基于光谱的影像的分类可分为监督与非监督分类,这类分类方法适合于中低分辨率的数据,根据其原理有基于传统统计分析的、基于神经网络的、基于模式识别的等。
本专题以ENVI5.3及以上版本的监督与非监督分类的实际操作为例,介绍这两种分类方法的流程和相关知识。有以下内容组成:
- 监督分类
- 非监督分类
- 分类后处理
监督分类

图1监督分类步骤
1、类别定义/特征判别
根据分类目的、影像数据自身的特征和分类区收集的信息确定分类系统;对影像进行特征判断,评价图像质量,决定是否需要进行影像增强等预处理。这个过程主要是一个目视查看的过程,为后面样本的选择打下基础。
本例是以ENVI自带Landsat tm5数据Can_tmr.img为数据源,类别分为:林地、草地/灌木、耕地、裸地、沙地、其他六类。
2、样本选择
为了建立分类函数,需要对每一类别选取一定数目的样本,在ENVI中是通过感兴趣区(ROIs)来确定,也可以将矢量文件转化为ROIs文件来获得,或者利用终端像元收集器(Endmember Collection)获得。
本例中使用ROIs方法,打开待分类图像,在主界面中的图层管理器(Layer Manager),“can_tmr.img”右键选择New Region of Interest菜单,打开ROI Tool对话框,默认ROIs为多边形,按照默认设置在影像上定义训练样本。如图2所示,设置好颜色和类别名称(支持中文名称)。
在ROIs面板中,选择Option->Compute ROI Separability,计算样本的可分离性。如图3所示,表示各个样本类型之间的可分离性,用Jeffries-Matusita, Transformed Divergence参数表示,这两个参数的值在0~2.0之间,大于1.9说明样本之间可分离性好,属于合格样本;小于1.8,需要重新选择样本;小于1,考虑将两类样本合成一类样本。

图2训练样本的选择
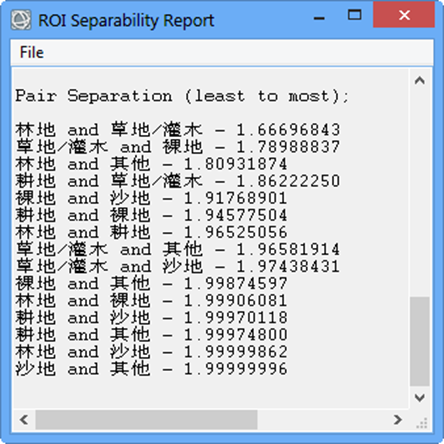
图3样本可分离性计算报表
- 在计算样本可分离性时候,可能会出现以下错误信息(Singular Value encountered…),经常出现在影像波段非常多的情况。出现这个情况主要是这一类样本的样本点数量太少,解决方法是多选择样本点。
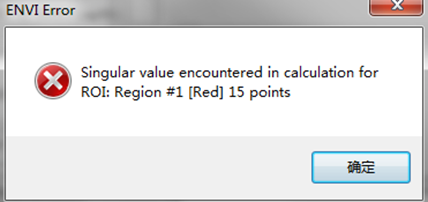
图4 样本可分离性计算报错
- 在选择样本的时候,可以使用一些增强的手段辅助样本的选择,如主成分分析、波段合成等。
3、分类器选择
根据分类的复杂度、精度需求等确定哪一种分类器。目前监督分类可分为基于传统统计分析学的,包括平行六面体、最小距离、马氏距离、最大似然,基于神经网络的,基于模式识别,包括支持向量机、模糊分类等,针对高光谱有波谱角(SAM),光谱信息散度,二进制编码。下面是几种分类器的简单描述。
表 几种监督分类器说明
| 分类器 | 说明 |
| 平行六面体(Parallelpiped) | 根据训练样本的亮度值形成一个n维的平行六面体数据空间,其他像元的光谱值如果落在平行六面体任何一个训练样本所对应的区域,就被划分其对应的类别中。平行六面体的尺度是由标准差阈值所确定的,而该标准差阈值则是根据所选类的均值求出。 |
| 最小距离(Minimum Distance) | 利用训练样本数据计算出每一类的均值向量和标准差向量,然后以均值向量作为该类在特征空间中的中心位置,计算输入图像中每个像元到各类中心的距离,到哪一类中心的距离最小,该像元就归入到哪一类。 |
| 马氏距离(Mahalanobis Distance) | 计算输入图像到各训练样本的马氏距离(一种有效的计算两个未知样本集的相似度的方法),最终统计马氏距离最小的,即为此类别。 |
| 最大似然 (Likelihood Classification) | 假设每一个波段的每一类统计都呈正态分布,计算给定像元属于某一训练样本的似然度,像元最终被归并到似然度最大的一类当中。 |
| 神经网络 (Neural Net Classification) | 指用计算机模拟人脑的结构,用许多小的处理单元模拟生物的神经元,用算法实现人脑的识别、记忆、思考过程应用于图像分类。 |
| 支持向量机 (Support Vector Machine Classification) | 支持向量机分类(SVM)是一种建立在统计学习理论(Statistical Learning Theory或SLT)基础上的机器学习方法。SVM可以自动寻找那些对分类有较大区分能力的支持向量,由此构造出分类器,可以将类与类之间的间隔最大化,因而有较好的推广性和较高的分类准确率。 |
| 波谱角(Spectral Angle Mapper) | 它是在N维空间将像元与参照波谱进行匹配,通过计算波谱间的相似度,之后对波谱之间相似度进行角度的对比,较小的角度表示更大的相似度。 |
4、影像分类
基于传统统计分析的分类方法参数设置比较简单,这里选择支持向量机分类方法。在Toolbox工具箱中,双击Classification/Supervised Classification/Support Vector Machine Classification工具。按照默认设置参数输出分类结果,如图5所示。
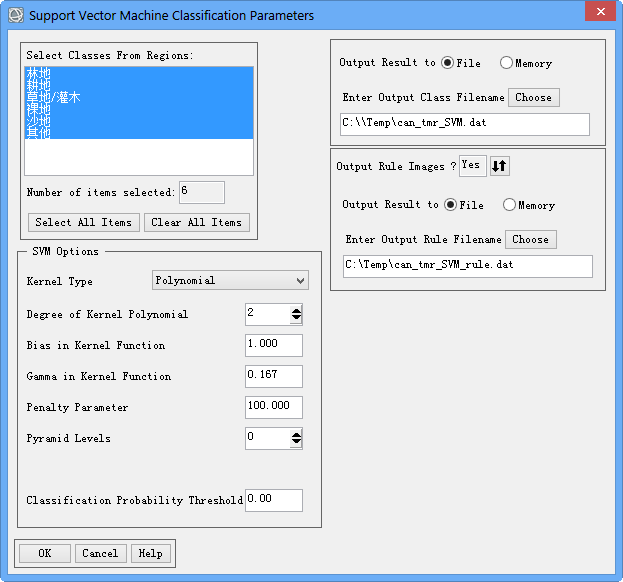
图5支持向量机分类器参数设置
5、分类后处理
分类后处理包括的很多的过程,都是些可选项,包括更改类别颜色、分类统计分析、小斑点处理(类后处理)、栅矢转换等操作。
- 更改类别颜色
可以在显示分类结果的图层管理上右键选择Edit Class Names and Corlors,如下图6所示,直接可以在对应的类别中修改颜色。
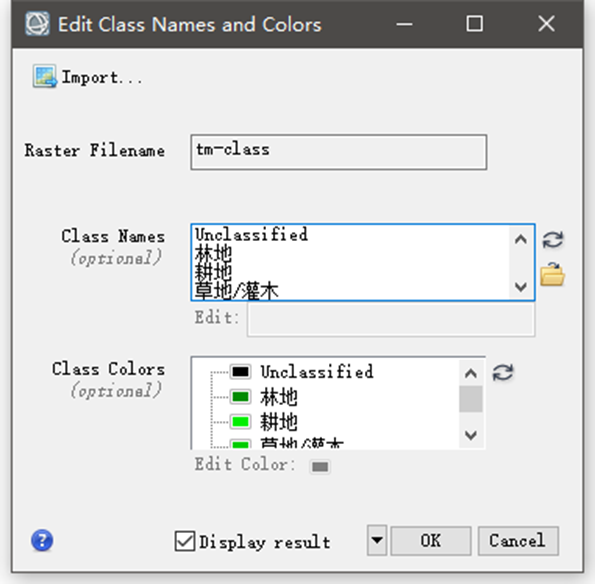
图6 类别颜色的更改
- 分类统计分析
/Classification/Post Classification/Class Statistics。如图7所示,包括基本统计:类别的像元数、最大最小值、平均值等,直方图,协方差等信息。
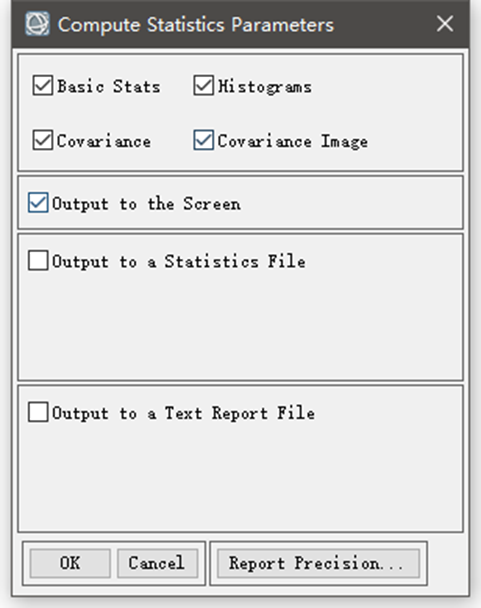
图7 分类结果统计
- 小斑点处理(类后处理)
运用遥感影像分类结果中,不可避免地会产生一些面积很小的图斑。无论从专题制图的角度,还是从实际应用的角度,都有必要对这些小图斑进行剔除和重新分类,目前常用的方法有Majority/Minority分析、聚类(clump)和过滤(Sieve)和。这些工具都可以在Toolbox/Classification/Post Classification中找到。Majority/Minority分析和聚类(clump)是将周围的“小斑点”合并到大类当中,过滤(Sieve)是将不符合的“小斑点”直接剔除。
- 栅矢转换
打开/Classification/Post Classification/Classification to Vector,可以将分类后得到的结果转化为矢量格式,在选择输出参数时候,可以选择特定的类别,也可以把类别单独输出为矢量文件或者一个矢量文件。
6、结果验证
对分类结果进行评价,确定分类的精度和可靠性。有两种方式用于精度验证:一是混淆矩阵,二是ROC曲线,比较常用的为混淆矩阵,ROC曲线可以用图形的方式表达分类精度,比较形象。
真实参考源可以使用两种方式:一是标准的分类图,二是选择的感兴趣区(验证样本区)。两种方式的选择都可以通过/Classification/Post Classification/Confusion Matrix Using…或者ROC Curves来选择。
真实的感兴趣区参考源的选择可以是在高分辨率影像上选择,也可以是野外实地调查获取,原则是获取的类别参考源的真实性。由于没有更高分辨率的数据源,本例中就把原分类的TM影像当作是高分辨率影像,在上面进行目视解译得到真实参考源。直接利用ROI工具,在TM图上均匀的选择6类真实参考源。
选择/Classification/Post Classification/Confusion Matrix Using Ground Truth ROIs。将分类结果和ROI输入,软件会根据区域自动匹配,如不正确可以手动更改。点击ok后选择报表的表示方法(像素和百分比),就可以得到精度报表。
图8 真实感兴趣区参考源选取
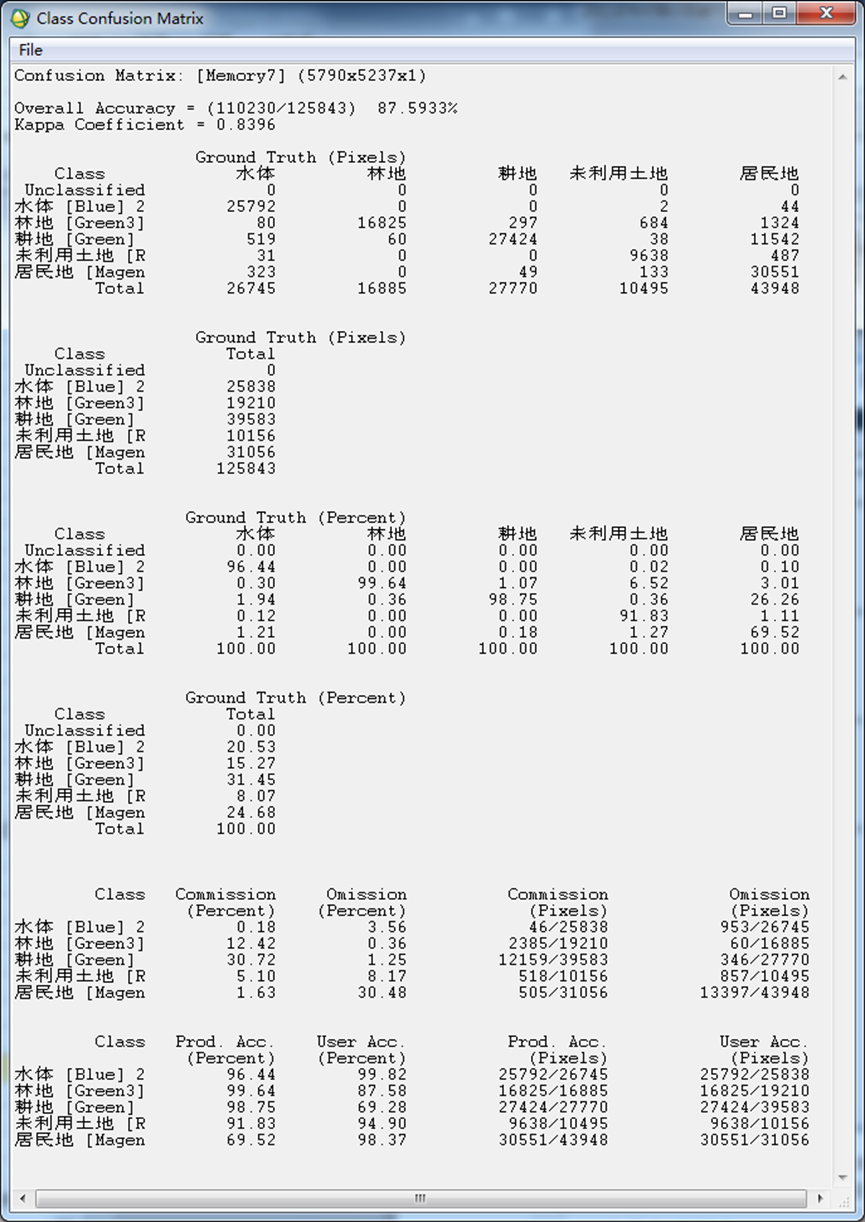
图9 分类精度评价混淆矩阵
这里说明一下混淆矩阵中的几项评价指标,如下:
- 总体分类精度
等于被正确分类的像元总和除以总像元数。被正确分类的像元数目沿着混淆矩阵的对角线分布,总像元数等于所有真实参考源的像元总数,如本次精度分类精度表中的Overall Accuracy = (1849/2346) 78.8150%。
- Kappa系数
它是通过把所有真实参考的像元总数(N)乘以混淆矩阵对角线(XKK)的和,再减去某一类中真实参考像元数与该类中被分类像元总数之积之后,再除以像元总数的平方减去某一类中真实参考像元总数与该类中被分类像元总数之积对所有类别求和的结果。
Kappa计算公式
- 错分误差
指被分为用户感兴趣的类,而实际属于另一类的像元,它显示在混淆矩阵里面。本例中,林地有419个真实参考像元,其中正确分类265,12个是其他类别错分为林地(混淆矩阵中林地一行其他类的总和),那么其错分误差为12/419=2.9%。
- 漏分误差
指本身属于地表真实分类,当没有被分类器分到相应类别中的像元数。如在本例中的耕地类,有真实参考像元465个,其中462个正确分类,其余3个被错分为其余类(混淆矩阵中耕地类中一列里其他类的总和),漏分误差为3/465=0.6%
- 制图精度
是指分类器将整个影像的像元正确分为A类的像元数(对角线值)与A类真实参考总数(混淆矩阵中A类列的总和)的比率。如本例中林地有419个真实参考像元,其中265个正确分类,因此林地的制图精度是265/419=63.25%。
- 用户精度
是指正确分到A类的像元总数(对角线值)与分类器将整个影像的像元分为A类的像元总数(混淆矩阵中A类行的总和)比率。如本例中林地有265个正确分类,总共划分为林地的有277,所以林地的用户精度是265/277=95.67%。
非监督分类
非监督分类:也称为聚类分析或点群分类。在多光谱图像中搜寻、定义其自然相似光谱集群的过程。它不必对影像地物获取先验知识,仅依靠影像上不同类地物光谱(或纹理) 信息进行特征提取,再统计特征的差别来达到分类的目的,最后对已分出的各个类别的实际属性进行确认。
目前比较常见也较为成熟的是ISODATA、K-Mean和链状方法等。遥感影像的非监督分类一般包括以下6个步骤:
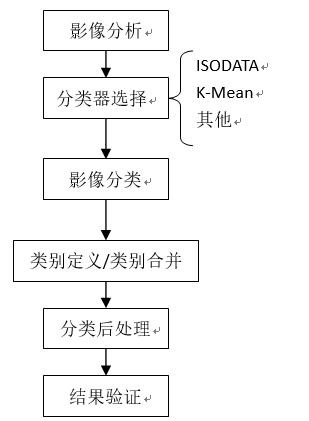
图10 非监督分类操作流程
1、影像分析
大体上判断主要地物的类别数量。一般监督分类设置分类数目比最终分类数量要多2-3倍为宜,这样有助于提高分类精度。
本案例的数据源为ENVI自带的Landsat tm5数据Can_tmr.img,类别分为:林地、草地/灌木、耕地、裸地、沙地、其他六类。确定在非监督分类中的类别数为15。
2、分类器选择
目前非监督分类器比较常用的是ISODATA、K-Mean和链状方法。ENVI包括了ISODATA和K-Mean方法。
ISODATA(Iterative Self-Orgnizing Data Analysize Technique)重复自组织数据分析技术,计算数据空间中均匀分布的类均值,然后用最小距离技术将剩余像元进行迭代聚合,每次迭代都重新计算均值,且根据所得的新均值,对像元进行再分类。
K-Means使用了聚类分析方法,随机地查找聚类簇的聚类相似度相近,即中心位置,是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的,然后迭代地重新配置他们,完成分类过程。
3、影像分类
打开ENVI,在Toolbox工具箱中,双击Classification/Unsupervised Classification/IsoData Classification工具或者K-Means。这里选择IsoData,在选择文件时候,可以设置空间或者光谱裁剪区。这里选择软件自带的Can_tmr.img,按默认设置,之后跳出参数设置。
这里主要设置类别数目(Number of Classes)为5-15、迭代次数(Maximum Iteration)为10。其他选项按照默认设置,输出文件。

图11 ISODATA非监督分类参数设置
4、类别定义/类别合并
- 类别定义
显示非监督分类结果,分别在view上显示不同的类别。
图层管理器上右键选择Edit Class Names and Corlors。通过目视或者其他方式识别分类结果,填写相应的类型名称和颜色。
- 类别合并
(1) 在Toolbox工具箱中,双击Classification/Post Classification/Combine Classes工具。把同一类的类别合并成一类
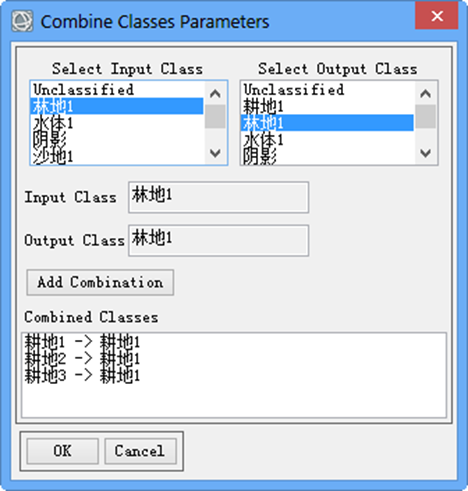
图12类别的合并
5、分类后处理
参照监督分类。
6、结果验证
参照监督分类。
ENVI 5下流程化分类工具
在ENVI5.x下,提供了一个流程的图像分类工具,Toolbox/Classification/Classification Workflow工具,下面对10米的ALI数据进行火烧迹地信息提取为例子,简单看看具体操作步骤如下:
第一步,打开数据“BurnALI_subset.dat”,用964波段合成显示;
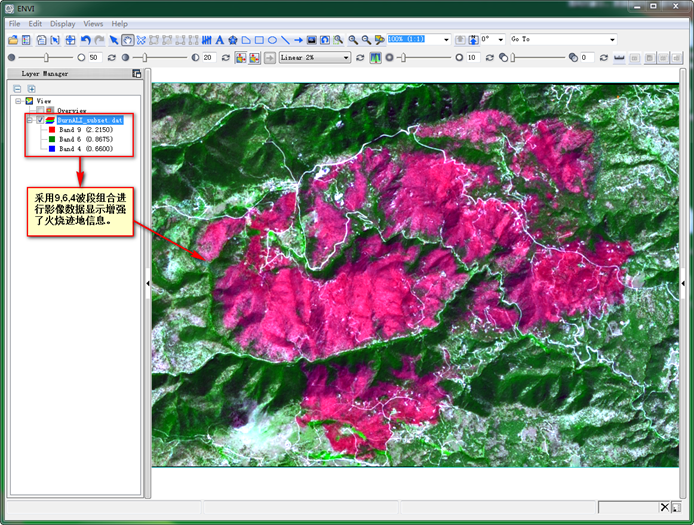
图13 band 9,6,4组合增强火烧迹地信息
第二步:打开监督分类的流程化工具,Toolbox/Classification/Classification Workflow,在Input Raster中输入待分类的数据,点击Next,选择Use Training Data(监督分类),点击Next,

图14 导入打开的影像数据
第三步:修改类别的名称和颜色非火烧迹地,在图像中选择样本,点击 新建一类,为非火灾区域,选择样本。选择Preview可以预览分类结果,点击Next;

图15 添加提取样本以及样本参数设置
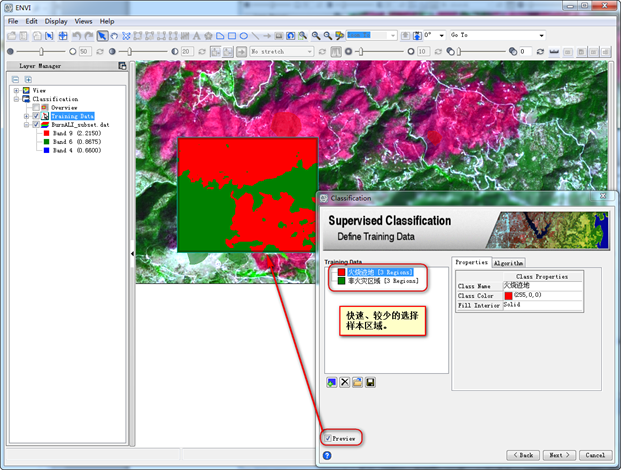
图16 选择样本区域
第四步,分类斑块后处理,设置平滑核和聚合算子,点击Next;
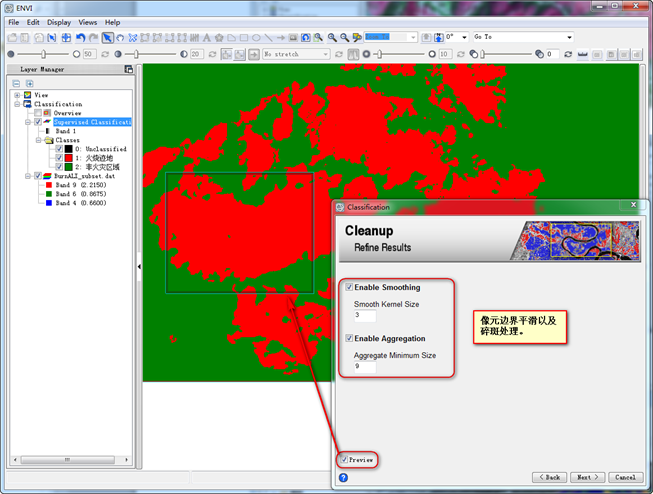
图 17 像元边界平滑以及碎斑处理分析
第五步,结果输出,可输出分类结果、矢量数据及统计结果文件。
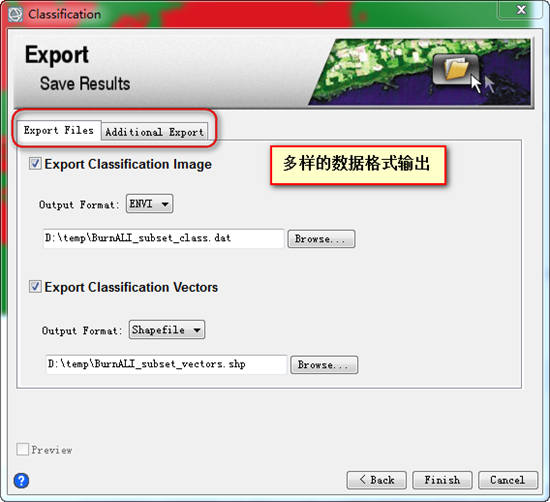
图18 结果输出
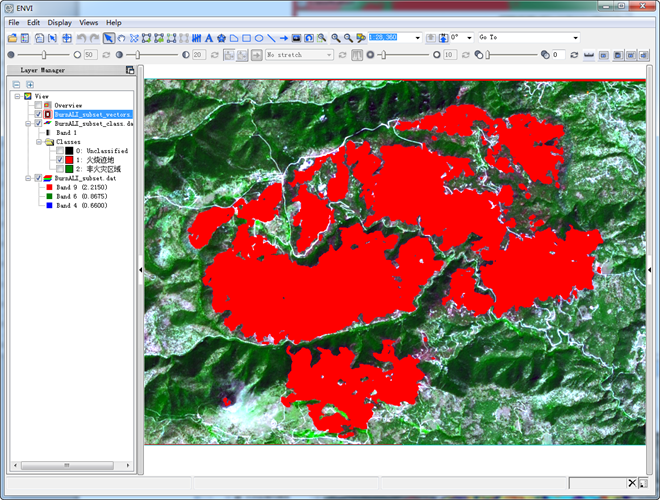
图19 提取结果展示
上可以看到,这个工具就是把监督分类的所有流程集成在一个界面下完成,而且还可以随时浏览
总结
1、监督分类中的样本选择和分类器的选择比较关键。在样本选择时,为了更加清楚的查看地物类型,可以适当的对图像做一些增强处理,如主成分分析、最小噪声变换、波段组合等操作,便于样本的选择;分类器的选择需要根据数据源和影像的质量来选择,比如支持向量机对高分辨率、四个波段的影像效果比较好。
2、非监督分类的关键部分是类别定义。这个过程需要数据的支持,甚至需要组织野外实地调查。


——力扣哈希)
)



)




、精度比较)


)
)
)

