在排查生产环境的性能问题时,以下是一些常见的步骤和技巧:
-
监控系统资源:使用系统监控工具(如top、htop、nmon等)来监控服务器的CPU使用率、内存使用率、磁盘IO等系统资源情况。这可以帮助你了解系统的整体负载情况,是否存在资源瓶颈。
-
分析日志:查看应用程序的日志文件,特别是错误日志和性能日志。错误日志可以帮助你找到潜在的问题,而性能日志可以提供关于请求处理时间、数据库查询时间等信息,帮助你定位性能瓶颈。
-
使用性能分析工具:使用性能分析工具(如JProfiler、VisualVM等)来分析应用程序的性能瓶颈。这些工具可以提供线程分析、内存分析、CPU分析等功能,帮助你找到性能瓶颈所在。
-
进行代码审查:审查应用程序的代码,特别是关键路径和频繁执行的代码。检查是否存在低效的算法、重复的数据库查询、频繁的IO操作等问题。
-
进行压力测试:使用压力测试工具(如JMeter、Apache Bench等)对应用程序进行压力测试,模拟多用户并发访问场景。观察系统的响应时间、吞吐量等指标,找出性能瓶颈。
-
调整JVM参数:根据应用程序的需求和服务器的配置,调整JVM参数来优化性能。例如,调整堆内存大小、垃圾收集器类型和参数、线程池大小等。
-
数据库优化:如果应用程序使用数据库,优化数据库查询语句、索引、连接池等,以提高数据库的性能。
-
分布式追踪:使用分布式追踪工具(如Zipkin、Jaeger等)来追踪分布式系统中的请求流程,找出请求处理过程中的性能瓶颈。
以上是一些常见的排查生产环境性能问题的步骤和技巧。在实际操作中,需要根据具体的情况和需求来选择合适的方法和工具。同时,建议在生产环境中进行性能调优时,谨慎操作,确保不会对系统的稳定性和安全性造成影响。
查看服务器的系统性能
top
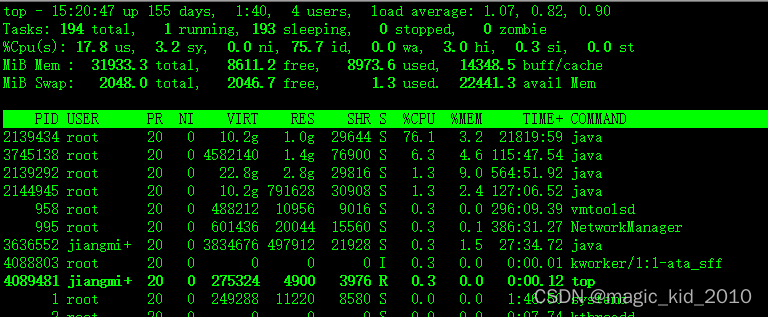
- 第一行代表任务队列信息
top - 15:22:47 系统时间
up 155 days, 1:40 机器运行了 155 天,1小时40分
4 users 当前登录用户 4 个
load average: 1.07, 0.82, 0.90 代表负载均衡,后面的 3 个数分别代表 1 分钟、5 分钟、15 分钟的负载情况。
- 第二行代表任务进程的情况
总进程 194 个,运行 1 个,休眠 193 个,停止 0 个,僵尸进程 0 个
- 第三行代表 CPU 状态信息
- us(user):表示用户空间进程使用CPU的百分比,即用户态CPU使用率。
- sy(system):表示内核空间进程使用CPU的百分比,即内核态CPU使用率。
- ni(nice):表示以较低优先级运行的用户进程使用CPU的百分比。
- id(idle):表示CPU处于空闲状态的百分比。
- wa(waiting):表示CPU等待IO操作完成的百分比。
- hi(hardware interrupt):表示硬件中断占用CPU的百分比。
- si(software interrupt):表示软件中断占用CPU的百分比。
- st(steal time):表示被虚拟化环境(如云服务器)偷取的CPU时间的百分比。
17.8%的CPU时间被用户空间进程使用,3.2%的CPU时间被内核空间进程使用,75.7%的CPU时间处于空闲状态,0.0%的CPU时间等待IO操作完成,3.0%的CPU时间被硬件中断占用,0.3%的CPU时间被软件中断占用,没有被虚拟化环境偷取的CPU时间。
- 第四行代表内存状态
- MiB Mem:表示系统的物理内存总量。
- total:表示物理内存的总大小,单位为MiB。
- free:表示未被使用的内存大小,单位为MiB。
- used:表示已被使用的内存大小,单位为MiB。
- buff/cache:表示用于缓存的内存大小,单位为MiB。
在给出的示例中,系统的物理内存总量为31933.3 MiB。其中,8611.2 MiB的内存是空闲的,8973.6 MiB的内存被使用了,而14384.5 MiB的内存被用于缓存。
- 第五行代表 swap 交换分区信息
- MiB Swap:表示系统的交换空间总量。
- total:表示交换空间的总大小,单位为MiB。
- free:表示未被使用的交换空间大小,单位为MiB。
- used:表示已被使用的交换空间大小,单位为MiB。
- avail Mem:表示可用内存的大小,单位为MiB。
在给出的示例中,系统的交换空间总量为2048.0 MiB。其中,2046.7 MiB的交换空间是空闲的,只有1.3 MiB的交换空间被使用了。可用内存的大小为22441.3 MiB。
交换空间是一种在物理内存不足时,将部分内存数据写入磁盘的机制。当系统的物理内存不足时,操作系统会将不常用的内存数据移至交换空间,以释放物理内存供其他进程使用。然而,交换空间的使用会导致较









—文件读取与存储》)


)
)




)
