目录
1.算法核心思想:
2.算法核心代码:
3.算法分类效果:
1.算法核心思想:
1.设置降维后主成分的数目为2
2.进行数据降维
3.设置main_factors+1个划分类型
4.根据组分中的值进行分类
5.绘制出对应的图像2.算法核心代码:
#导入matplotlib库和sklearn的一些函数
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris#导入莺尾花数据集作为数据来源
test_data=load_iris()
x=test_data.data
y=test_data.target
#进行PCA算法的优化
#1.设置降维后主成分的数目为2
main_factors=2
data_pca=PCA(main_factors)
#2.进行数据降维
data_reduce=data_pca.fit_transform(x)
#2.设置main_factors+1个划分类型
x_red=[]
y_red=[]
x_blue=[]
y_blue=[]
x_yellow=[]
y_yellow=[]
#3.根据组分中的值进行分类
#计算多少次分类并执行
number=len(data_reduce)
for i in range(number):if y[i]==1:x_red.append(data_reduce[i][0])y_red.append(data_reduce[i][1])elif y[i]==0:x_blue.append(data_reduce[i][0])y_blue.append(data_reduce[i][1])else:x_yellow.append(data_reduce[i][0])y_yellow.append(data_reduce[i][1])
#4.绘制出对应的图像
plt.scatter(x_red,y_red,color='r',marker='x')
plt.scatter(x_blue,y_blue,color='b',marker='o')
plt.scatter(x_yellow,y_yellow,color='y',marker='*')
plt.title('PCA Classified Image')
plt.xlabel('X distribution of data')
plt.ylabel('Y distribution of data')
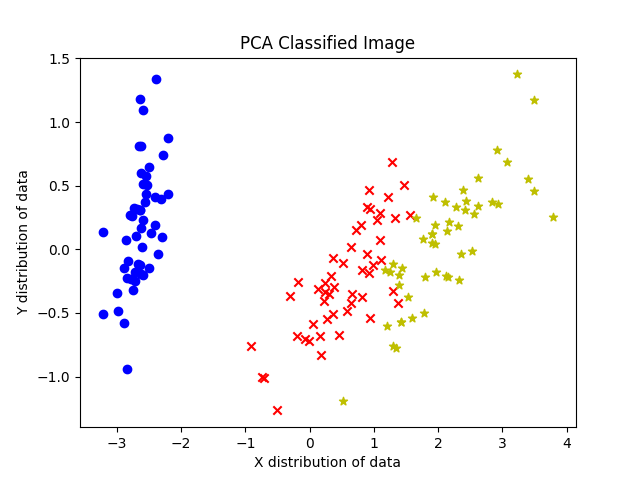
plt.show()3.算法分类效果:




:webpack + three.js + ts)
)





![一、了解[mysql]索引底层结构和算法](http://pic.xiahunao.cn/一、了解[mysql]索引底层结构和算法)



)

:源码篇 Ⅰ)

