
1. 引言
在FPGA逻辑电路设计中,FPGA设计能达到的最高性能往往由以下因素决定:
▪ 工作时钟偏移和时钟不确定性;
▪ 逻辑延迟:在一个时钟周期内信号经过的逻辑量;
▪ 网络或路径延迟:Vivado布局布线后引入的延迟量。
Vivado软件完成布局布线后,我们可以打开时序分析报告,来查看时序没有过的路径是由哪些因素导致的时序违规。Vivado会通过列表形式展示每条时序违规路径的信息,如下图所示。

双击上面表中的其中一条路径,会展开关于该路径更详细的时序报告,如下图:
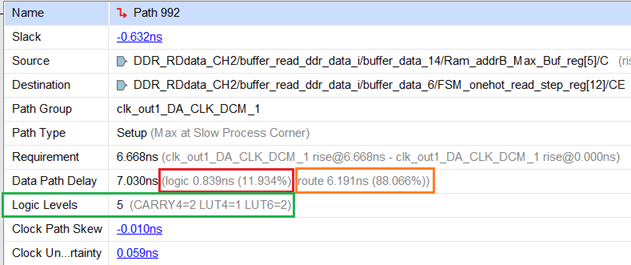
上图这个时序违例的例子,可以看到,该路径逻辑延迟贡献了11.934%的延迟量、路径延迟贡献了88.066%延迟量。该路径逻辑级数为5,经过了2个CARRY4、1个LUT4和2个LUT6。
2. 降低逻辑延迟的方法
如果逻辑延迟大,我们需要查看该路径是不是只包含CLB器件,还是说该路径还经过了如DSP、RAMB、URAM、FIFO或GT等器件。
2.1 路径只包含CLB器件
常规布线路径是在寄存器(FD*)或移位寄存器(SRL*)之间的路径,它们经过一些 LUT、MUXF 和 CARRY 元件。通常会遇到以下几种情形导致逻辑延迟过大:
(1)较高逻辑层数(logic levels)的组合电路。用户在两个寄存器之间插入的组合逻辑过于复杂,级联了过多的LUT、CARRY等元件,导致逻辑延迟过高时序过不了。如下图中,两个寄存器之间有一个logic levels为5层的组合逻辑。
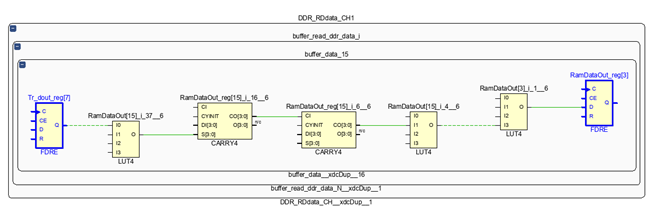
建议的解决方案:在设计的早期阶段,通过TCL命令“report_qor_assessment”,早些识别出逻辑层数较高组合逻辑,通过代码优化手段来降低逻辑层次。或者,在综合的时候,将“-retiming”全局变量勾选上。
(2)路径上有很多小的级联LUT(LUT1-LUT4)。这些多个小的级联查找表是可以被合并成数量更少的LUT的。阻止这些级联LUT合并的原因可能如下:
-
有些小的LUT表存在一些扇出(扇出为10,或者更高);
-
用户使用了一些properties语法,比如:KEEP、KEEP_HIERARCHY、DON’T_TOUCH或MARK_DEBUG。
建议的解决方案:移除掉这些properties语法,重新编译综合工程。
(3)路径上有单个CARRY(非级联)限制了LUT的优化,导致vivado布局也不是最优。
建议的解决方案:在综合的时候,使用“FewerCarryChains”综合指令。或者对该CELL在opt_design阶段设置CARRY_REMAP属性。(具体使用方法可以查看UG904)
2.2 路径包含其他复杂器件(DSP、RAM等)
如果时序路径上会经过宏原语元件(macro primitives)如DSP、RAM、URAM、FIFO或GT_CHANNEL等元件,布局布线的难度会加大,也会导致更高的布局布线延迟。降低这些路径的逻辑延迟方法如下:
(1)在进出宏原语元件电路周围,增加额外的流水结构。比如:
-
原设计是用的一个大位宽RAM缓存数据,把这个大位宽RAM拆分成多个并行的小位宽RAM实现相同的功能。
-
原设计乘法器为2级流水乘法器,把它改为2级以上的流水乘法器。
-
数据进出宏原语元件时,都用寄存器打一拍等。
(2)在包含宏原语元件的路径上减少逻辑层数,这点对改善整个设计的性能提升很明显。
Tips: 在修改RTL之前,可以尝试把DSP、RAM、URAM的自带流水寄存器使能都打开,然后重新编译工程,看时序是否能有改善。比如将下面这条路径:

设置如下属性:
set_property -dict {DOA_REG 1 DOB REG 1} [get_cells xx/ramb18_inst]
注意,由于使能这些寄存器后,逻辑时序会有变动,此时的RTL功能和你原先设计是有出入的,所以不用生成bitstream,这样操作的目的只是为了看时序能如何改善。





)
)

)


。 #经验分享#知识分享#媒体)
)
![[ARC145E] Adjacent XOR 题解](http://pic.xiahunao.cn/[ARC145E] Adjacent XOR 题解)

——从 AI 编程助手到 AI Agent 应用实战)



![[Git版本控制系统]](http://pic.xiahunao.cn/[Git版本控制系统])