《汇编语言》- 读书笔记 - 各章检测点归档
- 检测点 1.1
- 检测点 2.1
- 检测点 2.2
- 检测点 2.3
- 检测点 3.1
- 检测点 3.2
- 检测点 6.1
- 检测点 9.1
检测点 1.1
-
1个CPU 的寻址能力为8KB,那么它的地址总线的宽度为 13 。
解:8KB = 8192B= 213 -
1KB的存储器有 1024 个存储单元。存储单元的编号从 0 到 1023 。
解:一个存储单元可以存储一个Byte。 1KB = 1024B。从 0 开始算所以是 0到1023共1024个。 -
1KB 的存储器可以存储 2^13=8192 个bit, 2^10=1024 个 Byte。
解:8bit=1Byte,1024Byte=1KB。
1KB = 1bit * 8 * 1024 = 8192bit
1KB = 1Byte * 1024 = 1024Byte -
1GB、1MB、1KB分别是 1,073,741,824、1,048,576、1024 Byte。
解:230=1,073,741,824; 220=1,048,576; 210=1024 -
8080、8088、80286、80386 的地址总线宽度分别为16根、20根、24根、32根,则它们的寻址能力分别为: 64 (KB)、 1 (MB)、 16 (MB)、 4 (GB)
解:寻址能力=2(地址总线宽度)(CPU地址总线宽度,决定了它最多可以访问多大的内存地址范围。也就是它的寻址能力。
216-10=64;(B转KB:16-10,最终 26=64)
220-20=1; (B转KB:20-10,KB转MB:10-10,最终 20=1)
224-20=16;(B转KB:24-10,KB转MB:14-10,最终 24=16)
232-30=4; (B转KB:32-10,KB转MB:22-10,MB转GB:12-10,最终 22=4) -
8080、8088、8086、80286、80386 的数据总线宽度分别为8根、8根、16根、16根、32根。则它们一次可以传送的数据为: 1 (B)、 1 (B)、 2 (B)、 2 (B)、 4 (B)。
解:一根总线要么传高电平1,要么传低电平0,有几线就能同时传几个bit。
8bit=1Byte。 -
从内存中读取
1024字节的数据,8086至少要读 512 次,80386至少要读 256 次。
解:8086数据总线宽度16,一次传2B,1024 / 2 =512
80386数据总线宽度32,一次传4B,一次传2B,1024 / 4 =256 -
在存储器中,数据和程序以 二进制 形式存放。
检测点 2.1
- 写出每条汇编指令执行后相关寄存器中的值。
| 汇编指令 | 指令执行后相关寄存器中的值 | 说明 |
|---|---|---|
| mov ax, 62627 | AX= F4A3H | 62627 转16进制=F4A3H |
| mov ah, 31H | AX=31A3H | 修改AX的高8位为 31H |
| mov al, 23H | AX=3123H | 修改AX的低8位为 23H |
| add ax, ax | AX=6246H | 3123 + 3123 = 6246H |
| mov bx, 826CH | AX=6246H, BX=826CH | |
| mov cx, ax | AX=6246H, BX=826CH, CX=6246H | |
| mov ax, bx | AX=826CH, BX=826CH, CX=6246H | |
| add ax, bx | AX=04D8H, BX=826CH, CX=6246H | |
| mov al, bh | AX=0482H, BX=826CH, CX=6246H | 修改 ax 的低8位 = bx 的高8位 |
| mov ah, bl | AX=6C82H, BX=826CH, CX=6246H | 修改 ax 的高8位 = bx 的低8位 |
| add ah, ah | AX=D882H, BX=826CH, CX=6246H | ax 高8位相加: 6C + 6C = D8H |
| add al, 6 | AX=D888H, BX=826CH, CX=6246H | ax 低8位 + 6:82 + 6 = 88H |
| add al, al | AX=D810H, BX=826CH, CX=6246H | ax 低8位相加:88 + 88 = 110H;0001 0001 0000高4位溢出丢失。ax = 10H; |
| mov ax, cx | AX=6246H, BX=826CH, CX=6246H |
- 只能使用目前学过的汇编指令,最多使用 4条指令,编程计算 2的4次方。
| 指令 | ax值 |
|---|---|
| mov ax, 2 | 2 |
| add ax, ax | 2+2=4 |
| add ax, ax | 4+4=8 |
| add ax, ax | 8+8=16 |
检测点 2.2
-
给定段地址为 0001H,仅通过变化偏移地址寻址,CPU 的寻址范围为 00010H 到 1000FH 。
解:物理地址 =段地址 x 16 + 偏移地址。偏移地址的范围是从0000到FFFF。
0001H * 16 = 00010H。此CPU的寻址范围是00010H + 0000H到00010H + FFFFH=00010H到1000FH -
有一数据存放在内存
20000H单元中,现给定段地址为SA,若想用偏移地址寻到此单元。则 SA 应满足的条件是: 最小为 1001H ,最大为 2000H 。
提示,反过来思考一下,当段地址给定为多少,CPU 无论怎么变化偏移地址都无法寻到 20000H单元?
解:
| 步骤 | SA 最小 | SA 最大 |
|---|---|---|
| 1 | min * 16 + FFFFH = 20000H | max * 16 + 0000H = 20000H |
| 2 | min * 16 = 20000H - FFFFH (偏移地址最大时,段地址最小) | max * 16 + 0000H = 20000H |
| 3 | min = 10001H ÷ 16 | max = 20000H ÷ 16 |
| 4 | min = 0001 0000 0000 0000 0001B >> 4 | max = 0010 0000 0000 0000 0000B >> 4 |
| 5 | min = 0001 0000 0000 0000. 0001B | max = 0000 0010 0000 0000 0000B |
| 6 | min = 1000.1H(我靠除不尽。根物理地址计算公式,可知段地址必是个整数) | max = 2000H (得到最大值) |
| 7 | 倒回第2步,我们调整一下 20000H - FFFFH 的结果,让它能被16整除。如何调整呢?分析: 已知: 20000H是题目给定的条件,不能动。只能调FFFFH。同时 FFFFH已经是偏移地址最大值,尝试的方向只有减小它。FFFFH减多10001H就往上涨多少。调到能整除16为止。那么看一下 10001H加多少能被16整除呢?直接看 2进制,除以16就是右移4位。10001H = 0001 0000 0000 0000 0001B最近一个 >>4不丢精度的数是: 0001 0000 0000 0001 0000B = 10010H10010H - 10001H = 0000FH所以偏移量的最大值应该是: FFFFH - 000FH = FFF0H分析完毕,开始计算: | |
| 8 | min * 16 = 20000H - FFF0H | |
| 9 | min = 10010H ÷ 16 | |
| 10 | min = 1001H (得到最小值) |
找 FFF0H 的过程,穷举一下更直观
="20000H - "&DEC2HEX(65536-ROW())&"H" = =DEC2HEX(E1)&"H" | =131072-65536+ROW() | =E1&" ÷ 16 = "&E1/16
| 减小偏移地址 | 十进制 | 检查整除 |
|---|---|---|
| 20000H - FFFFH = 10001H | 65537 | 65537 ÷ 16 = 4096.0625 |
| 20000H - FFFEH = 10002H | 65538 | 65538 ÷ 16 = 4096.125 |
| 20000H - FFFDH = 10003H | 65539 | 65539 ÷ 16 = 4096.1875 |
| 20000H - FFFCH = 10004H | 65540 | 65540 ÷ 16 = 4096.25 |
| 20000H - FFFBH = 10005H | 65541 | 65541 ÷ 16 = 4096.3125 |
| 20000H - FFFAH = 10006H | 65542 | 65542 ÷ 16 = 4096.375 |
| 20000H - FFF9H = 10007H | 65543 | 65543 ÷ 16 = 4096.4375 |
| 20000H - FFF8H = 10008H | 65544 | 65544 ÷ 16 = 4096.5 |
| 20000H - FFF7H = 10009H | 65545 | 65545 ÷ 16 = 4096.5625 |
| 20000H - FFF6H = 1000AH | 65546 | 65546 ÷ 16 = 4096.625 |
| 20000H - FFF5H = 1000BH | 65547 | 65547 ÷ 16 = 4096.6875 |
| 20000H - FFF4H = 1000CH | 65548 | 65548 ÷ 16 = 4096.75 |
| 20000H - FFF3H = 1000DH | 65549 | 65549 ÷ 16 = 4096.8125 |
| 20000H - FFF2H = 1000EH | 65550 | 65550 ÷ 16 = 4096.875 |
| 20000H - FFF1H = 1000FH | 65551 | 65551 ÷ 16 = 4096.9375 |
20000H - FFF0H = 10010H | 65552 | 65552 ÷ 16 = 4097 |
反过来思考一下:段地址小于 1001H 或 大于2000H时,CPU无论怎么变化偏移地址都无法寻到 20000H单元。
检测点 2.3
下面的 3 条指令执行后,CPU 几次修改 IP? 都是在什么时候? 最后 IP 中的值是多少?
mov ax, bx
sub ax, ax
jmp ax
解:
mov 指令将bx中的数据送到ax中。指令本身不会修改IP。
sub 指令将两个操作数的相减,即从op1中减去op2,其结果放在op1中。指令本身不会修改IP。
jmp 指令将无条件地控制程序转移到目的地址去执行。jmp 指令会修改IP。
jmp ax 将 ax 的值传给 ip
- 总共 IP 被 修改了4 次。
- 读取每条指令后IP修改一次一起3次,执行 jmp ax 会修改 IP 1次。
- 最后 IP 中的值是 0 (因为
sub ax, ax后 ax 的值就是 0 了)

检测点 3.1
-
- 在Debug中,用
d 0:0 1F查看内存,结果如下:
- 在Debug中,用
0000:0000 70 80 F0 30 EF 60 30 E2-00 80 80 12 66 20 22 60
0000:0010 62 26 E6 D6 CC 2E 3C 3B-AB BA 00 00 26 06 66 88
下面的程序执行前,AX=0,BX=0,写出每条汇编指令执行完后相关寄存器中的值。
解:
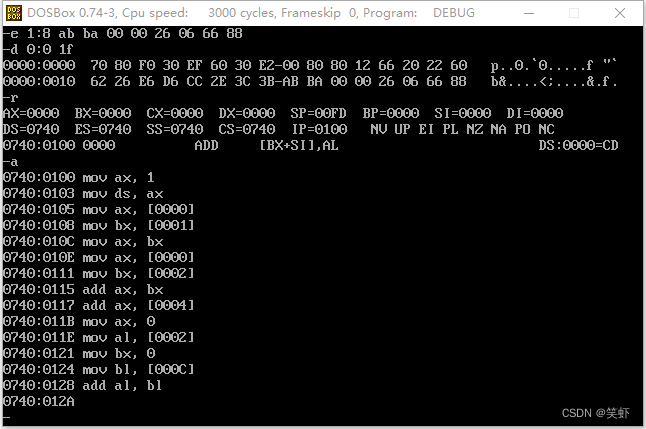
| 指令 | 寄存器值 |
|---|---|
| mov ax, 1 | |
| mov ds, ax | |
| mov ax, [0000] | AX=2662 |
| mov bx, [0001] | BX=E626 |
| mov ax, bx | AX=E626 |
| mov ax, [0000] | AX=2662 |
| mov bx, [0002] | BX=D6E6 |
| add ax, bx | AX=FD48 |
| add ax, [0004] | AX=2C14 |
| mov ax, 0 | AX=0000 |
| mov al, [0002] | AX=00E6 |
| mov bx, 0 | BX=0000 |
| mov bl, [000C] | BX=0026 |
| add al, bl | AX=000C |
-
- 内存中的情况如图 3.6 所示。
各寄存器的初始值: CS=2000H,IP=0,DS=1000H,AX=0,BX=0;
- 内存中的情况如图 3.6 所示。
- 写出 CPU 执行的指令序列(用汇编指令写出)。
- 写出 CPU 执行每条指令后,CS、IP 和相关寄存器中的数值。
- 再次体会: 数据和程序有区别吗?如何确定内存中的信息哪些是数据,哪些是程序?

解:
| 指令 | CS | IP | DS | AX | BX |
|---|---|---|---|---|---|
| 开始 | 2000 | 0000 | 1000 | 0000 | 0000 |
| mov ax, 6622H | 0003 | 6622 | |||
| jmp 0ff0:0100 | 1000 | 0000 | |||
| mov ax, 2000H | 0003 | 2000 | |||
| mov ds, ax | 0005 | 2000 | |||
| mov ax, [0008] | 0008 | C389 | |||
| mov ax, [0002] | 000B | EA66 | |||
| 结束 | 1000 | 000B | 2000 | EA66 | 0000 |
数据和程序在内存中都是机器码没有区别。
CS:IP 指向的就当指令用。
DS:[addr]指向就当数据用。
检测点 3.2
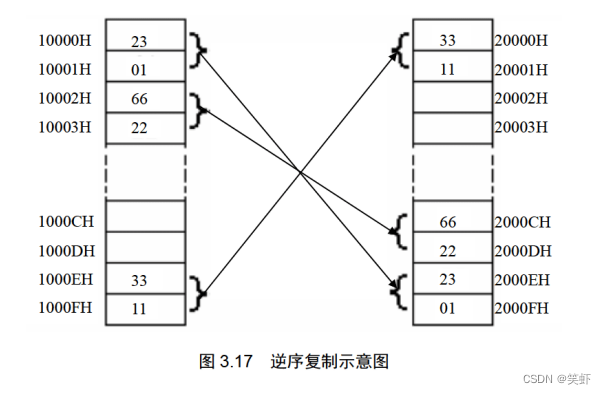
- 补全下面的程序,使其可以将
10000H~1000FH中的 8 个字,逆序复制到20000H~2000FH中。逆序复制的含义如图 3.17 所示(图中内存里的数据均为假设)。
mov ax, 1000H
mov ds, ax
mov ax, 2000H ; 设置栈段地址
mov ss, ax
mov sp, 0010H ; sp指向空栈时的位置
push [0]
push [2]
push [4]
push [6]
push [8]
push [A]
push [B]
push [C]
- 补全下面的程序,使其可以将
10000H~1000FH中的 8 个字,逆序复制到20000H~2000FH中。
mov ax, 2000H
mov ds, ax
mov ax, 1000H
mov ss, ax
mov sp, 0000H ; 栈顶指向 1000:0000 礼成
pop [E]
pop [C]
pop [B]
pop [A]
pop [8]
pop [6]
pop [4]
pop [2]
pop [0]
检测点 6.1
- 下面的程序实现依次用内存
0:0~0:15单元中的内容改写程序中的数据,完成程序:
assume cs:code
code segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h ; cs:0~15start: mov ax, 0mov ds, ax mov bx, 0mov cx, 8s: mov ax:[bx] mov cs:[bx], ax ; 将数据逐个送到 cs:[0]到 cs:[15]add bx, 2loop s mov ax, 4c00h int 21h
code ends
end start
- 下面的程序实现依次用内存
0:0~0:15单元中的内容改写程序中的数据,数据的传送用栈来进行。栈空间设置在程序内。完成程序:
assume cs:code
code segmentdw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h ; cs:00~0Fdw 1,2,3,4,5,6,7,8,9,10 ; cs:10~23
start: mov ax, cs ; 栈段就是代码段mov ss, ax mov sp, 24h ; 指向栈顶 cs:22 + 2mov ax, 0mov ds, axmov bx, 0mov cx, 8s: push [bx] pop cs:[bx] ; 数据出栈就送到 cs:[0]到 cs:[15]add bx, 2loop s mov ax, 4c00h int 21h
code ends
end start
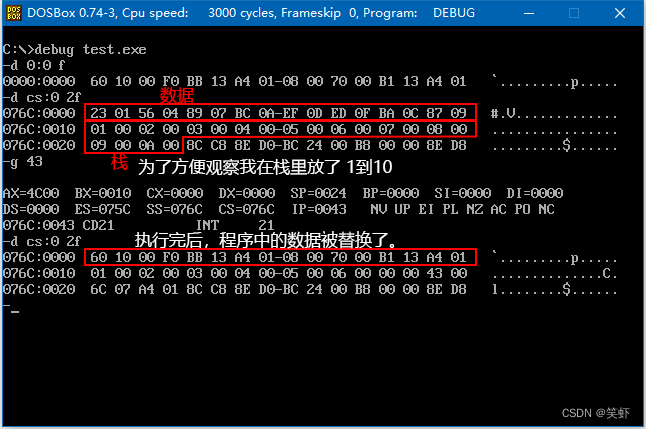
这里用栈做中转,其实只要一个字(16)字节的空间就够了。
检测点 9.1
- 程序如下
assume cs:codedata segment?
data endscode segmentstart: mov ax,datamov ds,axmov bx,0jmp word ptr [bx+1]
code ends
end start
若要使程序中的 jmp 指令执行后,CS:IP 指向程序的第一条指令,在 data 段中应该定义哪些数据?
解:
assume cs:codedata segmentdb 00 ; data 段的第1个字节,值随意dw offset start ; data 段的第2、3两个字节保存标号 start 的偏移地址
data endscode segmentstart: mov ax,datamov ds,axmov bx,0jmp word ptr [bx+1] ; bx 的值是 0 ,所以最终从 ds:[1] 处读偏移地址。长度 1 word
code ends
end start
分析:
jmp word ptr 从指定内存处读取一个字,修改偏移地址IP。
jmp word ptr [bx+1] 中 [bx+1] 实际值为 [1],表示从数据段的第2、3两个字节读取偏移地址 修改 IP,
所以只要取得标号 start 的偏移地址存在 ds:[1] - ds:[2] 即可。
我上面用的是 offset start 获取偏移地址。但是我们知道 start 是代码的入口偏移是 0,所以直接写死也是可以的。
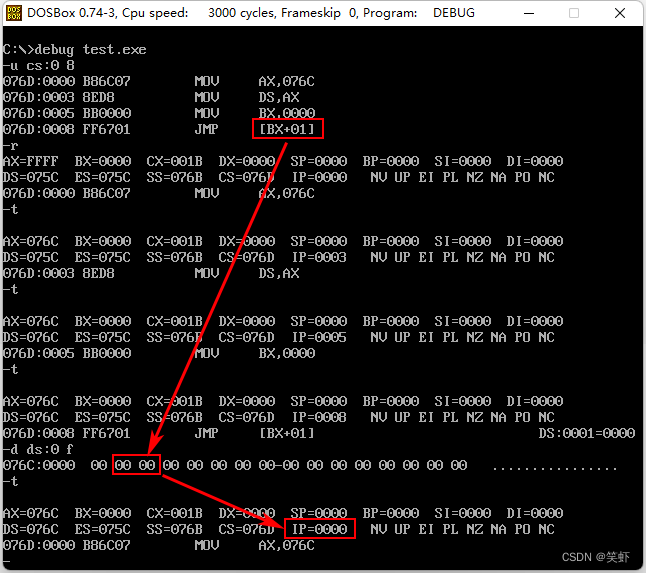
jmp word ptr [bx+1] 执行后 IP 修改成功。
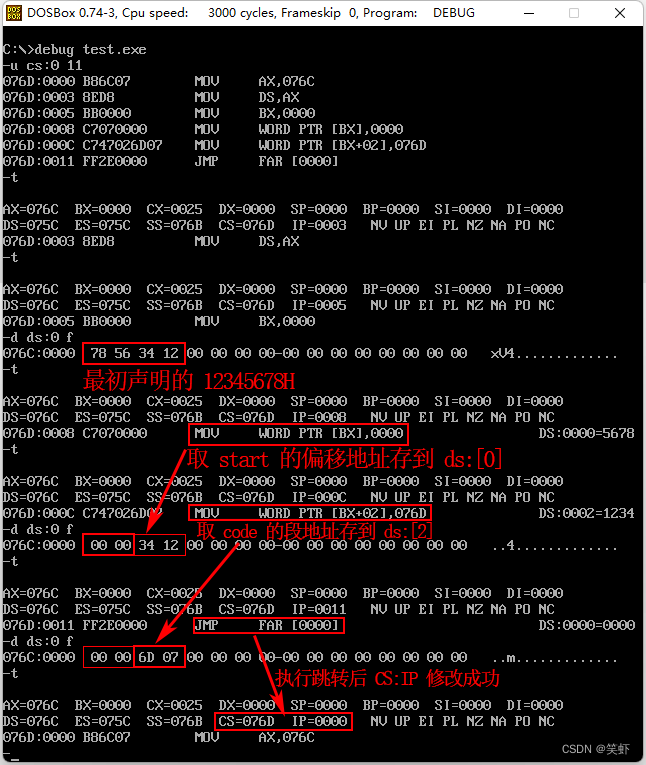
- 程序如下
assume cs:codedata segmentdd 12345678H
data endscode segmentstart: mov ax,datamov ds,axmov bx,0mov [bx],_____mov [bx+2],_____jmp dword ptr ds:[0]
code ends
end start
补全程序,使 jmp 指令执行后,CS:IP 指向程序的第一条指令
解:
assume cs:codedata segmentdd 12345678H
data endscode segmentstart: mov ax,datamov ds,axmov bx,0mov [bx], offset start ; 取偏移地址存到 ds:[0]mov [bx+2], code ; 取段地址存到 ds:[2]jmp dword ptr ds:[0]
code ends
end start
分析:
jmp dword ptr 从指定内存处读取一个双字,修改CS:IP。
data 中声明了内存空间,给 jmp 用。但值 12345678H 不是我们想要的。
正好留空的两处,供我们修改这段内存:
mov [bx], offset start:取偏移地址存到 ds:[0]
mov [bx+2], code:取段地址存到 ds:[2]
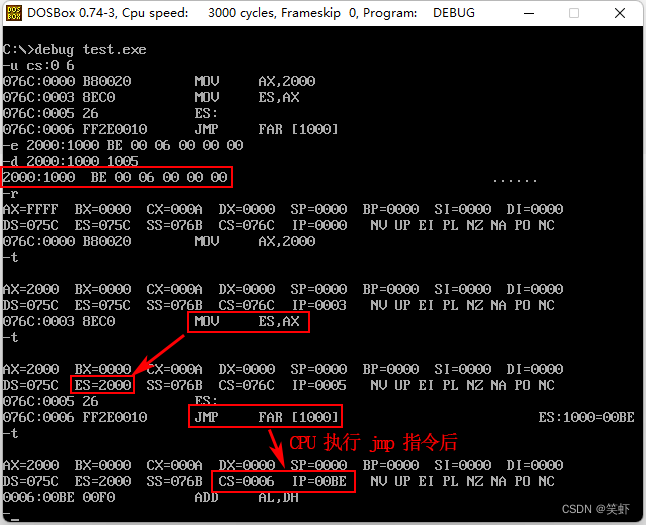
- 用 Debug 查看内存,结果如下:
2000:1000 BE 00 06 00 00 00 .....
则此时,CPU 执行指令:
mov ax,2000H
mov es,ax
jmp dword ptr es:[1000H]
后,(CS)=?,(IP)=?
解:
es:[1000H] 实际对应的内存位置是 2000H:1000H,也就是上面 Debug 查看的那段。
dword 是双字,所以对应 BE 00 06 00 这段。
(CS)=0006,(IP)=00BE

)
)


![[word] word小数点对齐怎么设置 #微信#其他#其他](http://pic.xiahunao.cn/[word] word小数点对齐怎么设置 #微信#其他#其他)
)





)






