多模态学习和注意力机制是当前深度学习研究的热点领域之一,而交叉注意力融合作为这两个领域的结合点,具有很大的发展空间和创新机会。
作为多模态融合的一个重要组成部分,交叉注意力融合通过注意力机制在不同模块之间建立联系,促进信息的交流和整合,从而提升了模型处理复杂任务的能力,展现出其在多模态学习和聚类分析等领域的强大优势。
本文盘点交叉注意力融合相关的13个技术成果,包含2024年最新的研究,这些模块的来源文章以及代码我都整理了,希望能给各位的论文添砖加瓦。
论文和模块代码需要的同学看文末
1.Rethinking Cross-Attention for Infrared and Visible Image Fusion
方法:本文提出了一种端到端的ATFuse网络,用于融合红外图像。通过在交叉注意机制的基础上引入差异信息注入模块(DIIM),可以分别探索源图像的独特特征。同时,作者还应用了交替公共信息注入模块(ACIIM),以充分保留最终结果中的公共信息。为了训练ATFuse,作者设计了一个由不同像素强度约束组成的分割像素损失函数,以在融合结果中达到纹理细节和亮度信息的良好平衡。
创新点:
-
提出了一种端到端的ATFuse网络,用于融合IV图像。在多个数据集上进行的大量实验表明,我们提出的ATFuse方法具有良好的效果和泛化能力。
-
基于交叉注意机制提出了一种差异信息注入模块(DIIM)。通过这个DIIM,可以分别探索源图像的独特特征。
-
将交替公共信息注入模块(ACIIM)应用于所提出的框架中,其中公共信息在最终结果中得到充分保留。
-
设计了由不同像素强度约束组成的分割像素损失函数,用于训练ATFuse,以便在融合结果中实现纹理细节和亮度信息的良好权衡。

2.ICAFusion: Iterative Cross-Attention Guided Feature Fusion for Multispectral Object Detection
方法: 作者提出了一种新颖的双交叉注意力特征融合方法,用于多光谱目标检测,同时聚合了RGB和热红外图像的互补信息。 该方法包括三个阶段:单模态特征提取、双模态特征融合和检测。在单模态特征提取阶段,分别对RGB和热红外图像进行特征提取。在双模态特征融合阶段,通过交叉注意力机制聚合来自不同分支的特征。最后,将融合后的特征输入到检测器进行多尺度特征融合,并进行分类和回归。
创新点:
-
提出了双交叉注意力变换器的特征融合框架,用于建模全局特征交互和同时捕捉多模态之间的互补信息。通过查询引导的交叉注意力机制增强了对象特征的可辨识性,从而提高了性能。
-
提出了迭代交互机制,通过在块状多模态变换器之间共享参数来减少模型复杂性和计算成本。这种迭代学习策略在不增加可学习参数的情况下,进一步改善了模型性能。

3.2D-3D Interlaced Transformer for Point Cloud Segmentation with Scene-Level Supervision
方法:本文提出了一种多模态交错注意力变换器(MIT),用于弱监督的点云分割。该方法包括两个编码器和一个解码器,分别用于提取3D点云和2D多视图图像的特征。解码器通过交叉注意力实现了2D和3D特征的隐式融合。作者交替切换查询和键值对的角色,使得2D和3D特征可以相互丰富。
创新点:
-
通过使用多视角信息而无需额外的注释工作,作者提出的MIT有效地融合了2D和3D特征,并显著改善了3D点云分割。
-
弱监督的点云分割。这个任务旨在使用弱标注数据(如稀疏标记点、包围盒级别标签、子云级别标签和场景级别标签)学习点云分割模型。在使用稀疏标记点的设置中取得了显著进展:最先进的方法与有监督的方法具有可比的性能。
-
2D和3D融合用于点云应用。现有方法依赖于相机姿态和/或深度图像来建立2D和3D域之间的对应关系。相比之下,本文方法通过交错的2D-3D注意力学习了一个变换器,实现了2D和3D特征的隐式融合,而无需相机姿态或深度图像。
-
查询和键值对交换。交叉注意力广泛应用于变换器解码器中,它捕捉查询和键值对之间的依赖关系。与他们的方法不同,本文方法将查询和键值对交换应用于跨域特征融合。

4.MMViT: Multiscale Multiview Vision Transformers
方法:本文介绍了一种新颖的多尺度多视图视觉Transformer(MMViT)模型,作为适用于多种模态的骨干模型。该模型将多尺度视觉Transformer(MViT)和多视图Transformer(MTV)的优势相结合,通过将多个视图输入到多尺度阶段层次模型中。在每个尺度阶段,使用交叉注意力层将不同分辨率的视图的信息进行融合,从而使网络能够捕捉复杂的高维特征。
创新点:
-
MMViT模型引入了交叉注意力层,使得模型能够在每个尺度阶段获取多视角的信息。通过并行处理不同分辨率的多个视角,MMViT模型能够在每个尺度阶段获取多分辨率的时间上下文。
-
MMViT模型使用了分层缩放系统,通过增加通道大小和降低空间分辨率,生成高维复杂特征。这种分层缩放系统使得网络能够在深度增加时获取更复杂的特征。
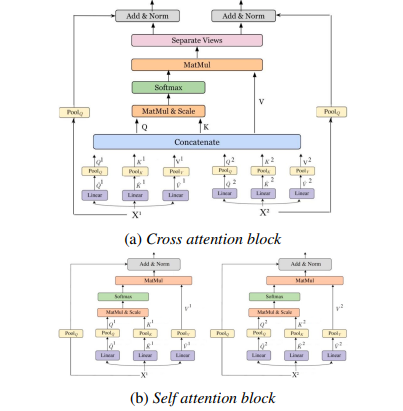
5.Multi-Modality Cross Attention Network for Image and Sentence Matching
方法:作者提出了一种新颖的图像和句子匹配方法,通过在统一的深度模型中联合建模跨模态和内部模态关系。作者首先提取显著的图像区域和句子标记。然后,应用所提出的自注意模块和交叉注意力模块来利用片段之间的复杂细粒度关系。最后,通过最小化基于困难负样本的三元组损失,将视觉和文本特征更新到一个公共嵌入空间中。
创新点:
-
提出了一种新颖的图像和句子匹配方法,通过在统一的深度模型中联合建模跨模态和内模态关系。首先提取显著的图像区域和句子标记。然后,应用所提出的自注意模块和交叉注意模块来利用片段之间的复杂细粒度关系。最后,通过最小化基于困难负样本的三元组损失将视觉和文本特征更新到一个共同的嵌入空间中。
-
提出了一种新颖的多模态交叉注意网络,通过在统一的深度模型中联合建模图像区域和句子单词的内模态关系和跨模态关系,用于图像和句子匹配。为了实现稳健的跨模态匹配,作者提出了一种新颖的交叉注意模块,能够利用每个模态内的内模态关系以及图像区域和句子单词之间的跨模态关系,相互补充和增强图像和句子匹配。
6.CCNet: Criss-Cross Attention for Semantic Segmentation
方法:本文提出了一种Criss-Cross网络(CCNet),用于以一种非常有效和高效的方式获取全图像的上下文信息。具体而言,对于每个像素,一种新颖的交叉关注模块收集其交叉路径上所有像素的上下文信息。通过进一步的循环操作,每个像素最终可以捕捉到全图像的依赖关系。此外,还提出了一种类别一致性损失,以强制交叉关注模块产生更具区分性的特征。
创新点:
-
创新的Criss-Cross Attention模块:通过在每个像素上采用新颖的Criss-Cross Attention模块,可以收集其所在的十字路径上所有像素的上下文信息。通过进一步的循环操作,每个像素最终可以捕捉到全图像的依赖关系。
-
引入的类别一致性损失:为了使Criss-Cross Attention模块产生更具辨别性的特征,作者提出了类别一致性损失。该损失函数使网络将图像中的每个像素映射到特征空间中的一个n维向量,使属于同一类别的像素的特征向量彼此靠近,而属于不同类别的像素的特征向量相距较远。

关注下方《学姐带你玩AI》🚀🚀🚀
回复“交叉注意力”获取论文+模块代码
码字不易,欢迎大家点赞评论收藏



)








-Modbus协议集成和测试)

)




