背景
项目上是用 ES 做数据库,存储的告警数据,量级在千万级别左右。测试在压测之后,系统频繁出现告警记录查询报错,系统不可用。基于此排查分析项目上 Elasticsearch 的使用是否合理。
版本及硬件
- 环境:10.xx.xxx.xx
- jdk:1.8.0
- elasticsearch:6.5.4
- es集群:1个client(预处理节点),1个data(即做主节点,又做数据节点)
- os:centos7 64核 128G
- 垃圾回收器:-XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+AlwaysPreTouch
ES JVM 分析
要针对 jvm 调优,必不可少的是先查看堆内存状况,使用如下命令查看
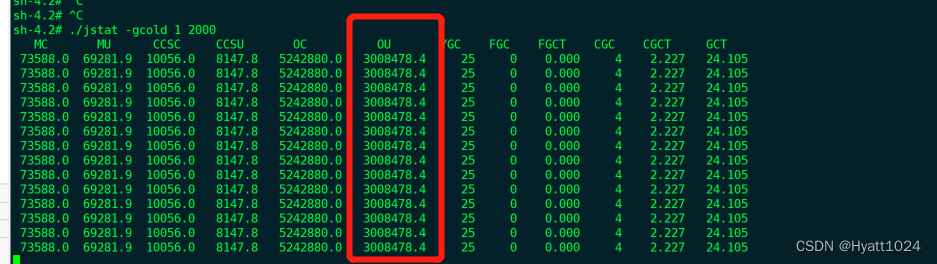
jstat -gc
jstat -gc命令查看堆分配情况
- 进入elasticsearch容器内部:kubectl exec -it -n logging elasticsearch-data-0 /bin/sh
- 查看堆内存使用情况:/opt/jdk-xx/bin/jstat -gc 1 1000
- 各参数详解参考:https://www.dcr-stephen.cn/post/5

ES各节点分配信息
| 节点 | 堆总大小 | 新生代 | survivor | eden | 老年代 | 元数据区 |
| data | 15G | 0.243G | 0.024G | 0.195G | 14.756G | 77M |
观察到的现象
- 新生代和老年代分配比不合理,新生代太小,老年代太大
- 新生代垃圾回收频繁
网上很多文章指出新生代和老年代的默认比例为1:2,但是通过观察发现并不是这样(我们的机器上大约是1:60)。
这篇文章解释了原因:https://bugs.openjdk.java.net/browse/JDK-8153578
查看k8s日志发现elasticsearch频繁发生minior GC,而且每次GC需要花费200-500ms,截图如下:kubectl logs -f -n logging elasticsearch-data-0 --tail=100

初步分析和解决
- 新生代太小:导致minior gc回收频繁,可适当加大新生代大小
- 老年代太大:导致major gc或full gc回收时间过长,可适当减少老年代大小
- 如何确定新生代老年代大小:根据 美团gc优化实战 文章所述:
- 总大小:3-4倍活跃数据大小
- 新生代:1-1.5倍活跃数据大小
- 老年代:总大小-新生代
调优实战
需总共给 Elasticsearch 分配 22 GB内存。原因如下:
elasticsearch-data
- 根据 gc 日志可算出活跃数据大小约为 3g,那么各分区大小可设为:
- 总堆:12g=3g*4,新生代:4.5g=3g*1.5,老年代:7.5g=12g-4.5g
- 因推送并发高时需要频繁的写入 es,会产生大量的短期对象,这种场景应该加大新生代来降低频繁的 minor GC,从而提高并发性
-
综上:elasticsearch-data 的调优参数为:-Xms15g -Xmx15g -Xmn10g
elasticsearch-client
- 根据 gc 日志可算出活跃数据大小约为 450M,那么各分区大小可设为:
- 总堆:8g=2g*4,新生代:3g=2g*1.5,老年代:5g=8g-3g
- 因 elasticsearch-client 只作为 ingest 节点,主要是对数据进行前置处理、过滤、转换等,内存可以相对调小一些
-
综上:elasticsearch-client 的调优参数为:-Xms4g -Xmx4g -Xmn2g
参考
- 《深入理解java虚拟机》
- https://tech.meituan.com/2017/12/29/jvm-optimize.html
- https://tech.meituan.com/2017/12/29/jvm-optimize.html






使用SOME/IP-SD宣布非SOME/IP协议的协议。)






函数)
 字节推出了国内版的 Coze 扣子;ChatGemini-使用 Google 的生成式 AI 来生成对您的消息的响应)

)
:Practical Deep Raw Image Denoising on Mobile Devices)

