引言
在机器学习领域,数据降维是一种常用的技术,旨在减少数据集的维度,同时保留尽可能多的有用信息。数据降维可以帮助我们解决高维数据带来的问题,提高模型的效率和准确性。本文将详细介绍机器学习中的数据降维方法和技术,以及其在实际应用中的重要性。
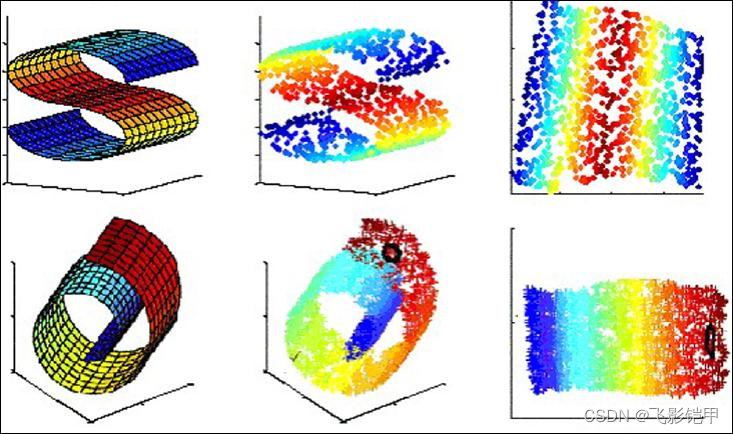
一、概念
数据降维是指通过对原始数据进行变换或压缩,将其映射到一个低维空间中,从而减少特征的数量。数据降维的目标主要包括以下几个方面:
- 减少计算复杂性:高维数据可能导致计算资源的浪费,数据降维可以减少计算的时间和空间复杂性,提高模型的训练和预测效率。
- 消除冗余信息:高维数据中可能存在冗余特征,这些特征对模型的训练并没有太大的帮助,甚至可能引起过拟合。数据降维可以消除这些冗余信息,提高模型的泛化能力。
- 可视化和解释性:降维后的数据可以更容易地进行可视化和解释,帮助我们更好地理解数据和模型的特征。
二、常见的方法
在进行数据降维时,可以使用以下几种常见的方法和技术:
- 主成分分析(Principal Component Analysis, PCA):PCA是一种常用的线性降维方法,通过找到数据中的主要方差方向,将其映射到新的低维空间。PCA可以有效地保留数据的主要信息,并且易于实现和解释。
- 线性判别分析(Linear Discriminant Analysis, LDA):LDA是一种有监督的降维方法,它在分类问题中广泛应用。LDA通过最大化类别间的距离和最小化类别内的距离,将数据映射到一个低维空间,以达到分类和降维的目的。
- t-SNE:t-SNE是一种非线性降维方法,它可以更好地保留数据之间的局部关系。t-SNE通过在高维空间中测量样本之间的相似度,并将其映射到低维空间中,生成具有可视化效果的降维结果。
- 自编码器(Autoencoder):自编码器是一种神经网络模型,它通过将数据压缩到一个低维表示,并尝试从该低维表示中重构原始数据。自编码器可以学习到数据中的潜在特征,并实现非线性降维。
三、数据降维的流程
下面是一般的数据降维流程,可根据具体情况进行调整:
- 数据预处理:对原始数据进行标准化、归一化等预处理操作,使其符合降维算法的要求。
- 选择降维方法:根据数据的特点和问题的需求,选择合适的降维方法。
- 数据降维:使用选定的降维方法对数据进行降维操作,得到低维表示。
- 可视化和解释:根据需要,对降维后的数据进行可视化和解释,以便更好地理解数据和模型的特征。
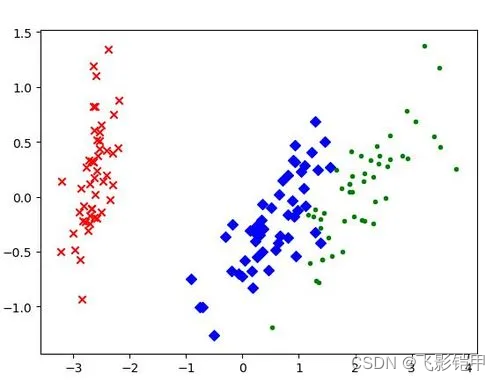
结论
数据降维是机器学习中重要的预处理步骤,它可以帮助我们解决高维数据带来的问题,提高模型的效率和准确性。在进行数据降维时,我们可以选择适当的方法和技术,根据数据的特点和问题的需求进行调整。通过合理的数据降维,我们可以获得更简洁、可解释的数据表示,为后续的模型训练和分析打下坚实的基础。

)
)
![[EFI]DELL-7472电脑 Hackintosh 黑苹果efi引导文件](http://pic.xiahunao.cn/[EFI]DELL-7472电脑 Hackintosh 黑苹果efi引导文件)



)











