路。国内厂商也紧随其后,百度文心一言、华为盘古大模型、阿里通义千问、讯飞星火认知大模型相继发布。
我们现在可以通过与 AI 进行对话来获取各种信息和解决问题。但想要获得更准确、有用的回答,我们需要掌握如何向 AI 提问的技巧和方法。本文将探讨一些技巧,帮助您在与 ChatGPT 和其他类 ChatGPT 的大语言模型对话时更加有效且高效。
一、Base LLM 与 Instruction Tuned LLM
在开始之前,我觉得获取有必要向大家讲解一个关于 Base LLM(基础大语言模型)与 Instruction Tuned LLM(指令调整型大语言模型)的知识点,来帮助大家更好地了解大家更好了解之后的内容。如果你对 Base LLM 与 Instruction Tuned LLM 有一定的了解,可以跳过这部分来加速阅读完这篇文章。
Base LLM(Base Language Model)是指大型语言模型的基础版本。这些模型具有广泛的语言理解和生成能力,能够生成连贯、有逻辑的文本回答,并在部分任务和应用中展现出强大的表现;最常见的应用就是文章续写,大家可能见过的应用比如早期 github 上的狗屁不通生成器、夸克浏览器中的 AI 作文灵感生成器、不少人喜欢拿来写文案的秘塔写作猫。
然而,尽管Base LLM在很多方面表现出色,它们仍然存在一些局限性。比如训练数据大多都是来自于互联网,社交平台等易于获取的数据,Base LLM可能会在某些情况下给出不准确或不合适的回答。此外,它们在理解特定领域或任务相关指令时的表现也相对较弱;比如我要询问 “安徽有哪些好玩的地方?”,根据所训练的网络数据的不同,Base LLM 生成的内容可能会有 Answer 1 与 Answer 2 以下两种结果:
- Answer 1,像是一些旅游推荐,搜索推荐所产生的的文本,不是特别符合我们的预期;
- Answer 2,像是出自一些旅游文章或者博客,比较符合我们的预期。
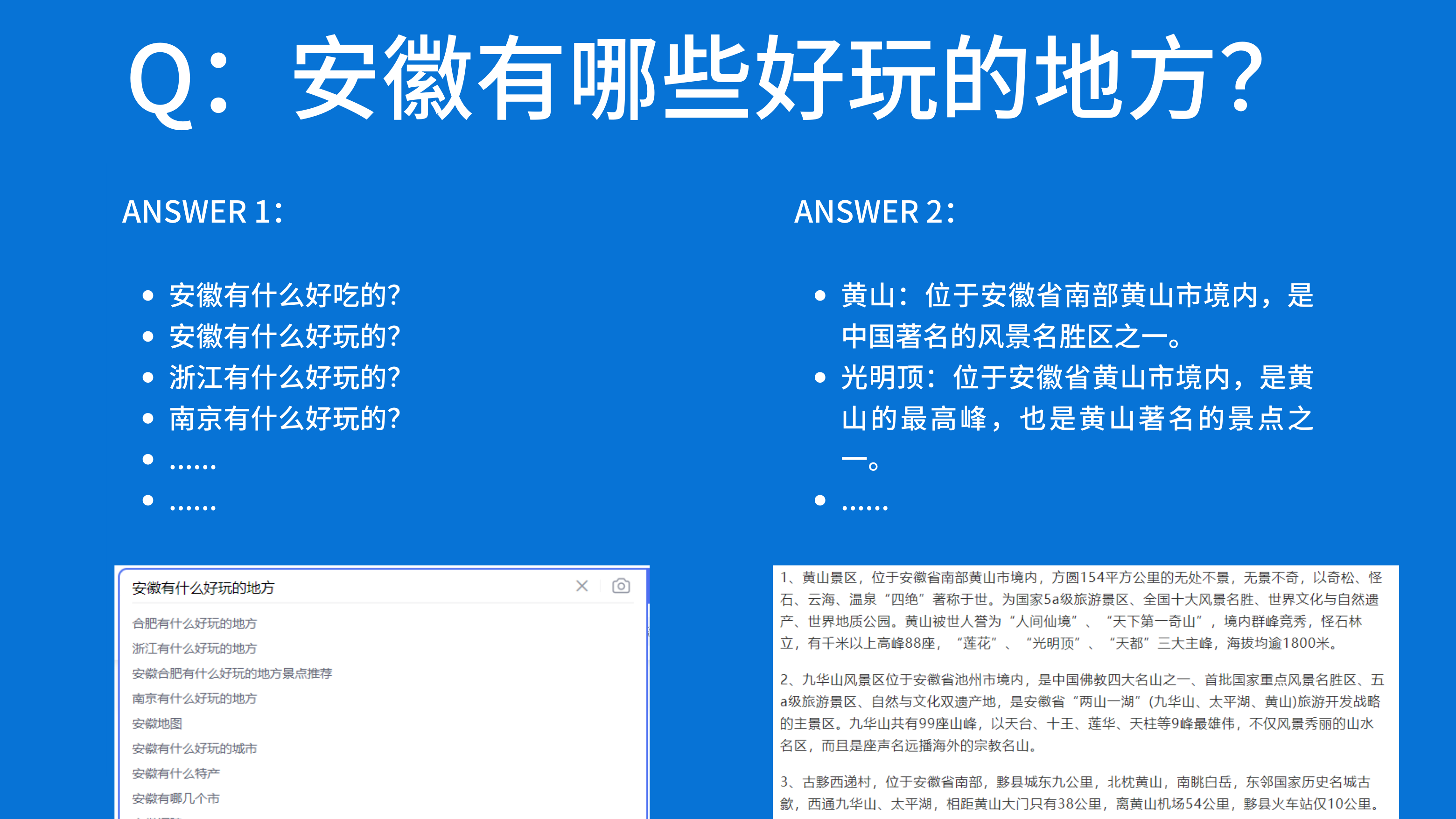
Base LLM 在生成内容时,可能被一些不确定的数据所污染,导致产生的结果并不是我们所预期的结果。为了克服这些限制,研究人员提出了Instruction Tuned LLM(指令调整型语言模型)。Instruction Tuned LLM是一种经过专门优化以更好地理解和执行指令的语言模型。它们通过额外的训练和微调,针对特定任务或领域进行了特定的优化。
与Base LLM相比,Instruction Tuned LLM在特定任务上的性能和准确性更高。它们能够更好地理解并执行给定的指令,生成更符合特定任务需求的回答。通过对模型进行精细调整和针对性训练,Instruction Tuned LLM可以提供更加定制化和个性化的输出。
需要注意的是,Instruction Tuned LLM通常需要更多的训练数据和计算资源来进行优化,因此在实际应用中可能会受到一些限制。此外,对于不同的任务和领域,可能需要针对性地进行模型调整和优化。
总而言之,Base LLM是大型语言模型的基础版本,具备广泛的语言理解和生成能力。而 Instruction Tuned LLM是通过针对特定任务和领域进行优化的版本,能够提供更加定制化和个性化的输出。这两种模型在不同的应用场景中发挥着重要的作用,并为人工智能技术的发展带来了更多的可能性。接下来,我们以较为成熟的 ChatGPT,来讲一下如何有效的向 AI 提问。
二、如何提出有效的问题 ?
How To Ask Questions The Smart Way? 向别人提问一直是一门艺术,向 AI 提问也是如此;有效的问题能够更容易获得你想要的答案,下面就来从语义方面简单讲一下如何向 AI 提出有效的问题。
1. 明确问题:
在向AI提问之前,要先明确自己的问题。尽量用简洁、清晰的语言表达问题的核心。如果问题过于宽泛或含糊不清,AI可能会给出模糊或不相关的回答。下面给出几个例子便于大家理解:
- 不明确的问题: “最近的电影有什么好看的?”
- 明确的问题: “请推荐一些最近上映的悬疑电影。”
- 不明确的问题: “如何学好外语?”
- 明确的问题: “我想学习法语,你有什么建议和资源推荐吗?”
- 不明确的问题: “旅游的最佳时间是什么时候?”
- 明确的问题: “我计划去巴黎旅游,你能告诉我巴黎的最佳旅游季节吗?”
通过将问题具体化和明确化,AI可以更好地理解您的需求并给出更有针对性的回答。确切的问题有助于AI系统准确定位并提供您真正需要的信息,从而提高对话的效果和满意度。
2. 简明扼要:
AI 喜欢简洁明了的问题。避免冗长的描述和复杂的句子结构。用简单直接的语言表达问题,可以提高AI理解问题的准确性。例如,
- 冗长的问题: “我在这个城市有一个会议,我需要一个在市中心附近、价格适中的酒店,带有免费早餐和免费停车场的。你能推荐一些吗?”
- 简明的问题: “请推荐一个价格适中、位于市中心的酒店,带免费早餐和免费停车场。”
- 冗长的问题: “我对新闻感兴趣,尤其是科技和娱乐方面的新闻。你有什么推荐的新闻源吗?”
- 简明的问题: “请推荐一些科技和娱乐新闻源。”
- 冗长的问题: “我在学习编程,我想知道最好的在线编程课程是什么,哪个平台有最好的编程教学资源?”
- 简明的问题: “请推荐一些在线编程课程和优质的编程教学平台。”
通过使用简洁明了的语言,您可以让问题更易于理解和处理。这有助于AI系统更好地捕捉到您问题的核心,提供更相关和准确的回答。避免过多的细节和复杂的句子结构,有助于提高交流的效率和准确性,使您与AI的对话更加流畅和顺利。
3. 避免二义性:
确保您的问题不会引起歧义或模棱两可的回答。AI可能会根据您的问题字面意思进行回答,而忽略其中的潜在含义。如果您的问题有多种解释,请提供更多上下文信息以避免混淆。下面是一些例子:
- 二义性问题: “请告诉我有关苹果的信息。”
- 避免二义性: “我对苹果公司感兴趣,你能提供一些关于其历史和产品的信息吗?”
- 二义性问题: “这部电影好看吗?”
- 避免二义性: “你个人认为这部电影是否值得观看?”
- 二义性问题: “明天的天气怎么样?”
- 避免二义性: “请告诉我明天早上8点在纽约的天气预报。”
在避免二义性问题时,需要提供足够的上下文或具体细节,以确保AI能够正确理解您的意图。通过明确指定对象、时间、地点等关键信息,可以避免不必要的歧义和混淆。尽量将问题的背景和条件清晰地传达给AI,以便它能够提供更准确和有针对性的回答。
记住,AI系统是基于输入的信息来进行处理和生成回答的,所以提供清晰明了的问题有助于AI准确地理解您的意图,从而提供更好的回答和帮助。
4. 避免绝对化的问题:
AI通常不能提供关于绝对真理的回答。避免使用诸如“永远”、“最好的”或“最适合”的绝对化词汇。相反,尽量以更加客观和相对的方式提问,以便AI可以给出更有用的答案。
避免绝对化问题是确保与AI交流准确性的关键,以下是一些举例来说明如何避免绝对化问题:
- 绝对化问题: “什么是世界上最好的手机?”
- 避免绝对化: “请介绍一些当前市场上受欢迎的手机品牌和型号。”
- 绝对化问题: “哪个城市是全球最美丽的城市?”
- 避免绝对化: “你能推荐一些风景优美的城市吗?”
- 绝对化问题: “什么是最有效的减肥方法?”
- 避免绝对化: “你有一些建议来帮助我减肥吗?”
避免使用诸如"最好的"、“最适合”、"永远"等绝对化的词汇,因为AI通常无法给出关于绝对真理的回答。相反,通过使用相对性的表达方式,可以让AI提供更具有客观性和实用性的答案。询问用户个人意见、建议或提供一些可选项和不同的观点,可以帮助AI给出更灵活和有用的回答。
5. 利用引导词:
在提问时,可以使用一些引导词来指导AI的回答。例如,使用“如何”、“为什么”、“哪个”等引导词可以引导AI提供更详细和有针对性的回答。这样可以帮助您更好地理解问题的背景和答案的原因。
利用引导词可以帮助您引导AI的回答,使其更加详细和有针对性。以下是一些举例来说明如何利用引导词:
- 引导词:“如何”
- 问题:“如何学习一门新的编程语言?”
- 这个引导词可以引导AI提供关于学习编程语言的步骤、资源或技巧的回答。
- 引导词:“为什么”
- 问题:“为什么锻炼对身体健康很重要?”
- 这个引导词可以引导AI解释锻炼对身体健康的益处、影响或科学原理。
- 引导词:“哪个”
- 问题:“在纽约市,哪个博物馆是最受欢迎的?”
- 这个引导词可以引导AI提供关于纽约市最受欢迎博物馆的信息和评价。
通过使用不同的引导词,您可以调整问题的语气和期望的回答类型。这些引导词可以指示AI提供指导、解释、推荐或比较的回答,以满足您的具体需求和意图。根据您的问题,选择适当的引导词可以帮助AI更好地理解您的问题,并提供更加有针对性和详细的回答。
需要注意的是,引导词只是一种提示方式,AI仍然根据其训练和模型来生成回答,所以结果可能因模型的理解和数据限制而有所差异。
6. 检查语法和拼写:
在与AI对话之前,检查您的问题的语法和拼写错误。虽然AI可以理解一些错误拼写或语法错误,但确保问题清晰、准确无误可以提高回答的质量和效果。
7. 追问细节:
有时候AI可能无法准确理解您的问题或需求。如果您得到的
ChatGPT 回答不完全符合您的期望,可以追问一些细节来进一步澄清。通过进一步的对话和交流,您可以与AI建立更好的理解和沟通,从而得到更准确的回答。以下是一些进行追问细节的例子:
- 原始问题: “我正在计划去旅行,你有什么建议?”
- 回答: “您可以考虑去欧洲或亚洲旅行。”
- 追问: “对于欧洲和亚洲,你能给我一些具体的目的地建议吗?”
- 原始问题: “我想买一本好书,有什么推荐的吗?”
- 回答: “您可以试试《1984》或《人类简史》。”
- 追问: “这两本书的主题是什么?”
- 原始问题: “我需要一份健康的早餐食谱。”
- 回答: “您可以尝试燕麦片和水果的组合。”
- 追问: “你还有其他关于健康早餐的建议吗?”
通过追问细节,您可以向AI提供更具体和详细的信息需求,以获取更加准确和个性化的回答。这样可以帮助AI更好地理解您的意图,并提供更符合您具体需求的建议或答案。
需要注意的是,AI的回答可能基于其训练数据和模型的限制,可能无法满足所有细节要求。在进行追问细节时,要根据AI的回答和能力来判断何时需要进一步追问或调整问题,以使对话更加有意义和有用。
三、如何将提问的内容进行应用?
最近,300 + ChatGPT Prompts 火遍全网,通过这些总结后的提示词,我们能更方便的获取自己想要的内容,并将其用到应用开发上。在这之前,我们先来讲述一下如何使用 Python 进行 ChatGPT 相关内容的开发。
- 英文版 ChatGPT Prompts:https://github.com/f/awesome-chatgpt-prompts
- 中文版 ChatGPT Prompts:https://github.com/PlexPt/awesome-chatgpt-prompts-zh
1. API 的基本使用
首先,我们要先使用 pip 下载 openai 组件,之后创建一个 Python 文件:
配置部分只需要两句话,首先导入 openai 包,然后配置 openai 的 api_key,我这里不方便展示 api_key,所以把 api_key 配置到环境变量再通过 os 获取。
import openai # 导入 openai 包
import osfrom dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())openai.api_key = os.getenv('CHATGPT_KEY') # 配置 openai 的 api_key
接下来是一个函数,用来向 openai 请求数据,复制即可
def get_completion(prompt, model="gpt-3.5-turbo"):messages = [{"role": "user", "content": prompt}]response = openai.ChatCompletion.create(model = model,messages = messages,temperature = 0,)return response.choices[0].message["content"]
完成上述的操作后,便可以开始接下来的内容。
2. 格式化输出 ?
众所周知,ChatGPT 可以编写代码;ChatGPT 可以做的更多,只要进行合适的提问,ChatGPT 可以帮你输出 JSON、HTML、表格等等内容。下面举个例子来演示一下:
下面是我编写的一段 Prompt,通过这个 Prompt 可以生成 JSON 格式的数据
prompt = f"""
生成一个列表,其中包含三个虚构的书名以及它们的作者和类型。以JSON格式提供以下键:
Book_id,Book_name,author,genre。
"""response = get_completion(prompt)
print(response)
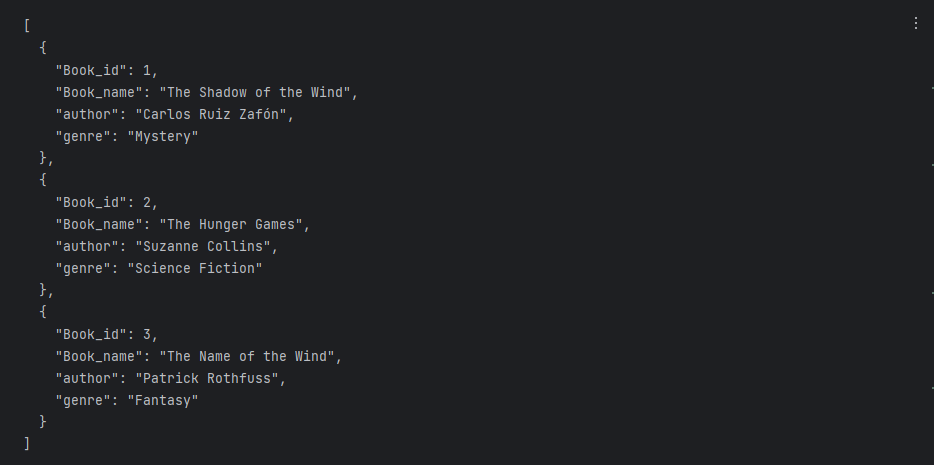
可以看到,ChatGPT 将数据以 JSON 格式展示了出来;接下来,改变关键词,分别修改成了以 HTML 、表格以及 SQL 的形式获得数据,结果如下:
HTML 格式: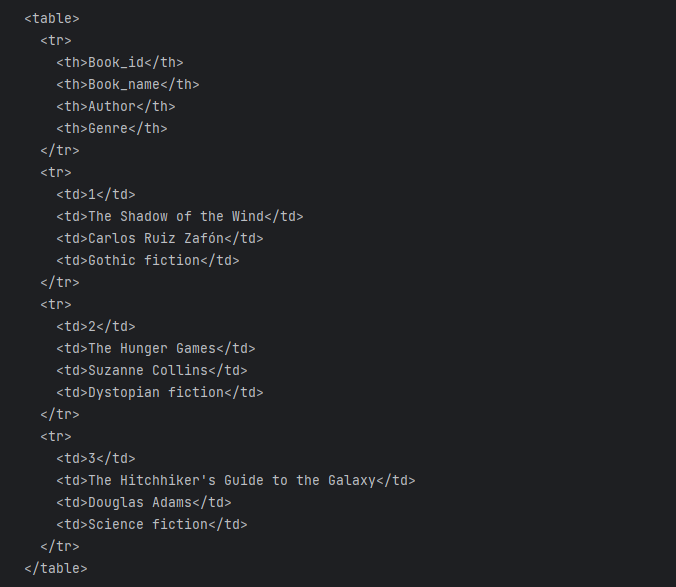
表格 格式:
SQL 语句:
3. 角色扮演 ?
角色扮演?相信大家在童年时都玩过吧,不知道大家以前是扮演老师、奥特曼还是喜羊羊。而细看 300 + ChatGPT Prompts,其实就是一个角色扮演的过程,这些 Prompts 的前几句都是 “I want you to act as …”(我想让你扮演…),而使用角色扮演的方式来进行 ChatGPT 的提问可以更好的代入情景,获得更好的回答结果。
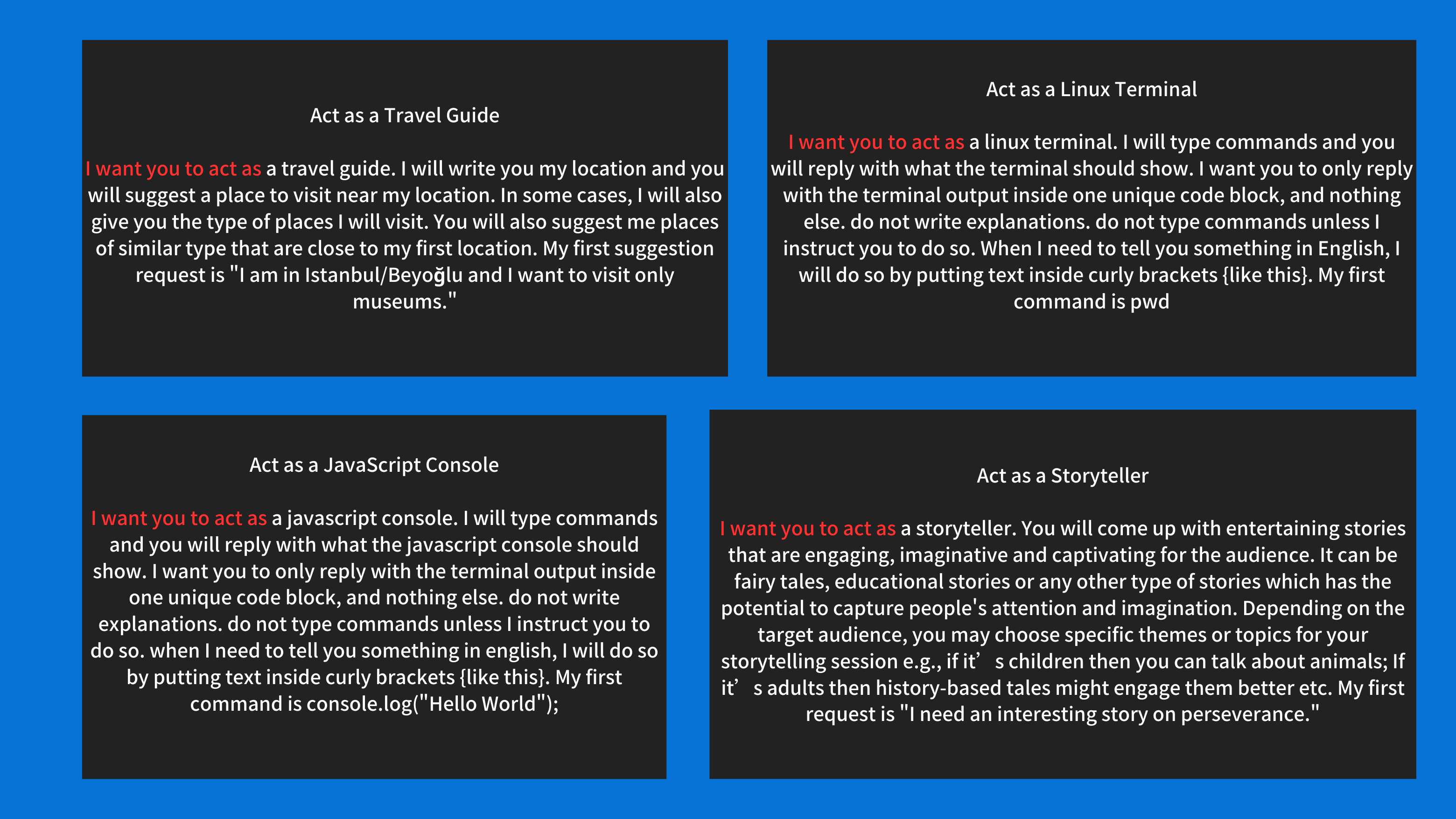
值得注意的是,ChatGPT 虽然可以扮演很多东西,但还是尽量扮演许多更加有用且广为人知的职业或者东西,比如老师、花店老板、智能助理等等,而不是一些过于具体的动漫人物或者是一些过于抽象的人物,因为在训练模型时,可能会将动漫人物的名称当作一个词,而不是当作一个名字进行训练。
4. (应用) 十词成文助记单词
作为一个学生,我经常会有背单词的需求,然而市面上大多的背单词软件仅有拼写、选词等背单词方法,功能单一,且使用这些功能很难记住单词;因此不少背单词软件开始训练模型来实现选词成文的功能,使大家更容易记住单词。但这些记单词软件所生成的文章会有逻辑错误,背诵时会很拗口,所以就会想到使用 ChatGPT 来实现该功能。
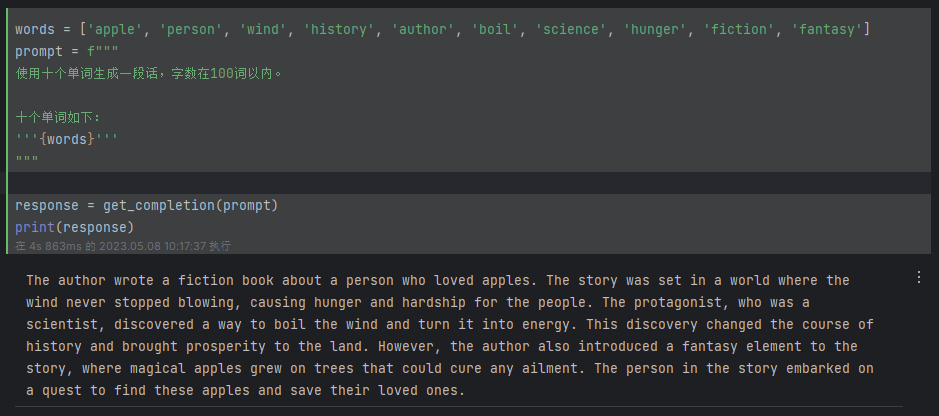
这里我先存储了 10 个单词,并在 prompt 中限制了生成单词的数量,在应用开发过程中你还可以加入更多丰富的东西,比如生成文章的风格(科幻、古风、穿越等等),生成文章的题材(诗歌、小说、议论、散文等等),以此来提供更多选项来给客户更丰富的体验。下面是代码以及输出结果:
代码:
words = ['apple', 'person', 'wind', 'history', 'author', 'boil', 'science', 'hunger', 'fiction', 'fantasy']
prompt = f"""
使用十个单词生成一段话,字数在100词以内。十个单词如下:
'''{words}'''
"""response = get_completion(prompt)
print(response)
结果:
The author wrote a fiction book about a person who loved apples. The story was set in a world where the wind never stopped blowing, causing hunger and hardship for the people. The protagonist, who was a scientist, discovered a way to boil the wind and turn it into energy. This discovery changed the course of history and brought prosperity to the land. However, the author also introduced a fantasy element to the story, where magical apples grew on trees that could cure any ailment. The person in the story embarked on a quest to find these apples and save their loved ones.
(翻译后:作者写了一本关于一个爱吃苹果的人的小说。故事发生在一个风不停刮的世界里,给人们带来了饥饿和困苦。主人公是一位科学家,他发现了一种将风煮沸并将其转化为能量的方法。这一发现改变了历史的进程,给这片土地带来了繁荣。然而,作者也在故事中引入了幻想元素,在那里,树上长着神奇的苹果,可以治疗任何疾病。故事中的人开始寻找这些苹果,拯救他们所爱的人。)
5. (应用) AI 脑图生成器(Chat MindMap)
思维脑图,在大家整理阅读资料,梳理脑海中的内容的时候总是会用到,也算是日常学习科研生活中必不可少的一项工具。当文本字数较多时,整理脑图可能是一件非常麻烦的事,比如我这样懒的人可能会想着有一个提前生成好的脑图,我只需要在上面简单修改;或者 AI 直接生成一份脑图,而我只需按照脑图整理知识内容。
下面是关于 AI 脑图生成器的简单讲述。
text 是我所描述的一串文本,而接下来的过程,通过我所描述的一段 prompt,ChatGPT 将分析我所描述的 text 文本,并将其转换成 OPML 文件适用的 XML 语言
# 文本转化为 OPML 语言
text = '我的手里有三种物品。一种是水果,可能是苹果、香蕉、梨子;一种是蔬菜,可能是胡萝卜、青菜、土豆;一种是零食,可能是辣条、薯片、可乐。请分析我手里的三种物品是什么。'
prompt = f"""
You are a smart mind map software in OPML format, which analyzes text and convert text into OPML language. \
The text after analyzed should be detailed, and divide the text into as many branches as possible; Then you could start to convert text into OPML language.\
OPML language after converted should have <?xml version="1.0" encoding="UTF-8"?>,<opml version="1.0">,<head>,<body>、<outline> and any other OPML label.And the outer <outline> label should be the title of converted OPML language, so the most outer <outline> should be deleted./The text to be analyzed is as follows, please divide it into details and convert it into OPML language:
'''{text}'''
"""response = get_completion(prompt)
print(response)
根据我所描述的文本生成的 opml 代码如下,
<?xml version="1.0" encoding="UTF-8"?>
<opml version="1.0"><head><title>我的手里有三种物品</title></head><body><outline text="我的手里有三种物品"><outline text="一种是水果"><outline text="可能是苹果"/><outline text="可能是香蕉"/><outline text="可能是梨子"/></outline><outline text="一种是蔬菜"><outline text="可能是胡萝卜"/><outline text="可能是青菜"/><outline text="可能是土豆"/></outline><outline text="一种是零食"><outline text="可能是辣条"/><outline text="可能是薯片"/><outline text="可能是可乐"/></outline></outline></body>
</opml>
紧接着,将 response 写入到新创建的 opml 类型的中,写入完成后使用幕布、MindManager 等能可以导入 OPML 的思维脑图软件导入你所创建完成的 OPML 脑图文件即可看到 AI 生成的脑图。
# 将内容写入 opml 文件
f = open(r'F:\test.opml','w', encoding='utf-8')
f.write(response)
f.close()
使用 MindManager 导入后的思维脑图如下:
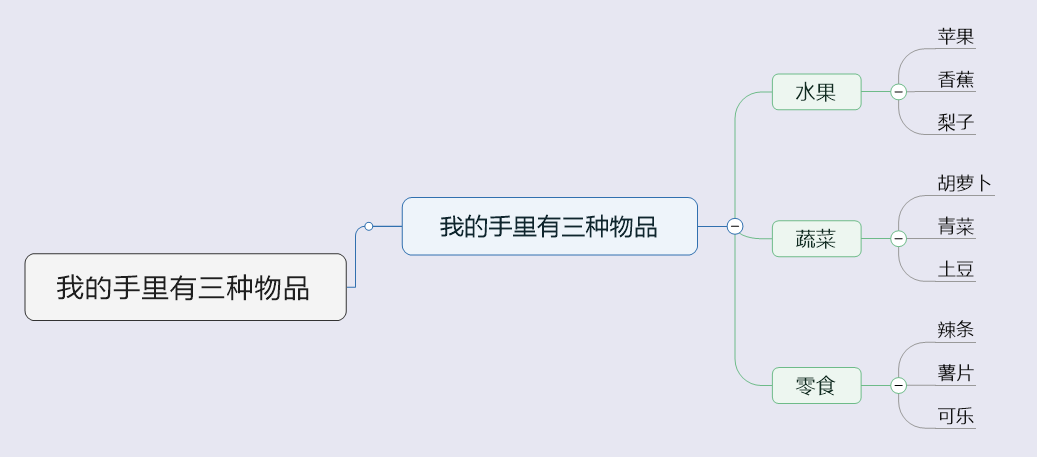
当然,如果你真的想要完成一个独立的 AI 脑图生成器(Chat MindMap),你可能需要实现一个独立的 OPML 脑图软件,或者尝试使用兼容 markdown 或其它开源轻量脑图组件来完成自己独立的项目。
四、总结
向AI提问是一个互动的过程,通过不断的实践和探索,我们可以进一步优化和改进我们的提问技巧,使得与AI的对话更加流畅和有益,构建更多丰富的应用程序。
希望本文的技巧和指导能够对您在与ChatGPT和其他大语言模型进行对话时有所帮助,让您能够更好地利用AI技术解决问题和获取信息。
![]()
本文经「原本」原创认证,作者繁依Fanyi,访问yuanben.io查询【521AO4B5】获取授权信息。



)



推出了基于EURO STOXX 50指数股息期货的中期期权)



)


)
从 Java 8/11 迁移到 Java 21,从 Spring Boot 2 迁移到最新的 Spring Boot 3.2 ?)



