二月将至,ModelWhale 迎来开年首次版本更新,期待为大家带来更优质的使用体验。
本次更新中,ModelWhale 主要进行了以下功能迭代:
- 新增 模型检验(团队版✓)
- 优化 模型评审测试(团队版✓)
- 新增 自动评审‘数据源文件’(团队版✓)
- 新增 组织私有数据公开到和鲸社区(团队版✓)
- 新增 Canvas 支持 ipywidgets 渲染(专业版✓ 团队版✓)
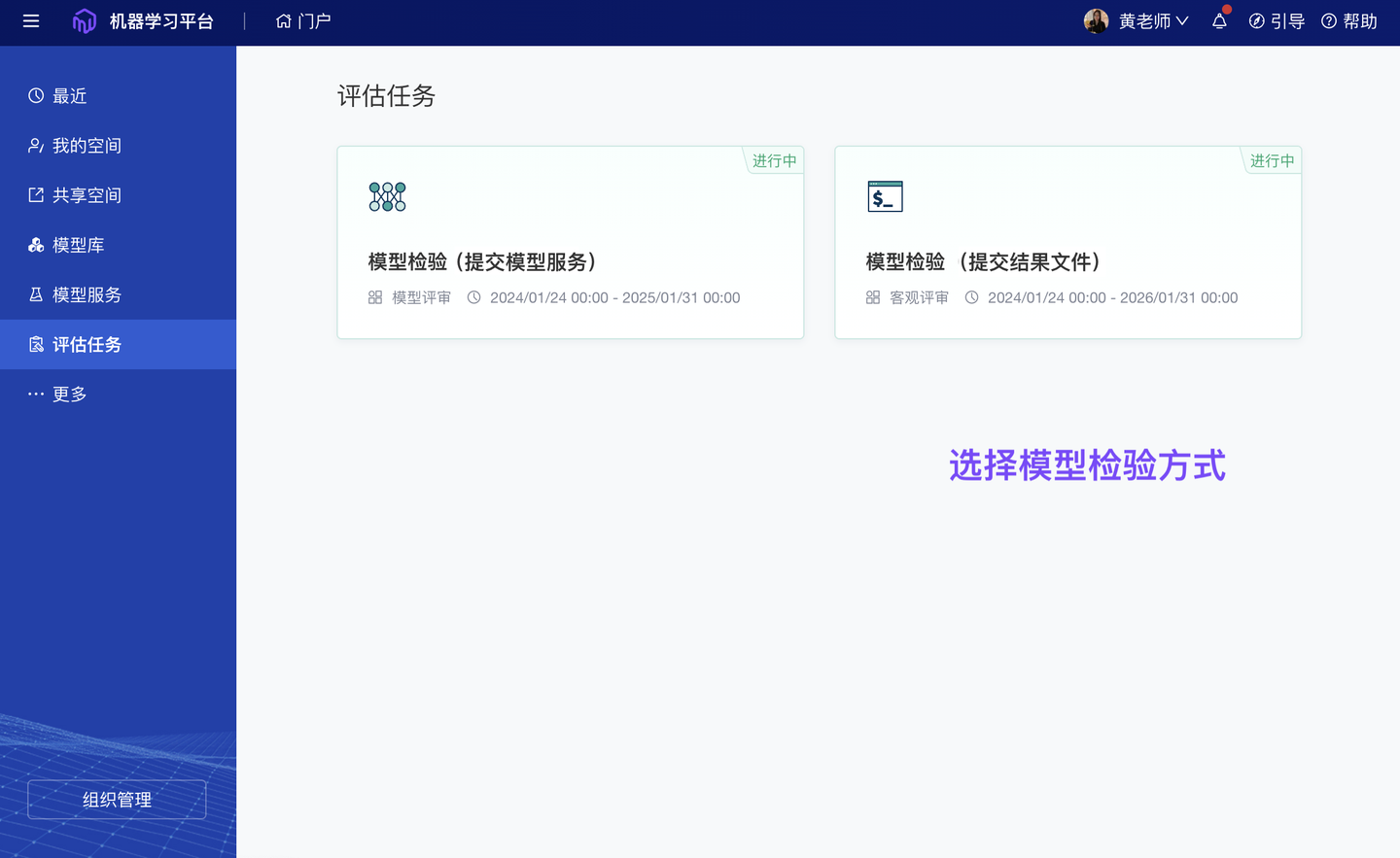
1、新增 模型检验(团队版✓)
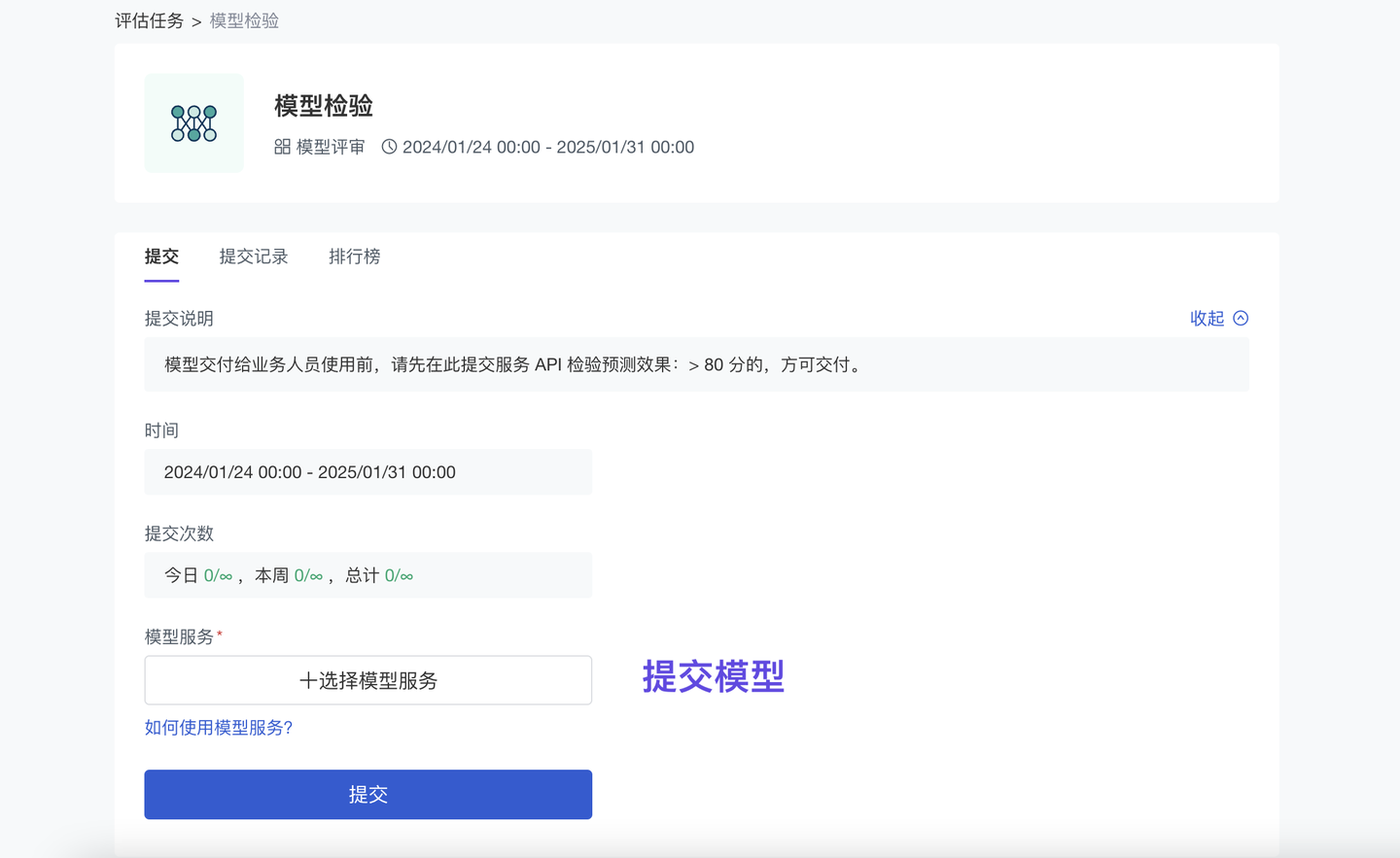
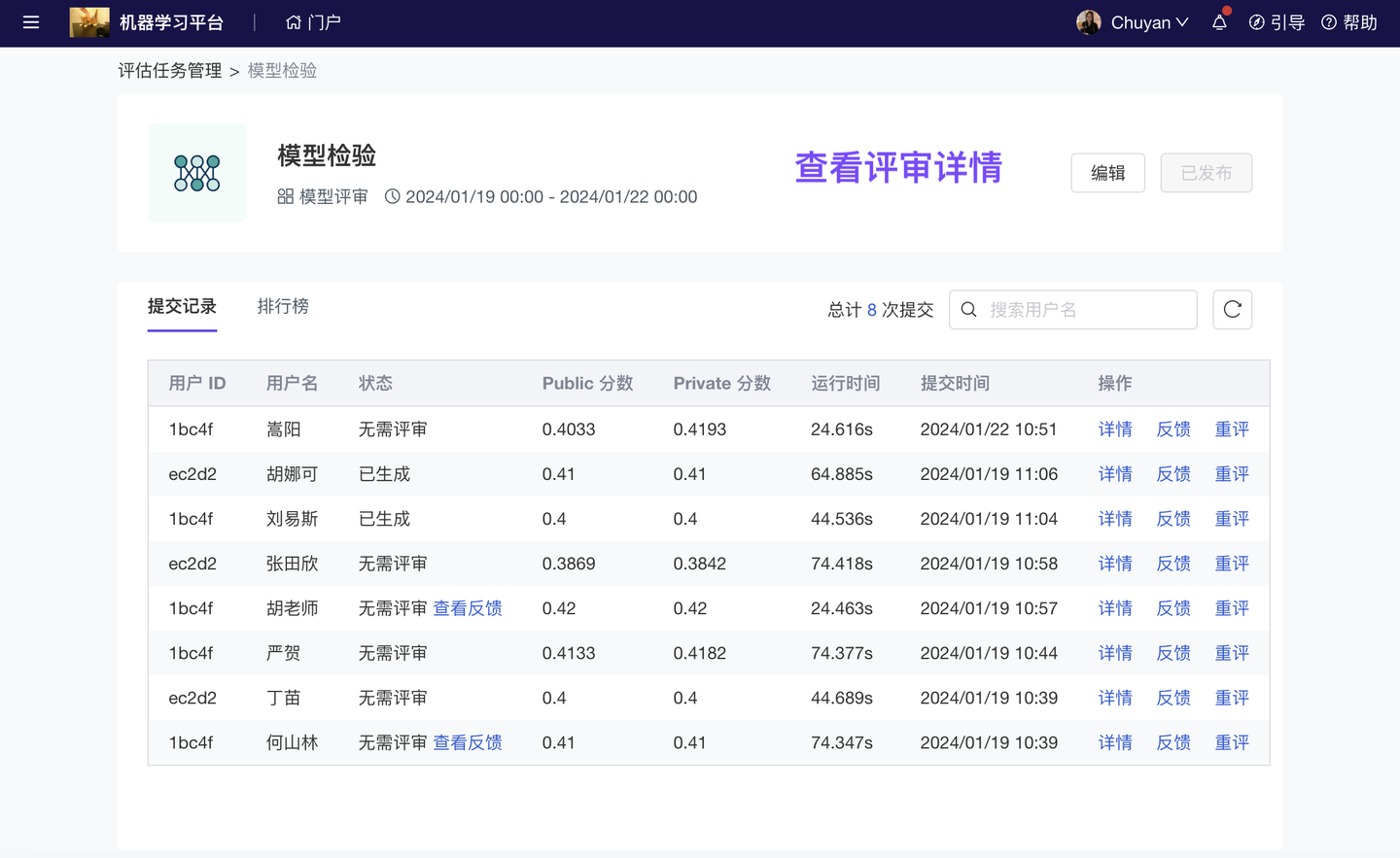
模型效果检验贯穿整个模型生命周期:训练时通过“历史数据”检验,业务应用后通过“真实使用数据”检验。算法竞赛中,主办方还会通过一些“评审算法”检验选手提交的模型作品。ModelWhale 基于多年在竞赛场景下的模型检验经验,新增【模型评估】功能模块(从已有竞赛系统抽离):支持通过多种业务指标(评审算法)自动化检验模型效果。以气象预测模型为例,可以通过「客观评审」比对“模型输出结果”和“实况观测数据”,评估预报准确性;如果模型输出结果较大(或已封装为服务 API 应用于实际业务场景),可以通过「模型评审」进行效果验证。
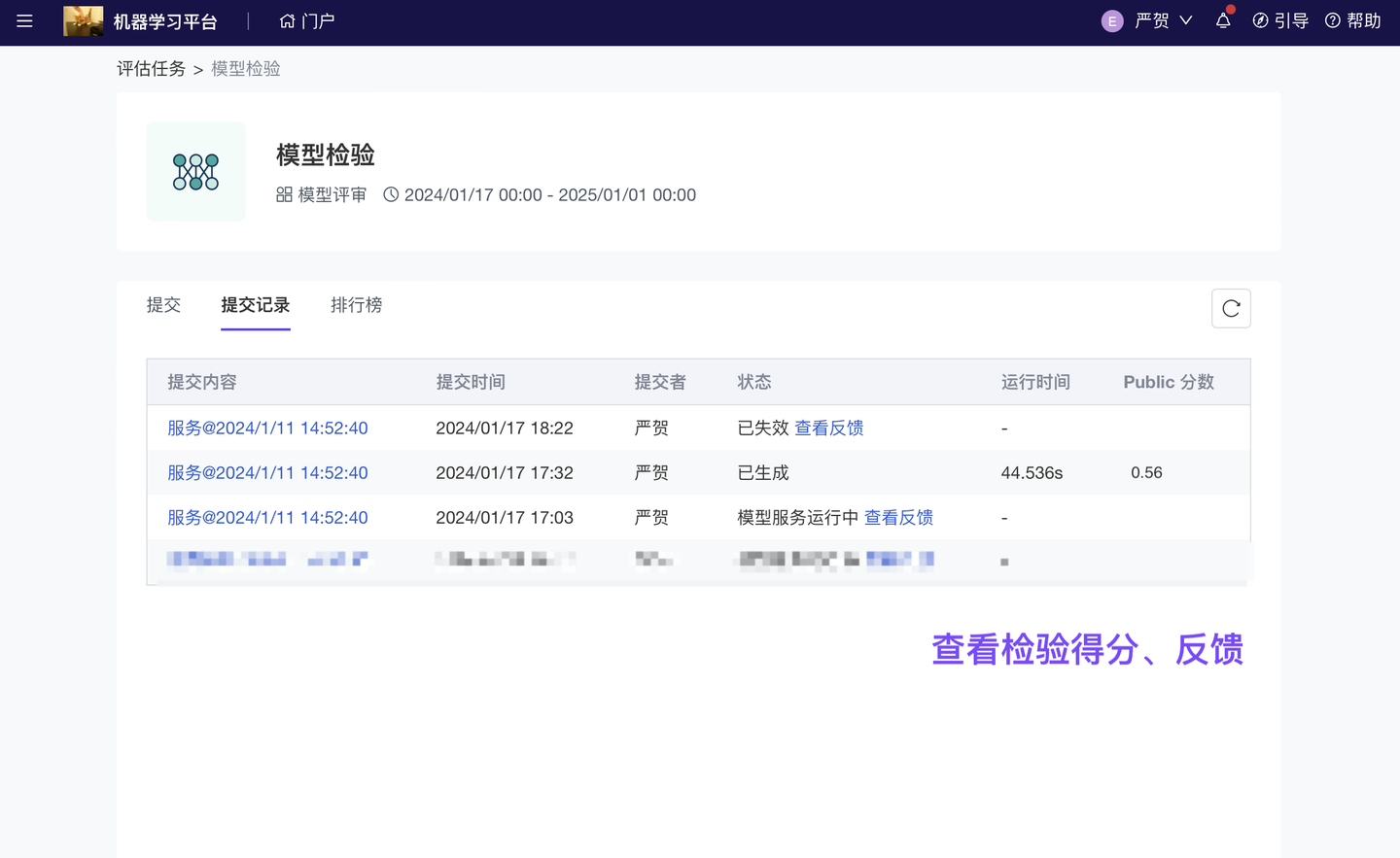
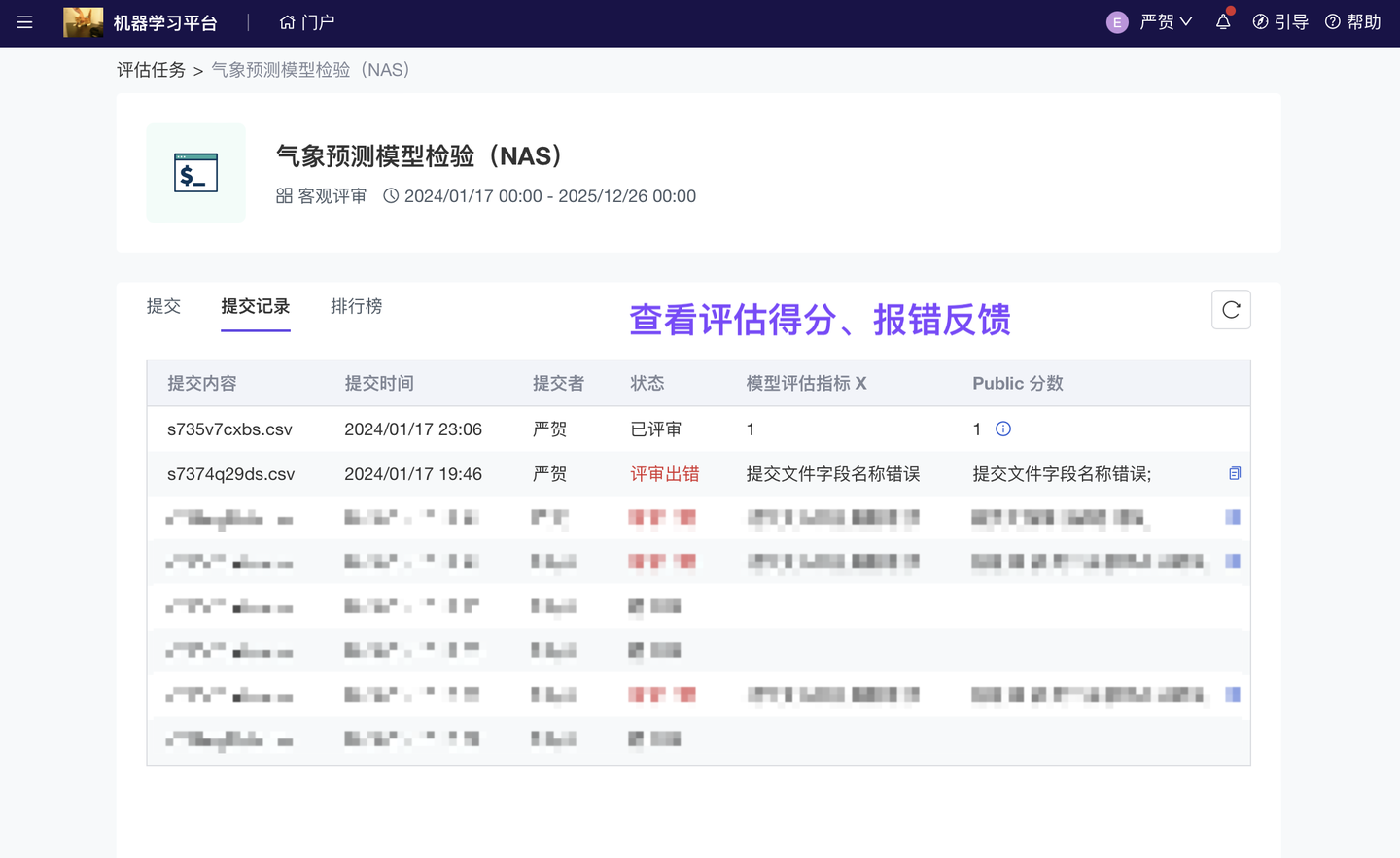
算法工程师提交“模型输出文件”或“模型服务应用”后,可即时获得模型评分、反馈;而,每个检验任务的配置(i.e 使用哪个检验指标、任务运行算力、提交格式规范)均可以由任务管理员(小组主管)按业务需求设计。
注:“模型服务应用”是 ModelWhale 产品功能,将模型部署为服务 API(或网站应用),以便应用于实际业务场景。模型服务配有运维监控系统:支持追踪服务的实际运行情况、输入及输出数据,可供进行模型调优。
更多详见:模型服务的监控和调用

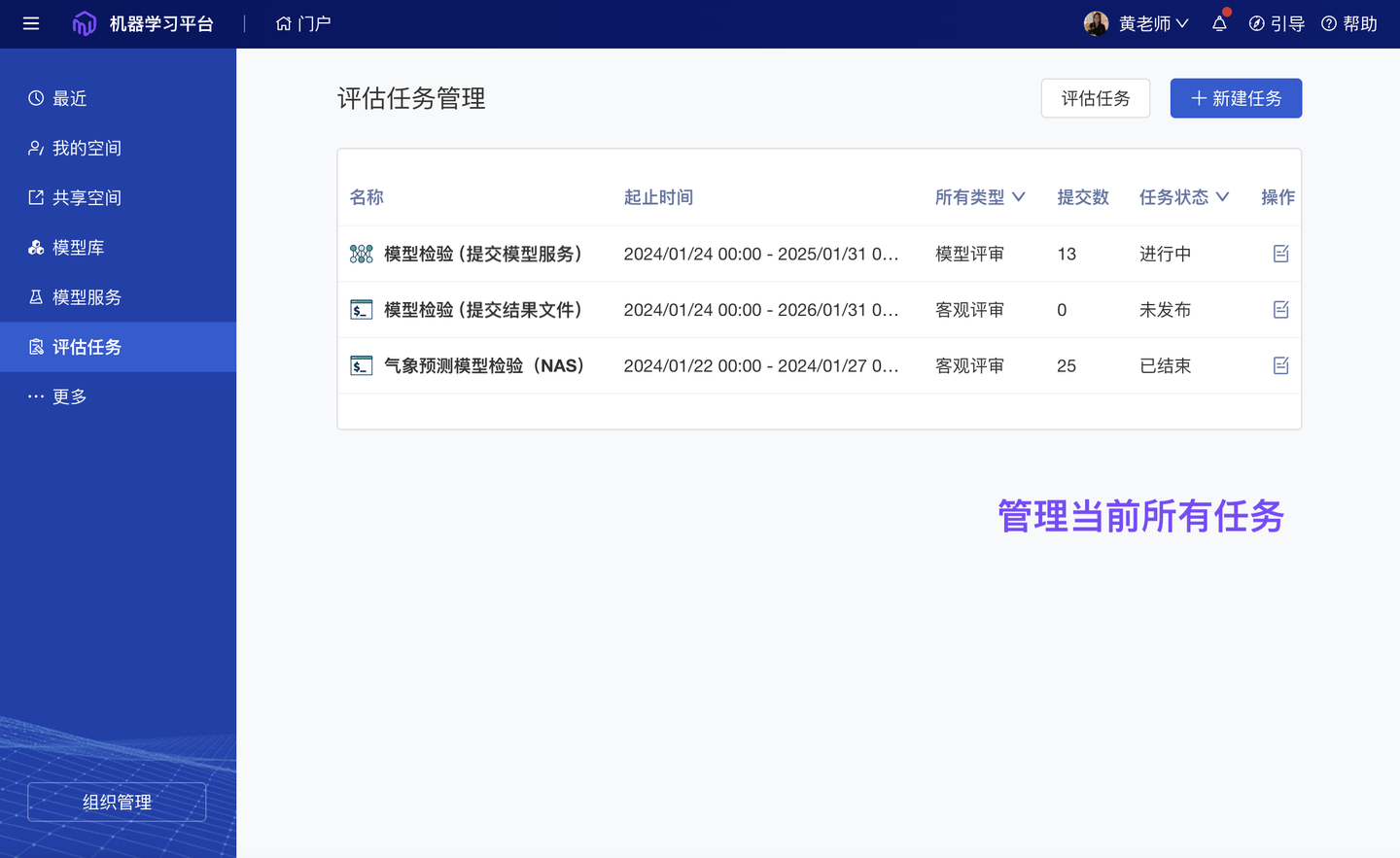
任务配置、管理(管理员)
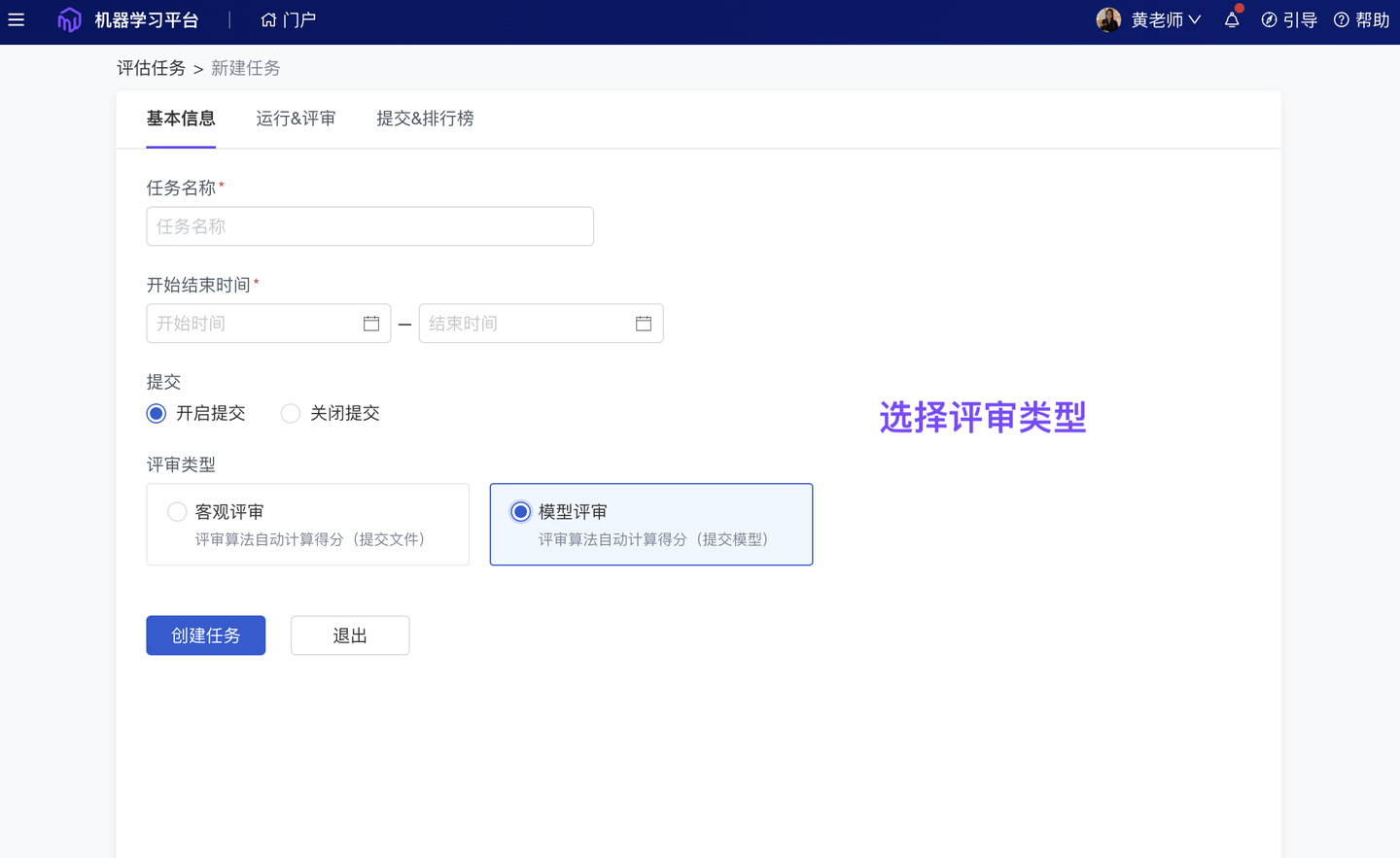

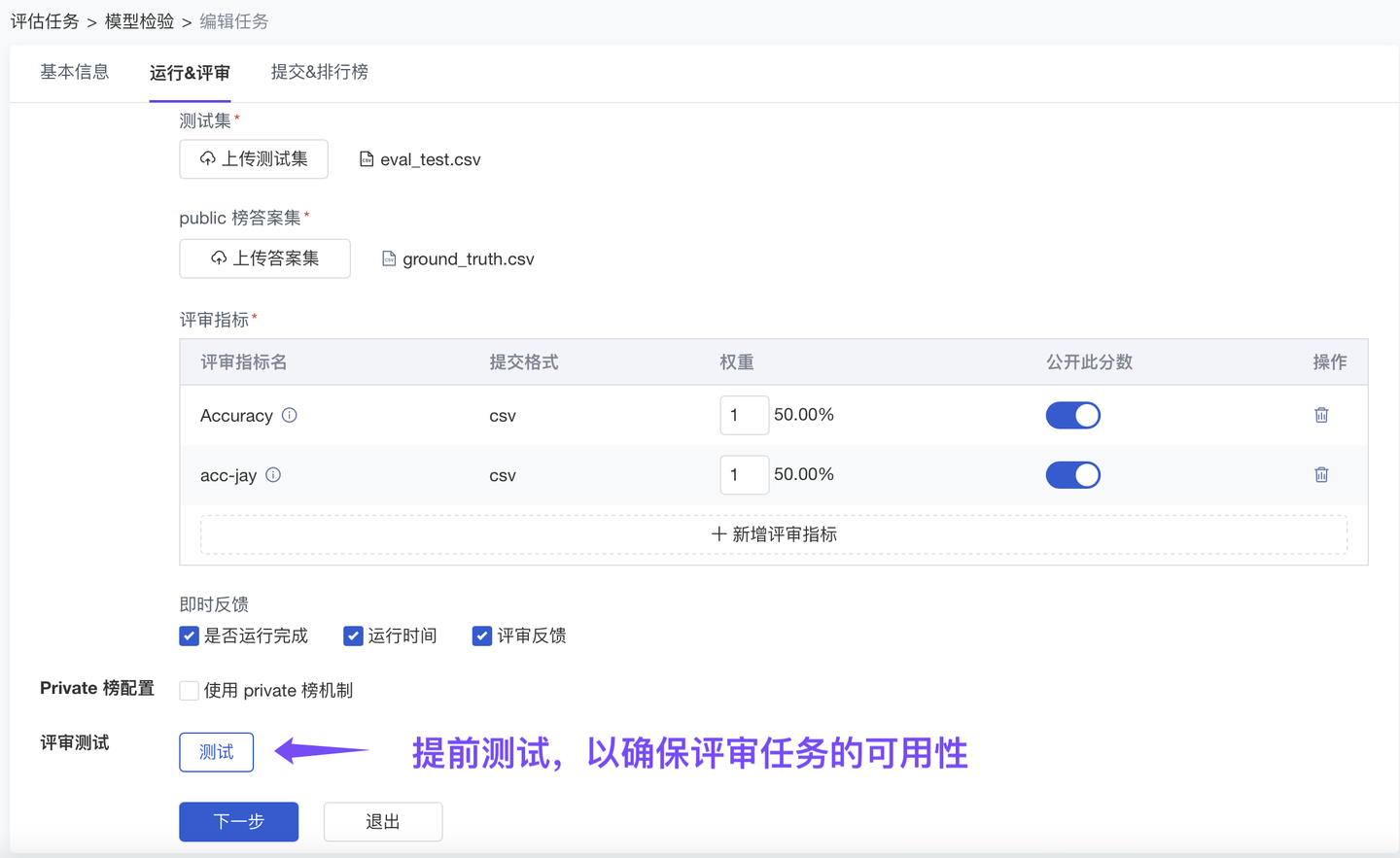
2、优化 模型评审测试(团队版✓)
仅评估“模型输出文件(传统的客观评审)”未必可以识别过拟合现象。ModelWhale 支持【模型评审】:通过运行算法工程师(或比赛选手)提交的“模型服务应用”,直接检验原始模型,更准确评估模型效果。为保证评审顺利进行(i.e 按规则出分反馈),现已优化评审测试:任务管理员可以在配置任务时获得测试反馈,如遇报错可依据调整,直至按预期出分后,再将任务发布、公开。

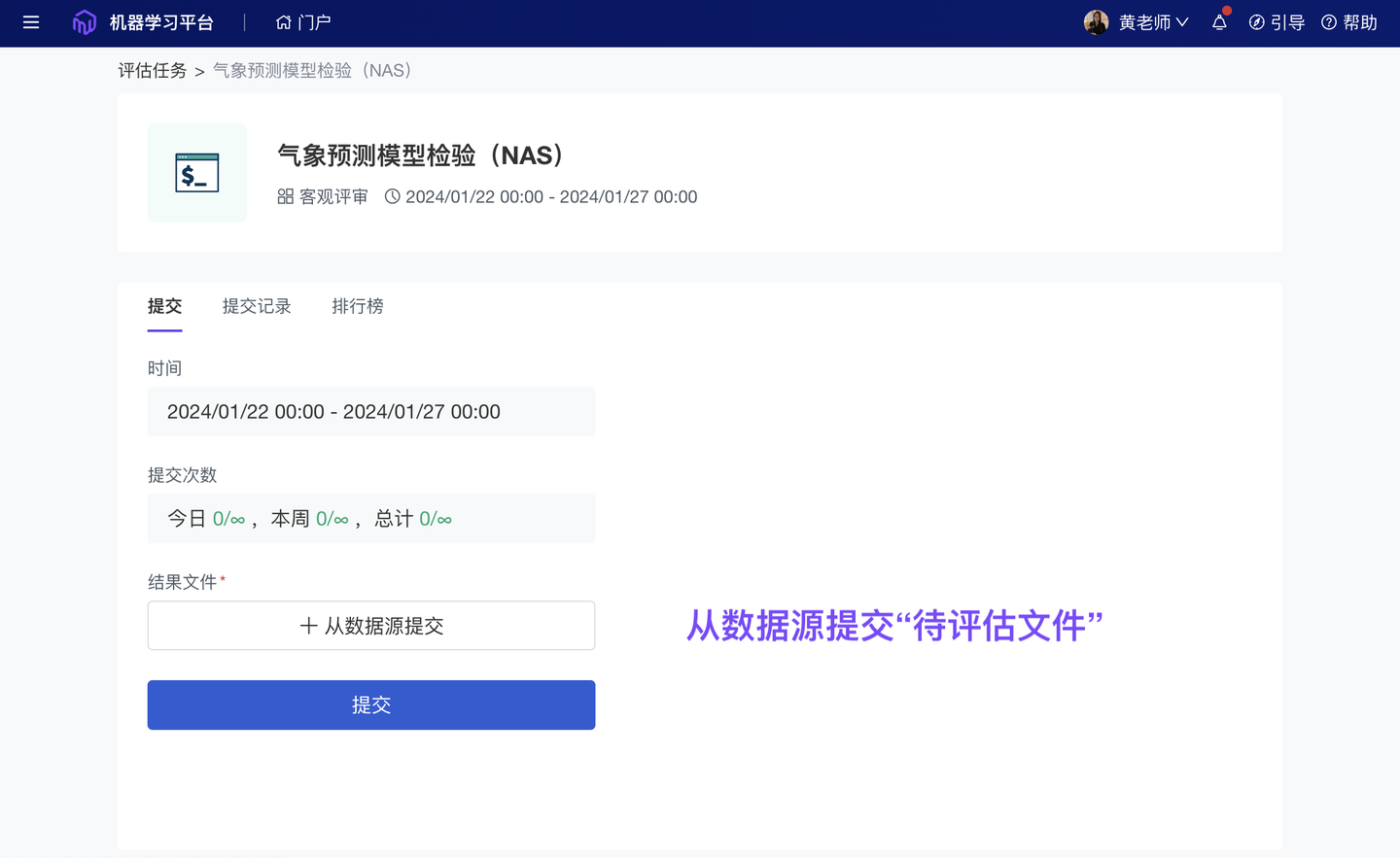
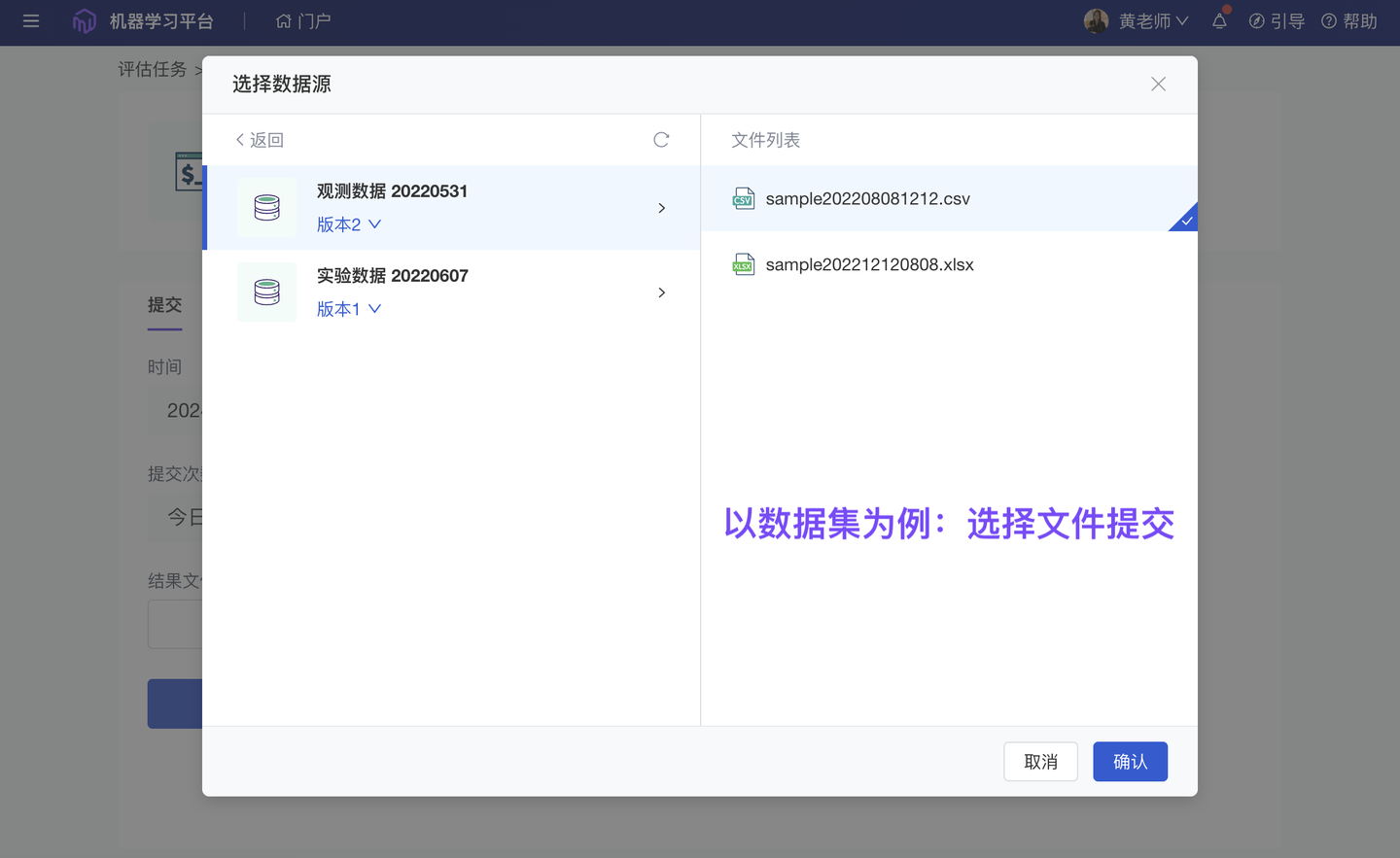
3、新增 自动评审‘数据源文件’(团队版✓)
ModelWhale 客观评审任务,支持按照“检验指标”自动评估提交的结果文件(本地/在线文件)。当需要评估的文件较大时(i.e 一些算法模型的输出较复杂):算法工程师(或比赛选手)现在可以选择将它们保存成“数据集”、保存至“对象存储”、“NAS 空间”,然后将对应位置的数据文件提交到评审任务,进行结果检验。
注:结果文件的提交来源(在线文件/数据源/本地文件)、提交方式(是否支持 Token 提交),均由任务管理员依据实际需求配置。

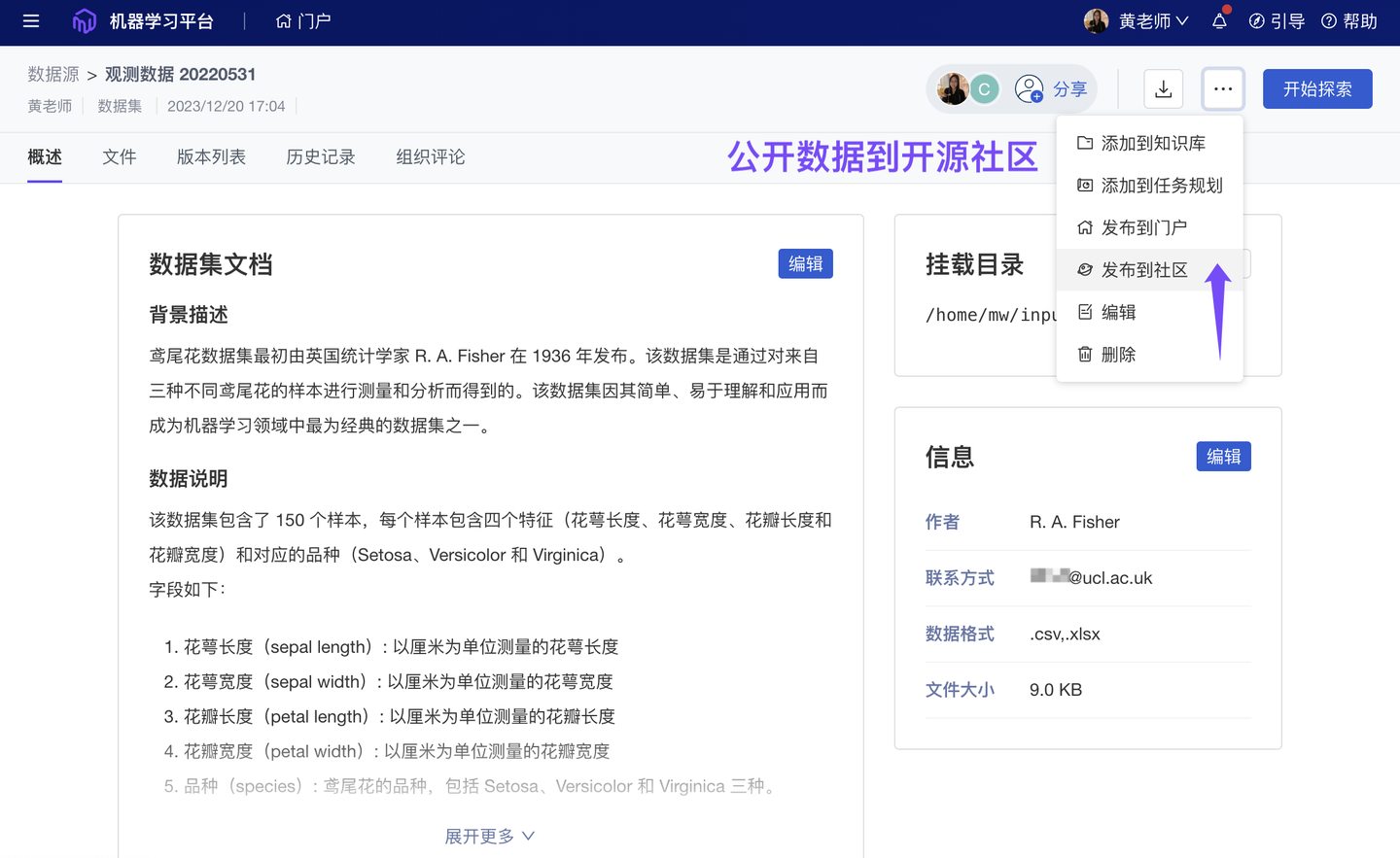
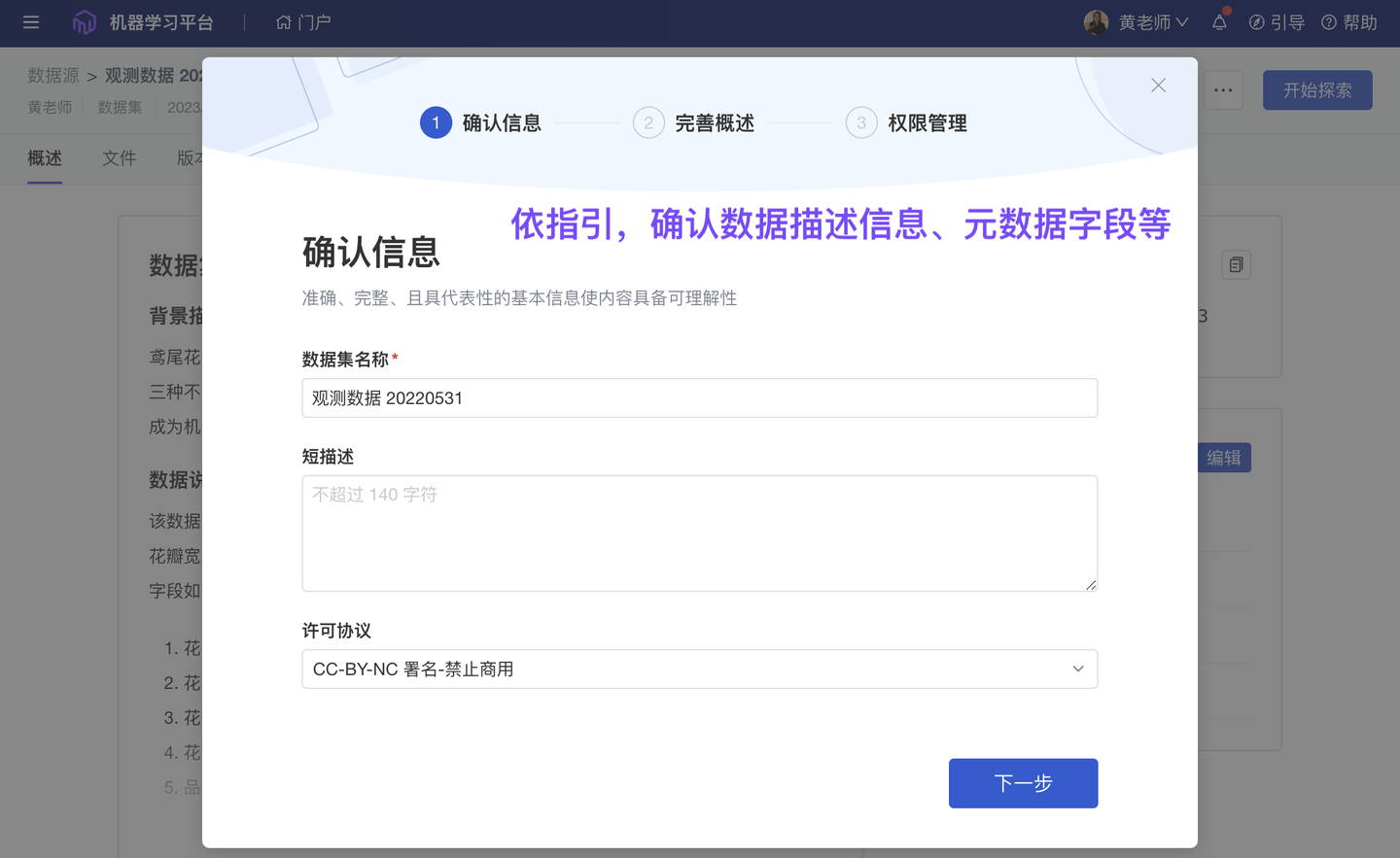
4、新增 组织私有数据公开到和鲸社区(团队版✓)
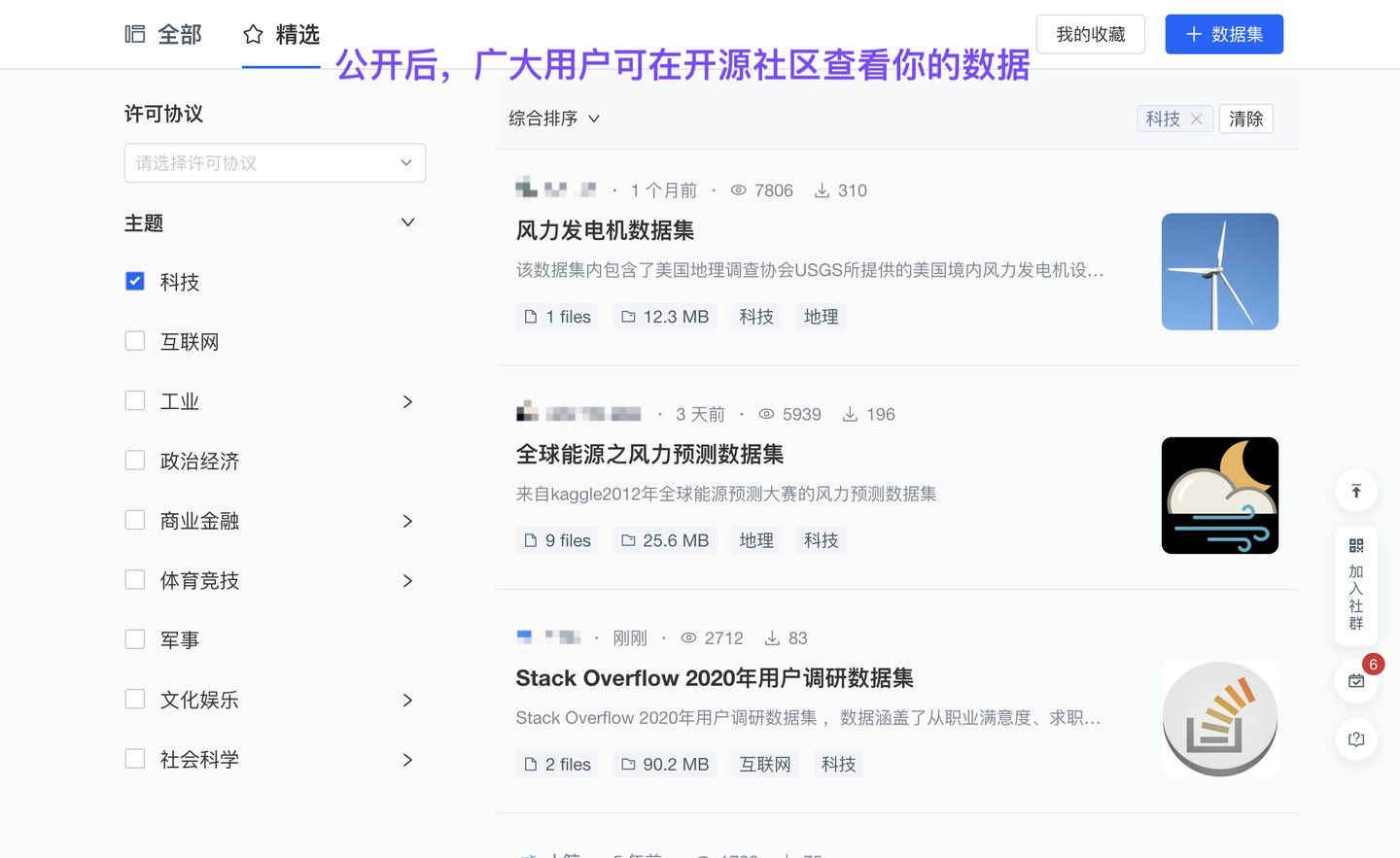
和鲸社区,汇聚由专业研究机构、行业垂类专家、优秀研究个人提供的丰富案例、数据集;它也与 ModelWhale 公有云平台关联:ModelWhale 组织内用户均可参考使用这些宝贵资源。与此同时,组织内的研究成果(分析报告、数据集)也支持一键【发布到社区】:供更多用户查看使用、讨论交流,以发挥更大影响力、创造更大社会价值。
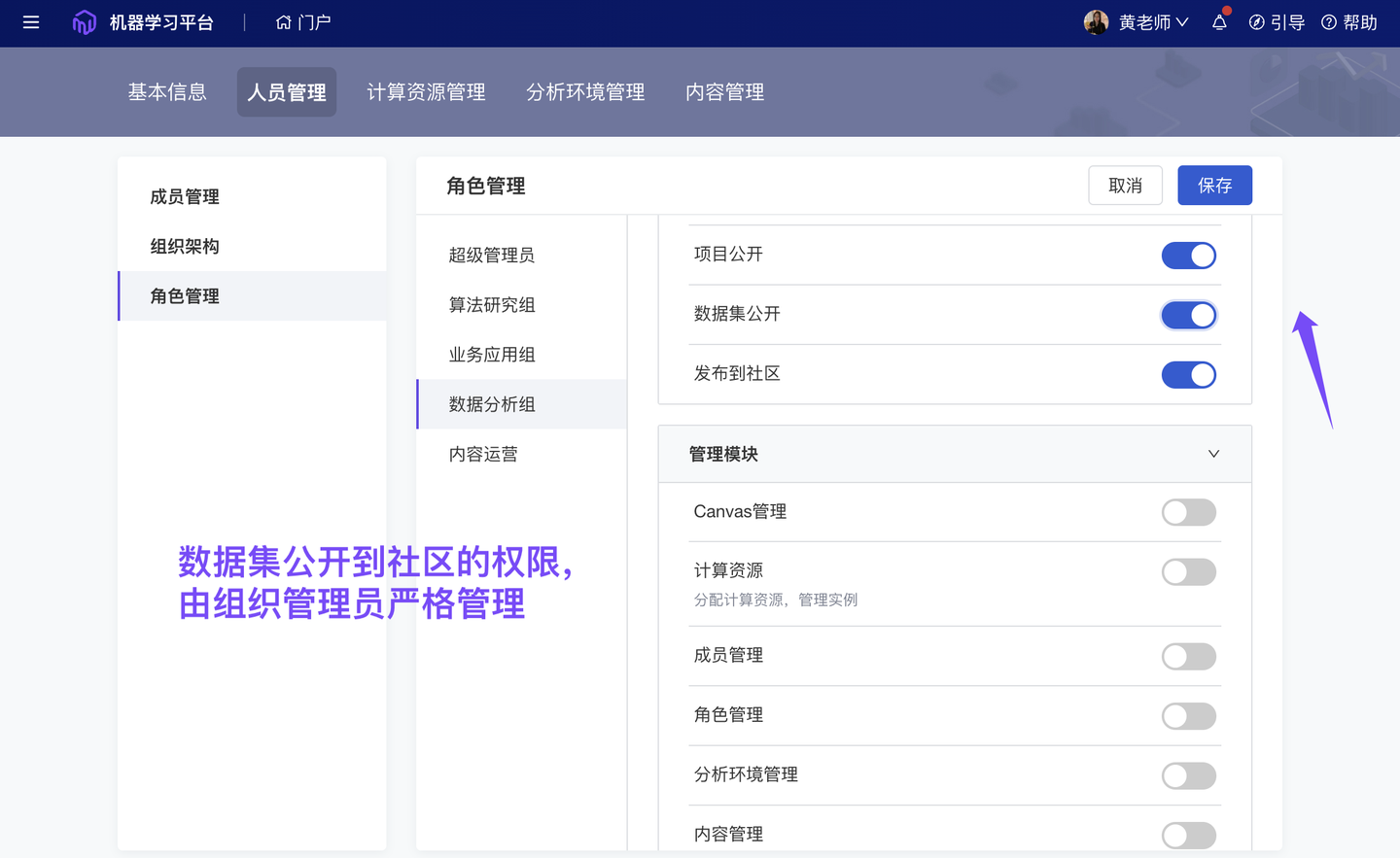
Tips:ModelWhale 重视“数据资产的安全问题”,公有云组织配有严格的权限管理系统 + 相对封闭的研究环境(私有化环境完全封闭),组织成员需获得“对应权限”方可公开自己的研究成果。
权限控制(管理员)
5、新增 Canvas 支持 ipywidgets 渲染(专业版✓ 团队版✓ )
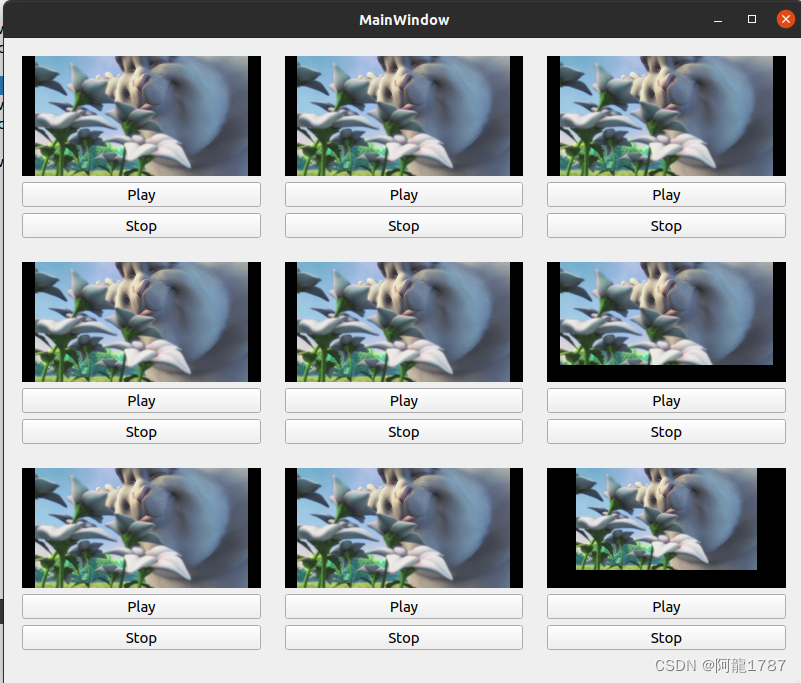
ipywidgets 交互控件,可用于 Notebook 内进行界面设计,实现简单的交互操作。现 ModelWhale Canvas 也已支持渲染 ipywidgets:你可以将在 Notebook 内跑通的分析流程(比如 含 ipywidgets 交互的分析流程),封装固化到 Canvas 中,以便其他同事后续更简洁的复用。下述图片展示一个视频标注的案例。
Tips:ModelWhale Canvas 的输入输出交互简单,可零代码实现算法调用、完成业务分析;
更多详见:ModelWhale Canvas 使用说明。
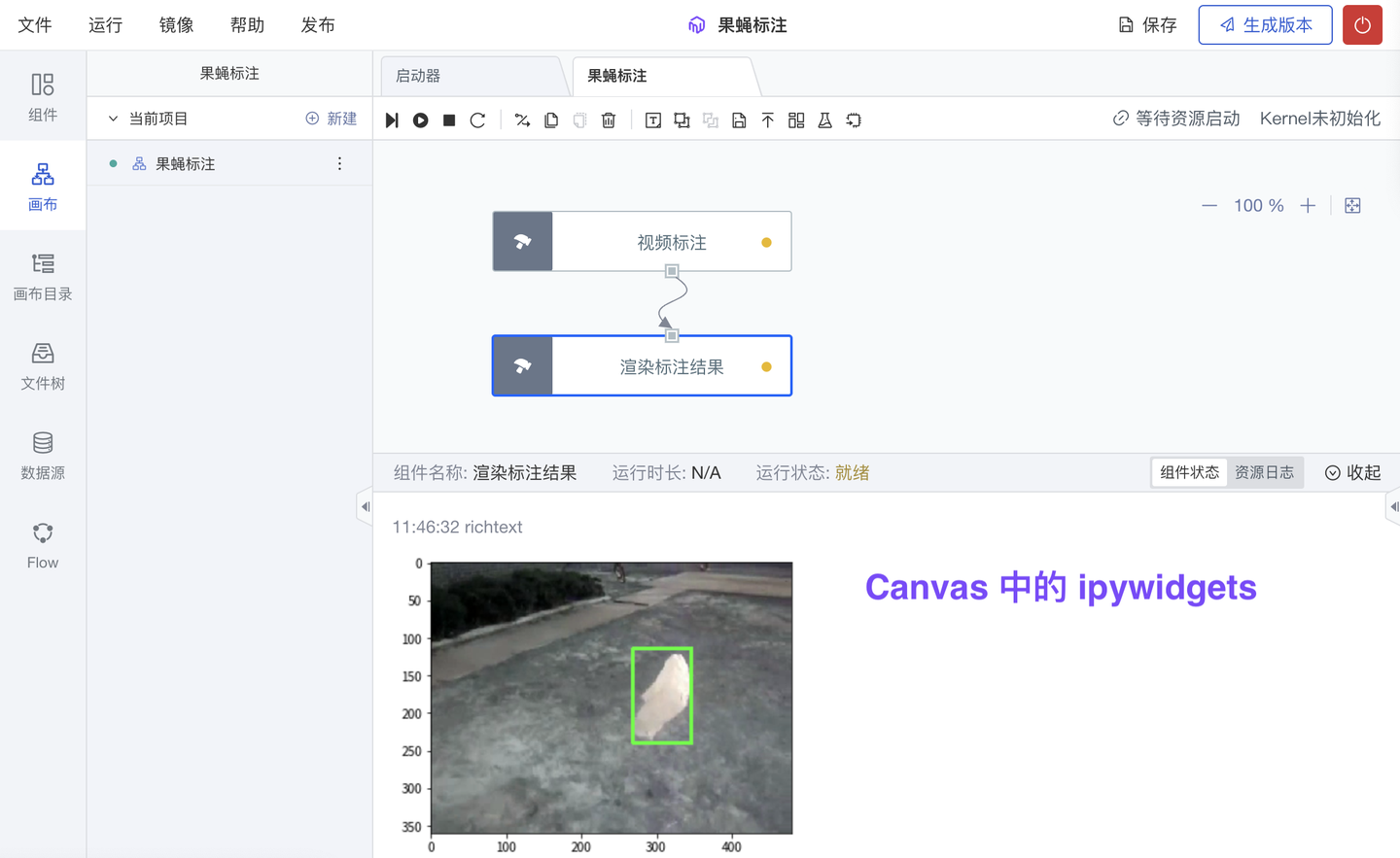
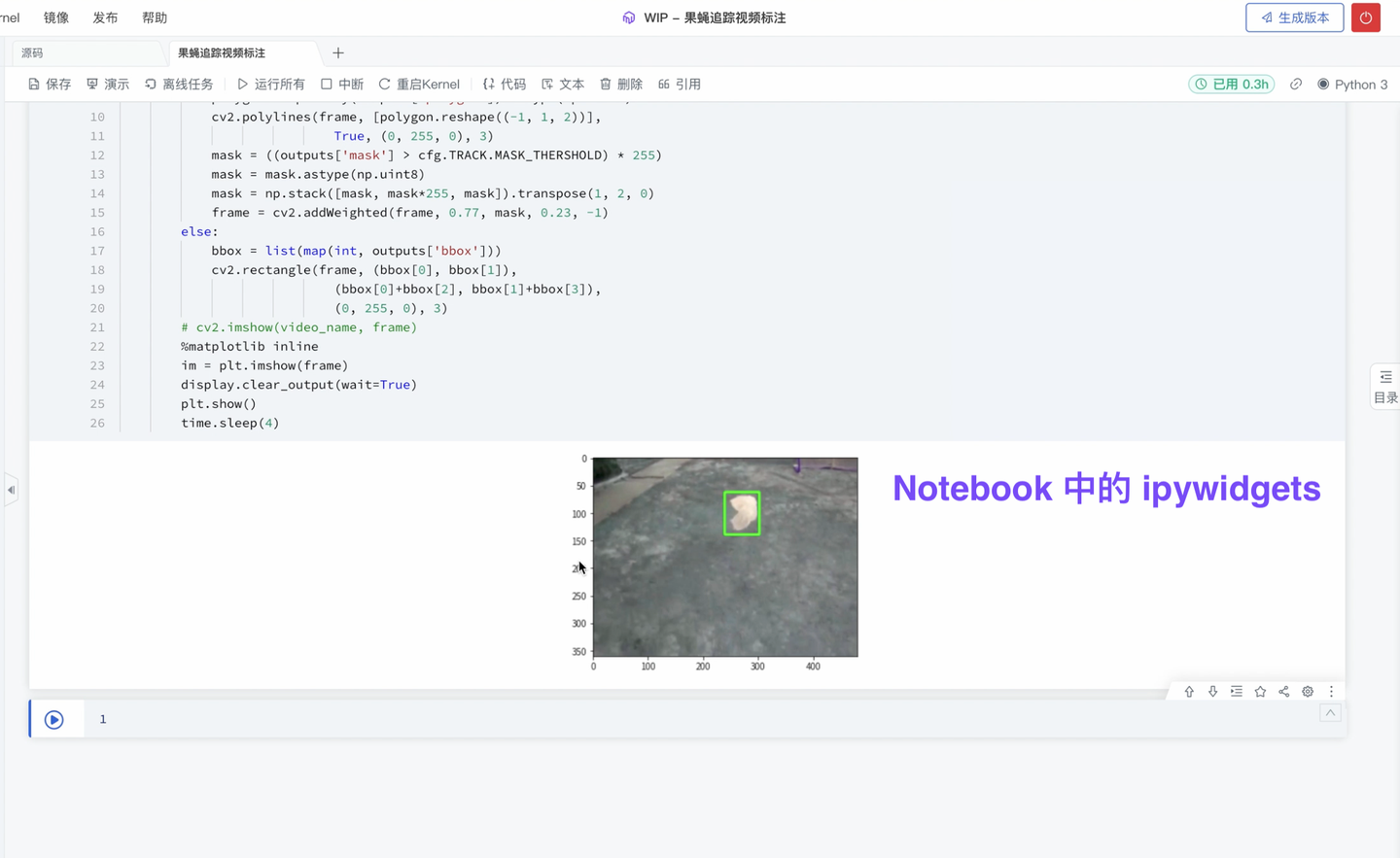
以上,就是本期 ModelWhale 版本更新的全部内容。
进入 Modelwhale 官网,免费试用 Modelwhale 专业版(个人研究)或团队版(组织协同),获赠 CPU、GPU 算力!(建议使用 pc 端体验试用)
若对 ModelWhale 有任何建议、疑问,或有试用续期需求,欢迎点击【联系产品顾问】,MoMo 很高兴为你服务、与你交流(咨询备注“产品咨询”)。