gorm day1
- gorm简介
- gorm声明模型
代码样例基本来自官方文档
Gorm简介
什么是ORM?
对象关系映射(Objection Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库(如mysql数据库)存在的互不匹配现象的计数。简单来说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中。
什么是Gorm?
Gorm就是Go语言的ORM框架。它提供了一种高效的方式来在Go代码和数据库之间进行数据操作和交互。Gorm允许开发者通过Go结构体来定义数据库表,并通过简介的API进行数据库的CRUD操作(创建,读取,更新,删除)。它支持自动迁移,关联,事务处理等高级功能,同时也兼容多种主流的数据库系统,比如MYSQL,SQLITE等。Gorm通过抽象化数据库操作,使得数据操作更加直观和便捷,而无需之间编写SQL代码。
什么是自动迁移:在ORM框架中,自动迁移是指自动同步数据库模式以匹配程序中定义的数据模型。当你在应用程序中定义或修改了数据类型(通常是以类或结构体的形式),自动迁移功能可以自动创建或修改数据库的表,列等,以确保数据库结构与数据模型保持一致。这样开发者就不需要手动编写SQL语句来更新数据库模式。从而简化了数据库管理和维护的工作。
安装
go get -u gorm.io/gorm
go get -u gorm.io/driver/mysql先在终端把这两个库给安装了,第一个是gorm的库,第二个是gorm和mysql的驱动
简单连接
username := "root" //账号
password := "root" //密码
host := "127.0.0.1" //数据库地址,可以是Ip或者域名
port := 3306 //数据库端口
Dbname := "gorm" //数据库名
timeout := "10s" //连接超时,10秒// root:root@tcp(127.0.0.1:3306)/gorm?
dsn := fmt.Sprintf("%s:%s@tcp(%s:%d)/%s?charset=utf8mb4&parseTime=True&loc=Local&timeout=%s", username, password, host, port, Dbname, timeout)
//连接MYSQL, 获得DB类型实例,用于后面的数据库读写操作。
db, err := gorm.Open(mysql.Open(dsn))
if err != nil {panic("连接数据库失败, error=" + err.Error())
}
// 连接成功
fmt.Println(db)这个代码是gorm用于连接到Mysql数据库的例子
逻辑:
1.定义数据库连接信息:设置数据库用户名、密码、主机地址、端口号、数据库名称和连接超时时间。
2.构建DSN(Data Source Name)数据源:使用fmt.Sprintf根据提供的数据连接信息构建DSN字符串。DSN字符串包含了连接数据库所需的所有信息,如字符集、解析时间格式、地区设置、超时时间。这个字符串里面,?这个字符在DSN中用来看是连接参数部分,&这个字符用于分隔多个连接参数。每个连接参数都是以key=value的形式出现,&就是用来分隔这些不同的key=value。
3.打开数据库连接:调用gorm.Open并传递mysql.Open(dsn)来建立连接。如果连接出现错误,程序将出发panic。gorm.Open是为了建立数据库连接,mysql.Open()是GORM的mysql驱动的函数,用于创建数据库的Dialector,它的参数接收一个字符串参数,通常是数据库的连接信息(数据源)。
4.输出数据库对象:如果连接成功,db遍历将包含数据库连接对象,可用于后续的数据库操作。
高级配置:
db, err := gorm.Open(mysql.Open("gorm.db"), &gorm.Config{SkipDefaultTransaction: true,
})这个Open还有一个参数就是配置选项,选项键值对设置为true,就是代表开启了这个选项。用到了再来查。
命名策略
gorm采用的命名策略是,表名是蛇形复数,字段名是蛇形单数
type Student struct {Name stringAge intMyStudent string
}这个结构体在使用gorrm生成表之后对应的表结构:
CREATE TABLE students (name longtext,age bigint,my_student longtext)
可以发现表名复数,字段变成单数了。
这里有个修改策略:
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{NamingStrategy: schema.NamingStrategy{TablePrefix: "f_", // 表名前缀SingularTable: false, // 单数表名NoLowerCase: false, // 关闭小写转换},
})这个是开启了配置的命名策略这个选项,可以对表的名字做一些相关的要求,可以看到上面的注释。
显示日志
gorm的默认日志是只打印错误和慢SQL。慢 SQL 指的是执行时间过长的 SQL 查询。这通常是由于查询的复杂性、数据库设计问题、缺乏必要的索引、数据量过大等原因引起的。慢 SQL 查询可能导致应用程序响应缓慢,甚至引起数据库和应用服务器的性能问题。
也可以自定义日志的显示:
newLogger := logger.New(log.New(os.Stdout, "\r\n", log.LstdFlags), // (日志输出的目标,前缀和日志包含的内容)logger.Config{SlowThreshold: time.Second, // 慢 SQL 阈值LogLevel: logger.Info, // 日志级别IgnoreRecordNotFoundError: true, // 忽略ErrRecordNotFound(记录未找到)错误Colorful: true, // 使用彩色打印},
)db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{Logger: newLogger,
})这个是利用logger.New函数创建了一个新的日志器,其配置如下:
日志输出的目标:log.New(os.Stdout, “\r\n”, log.LstdFlags) 指定了日志输出到标准输出(控制台),每条日志前有换行,日志格式包括标准的时间、文件和行号。log.LstdFlags 是 Go 语言标准库中 log 包的一个常量,用于定义日志的格式。具体来说,log.LstdFlags 会设置日志输出包含标准的时间和日期信息。这意味着每条日志消息前会有一个时间戳,显示日志记录的时间。这个标志常用于创建日志记录器时,以提供一定的时间上下文信息,有助于在分析日志时确定事件的发生时间。
慢 SQL 阈值: SlowThreshold: time.Second 表示执行时间超过一秒的 SQL 将被视为慢查询。
日志级别:LogLevel: logger.Info 设置日志级别为信息级别,意味着会输出普通的日志信息。
日志级别:
在 GORM 中,日志级别定义了不同类型的日志信息的输出程度,通常包括以下几种级别:
Silent:静默级别,不输出任何日志。
Error:错误级别,仅输出错误信息,适用于生产环境中最小化日志输出。
Warn:警告级别,输出错误和潜在问题的信息。
Info:信息级别,输出所有常规操作日志,包括查询和慢查询等。
忽略记录未找到错误: IgnoreRecordNotFoundError: true 表示当记录未找到时,不记录错误信息。
彩色打印:Colorful: true 启用彩色日志输出,使日志更易于阅读。
这个日志器随后被传递给 gorm.Open 用于数据库连接的配置,使得所有通过该 GORM 实例进行的数据库操作都使用这个自定义日志器来记录日志。
展示部分日志:
var model Student
session := DB.Session(&gorm.Session{Logger: newLogger})
session.First(&model)
// SELECT * FROM `students` ORDER BY `students`.`name` LIMIT 1这段代码中,首先定义了一个Student类型的遍历model。接着,使用DB。Session创建了一个新的会话session,并且将自定义的日支持newlogger串进这个会话,这意味着在session中进行的所有数据库操作,都将使用newlogger来记录日志
然后调用session.First(&model)执行了一个查询操作,试图获取第一个Student记录,并将其存储在model中。该查询会在数据库students表中进行,并默认按name字段排序,只获取一条记录。
该代码展示了如何在gorm中自定义会话的日志记录方式,并执行一次基本的数据库查询操作。
DB.Session 是 GORM 中用于创建数据库会话的函数。它的返回值是一个包含了定制配置的会话对象,这个对象可以执行数据库操作。
在 GORM 中,数据库操作一般需要通过会话对象来执行。当你创建一个会话后,它就可以用于执行各种数据库操作,例如查询、插入、更新、删除等。会话对象允许你控制事务、日志记录、超时设置等数据库操作的行为。
所以,DB.Session 返回的会话对象可以用于执行数据库查询,是因为它实际上是一个带有数据库连接和一些配置的对象,可以代表一个数据库会话来执行各种操作。
如果只想某些语句显示日志
DB.Debug().First(&model)
这段代码使用了 GORM 提供的 Debug 模式,通过 DB.Debug() 开启了调试模式,这会导致 GORM 在执行数据库操作时输出详细的调试信息。
然后,它使用 First(&model) 这个函数从数据库中查询第一条记录,并将结果保存到 model 变量中。
我发现这个代码没有表名:
思考:
在 GORM 中,如果你没有明确指定要查询的表名,它会默认使用模型的结构体名称的复数形式作为表名进行查询。例如,如果你的模型结构体名为 Student,它会默认在数据库中查找名为 students 的表。所以,在这个代码中,虽然没有明确指定要查询的表名,但 GORM 会根据 model 变量的类型(Student)来确定要查询的表名,并执行相应的查询。
这种默认的行为适用于大多数情况,但如果你的表名与默认规则不匹配,你可以使用 GORM 提供的 Table 方法来显式指定要查询的表名。例如:
DB.Table("custom_table_name").First(&model)
这将查询名为 custom_table_name 的表中的第一条记录,并将结果保存到 model 变量中。
了解完这些东西之间来看个例子,这个例子看得懂就代表入门了
package mainimport ("gorm.io/gorm""gorm.io/driver/mysql"
)type Product struct {gorm.ModelCode stringPrice uint
}func main() {db, err := gorm.Open(mysql.Open("test.db"), &gorm.Config{})if err != nil {panic("failed to connect database")}// 迁移 schemadb.AutoMigrate(&Product{})// Createdb.Create(&Product{Code: "D42", Price: 100})// Readvar product Productdb.First(&product, 1) // 根据整型主键查找db.First(&product, "code = ?", "D42") // 查找 code 字段值为 D42 的记录// Update - 将 product 的 price 更新为 200db.Model(&product).Update("Price", 200)// Update - 更新多个字段db.Model(&product).Updates(Product{Price: 200, Code: "F42"}) // 仅更新非零值字段db.Model(&product).Updates(map[string]interface{}{"Price": 200, "Code": "F42"})// Delete - 删除 productdb.Delete(&product, 1)
}
案例全方位解读:
db.AutoMigrate(&Product{}),这个操作就是创建表,按照Product结构体的结构来创建。
我有个问题:这个函数实际上叫自动迁移,为什么?
回答:迁移在数据库领域通常指的是数据库结构的变更操作,包括创建表、删除表、添加字段、删除字段等。在Gorm中,AutoMigrate方法的作用是自动创建表,但它也可以用于更新表结构。
虽然一开始创建表的时候使用AutoMigrate可能不会有太多表结构的变更,但当你的应用程序逐渐演进,可能会需要添加新的字段或修改字段类型等操作。这时你可以再次允许AutoMigrate,它会根据模型定义检测表结构的变更,然后执行相应的数据库迁移操作,使数据库结构与模型定义保存一致。
所以,尽管AutoMigrate的主要作用是创建表,但它也可以用于将表结构与模型定义同步,因此被称为数据库迁移,可以报纸数据库与应用程序的模型定义一致性。
db.Create(&Product{Code: “D42”, Price: 100})
这个函数用于创建一个新的数据库记录,插入到数据库里。参数就是一个结构体指针,这里面之间进行了结构体初始化操作,由于要的指针,所以这里取地址。
db.First(&product, 1) // 根据整型主键查找
db.First(&product, “code = ?”, “D42”) // 查找 code 字段值为 D42 的记录
- db.First是GORM中用于查询数据库的函数,它的作用是查询符合条件的第一条记录并将结果存在指定的结构体遍历中,注意必须是指针。
- 一个衍生思考:如果我的查询返回了多条记录,这个时候我就需要搞一个结构体切片来装结果了。而且返回多条记录一半用的查询函数是Find。
- 主键通常是用于唯一标识每个记录的字段,而在Gorm中,你可以使用First函数通过主键来查找特定记录,如果你的数据表没有明确的主键字段,你可以在GORM模型中使用gorm:“primaryKey” 标签来指定一个字段作为主键。
- 关于这个First的查询条件,First只支持一个查询条件,多了就要用where来查询。还有看这个例子中,这个参数的格式要记一下,?是代表占位符的意思。
db.Model(&product).Update(“Price”, 200)
这个操作仅仅只是将表里面字段为Price值全改为了200.是不是感觉显得非常的不方便。这也是我的疑问。
具体分析这个函数db是数据库连接对象,Model那个就是指定要查哪张表,然后才是UPdate操作。
这里我就在想,能不能实现对某些数据的这个字段值进行修改,然后我就去查了资料。
db.Model(&product).Where(“ID = ?”, 1).Update(“Price”, 200)
我把这种称之为链式调用。
db.Model(&product).Updates (Product{Price: 200, Code: “F42”})
这个的意思是把Product的Price和Code这两个字段全部修改为200,“F42”,这样就实现了多字段修改。而且默认仅更新非0字段。如果某个字段的新值是零值,那么它不会被更新到数据库中。这有助于避免不必要的数据库操作。只更新实际发生了实际更改的字段。如果想要更新所有字段,包括非0字段,可以在链式调用上加一个Unscoped(),用于取消默认的非0值过滤。
这条语句后,会更新所有符合条件的记录的 Price 字段为 200,但只有原本 Price 字段的值非零的记录才会被更新。如果某条记录的 Price 字段原本为 0,那么它不会被更新为 200,而是保持为 0。.Unscoped() 方法用于关闭 GORM 的软删除功能,它会将软删除的记录也包括在查询中,因此如果在语句后加了 .Unscoped(),那么所有的记录都会被查询并更新,不受软删除的影响。所以,即使某条记录的 Price 字段原本为 0,加了 .Unscoped() 后也会被更新为 200。
db.Model(&product).Updates(map[string]interface{}{“Price”: 200, “Code”: “F42”})
这调语句的效果和上面一样,但是这条语句是利用了map存要如何修改。
db.Delete(&product, 1)这就单纯的就是删记录。后面这个1是删除主键为1的记录。
注意:Delete就不像上面的First一样好用,这里只能按照主键值来删除记录。如果要是想通过条件来删除记录,就要像我之前做的衍生一样,要配合where来查询。
db.Where(“condition”).Delete(&Product{}),Delete里面这个参数就是要删除的记录所属的模型类型。
最重要的一点:这个删除并非是把记录删除,而是软删除
一点个人思考:
1.你会发现,我这些查找几乎都没有指定表,那你肯定就会有这样的疑惑,要是数据库里面表很多,那这个语句怎么知道该查哪张?
回答:它是根据结构体的结构来进行判断查哪张表的,因为我传参必须传一个结构体去接查询的结构。它是根据这个结构体的结构来判断的。
2.我发现这些函数没有返回值,这也可能是我习惯了go语言,感觉是个库函数都有返回值。这里就可以做个对比记忆。这是没有返回值的。
3.如果我写一个函数来进行更新写函数来进行删除
这样也能实现操作,为什么能实现,因为用的全是指针。
func update(db *gorm.DB){var p Productdb.First(&p,1)db.Model(&p).Update("Price",1000)db.Model(&p).Updates(Product{Price:1001,Code:"1002"})
}
func del(db *gorm.DB){var p Product db.First(&p,1)db.Delete(&p,1)
}
但是这么做我有一个很大的疑问:
我从这个代码来分析我写的这个函数就感觉只是取到了记录放在p里面,然后把p删了,这为什么能够实现数据库里面这条记录也删除了
回答:
这实际的过程是这样的:对于我这个代码:我是先使用了first方法,检索到了记录,然后发那个到了这个Product类型的变量p中,GORM内部实际上是执行了一个SQL查询,找到了这条记录,p变量现在包含了这条记录的所有字段数据。
随后我调用Delete方法传入p时,GORM不仅仅是删除了p在go程序中的对象,重要的是,GORM根据p中的信息(尤其是主键字段)构造了一个SQL删除语句,然后再数据库上执行了这个语句。这个删除语句实际上是根据p对象的主键值(在本例中ID为1)来定位和删除数据库中的相应记录。
因此虽然在GO程序中,p只是一个变量,但Gorm使用p的信息与数据库中的记录建立了练习,并在数据库中执行了相应的删除操作。这就是为什么删除p可以导致数据库中相应记录被删除的原因。简而言之,GORM通过p中存储的信息(比如主键)与数据库表中的记录建立了映射,并执行了相应的SQL操作。
4.Delete是软删除,这里来看怎么实现之间在数据库中真正干掉这条数据
方法1:db.Unscoped().Delete(&product)
方法2:更改模型定义: 如果你想要更改模型的默认删除行为,从而使 Delete 方法总是执行硬删除,你可以在模型定义中去掉 gorm.Model 的嵌入或者不定义 DeletedAt 字段。例如:
type Product struct {gorm.Model// 其他字段
}我现在不用这个,因为里面有DeletedAD字段,我用这个
type Product struct {ID uint `gorm:"primary_key"`CreatedAt time.TimeUpdatedAt time.Time// 注意,没有 DeletedAt 字段// 其他字段
}5.软删除和硬删除各有其好处,关键看应用场景
软删除的好处
数据安全和恢复: 软删除的最大优势是安全性。如果记录被错误地删除,它可以轻松地恢复,因为数据实际上仍然存储在数据库中。
数据完整性: 在有外键依赖的情况下,软删除可以防止违反引用完整性。即使一条记录被标记为删除,依赖于它的其他记录仍然可以保持其引用完整性。
历史数据保留: 对于需要保留历史记录的应用(例如,为了审计或分析目的),软删除可以保留所有交易的历史。
避免意外删除: 软删除减少了因意外删除数据而导致的风险和影响。
硬删除的好处
节省空间: 硬删除可以节省存储空间,因为删除的数据不会占用数据库空间。
性能优化: 对于大型数据库,移除不再需要的数据可以提高查询性能,尤其是在处理大量数据的表时。
数据清洁: 硬删除可以保持数据库的清洁和整洁,特别是当删除的数据不再具有价值或不需要保留时。
简化数据管理: 在某些情况下,硬删除可以简化数据管理和维护,因为只有当前有效的数据被保留在数据库中。
gorm声明模型
模型就是标准的struct
例如:
type User struct {ID uintName stringEmail *stringAge uint8Birthday *time.TimeMemberNumber sql.NullStringActivatedAt sql.NullTimeCreatedAt time.TimeUpdatedAt time.Time
}gorm 倾向于约定,而不是配置,默认情况下,GORM使用ID作为主键,使用结构体名的蛇形复数作为表名,字段名的蛇形作为列名,并使用CreatedAt、UpdatedAt字段追踪创建和更新时间。
关于这个蛇形复数我要讲一下,我确实不知道什么是蛇形复数,这里做一个学习:
蛇形命名法(Snake Case)和蛇形复数指的是一种特定的字符串格式,主要用于编程和数据库命名中。在蛇形命名法中,单词之间使用下划线(_)连接,且所有字符通常都是小写的。而蛇形复数则是指在蛇形命名法的基础上,将名词转换为复数形式。
举个例子:
蛇形命名法(Snake Case)示例
单个单词:user
多个单词:user_profile、order_history、record_status
对于上面这个结构体来说
字段CreatedAt 迁移到数据库中那就是created_at
表名比如Product迁移到数据库,表名就是products
遵循GORM已有的约定,可以减少配置和代码里。如果约定不符合你的需求,Gorm允许你自定义它们。
gorm.Model
这个是gorm自定义的结构体
// gorm.Model 的定义
type Model struct {ID uint `gorm:"primaryKey"`CreatedAt time.TimeUpdatedAt time.TimeDeletedAt gorm.DeletedAt `gorm:"index"`
}我们把他嵌入进我们字节的结构体,以包含这几个字段。
`gorm:"primaryKey"这个就是显示声明主键,主键是用来唯一标识记录的。在数据库表中,主键是唯一的,并且用于标识表的每一行,通常,主键是自动递增的。
在没有显示指定主键的情况下,GORM会默认寻找名为ID的字段作为主键。通过显式声明可以确保无论字段名或者结构如何变化,GORM都能准确识别哪个字段是主键。这在设计数据库主键时非常灵活。
gorm:"index"这个是结构体字段标签,用于给GORM提供额外信息,在GORM中,这些标签用来定义模型与数据库之间的映射关系及其他一些数据库相关的操作和属性。
解释gorm:“index”,这个标签只是GORM为该字段创建了一个数据库索引,数据库索引是数据库管理系统中用于提高数据检索速度的一种数据结构。
为什么要用索引?
1.提高查询性能:在频繁查询的列上创建索引可以显著提高查询效率,尤其是大数据集上。
2.DeletedAt字段的特殊用途:在GORM中,DeletedAt通常用于实现软删除(即标记记录为删除,但不是真的从数据库上完全删除)。**在执行查询时,GORM会自动过滤调被标记为删除的记录。**因此在DeletedAt字段上创建索引可以帮助数据库更快地识别出哪些记录是活动的,哪些是已被软删除的。
总之就是在查询性能的优化上有很大作用。
高级选项
字段级权限控制
可导出的字段在使用 GORM 进行 CRUD 时拥有全部的权限,此外,GORM 允许您用标签控制字段级别的权限。这样您就可以让一个字段的权限是只读、只写、只创建、只更新或者被忽略。
什么是可导出的字段?
在 Go 语言中,“可导出的字段”(Exported Field)指的是可以被其他包访问的字段。Go 语言通过字段名称的首字母的大小写来控制访问权限。如果一个字段的名称以大写字母开头,那么这个字段就是可导出的(public),可以被其他包访问。相反,如果一个字段名称以小写字母开头,那么这个字段是不可导出的(private),只能在其定义所在的包内部访问。
可导出字段例子:
type User struct {Name string // 可导出字段,因为 Name 是以大写字母开头age int // 不可导出字段,因为 age 是以小写字母开头
}在这个例子中,Name 字段可以被其他包访问和修改,因为它是以大写字母开头的。而 age 字段则只能在定义它的包内部使用。
在Gorm中的意义:
当使用 GORM(一个 Go 语言的 ORM 库)进行数据库操作时,它只能操作可导出的字段。也就是说,GORM 可以读取和修改那些以大写字母开头的字段,因为这些字段在包外是可见的。这是因为 GORM 需要能够从其他包访问这些字段,以便执行 CRUD(创建、读取、更新、删除)操作。如果一个字段不是可导出的,GORM 将无法直接操作这个字段。
因此,当你使用 GORM 定义一个模型用于数据库操作时,你需要确保所有需要由 GORM 直接操作的字段都是可导出的。
继续来看权限控制
type User struct {Name string `gorm:"<-:create"` // 允许读和创建Name string `gorm:"<-:update"` // 允许读和更新Name string `gorm:"<-"` // 允许读和写(创建和更新)Name string `gorm:"<-:false"` // 允许读,禁止写Name string `gorm:"->"` // 只读(除非有自定义配置,否则禁止写)Name string `gorm:"->;<-:create"` // 允许读和写Name string `gorm:"->:false;<-:create"` // 仅创建(禁止从 db 读)Name string `gorm:"-"` // 通过 struct 读写会忽略该字段
}后面这些就是权限控制,了解一下。用到再看
注意使用GORM Migrator创建表时,不会创建被忽略的字段。
创建/更新时间追踪(纳秒、毫秒、秒、Time)
GORM 约定使用 CreatedAt,UpdatedAt 追踪创建/更新时间。如果您定义了这种字段,GORM 在创建、更新时会自动填充 当前时间.
要使用不同名称的字段,您可以配置 autoCreateTime、autoUpdateTime标签
type User struct {CreatedAt time.Time // Set to current time if it is zero on creatingUpdatedAt int // Set to current unix seconds on updating or if it is zero on creatingUpdated int64 `gorm:"autoUpdateTime:nano"` // Use unix nano seconds as updating timeUpdated int64 `gorm:"autoUpdateTime:milli"`// Use unix milli seconds as updating timeCreated int64 `gorm:"autoCreateTime"` // Use unix seconds as creating time
}加上了这个选项后就实现了自定义名称。
嵌入结构体
对于匿名字段,GORM 会将其字段包含在父结构体中,例如:
type User struct {gorm.ModelName string
}
// 等效于
type User struct {ID uint `gorm:"primaryKey"`CreatedAt time.TimeUpdatedAt time.TimeDeletedAt gorm.DeletedAt `gorm:"index"`Name string
}对于正常的结构体字段,你也可以通过标签 embbeded将其嵌入,例如:
type Author struct {Name stringEmail string
}type Blog struct {ID intAuthor Author `gorm:"embedded"`Upvotes int32
}
// 等效于
type Blog struct {ID int64Name stringEmail stringUpvotes int32
}并且,您可以使用标签 来为 db 中的字段名添加前缀,例如:
type Author struct {Name stringEmail string
}type Blog struct {ID intAuthor Author `gorm:"embedded;embeddedPrefix:author_"`Upvotes int32
}
// 等效于
type Blog struct {ID int64AuthorName stringAuthorEmail stringUpvotes int32
}字段标签:
声明model时,tag是可选的,GORM支持一下tag,tag名大小写不敏感。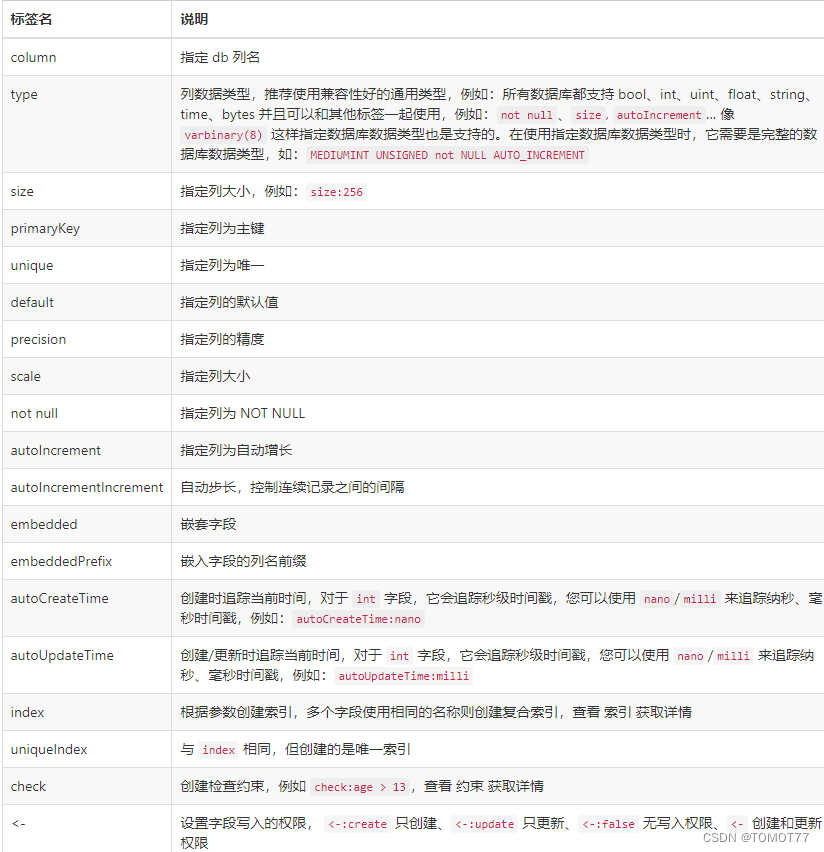

除此之外还有关联标签
关联标签
gorm允许通过标签为关联配置外键、约束、many2many表。这些后续再说
小结:
今天是第一天,说实话要是看视频,早学完了,但是学的难受,我在看视频的过程中有各种各样的问题和不解,但是这些问题我都去自己找了答案,现在看着gorm的代码感觉也不是那么烦心了。



是什么?如何在 Python 中实现一个简单的 ORM(对象关系映射)?)
)
)

)
)





![[python]基于opencv实现的车道线检测](http://pic.xiahunao.cn/[python]基于opencv实现的车道线检测)

关于李飞飞团队的ImageNet)


)