第三章 数据类型
3.1 Key操作
3.1.1 相关命令
| 序号 | 命令语法 | 描述 |
|---|---|---|
| 1 | DEL key | 该命令用于在 key 存在时删除 key |
| 2 | DUMP key | 序列化给定 key ,并返回被序列化的值 |
| 3 | EXISTS key | 检查给定 key 是否存在,存在返回1,否则返回0 |
| 4 | EXPIRE key seconds | 为给定 key 设置过期时间,以秒计 |
| 5 | EXPIREAT key timestamp | EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳 |
| 6 | PEXPIRE key milliseconds | 设置 key 的过期时间以毫秒计 |
| 7 | PEXPIREAT key milliseconds-timestamp | 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计 |
| 8 | KEYS pattern | 查找所有符合给定模式( pattern)的 key |
| 9 | MOVE key db | 将当前数据库的 key 移动到给定的数据库 db 当中 |
| 10 | PERSIST key | 移除 key 的过期时间,key 将持久保持 |
| 11 | PTTL key | 以毫秒为单位返回 key 的剩余的过期时间 |
| 12 | TTL key | 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live) |
| 13 | RANDOMKEY | 从当前数据库中随机返回一个 key |
| 14 | RENAME key newkey | 修改 key 的名称 |
| 15 | RENAMENX key newkey | 仅当 newkey 不存在时,将 key 改名为 newkey |
| 16 | SCAN cursor [MATCH pattern] [COUNT count] | 迭代数据库中的数据库键 |
| 17 | TYPE key | 返回 key 所储存的值的类型 |
| 18 | SELECT db | 选择数据库 数据库为0-15(默认一共16个数据库) |
| 19 | DBSIZE | 查看数据库的key数量 |
| 20 | FLUSHDB | 清空当前数据库 |
| 21 | FLUSHALL | 清空所有数据库 |
| 22 | ECHO | 打印命令 |
说明: KEYS * 匹配数据库中所有key KEYS h?llo 匹配hello,hallo,hxllo等 KEYS h*llo 匹配hllo和heeello等 KEYS h[ae]llo 匹配hello和hallo
3.1.2 示例演示
127.0.0.1:6379> dbsize (integer) 0 127.0.0.1:6379> keys * (empty array) 127.0.0.1:6379> set name openlab OK 127.0.0.1:6379> get name "openlab" 127.0.0.1:6379> type name string 127.0.0.1:6379> EXISTS name (integer) 1
3.2 String
String 是 redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value。
String 类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象。
String 类型是 Redis 最基本的数据类型,String 类型的值最大能存储 512MB。
String类型一般用于缓存、限流、计数器、分布式锁、分布式Session。
3.2.1 结构图

3.2.2 相关命令
| 序号 | 语法 | 描述 |
|---|---|---|
| 1 | SET key value | 设置指定 key 的值 |
| 2 | GET key | 获取指定 key 的值 |
| 3 | GETRANGE key start end | 返回 key 中字符串值的子字符,end=-1时表示全部 |
| 4 | SETBIT key offset value | 对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit) |
| 5 | MSET key value [key value ...] | 同时设置一个或多个 key-value 对 |
| 6 | MGET key1 [key2..] | 获取所有(一个或多个)给定 key 的值 |
| 7 | GETSET key value | 将给定 key 的值设为 value ,并返回 key 的旧值(old value) |
| 8 | SETNX key value | 只有在 key 不存在时设置 key 的值 |
| 9 | STRLEN key | 返回 key 所储存的字符串值的长度 |
| 10 | MSETNX key value [key value ...] | 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在 |
| 11 | INCR key | 将 key 中储存的数字值增一 |
| 12 | DECR key | 将 key 中储存的数字值减一 |
| 13 | INCRBY key increment | 将 key 所储存的值加上给定的增量值 |
| 14 | DECRBY key decrement | 将 key 所储存的值减少给定的增量值 |
| 15 | APPEND key value | 如果 key 已经存在并且是一个字符串,APPEND 命令将指定的 value 追加到该 key 原来值 value 的末尾 |
3.2.3 示例
127.0.0.1:6379> set k1 tom OK 127.0.0.1:6379> get k1 "tom" 127.0.0.1:6379> set k1 harry OK 127.0.0.1:6379> get k1 "harry" 127.0.0.1:6379> set k2 5 OK 127.0.0.1:6379> INCR k2 (integer) 6 127.0.0.1:6379> get k2 "6" 127.0.0.1:6379> INCRBY k2 101 (integer) 107 127.0.0.1:6379> get k1 "harry" 127.0.0.1:6379> APPEND k1 Potter (integer) 11 127.0.0.1:6379> get k1 "harryPotter"
3.3 List
Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)一个列表最多可以包含 2^32^ - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
简单队列
3.3.1 结构图
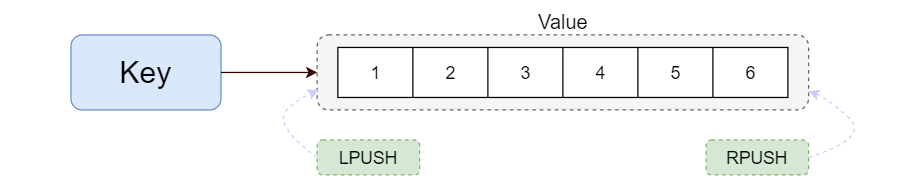
3.3.2 相关命令
| 序号 | 命令语法 | 描述 |
|---|---|---|
| 1 | LPUSH key value1 [value2] | 将一个或多个值插入到列表头部,压子弹 |
| 2 | LPOP key | 移出并获取列表的第一个元素,发射子弹 |
| 3 | LRANGE key start stop | 获取列表指定范围内的元素 |
| 4 | LPUSHX key value | 将一个值插入到已存在的列表头部 |
| 5 | LLEN key | 获取列表长度 |
| 6 | LINSERT key BEFORE|AFTER pivot value | 在列表的元素前或者后插入元素 |
| 7 | LINDEX key index | 通过索引获取列表中的元素 |
| 8 | LREM key count value | 移除列表元素 |
| 9 | LSET key index value | 通过索引设置列表元素的值 |
3.3.3 演示示例
127.0.0.1:6379> LPUSH names zhangsan lisi wangwu (integer) 3 127.0.0.1:6379> LLEN names (integer) 3 127.0.0.1:6379> LRANGE names 0 2 1) "wangwu" 2) "lisi" 3) "zhangsan" 127.0.0.1:6379> LPUSHX names louis (integer) 4 127.0.0.1:6379> LRANGE names 0 2 1) "louis" 2) "wangwu" 3) "lisi"
3.4 Set
Redis 的 Set 是 String 类型的无序(号)集合。集合中成员是唯一的,这就意味着集合中不能出现重复的数据。Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。 集合中最大的成员数为 2^32^ - 1 (4294967295, 每个集合可存储40多亿个成员)。
Set类型一般用户 好友关系 点赞 标签 等
3.4.1 结构图

3.4.2 相关命令
| 序号 | 命令语法 | 描述 |
|---|---|---|
| 1 | SADD key member1 [member2] | 向集合添加一个或多个成员 |
| 2 | SMEMBERS key | 返回集合中的所有成员 |
| 3 | SCARD key | 获取集合的成员数 |
| 4 | SRANDMEMBER key [count] | 返回集合中一个或多个随机数 |
| 5 | SISMEMBER key member | 判断 member 元素是否是集合 key 的成员 |
| 6 | SREM key member1 [member2] | 移除集合中一个或多个成员 |
| 7 | SDIFF key1 [key2] | 返回给定所有集合的差集 |
| 8 | SINTER key1 [key2] | 返回给定所有集合的交集 |
| 9 | SUNION key1 [key2] | 返回所有给定集合的并集 |
| 10 | SPOP key | 移除并返回集合中的一个随机元素 |
| 11 | SSCAN key cursor | 迭代集合中的元素 |
3.4.3 实例演示
127.0.0.1:6379> SADD course redis (integer) 1 127.0.0.1:6379> SADD course mysql (integer) 1 127.0.0.1:6379> SADD course redis (integer) 0 127.0.0.1:6379> SADD course mongodb (integer) 1 127.0.0.1:6379> SMEMBERS course 1) "mongodb" 2) "mysql" 3) "redis" 127.0.0.1:6379> SRANDMEMBER course "mongodb" 127.0.0.1:6379> SRANDMEMBER course "redis" 127.0.0.1:6379> SRANDMEMBER course "mysql" 127.0.0.1:6379> SRANDMEMBER course "mongodb" 127.0.0.1:6379> SRANDMEMBER course "mysql" 127.0.0.1:6379> SMEMBERS course 1) "mongodb" 2) "mysql" 3) "redis" 127.0.0.1:6379> SSCAN course (error) ERR wrong number of arguments for 'sscan' command 127.0.0.1:6379> SSCAN course 0 1) "0" 2) 1) "mysql"2) "mongodb"3) "redis" 127.0.0.1:6379> SSCAN course 0 1) "0" 2) 1) "mysql"2) "mongodb"3) "redis" 127.0.0.1:6379> SSCAN course 0 MATCH m* count 10 1) "0" 2) 1) "mysql"2) "mongodb"
3.5 Zset
Redis 有序集合和集合一样也是string类型元素的集合且不允许重复的成员。不同的是每个元素都会关联一个==double类型的分数==。redis正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 2^32^ - 1 (4294967295, 每个集合可存储40多亿个成员)。
Zset类型一般用于排行榜等。
3.5.1 结构图

3.5.2 相关命令
| 序号 | 命令语法 | 描述 |
|---|---|---|
| 1 | ZADD key score1 member1 [score2 member2] | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| 2 | ZCARD key | 获取有序集合的成员数 |
| 3 | ZCOUNT key min max | 计算在有序集合中指定区间分数的成员数 |
| 4 | ZRANK key member | 返回有序集合中指定成员的索引 |
| 5 | ZSCORE key member | 返回有序集中,成员的分数值 |
| 6 | ZREM key member [member ...] | 移除有序集合中的一个或多个成员 |
| 7 | ||
| 8 | ||
| 9 |
3.6 Hash
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。Redis 中每个 hash 可以存储 2^32^ - 1 键值对(40多亿)。
Hash类型一般用于存储用户信息、用户主页访问量、组合查询等。
3.6.1 结构图
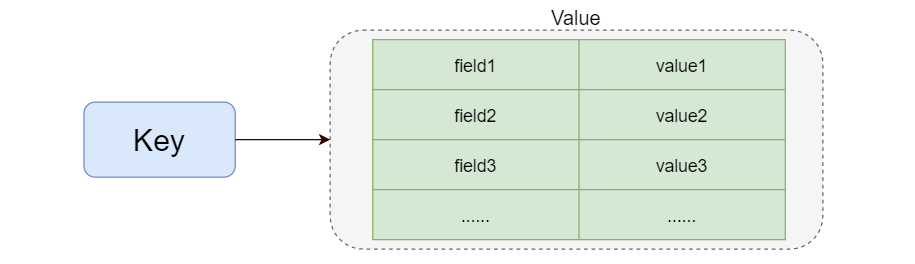
3.6.2 相关命令
| 序号 | 命令语法 | 描述 |
|---|---|---|
| 1 | HSET key field value | 将哈希表 key 中的字段 field 的值设为 value |
| 2 | HGET key field | 获取存储在哈希表中指定字段的值 |
| 3 | HGETALL key | 获取在哈希表中指定 key 的所有字段和值 |
| 4 | HEXISTS key field | 查看哈希表 key 中,指定的字段是否存在 |
| 5 | HKEYS key | 获取所有哈希表中的字段 |
| 6 | HVALS key | 获取哈希表中所有值 |
| 7 | HLEN key | 获取哈希表中字段的数量 |
| 8 | HMGET key field1 [field2] | 获取所有给定字段的值 |
| 9 | HMSET key field1 value1 [field2 value2] | 同时将多个 field-value (域-值)对设置到哈希表 key 中 |
3.6.3 演示示例
127.0.0.1:6379> HMSET hpe name zhangsan age 18 gender men birth 2000-01-01 OK 127.0.0.1:6379> HKEYS hpe 1) "name" 2) "age" 3) "gender" 4) "birth" 127.0.0.1:6379> HvalS hpe 1) "zhangsan" 2) "18" 3) "men" 4) "2000-01-01" 127.0.0.1:6379> HGETALL hpe 1) "name" 2) "zhangsan" 3) "age" 4) "18" 5) "gender" 6) "men" 7) "birth" 8) "2000-01-01"
3.7 Bitmaps
3.7.1 介绍
现代计算机用二进制(位) 作为信息的基础单位, 1个字节等于8位, 例如“abc”字符串是由3个字节组成, 但实际在计算机存储时将其用二进制表示, “abc”分别对应的ASCII码分别是97、 98、 99, 对应的二进制分别是01100001、 01100010和01100011,如下图:

合理地使用操作位能够有效地提高内存使用率和开发效率。
Redis 6 中提供了 Bitmaps 这个“数据类型”可以实现对位的操作:
1)Bitmaps本身不是一种数据类型,实际上它就是字符串(key-value),但是它可以对字符串的位进行操作。
2)Bitmaps单独提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。 可以把Bitmaps想象成一个以位为单位的数组, 数组的每个单元只能存储0和1, 数组的下标在Bitmaps中叫做偏移量。

3.7.2 相关命令
1、setbit
这个命令用于设置Bitmaps中某个偏移量的值(0或1),offset偏移量从0开始。格式如下:
setbit <key> <offset> <value>
例如,把每个独立用户是否访问过网站存放在Bitmaps中, 将访问的用户记做1,没有访问的用户记做0,用偏移量作为用户的id。
设置键的第offset个位的值(从0算起) , 假设现在有20个用户,userid=1,6,11,15,19的用户对网站进行了访问, 那么当前Bitmaps初始化结果如图:
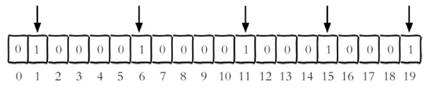
下面示例是代表 2022-07-18 这天的独立访问用户的Bitmaps:
127.0.0.1:6379> setbit unique:users:20220718 1 1 127.0.0.1:6379> setbit unique:users:20220718 6 1 127.0.0.1:6379> setbit unique:users:20220718 11 1 127.0.0.1:6379> setbit unique:users:20220718 15 1 127.0.0.1:6379> setbit unique:users:20220718 19 1
注意:
很多应用的用户id以一个指定数字(例如10000) 开头, 直接将用户id和Bitmaps的偏移量对应势必会造成一定的浪费, 通常的做法是每次做setbit操作时将用户id减去这个指定数字。
在第一次初始化Bitmaps时, 假如偏移量非常大, 那么整个初始化过程执行会比较慢, 可能会造成Redis的阻塞。
2、getbit
这个命令用于获取Bitmaps中某个偏移量的值。格式为:
getbit <key> <offset>
获取键的第offset位的值(从0开始算)。例如获取id=6的用户是否在2022-07-18这天访问过, 返回0说明没有访问过:
127.0.0.1:6379> getbit unique:users:20220718 6 127.0.0.1:6379> getbit unique:users:20220718 7
3、bitcount
这个命令用于统计字符串被设置为1的bit数。一般情况下,给定的整个字符串都会被进行计数,通过指定额外的 start 或 end 参数,可以让计数只在特定的位上进行。start 和 end 参数的设置,都可以使用负数值:比如 -1 表示最后一个位,而 -2 表示倒数第二个位,start、end 是指bit组的字节的下标数,二者皆包含。格式如下:
bitcount <key> [start end]
用于统计字符串从start字节到end字节比特值为1的数量。例如,统计id在第1个字节到第3个字节之间的独立访问用户数, 对应的用户id是11, 15, 19。
127.0.0.1:6379> bitcount unique:users:20220718 1 3
4、bitop
这个命令是一个复合操作, 它可以做多个Bitmaps的and(交集) 、 or(并集) 、 not(非) 、 xor(异或) 操作并将结果保存在destkey中。格式如下:
bitop and(or/not/xor) <destkey> [key…]
例如:2020-11-04 日访问网站的userid=1,2,5,9。
127.0.0.1:6379> setbit unique:users:20201104 1 1 127.0.0.1:6379> setbit unique:users:20201104 2 1 127.0.0.1:6379> setbit unique:users:20201104 5 1 127.0.0.1:6379> setbit unique:users:20201104 9 1
2020-11-03 日访问网站的userid=0,1,4,9。
127.0.0.1:6379> setbit unique:users:20201103 0 1 127.0.0.1:6379> setbit unique:users:20201103 1 1 127.0.0.1:6379> setbit unique:users:20201103 4 1 127.0.0.1:6379> setbit unique:users:20201103 9 1
计算出两天都访问过网站的用户数量
127.0.0.1:6379> bitop and unique:users:and:20201104_03 unique:users:20201103 unique:users:20201104 127.0.0.1:6379> bitcount unique:users:and:20201104_03
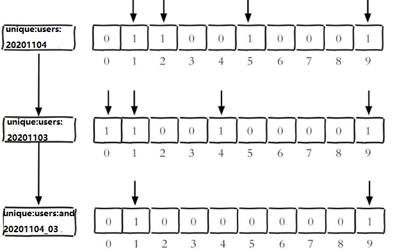
计算出任意一天都访问过网站的用户数量(例如月活跃就是类似这种) , 可以使用or求并集
127.0.0.1:6379> bitop or unique:users:or:20201104_03 unique:users:20201103 unique:users:20201104 127.0.0.1:6379> bitcount unique:users:or:20201104_03
3.8 HyperLogLog
3.8.1 简介
在工作当中,我们经常会遇到与统计相关的功能需求,比如统计网站PV(PageView页面访问量),可以使用Redis的incr、incrby轻松实现。
但像UV(UniqueVisitor,独立访客)、独立IP数、搜索记录数等需要去重和计数的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题。
解决基数问题有很多种方案:
1)数据存储在MySQL表中,使用distinct count计算不重复个数
2)使用Redis提供的hash、set、bitmaps等数据结构来处理
以上的方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。
为了能够降低一定的精度来平衡存储空间,Redis推出了HyperLogLog。
HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是:在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8},那么这个数据集的基数集为 {1, 3, 5 ,7, 8},基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
3.8.2 相关命令
| 序号 | 命令语法 | 描述 |
|---|---|---|
| 1 | PFADD key element [element ...] | 添加指定元素到 HyperLogLog 中 |
| 2 | PFCOUNT key [key ...] | 返回给定 HyperLogLog 的基数估算值 |
| 3 | PFMERGE destkey sourcekey [sourcekey ...] | 将多个 HyperLogLog 合并为一个 HyperLogLog |
3.8.3 示例演示
127.0.0.1:6379> PFADD course "redis" (integer) 1 127.0.0.1:6379> PFADD course "mongodb" (integer) 1 127.0.0.1:6379> PFADD course "mysql" (integer) 1 127.0.0.1:6379> PFADD course "redis" (integer) 0 redis 127.0.0.1:6379> PFCOUNT course (integer) 3 127.0.0.1:6379> PFADD course1 "redis" (integer) 0 redis 127.0.0.1:6379> pfmerge course course1 (integer) 1 redis 127.0.0.1:6379> PFCOUNT course (integer) 3
将所有元素添加到指定HyperLogLog数据结构中。如果执行命令后HLL估计的近似基数发生变化,则返回1,否则返回0。
3.9 Geospatial
3.9.1 简介
Redis 3.2 中增加了对GEO类型的支持。GEO,Geographic,地理信息的缩写。该类型,就是元素的2维坐标,在地图上就是经纬度。redis基于该类型,提供了经纬度设置,查询,范围查询,距离查询,经纬度Hash等常见操作。
3.9.2 相关命令
| 序号 | 命令语法 | 描述 |
|---|---|---|
| 1 | geoadd key longitude latitude member [longitude latitude member...] | 添加地理位置(经度,纬度,名称) |
| 2 | geopos key member [member...] | 获得指定地区的坐标值 |
| 3 | geodist key member1 member2 [m|km|ft|mi] | 获取两个位置之间的直线距离 |
| 4 | georadius key longitude latitude radius [m|km|ft|mi] | 以给定的经纬度为中心,找出某一半径内的元素 |
3.9.3 示例演示
127.0.0.1:6379> geoadd china:city 121.47 31.23 shanghai (integer) 1 127.0.0.1:6379> geoadd china:city 106.50 29.53 chongqing (integer) 1 127.0.0.1:6379> geoadd china:city 114.05 22.52 shenzhen (integer) 1 127.0.0.1:6379> geoadd china:city 116.38 39.90 beijing (integer) 1 127.0.0.1:6379> geopos china:city chongqing 1) 1) "106.49999767541885376"2) "29.52999957900659211" 127.0.0.1:6379> geodist china:city beijing shanghai km "1068.1535" 127.0.0.1:6379> georadius china:city 110 30 1000 km 1) "chongqing" 2) "shenzhen"


)
 #人工智能#学习方法的原因是因为0xc8大于??????????? 。 #微信#其他#微信)
)
—— JVM3:垃圾收集器)


:入门)










