在深度学习中模型量化可以分为3块知识点,数据类型、常规模型量化与大模型量化。本文主要是对这3块知识点进行浅要的介绍。其中数据类型是模型量化的基本点。常规模型量化是指对普通小模型的量化实现,通常止步于int8的量化,绝大部分推理引擎都支持该能力。而大模型的量化,需要再cuda层次进行能力的扩展,需要特殊的框架支持。
1、深度学习中的数据类型
1.1 常见的数据类型
在深度学习中常见的数据类型主要可以区分为int与float,在float中又可以区分为fp32、tf32、fp16、bf16等类型,这些float数据的差异在于指数位于小数位长度的差异。深度学习模型部署的参数数据类型有int64、int32、int8、int4等,int64与int32通常是用于模型进行索引操作时,int8与int4通常用于量化后模型参数的直接表示。关于模型量化还有二值量化、三值量化、稀疏量化等可以参考:https://zhuanlan.zhihu.com/p/20329244481
下图详细详细的展示了fp32、tf32、fp16、bf16等4种数据类型的差异。
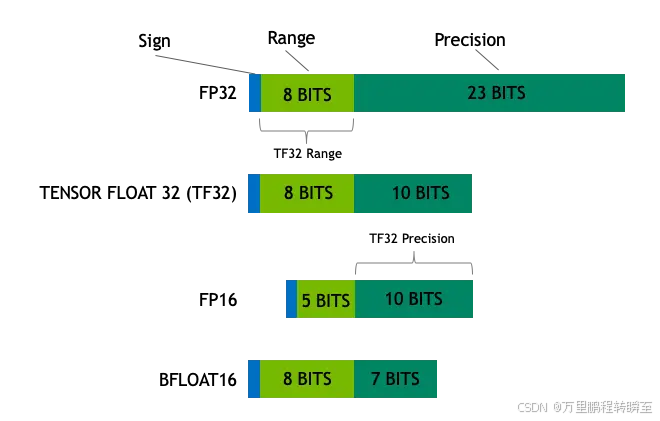
数据类型基本信息
| 数据类型 | 描述 | 特点 |
|---|---|---|
| FP32 | 32位单精度浮点数,符合IEEE 754标准,由1位符号位、8位指数位和23位尾数位组成。 | 能表示较宽的数值范围和较高的精度,可精确表示大多数实数,是深度学习中常用的默认数据类型。 |
| TF32 | 一种特殊的32位浮点数格式,主要用于NVIDIA的Tensor Core架构。它与FP32类似,但指数范围较小,为8位(与FP16相同),尾数位为23位。 | 相比传统FP32,TF32在保持一定精度的同时,能利用Tensor Core的硬件加速特性,提高计算效率。 |
| FP16 | 16位半精度浮点数,由1位符号位、5位指数位和10位尾数位组成。 | 占用空间是FP32的一半,数据传输和计算速度快,但数值范围和精度相对较低。 |
| BF16 | 16位脑浮点格式,由1位符号位、8位指数位和7位尾数位组成。 | 指数位与FP32相同,能表示较大数值范围,在精度和计算效率上有一定平衡,对某些深度学习任务能在减少内存占用的同时保持较好的模型性能。 |
| Int8 | 8位有符号整数,取值范围通常是 -128到127。 | 占用存储空间小,计算速度快,对硬件要求低,但只能表示整数,无法精确表示小数,精度有限。 |
| Int4 | 4位有符号整数,取值范围通常是 -8到7。 | 占用空间极小,是Int8存储空间的一半,计算速度更快,但精度损失更为严重,能表示的数值范围非常有限。 |
数据类型应用特性
| 数据类型 | 优势 | 劣势 | 应用场景 |
|---|---|---|---|
| FP32 | 计算精度高,模型训练和推理结果准确,适用于各种深度学习任务,尤其是对精度要求苛刻的场景。 | 占用内存和存储空间大,计算速度相对慢,在一些资源受限的环境中可能不太适用。 | 广泛应用于图像识别、自然语言处理、语音识别等各种深度学习领域,如大型复杂神经网络的训练和推理。 |
| TF32 | 能利用专门的硬件(如NVIDIA Tensor Core)实现高效计算,在不显著降低精度的情况下提高计算速度,减少训练时间。 | 依赖特定的硬件支持,不具有广泛的兼容性,如果硬件不支持TF32,则无法发挥其优势。 | 主要用于NVIDIA支持Tensor Core的GPU设备上进行深度学习计算,特别是在处理大规模矩阵运算的神经网络中表现出色,如一些需要快速训练的深度卷积神经网络。 |
| FP16 | 减少内存占用和传输带宽,提高计算速度,降低模型存储和传输成本,适用于对实时性要求较高的场景。 | 精度有限,在一些复杂模型训练中可能出现精度损失,导致模型性能下降。 | 常用于移动端、嵌入式设备以及一些对实时性要求高的场景,如自动驾驶中的实时目标检测、移动设备上的图像分类应用等。 |
| BF16 | 在大规模数据和复杂模型处理中,能较好地平衡精度和计算效率,可减少内存占用,同时利用硬件加速提高计算速度。 | 相比FP32精度有一定损失,虽然比FP16更能保持模型准确性,但在某些对精度要求极高的任务中可能不够精确。 | 常用于数据中心的深度学习训练,尤其是针对一些大型神经网络,如大规模的语言模型训练、图像生成模型等,可利用支持BF16的硬件来提高训练效率。 |
| Int8 | 降低存储和计算成本,提高运行效率,适合内存和计算资源有限的场景,如边缘计算设备和低功耗芯片。 | 精度丢失,不适用于高精度计算任务,在将浮点数转换为Int8时可能会引入量化误差,影响模型准确性。 | 常用于边缘计算设备,如智能摄像头中的目标检测模型、工业物联网设备中的预测模型等,通过量化为Int8类型,可以在不影响太多性能的前提下,减少内存占用和计算量。 |
| Int4 | 进一步降低存储和计算成本,适用于资源极度受限的环境,如一些物联网设备。 | 精度损失严重,能表示的数值范围非常有限,对模型的准确性影响较大,需要更复杂的量化和校准技术来保证模型性能。 | 目前相对较少单独使用,主要探索用于一些特定的超轻量级模型或对存储和能耗有极致要求的场景,如某些简单的物联网传感器数据处理模型,常与其他优化技术结合使用以平衡精度和性能。 |
1.2 不同数据类型下的算力差异
以抖音百科提炼的A100显卡的算力数据,可以发现a100显卡fp32计算的算力是156TFlops,但随着数据类型的精简,算力在翻倍。

以下是RTX 3060显卡在不同数据格式下的算力情况图表:
| 数据格式 | 算力 |
|---|---|
| FP32 | 12.7 TFLOPS |
| TF32 | 无官方明确数据,一般认为在利用Tensor Core加速时接近FP16性能(由于架构设计,RTX 3060的TF32性能不像A100那样有明确区分和突出优势) |
| FP16 | 25.4 TFLOPS |
| BF16 | 无官方明确数据,推测与FP16相近或略低,因为RTX 3060硬件对BF16的支持不是特别突出 |
| INT8 | 50.8 TOPS |
| INT4 | 暂无公开的准确官方数据,考虑到其数据位宽更窄,理论上在特定计算场景下会比INT8有更高的计算吞吐量,但具体数值需根据实际测试确定。 |
需要注意的是,实际应用中的算力表现可能会受到多种因素的影响,如显存带宽、算法实现、软件优化等,以上数据仅供参考。这里也同样可以发现表示数据的位数减少一半,显卡的算力基本上可以提升一倍。同时a100的算力是3060显卡的12倍以上
量化对于精度的影响
随意截取一个论文数据,可以发现对于10b以上的模型进行int量化操作基本上没有精度损失,而对于7b或更小的模型进行量化有一定的精度损失风险。
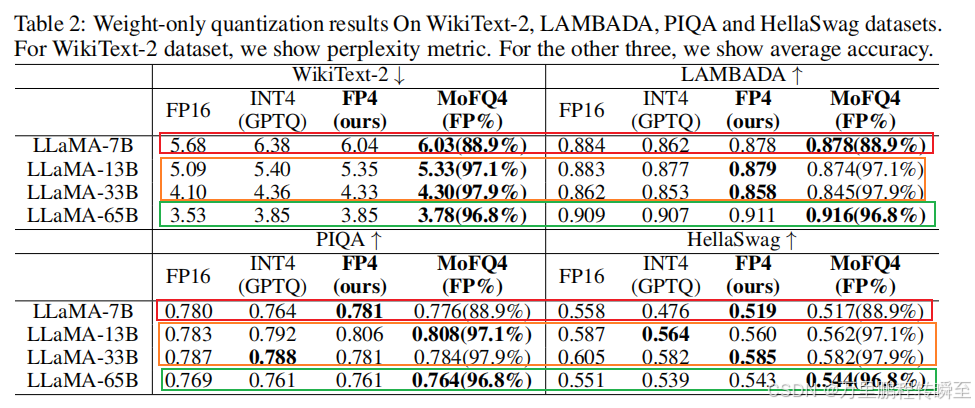
1.3 fp8与fp4
除了前面提到的各种float数据类型外,还有fp8与fp4两个不常见的类型。FP8是由Nvidia在Hopper和Ada Lovelace架构GPU上推出的数据类型,有如下两种形式:
- E4M3:具有4个指数位、3个尾数位和1个符号位
- E5M2:具有5个指数位、2个尾数位和1个符号位
其中E4M3支持动态范围更小、精度更高的计算,而E5M2可提供更宽广的动态范围和更低的精度。LLM推理过程对精度要求较高,对数值范围要求偏低,因此FP8-E4M3更适合于LLM推理。
在论文Integer or Floating Point? New Outlooks for Low-Bit Quantization on Large Language Models中详细的对比了FP8与INT8的差异。以下是关键信息。整体来说,就是int8适用于权重的量化,fp8适用于激活值的量化。
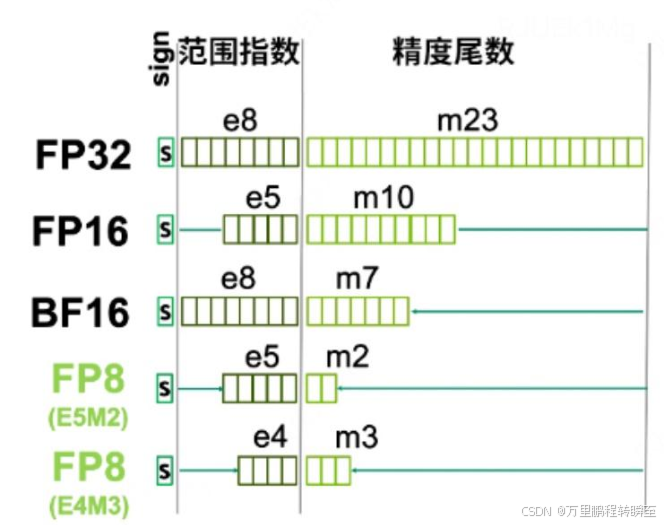
数值范围
FP8与INT8相比,整数格式在可表示范围内具有均匀的分布,两个连续数字之间的差值为1。而浮点格式由于结合了指数和尾数设计而表现出非均匀分布,从而为较小的数字提供较高的精度,为较大的数字提供较低的精度。
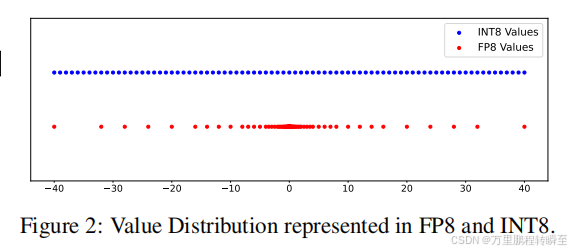
权重量化效果
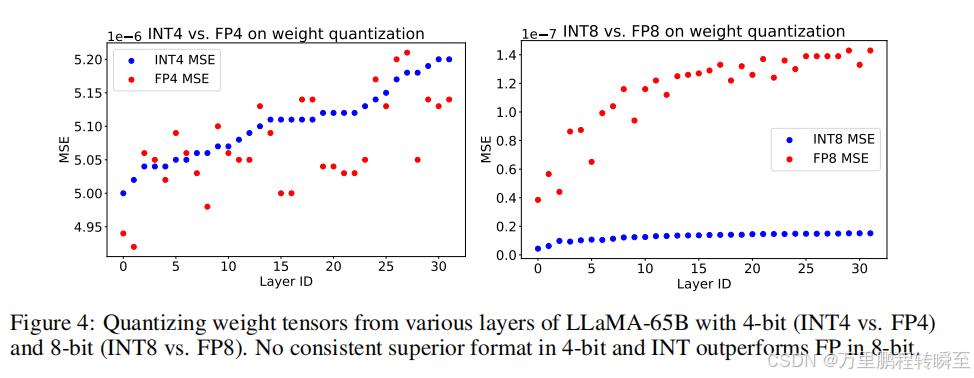
基于论文作者对于LLaMA-65B模型的权重量化实验,可以发现int8的效果部分fp8要好很多。int8量化后的差异比较稳定,而fp8量化后的差异增长较快。
这一分析结果表明,INT在8位权重量化中具有优势。然而,当位宽减小时,指数位也会减少,使得INT和FP的分布更加相似。在4位量化中,使用均匀分布的INT格式量化静态张量的优势逐渐消失,导致4位量化权重没有明确的最优解。
激活值量化
与推理过程中的静态权值张量不同,激活张量是动态的,并随着每个输入而变化。因此,校准是激活张量量化过程中确定适当尺度因子的重要步骤。作者比较了FP8和INT8量化的MSE误差,如图5所示。FP8的量化误差低于INT8因为校准过程总是在多个批次中选择最大的值来确定量化中的比例因子。这个过程倾向于为大多数批次得出一个大于合适的比例因子。然而,FP格式对于大值的精度较低,对于小值的精度较高,本质上更适合量化这种动态张量。
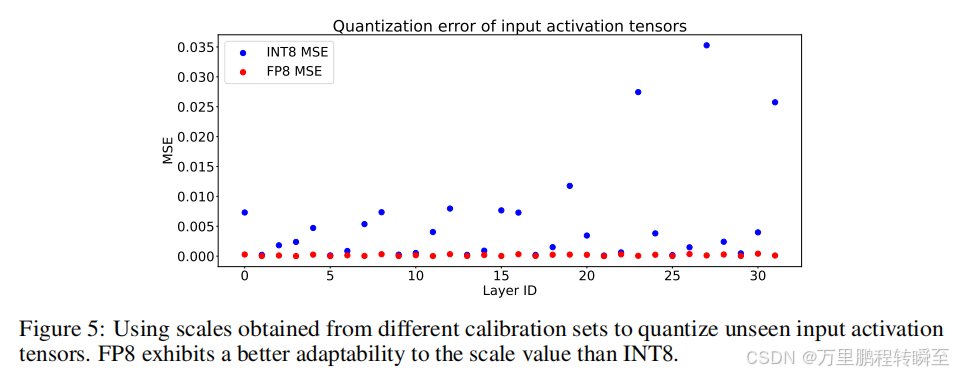
因为int8量化受极大值影响精度表示,而fp8量化不受极大值影响,反而对于极大值表示误差反而大。而极大值可能为异常值,int8量化为极大值浪费精度,而fp8为极小值提供高精度,故fp8量化激活值效果更好
2、模型的常规量化
模型量化的精度越低,模型尺寸和推理内存占用越少,为了尽可能的减少资源占用,量化算法被发明。FP32占用4个字节,量化为int8,只需要1个字节。
本节内容参考:https://zhuanlan.zhihu.com/p/29140505773

2.1 量化方式的基本分类
量化可以分为对称量化与非对称量化
在对称量化中,值域为-127到127,由于模型参数不是对称分布的,故量化后权重的部分表示范围被浪费了。
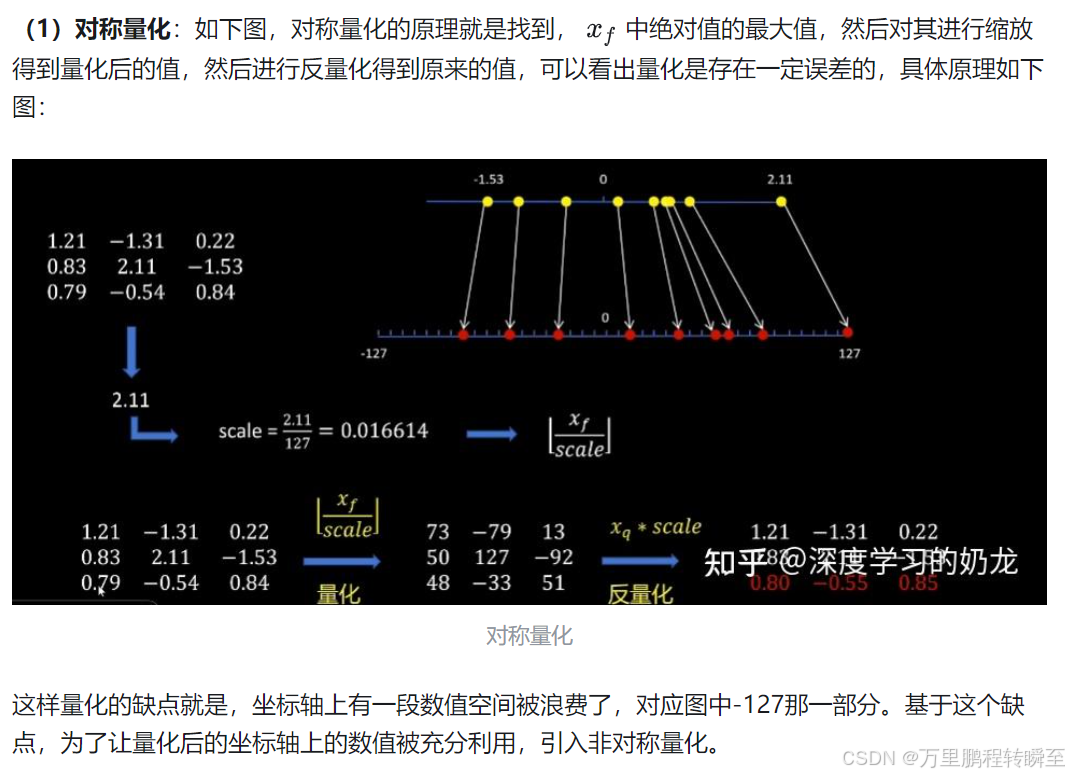
在非对称量化中,将参数的最小值平移到0点,故值域为0到255。故量化后权重的部分表示范围均被有效利用了。但非对称量化,每一次都需要多一个反平移操作,计算量略多,但精度较高。
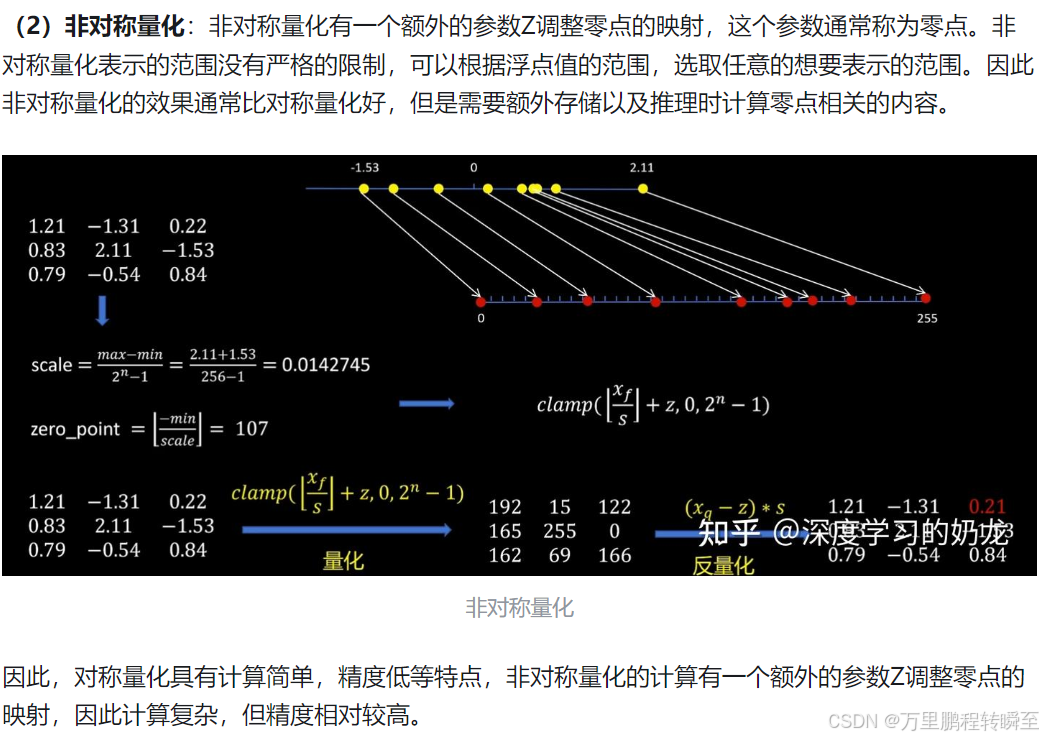
量化后的模型计算方式如下,可以看到下图,量化后的模型将float的矩阵乘法等价为 int的矩阵乘法+2个float乘法操作,该操作大幅度的发挥了机器的计算能力,同时计算误差较小。
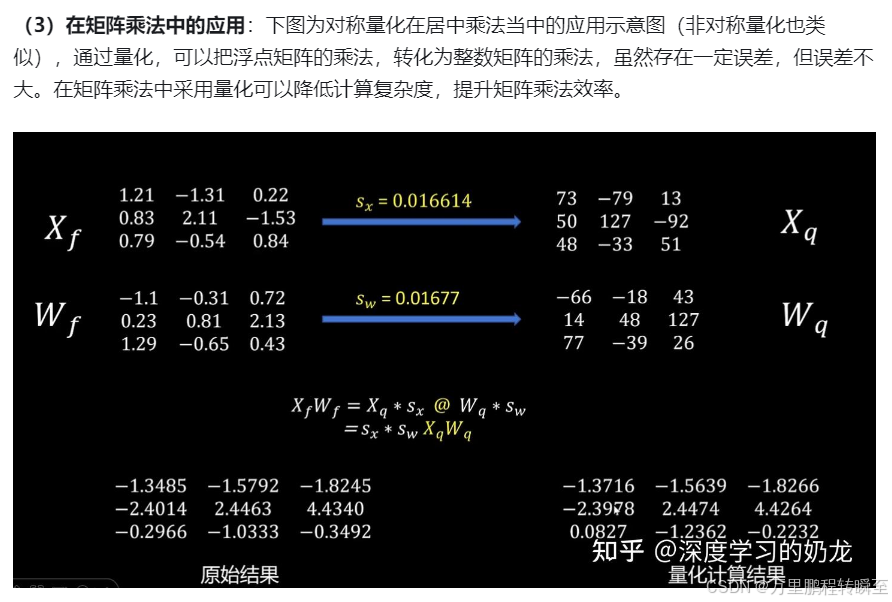
2.2 量化步骤的分类
根据量化的时机,有量化感知训练和训练后量化两条路径。PTQ(Post - Training Quantization,训练后量化)和 QAT(Quantization - Aware Training,量化感知训练)。
PTQ
- 原理:PTQ是
在模型训练完成后,对训练好的浮点数模型进行量化处理,将模型的权重和激活值从较高精度的浮点数格式转换为较低精度的定点数格式,如INT8、INT4等。其核心思想是通过对模型中的数值分布进行统计分析,确定合适的量化参数,使得量化后的模型在尽可能减少精度损失的情况下,能够在特定的硬件上高效运行。 - 优点
- 简单高效:不需要对模型的训练过程进行修改,只需在训练结束后进行一次量化操作,即可得到量化后的模型,操作相对简单,节省了大量的训练时间和计算资源。
- 通用性强:适用于各种已经训练好的模型,无论是深度学习模型还是传统的机器学习模型,只要其权重和激活值可以表示为数值形式,都可以应用PTQ进行量化。
- 缺点:由于是在训练后进行量化,无法在训练过程中考虑量化带来的误差,因此对于一些对精度要求较高的模型,可能会导致较大的精度损失。
- 应用场景:适用于对
模型精度要求不是特别高,但是希望能够快速部署到资源受限的设备上,如嵌入式设备、移动设备等,以减少模型的存储空间和计算量,提高推理速度。
在模型进行PTQ时通常需要收集部分校准数据,用于推断模型中各层的权重和激活值分布信息,用于计算每个张量(权重或激活值)的量化参数,包括量化比例因子(scale)和零点(zero - point)。这里比较重要的是激活值分布信息,不同的数据输入,激活值分布是不同的。
QAT
- 原理:QAT是一种
在模型训练过程中就考虑量化影响的技术。它通过在训练过程中模拟量化操作,将模型中的浮点数权重和激活值在训练过程中逐步转换为低精度的定点数表示。具体来说,在训练过程中的前向传播和反向传播过程中,插入量化和反量化操作,使得模型在训练过程中就能够适应量化带来的精度损失,从而在量化后能够保持较好的性能。 - 优点
- 精度保持较好:由于在训练过程中就对量化误差进行了优化,使得模型能够更好地适应量化后的数值表示,因此在量化后能够保持较高的精度,尤其适用于对精度要求较高的任务,如医学图像分析、金融风险预测等。
- 灵活性高:可以根据具体的任务和模型特点,在训练过程中动态调整量化参数,以达到最佳的量化效果。
- 缺点
- 训练时间长:由于在训练过程中增加了量化和反量化操作,以及额外的参数调整,使得训练过程变得更加复杂,训练时间也会显著增加。
- 实现复杂:需要对模型的训练框架进行一定的修改和扩展,以支持量化感知训练的相关操作,对开发人员的技术要求较高。
- 应用场景:适用于对模型精度要求严格,同时又希望通过量化来提高模型的运行效率和减少存储空间的场景,如数据中心的大规模模型部署、高性能计算等。
2.3 PAT(静态量化与动态量化)
静态量化和动态量化是模型量化中两种不同的技术方法,本质上是对PTQ的不同实现步骤。
静态量化:就是在模型推理前已经基于部分数据得到了模型的激活值的比例因子(scale)和零点(zero - point)信息。该操作会降低模型精度,但推理速度较快
动态量化:是实时根据输入数据计算比例因子(scale)和零点(zero - point)。该操作需要对每一个输入都计算量化因子,若推理引擎支持性差,可能速度提升不明显,但精度保持性好
量化时机
- 静态量化:在模型训练后部署前,根据事先收集的数据来确定量化参数,然后一次性将模型的权重和激活值按照这些固定的量化参数进行量化,整个量化过程是在训练后静态进行的,不考虑模型在实际运行时数据的动态变化。
- 动态量化:是在模型部署运行时,根据当前处理的数据动态地计算量化参数,并对数据进行量化。这意味着量化参数会随着输入数据的不同而实时调整,以更好地适应数据的动态范围。
量化参数计算方式
- 静态量化:通常基于对训练数据或一小部分代表性数据的统计分析来确定量化参数。例如,计算权重或激活值的最大值、最小值,然后根据这些统计信息计算出固定的量化比例因子和零点,这些参数在模型部署后就不再改变。
- 动态量化:在模型推理过程中,对于每个要量化的张量,会根据当前批次数据的实际分布情况实时计算量化参数。例如,对于每一批输入数据,动态地计算其均值和标准差,然后根据这些动态统计信息来调整量化比例因子,使得量化能够更好地适应数据的变化。
模型性能影响
- 静态量化:优点是实现相对简单,不需要在运行时进行复杂的参数计算,因此推理速度较快,适用于对推理速度要求较高的场景。但由于量化参数是固定的,可能无法很好地适应不同输入数据的动态范围,导致一定的精度损失,尤其是在数据分布变化较大的情况下。
- 动态量化:能够更好地适应数据的动态变化,因此在量化后通常能保持较高的精度。然而,由于需要在运行时实时计算量化参数,会增加一定的计算开销,导致推理速度相对较慢。不过,随着硬件技术的发展,一些专门的硬件架构能够高效地支持动态量化计算,使得这种方法在一些对精度要求较高的场景中得到了广泛应用。
适用场景
- 静态量化:适用于数据分布相对稳定,对模型推理速度要求较高,且能够接受一定精度损失的场景,如一些嵌入式设备或移动设备上的模型部署,这些设备通常计算资源有限,静态量化可以在不显著降低性能的前提下减少模型存储空间和计算量。
- 动态量化:更适合于数据分布复杂且变化较大,对模型精度要求较高的场景,如在数据中心或高性能计算平台上运行的模型,这些场景通常有足够的计算资源来支持动态量化所需的额外计算,同时能够通过动态量化获得更好的模型性能。
3、GPTQ与AWQ量化
GPQT与AWQ量化是常见于大模型的量化方法。GPTQ 是一种后训练量化(PTQ)方法,主要聚焦于 GPU 推理和性能提升。它基于近似二阶信息的一次性权重量化方法,能实现高精度和高效的量化。AWQ 即激活感知权重量化,由 MIT - Han Lab 开发。该方法通过观察激活值来保护显著权重,而非权重本身,在指令微调的语言模型和多模态语言模型上表现出色。
这里的两个量化方法与章节2中的量化有所差异,量化后的模型需要特殊的引擎才能推理。通常来说两个量化方式在大模型上精度保持是差不多的,但是在7b及以下小模型上的量化,awq的量化方式效果保持更好。
3.1 GPTQ量化
这里可以详细参考:https://zhuanlan.zhihu.com/p/9270075965
GPTQ(GENERATIVE POST-TRAINING QUANTIZATION)量化基于OBQ量化方式改进。OBQ是2022年提出的一种基于二阶信息的量化方法,其主要目的就是优化量化后的权重,使量化前后的模型差异值最小。GPTQ量化是一种基于静态量化的后量化方法,只需要少量校准数据即可

OBQ其主要思想是:
- 逐个量化权重:按照权重对量化误差的影响,从大到小依次选择权重进行量化。
- 调整剩余权重:每次量化一个权重后,调整未量化的权重以补偿误差。
- 利用Hessian矩阵:通过二阶导数信息,计算权重调整的最优值。
然而,OBQ量化方式计算复杂度比较高,不适用于大模型的量化。

关于GPTQ量化方式(OBD -> OBS -> OBQ ->GPTQ)的演进可以参考:https://zhuanlan.zhihu.com/p/18714878738
按照:https://zhuanlan.zhihu.com/p/9270075965的总结,GPTQ量化进行以下改进

以下图片是GPTQ减少IO操作的原理示意,针对于后续列的更新,只是先累加记录更新值,不进行写操作,等到量化该列时才更新参数。
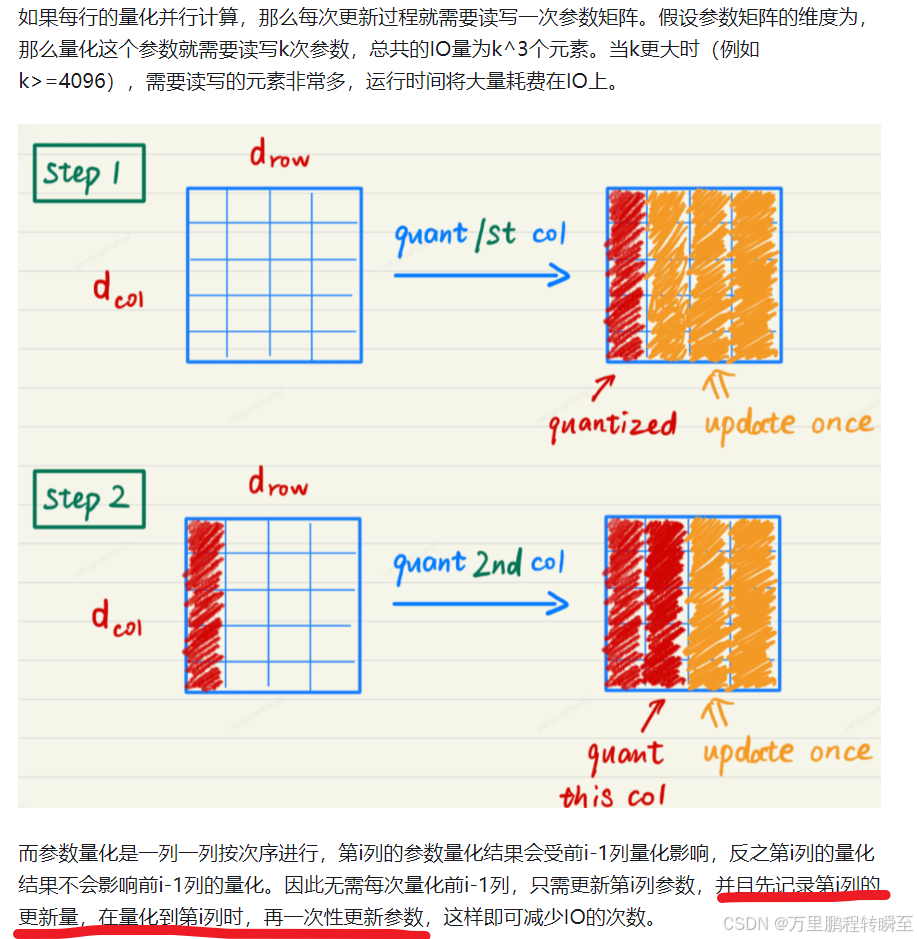
以下图片是GPTQ减少IO操作的具体流程,与原型示意相比补充了group跟新的概念,明显缓解了累加记录更新值的变量需求。
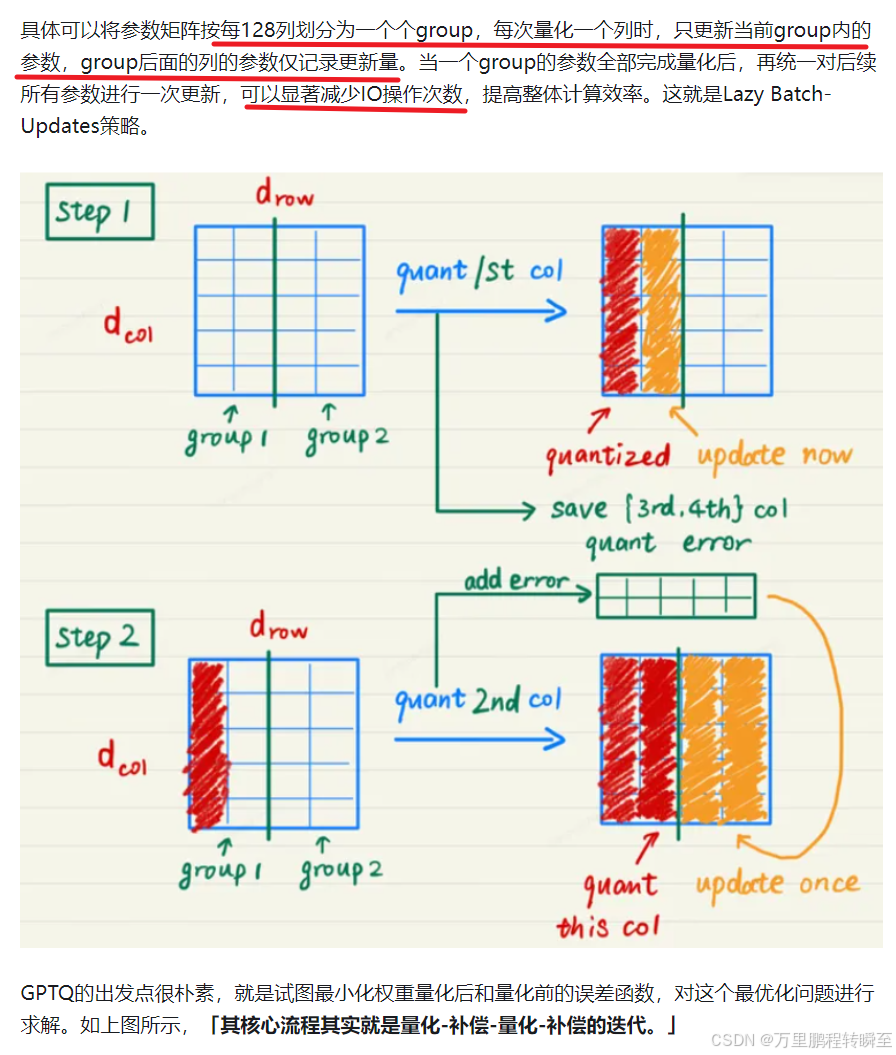

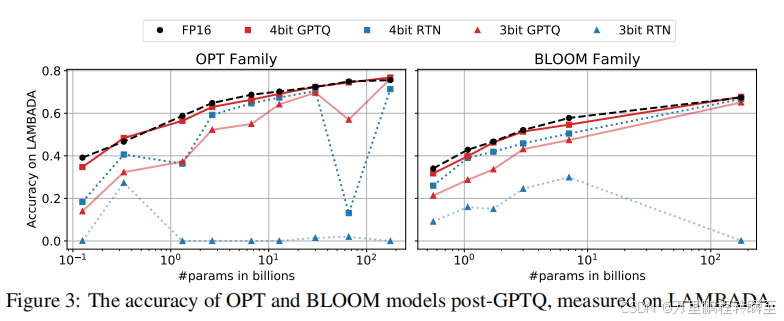
根据GPTQ论文中的数据,可以发现int4量化后于fp16保持了相同的精度
3.2 AWQ量化
激活感知权重量化 (AWQ),这是一种适合硬件的 LLM 低位权重(比如 w4)量化方法。AWQ 发现,并非所有 LLM 权重都同等重要,仅保护 1% 的显著权重便能大幅减少量化误差。AWQ 不依赖反向传播或重构,因此可以泛化到不同领域和模态而不会对校准集过拟合。
以下信息参考自:https://www.armcvai.cn/2024-11-01/llm-quant-awq.html
如何选择出重要权重
对激活值的每一列求绝对值的平均值,然后把平均值较大的一列对应的通道视作显著通道,保留 FP16 精度。

如果权重矩阵中有的元素用FP16格式存储,有的用INT4格式存储,不仅存储时很麻烦,计算时取数也很麻烦,kernel函数写起来会很抽象。于是,作者想了一个变通的方法——Scaling。
如何利用重要权重
对于所有的元素进行int量化,但引入逐通道缩放减少关键权重的量化误差,避免硬件效率问题。量化时对显著权重进行放大即引入缩放因子 s,是可以降低量化误差的。
计算缩放因子 s*
作者统计各通道的激活值平均值(计算输入矩阵各列绝对值的平均值)sX ,将此作为各通道的缩放系数。


 高频词汇背诵)
)
)







之制作简单的倒计时)

)



)

—— DQL)