数据库简介
数据库:英文为 DataBase,简称DB,它是存储和管理数据的仓库。
接下来,我们来学习Mysql的数据模型,数据库是如何来存储和管理数据的。在介绍 Mysql的数据模型之前,需要先了解一个概念:关系型数据库。
关系型数据库(RDBMS)是指建立在关系模型基础上,由多张相互连接的二维表组成的数据库。二维表,指的是由行和列组成的表。
二维表的优点:使用表存储数据,格式统一,便于维护使用SQL语言操作,标准统一,使用方便,可用于复杂查询
MySQL是关系型数据库,是基于二维表进行数据存储的,具体的结构图下:

通过MySQL客户端连接数据库管理系统DBMS,然后通过DBMS操作数据库使用MySQL客户端,向数据库管理系统发送一条SQL语句,由数据库管理系统根据SQL语句指令去操作数据库中的表结构及数据。一个数据库服务器中可以创建多个数据库,一个数据库中也可以包含多张表,而一张表中又可以包含多行记录。
在Mysql数据库服务器当中存储数据,你需要:1. 先去创建数据库(可以创建多个数据库,之间是相互独立的)2. 在数据库下再去创建数据表(一个数据库下可以创建多张表)3. 再将数据存放在数据表中(一张表可以存储多行数据)
SQL通用语法
SQL:一门操作关系型数据库的编程语言,定义操作所有关系型数据库的统一标准。
SQL语句可以单行或多行书写,以分号结尾。

SQL语句可以使用空格/缩进来增强语句的可读性。

MySQL数据库的SQL语句不区分大小写。

注释:
1.单行注释:-注释内容或#注释内容(MySQL特有)
2.多行注释:/* 注释内容 */
SQL数据类型
MySQL中的数据类型有很多,主要分为三类:数值类型、字符串类型、日期时间类型。
数值类型
| 类型 | 大小 | 有符号(SIGNED)范围(默认) | 无符号(UNSIGNED)范围 | 描述 |
|---|---|---|---|---|
| TINYINT | 1byte | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2bytes | (-32768,32767) | (0,65535) | 大整数值 |
| MEDIUMINT | 3bytes | (-8388608,8388607) | (0,16777215) | 大整数值 |
| INT/INTEGER | 4bytes | (-2147483648,2147483647) | (0,4294967295) | 大整数值 |
| BIGINT | 8bytes | (-263, 263-1) | (0,264-1) | 极大整数值 |
| FLOAT | 4bytes | (-3.402823466 E+38,3.402823466351 E+38) | 0 和 (1.175494351 E-38,3.402823466 E+38) | 单精度浮点数值 |
| DOUBLE | 8bytes | (-1.7976931348623157E+308,1.7976931348623157E+308) | 0 和(2.2250738585072014 E-308,1.7976931348623157E+308) | 双精度浮点数值 |
| DECIMAL | 依赖于M(精度)和D(标度)的值 | 依赖于M(精度)和D(标度)的值 | 小数值(精确定点数) |
字符串类型
| 类型 | 大小 | 描述 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串(需要指定长度) |
| VARCHAR | 0-65535 bytes | 变长字符串(需要指定长度) |
| TINYBLOB | 0-255 bytes | 不超过255个字符的二进制数据 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
char 与 varchar 都可以描述字符串,char是定长字符串,指定长度多长,就占用多少个字符,和字段值的长度无关 。而varchar是变长字符串,指定的长度为最大占用长度 。相对来说,char的性能会更高些。
日期时间类型
| 类型 | 大小 | 范围 | 格式 | 描述 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01 至 9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | -838:59:59 至 838:59:59 | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901 至 2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00 至9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:01 至2038-01-19 03:14:07 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值,时间戳 |
SQL语句分类
SQL语句根据其功能被分为四大类:DDL、DML、DQL、DCL

| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DOL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 |
项目开发流程如下:

在上述的流程当中,针对于数据库来说,主要包括三个阶段:1. 数据库设计阶段:参照页面原型以及需求文档设计数据库表结构2. 数据库操作阶段:根据业务功能的实现,编写SQL语句对数据表中的数据进行增删改查操作3. 数据库优化阶段:通过数据库的优化来提高数据库的访问性能。优化手段:索引、SQL优化、分库分表等
数据库设计-DDL-数据库操作
DDL英文全称是Data Definition Language(数据定义语言),用来定义数据库对象(数据库、表)。DDL中数据库的常见操作:查询、创建、使用、删除。
查询数据库
查询所有数据库:show databases;

查询当前数据库:select database();
要操作某一个数据库,必须要切换到对应的数据库中。通过指令:select database() ,就可以查询到当前所处的数据库。

创建数据库
创建数据库语法:create database if not exists 数据库名;
数据库不存在,则创建该数据库;如果存在则不创建。
使用数据库
要操作某一个数据库下的表时,就需要通过指令,切换到对应的数据库下,否则不能操作。
使用数据库语法:use 数据库名 ;
删除数据库
删除数据库语法:drop database if exists 数据库名;
数据库存在时删除
数据库设计-DDL-表操作
约束:是指作用在表中字段上的规则,用于限制存储在表中的数据。来保证数据库当中数据的正确性、有效性和完整性。
在MySQL数据库当中,提供了以下5种约束:
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段值不能为null | not null |
| 唯一约束 | 保证字段的所有数据都是唯一、不重复的 | unique |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯 | primary key |
| 默认约束 | 保存数据时,如果未指定该字段值,则采用默认值 | default |
| 外键约束 | 让两张表的数据建立连接,保证数据的一致性和完整性 | foreign key |
主键自增:auto_increment,每次插入新的行记录时,数据库自动生成id字段(主键)下的值具有auto_increment的数据列是一个正数序列开始增长(从1开始自增)。
创建表

注意: [ ] 中的内容为可选参数; 最后一个字段后面没有逗号
案例:创建tb_user表

建表语句:
create table tb_user (id int primary key comment 'ID,唯一标识',username varchar(20) not null unique comment '用户名',name varchar(10) not null comment '姓名',age int comment '年龄',gender char(1) default '男' comment '性别'
) comment '用户表';
查询表
查询当前数据库所有表:show tables;
查询表结构:desc 表名;
查询建表语句:show create table表名;
图形化界面:

修改表
添加字段:alter table 表名 add 字段名 类型(长度) [comment注释] [约束];
修改字段类型:alter table 表名 modify 字段名 新数据类型(长度);
修改字段名和字段类型:alter table 表名 change l旧字段名 新字段名 类型(长度) [comment注释] [约束];
删除字段:alter table 表名 drop column 字段名;
修改表名:rename table 表名 to 新表名;
图形化界面:添加字段

图形化界面:修改数据类型和字段名

图形化界面:删除字段
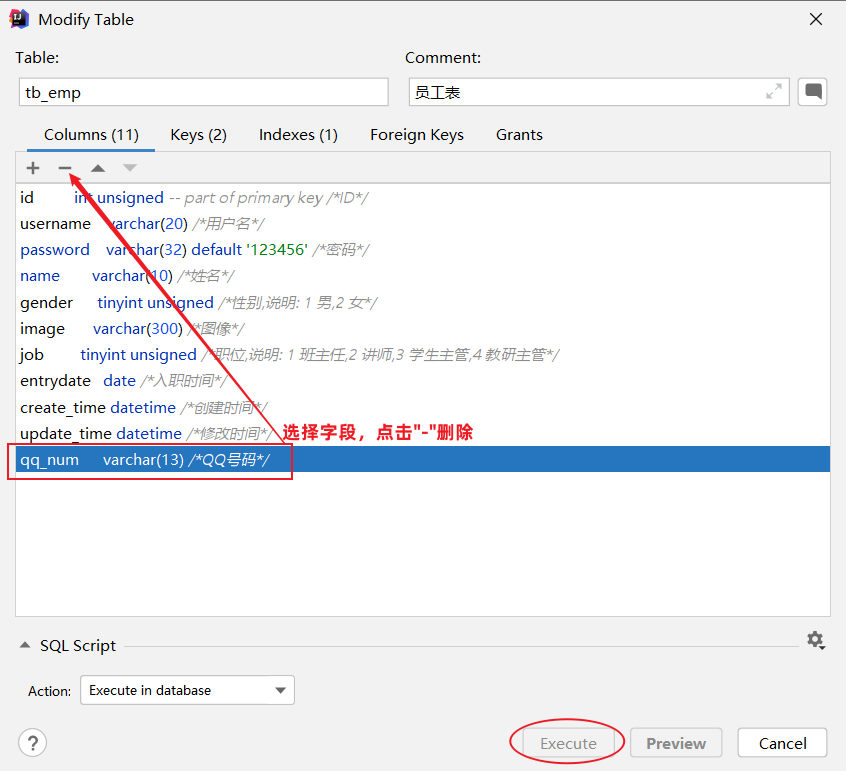
图形化界面:修改表名

删除表
删除表语法:drop table [ if exists ] 表名;
图形化操作:删除表

数据库操作-DML
DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。
添加数据(INSERT)
向指定字段添加数据:insert into 表名 (字段名1, 字段名2) values (值1, 值2);
全部字段添加数据:insert into 表名 values (值1, 值2, ...);
批量添加数据(指定字段):insert into 表名 (字段名1, 字段名2) values (值1, 值2), (值1, 值2);
批量添加数据(全部字段):insert into 表名 values (值1, 值2, ...), (值1, 值2, ...);
案例1:向tb_emp表的username、name、gender字段插入数据
-- 因为设计表时create_time, update_time两个字段不能为NULL,所以也做为要插入的字段
insert into tb_emp(username, name, gender, create_time, update_time) values ('wuji', '张无忌', 1, now(), now());
案例2:向tb_emp表的所有字段插入数据
insert into tb_emp values (null, 'zhirou', '123', '周芷若', 2, '1.jpg', 1, '2010-01-01',now(), now());
案例3:批量向tb_emp表的username、name、gender字段插入数据
insert into tb_emp(username, name, gender, create_time, update_time)
values ('weifuwang', '韦一笑', 1, now(), now()),('fengzi', '张三疯', 1, now(), now());
图形化操作:双击tb_emp表查看数据

Insert操作的注意事项: 1. 插入数据时,指定的字段顺序需要与值的顺序是一一对应的。2. 字符串和日期型数据应该包含在引号中。3. 插入的数据大小,应该在字段的规定范围内。
修改数据(UPDATE)
update语法:update 表名 set 字段名1 = 值1 , 字段名2 = 值2 , .... [where 条件] ;案例1:将tb_emp表中id为1的员工,姓名name字段更新为'张三'
update tb_emp set name='张三',update_time=now() where id=1;注意事项:1. 修改语句的条件可以有,也可以没有,如果没有条件,则会修改整张表的所有数据。2. 在修改数据时,一般需要同时修改公共字段update_time,将其修改为当前操作时间。
删除数据(DELETE)
delete语法:delete from 表名 [where 条件] ;案例1:删除tb_emp表中id为1的员工
delete from tb_emp where id = 1;注意事项:• DELETE 语句的条件可以有,也可以没有,如果没有条件,则会删除整张表的所有数据。• DELETE 语句不能删除某一个字段的值(可以使用UPDATE,将该字段值置为NULL即可)。• 当进行删除全部数据操作时,会提示询问是否确认删除所有数据,直接点击Execute即可。
数据库查询操作-DQL
DQL英文全称是Data Query Language(数据查询语言),用来查询数据库表中的记录。
查询关键字:SELECT
查询操作是所有SQL语句当中最为常见,也是最为重要的操作。在一个正常的业务系统中,查询操作的使用频次是要远高于增删改操作的。当打开某个网站或APP所看到的展示信息,都是通过从数据库中查询得到的,而在这个查询过程中,还会涉及到条件、排序、分页等操作。
DQL查询语句,语法结构如下:

DQL语句-单表操作
基本查询
查询多个字段:select 字段1,字段2,字段3 from 表名;
查询所有字段(通配符):select*from表名;
设置别名:select字段1[as别名1],字段2[as别名2]from表名;
去除重复记录:select distinct字段列表from表名;注:* 号代表查询所有字段,在实际开发中尽量少用(不直观、影响效率)
# 案例1:查询指定字段 name,entrydate并返回
select name,entrydate from tb_emp;# 案例2:查询返回所有字段
select * from tb_emp;# 案例3:查询所有员工的 name,entrydate,并起别名(姓名、入职日期)
select name as "姓名" , entrydate as "入职日期" from tb_emp;# 案例4:查询已有的员工关联了哪几种职位(不要重复)
select distinct job from tb_emp;
条件查询(where)
语法:select 字段列表 from 表名 where 条件列表 ;
条件列表:意味着可以有多个条件
学习条件查询就是学习条件的构建方式,而在SQL语句当中构造条件的运算符分为两类:比较运算符、逻辑运算符
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| between … and … | 在某个范围之内(含最小、最大值) |
| in(…) | 在in之后的列表中的值,多选一 |
| like 占位符 | 模糊匹配(_匹配单个字符, %匹配任意个字符) |
| is null | 是null |
| 逻辑运算符 | 功能 |
|---|---|
| and 或 && | 并且 (多个条件同时成立) |
| or 或 1 | 或者 (多个条件任意一个成立) |
| not 或 ! | 非 , 不是 |
# 案例1:查询 姓名 为 杨逍 的员工
select * from tb_emp where name='杨逍' ;# 案例2:查询 id小于等于5 的员工信息
select * from tb_emp where id<=5 ;# 案例3:查询 没有分配职位 的员工信息
# 注意:查询为NULL的数据时,不能使用 = null
select * from tb_emp where job is null ;# 案例4:查询 有职位 的员工信息
select * from tb_emp where job is not null ;# 案例5:查询 密码不等于 '123456' 的员工信息
select * from tb_emp where password != 123456 ;# 案例6:查询 入职日期 在 '2000-01-01' (包含) 到 '2010-01-01'(包含) 之间的员工信息
select * from tb_emp where entrydate>= '2000-01-01' and entrydate<= '2010-01-01';
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01';# 案例7:查询 入职时间 在 '2000-01-01' (包含) 到 '2010-01-01'(包含) 之间 且 性别为女的员工信息
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01' and gender=2;# 案例8:查询 职位是 2 (讲师), 3 (学工主管), 4 (教研主管) 的员工信息
select * from tb_emp where job=2 or job=3 or job=4;
select * from tb_emp where job in (2,3 ,4);# 案例9:查询 姓名 为两个字的员工信息
# 通配符 "_" 代表任意1个字符
select * from tb_emp where name like '__';# 案例10:查询 姓 '张' 的员工信息
# 通配符 "%" 代表任意个字符(0个 ~ 多个)
select * from tb_emp where name like '张%';聚合函数
之前做的查询都是横向查询,就是根据条件一行一行的进行判断,而使用聚合函数查询就是纵向查询,它是对一列的值进行计算,然后返回一个结果值。(将一列数据作为一个整体,进行纵向计算)
语法:select 聚合函数(字段列表) from 表名 ;
注意 : 聚合函数会忽略空值,对NULL值不作为统计。
常用聚合函数:
| 函数 | 功能 | 描述 |
|---|---|---|
| count | 统计数量 | 按照列去统计有多少行数据(在根据指定的列统计的时候,如果这一列中有null的行,该行不会被统计在其中) |
| max | 最大值 | 计算指定列的最大值 |
| min | 最小值 | 计算指定列的最小值 |
| avg | 平均值 | 计算指定列的平均值 |
| sum | 求和 | 计算指定列的数值和,如果不是数值类型,那么计算结果为0 |
# 案例1:统计该企业员工数量
# count(字段)
select count(name) from tb_emp ;
select count(id) from tb_emp;# count(常量)
select count(0) from tb_emp;
select count('A') from tb_emp;# count(*) 推荐此写法(MySQL底层进行了优化)
select count(*) from tb_emp;# 案例2:统计该企业最早入职的员工
select min(entrydate) from tb_emp ;# 案例3:统计该企业最迟入职的员工
select max(entrydate) from tb_emp ;# 案例4:统计该企业员工 ID 的平均值
select avg(id) from tb_emp ;# 案例5:统计该企业员工的 ID 之和
select sum(id) from tb_emp ;
分组查询(group by)
分组: 按照某一列或者某几列,把相同的数据进行合并输出。分组其实就是按列进行分类(指定列下相同的数据归为一类),然后可以对分类完的数据进行合并计算。分组查询通常会使用聚合函数进行计算。
语法:select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];注意事项:• 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义• 执行顺序:where > 聚合函数 > havingwhere与having区别(面试题)执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。判断条件不同:where不能对聚合函数进行判断,而having可以。
# 案例1:根据性别分组 , 统计男性和女性员工的数量
select gender,count(*) from tb_emp group by gender ;# 案例2:查询入职时间在 '2015-01-01' (包含) 以前的员工 , 并对结果根据职位分组 , 获取员工数量大于等于2的职位
select job,count(*) from tb_emp
# 分组前:筛选出入职时间在'2015-01-01'之前的员工
where entrydate<='2015-01-01'# 按照职位分组(ob字段下相同的数据划分为一组)
group by job# 分组后:筛选出各组中员工数量>=2的(仅保留满足条件的组)
having count(*)>=2;排序查询(order by)
排序在日常开发中是非常常见的一个操作,有升序排序,也有降序排序。ASC :升序(默认值)、DESC:降序
语法:
select 字段列表
from 表名
[where 条件列表]
[group by 分组字段 ]
order by 字段1 排序方式1 , 字段2 排序方式2 … ;
注意事项:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
# 案例1:根据入职时间, 对员工进行升序排序
# 默认就是ASC(升序)
select * from tb_emp order by entrydate ASC ;
select * from tb_emp order by entrydate;# 案例2:根据入职时间,对员工进行降序排序
select * from tb_emp order by entrydate desc ;# 案例3:根据入职时间对公司的员工进行升序排序,入职时间相同,再按照更新时间进行降序排序
select * from tb_emp order by entrydate ,update_time desc ;分页查询((limit)
分页操作在业务系统开发时,也是非常常见的一个功能,日常我们在网站中看到的各种各样的分页条,后台也都需要借助于数据库的分页操作。
分页查询语法:select 字段列表 from 表名 limit 起始索引, 查询记录数 ;
# 案例1:从起始索引0开始查询员工数据, 每页展示5条记录
select * from tb_emp limit 0, 5 ;# 案例2:查询 第1页 员工数据, 每页展示5条记录
# 如果查询的是第1页数据,起始索引可以省略,直接简写为:limit 条数
select * from tb_emp limit 5 ;# 案例3:查询 第2页 员工数据, 每页展示5条记录
select * from tb_emp limit 5,5 ;# 案例4:查询 第3页 员工数据, 每页展示5条记录
select * from tb_emp limit 10,5 ;
#员工性别统计:
-- if(条件表达式, true取值 , false取值)
select if(gender=1,'男性员工','女性员工') AS 性别, count(*) AS 人数
from tb_emp
group by gender;# 员工职位统计:
# case 表达式 when 值1 then 结果1 when 值2 then 结果2 ... else result end
select (case jobwhen 1 then '班主任'when 2 then '讲师'when 3 then '学工主管'when 4 then '教研主管'else '未分配职位'end) AS 职位 ,count(*) AS 人数
from tb_emp
group by job;
DQL语句-多表操作
多表的设计
关于单表的操作(单表的设计、单表的增删改查)已经学习完了。接下来就要来学习多表的操作,首先来学习多表的设计。项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:一对多(多对一)、多对多、一对一
一对多(多对一)

一对多关系实现:在数据库表中多的一方,添加字段,来关联属于一这方的主键。使用外键约束,让两张表的数据建立连接,保证数据的一致性和完整性。
对应的关键字:foreign key
外键约束的语法:
-- 创建表时指定
create table 表名(字段名 数据类型,...[constraint] [外键名称] foreign key (外键字段名) references主表 (主表列名)
);
-- 建完表后,添加外键
alter table 表名 add constraint 外键名称 foreign key(外键字段名) references 主表(主表列名);
方式1:通过SQL语句操作
-- 修改表: 添加外键约束
alter table tb_emp
add constraint fk_dept_id foreign key (dept_id) references tb_dept(id);
方式2:图形化界面操作

物理外键:指使用foreign key定义外键关联另外一张表。缺点:影响增、删、改的效率(需要检查外键关系)。仅用于单节点数据库,不适用与分布式、集群场景。容易引发数据库的死锁问题,消耗性能。逻辑外键:指在业务层逻辑中,解决外键关联。通过逻辑外键,就可以很方便的解决上述问题。在现在的企业开发中,很少会使用物理外键,都是使用逻辑外键。 甚至在一些数据库开发规范中,会明确指出禁止使用物理外键 foreign key
一对一
一对一关系表在实际开发中应用起来比较简单,通常是用来做单表拆分,也就是将一张大表拆分成两张小表,将大表中的一些基础字段放在一张表当中,将其他的字段放在另外一张表当中,以此来提高数据的操作效率。
一对一的应用场景: 用户表(基本信息+身份信息)
其实,一对一我们可以看成一种特殊的一对多。同样,我们也可以通过外键来体现一对一之间的关系,只需要在任意一方来添加一个外键就可
以了。
一对一 :在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)


多对多
多对多的关系在开发中属于也比较常见的。比如:学生和老师的关系,一个学生可以有多个授课老师,一个授课老师也可以有多个学生。在比如:学生和课程的关系,一个学生可以选修多门课程,一个课程也可以供多个学生选修。
案例:学生与课程的关系
关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择
实现关系:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键

多表查询
多表查询:查询时从多张表中获取所需数据
单表查询的SQL语句:select 字段列表 from 表名;
多表查询的SQL语句:select 字段列表 from 表1, 表2;直接使用会出现无效的笛卡尔积,需要给多表查询加上连接查询的条件。
多表查询的SQL语句:select * from 表1, 表2 where 连接条件 ;如:select * from tb_emp , tb_dept where tb_emp.dept_id = tb_dept.id ;
多表查询可以分为:连接查询(内连接, 外连接)、子查询。
内连接:相当于查询A、B交集部分数据

外连接:
左外连接:查询 左表 所有数据(包括两张表交集部分数据)
右外连接:查询 右表 所有数据(包括两张表交集部分数据)
连接查询
内连接
内连接查询:查询两表或多表中交集部分数据。
内连接从语法上可以分为:隐式内连接、显式内连接
隐式内连接:select 字段列表 from 表1 , 表2 where 条件 ... ;
显式内连接:select 字段列表 from 表1 [ inner ] join 表2 on 连接条件 ... ;多表查询时给表起别名:tableA as 别名1 , tableB as 别名2 ;tableA 别名1 , tableB 别名2 ;
案例:查询员工的姓名及所属的部门名称
隐式内连接实现
select tb_emp.name , tb_dept.name -- 分别查询两张表中的数据
from tb_emp , tb_dept -- 关联两张表
where tb_emp.dept_id = tb_dept.id; -- 消除笛卡尔积显式内连接实现
select tb_emp.name , tb_dept.name
from tb_emp inner join tb_dept
on tb_emp.dept_id = tb_dept.id;
外连接
外连接分为两种:左外连接 和 右外连接。
左外连接语法结构:select 字段列表 from 表1 left [ outer ] join 表2 on 连接条件 ... ;
右外连接语法结构:select 字段列表 from 表1 right [ outer ] join 表2 on 连接条件 ... ;
案例:查询员工表中所有员工的姓名, 和对应的部门名称
-- 左外连接:以left join关键字左边的表为主表,查询主表中所有数据,以及和主表匹配的右边表中的数据
select emp.name , dept.name
from tb_emp AS emp left join tb_dept AS dept
on emp.dept_id = dept.id;案例:查询部门表中所有部门的名称, 和对应的员工名称
-- 右外连接
select dept.name , emp.name
from tb_emp AS emp right join tb_dept AS dept
on emp.dept_id = dept.id;
注意事项:左外连接和右外连接是可以相互替换的,只需要调整连接查询时SQL语句中表的先后顺序就可以了。日常开发使用中,更偏向于左外连接。没有匹配到的数据,填充为null
子查询
SQL语句中嵌套select语句,称为嵌套查询,又称子查询。
形式:select * from t1 where column1=(select column1 from t2 ……);
子查询外部的语句可以是 insert/update/delete/select 的任何一个,最常见的是select。
标量子查询(子查询结果为单个值[一行一列])
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询。
常用的操作符: =、<>、>、>=、<、<=
案例1:查询"教研部"的所有员工信息
将需求分解为两步:1. 查询 "教研部" 部门ID、2. 根据 "教研部" 部门ID,查询员工信息-- 1.查询"教研部"部门ID
select id from tb_dept where name = '教研部';-- 2.根据"教研部"部门ID, 查询员工信息
select * from tb_emp where dept_id = 2;-- 合并出上两条SQL语句
select * from tb_emp where dept_id = (select id from tb_dept where
name = '教研部');案例2:查询在 "方东白" 入职之后的员工信息
将需求分解为两步:1. 查询 方东白 的入职日期、2. 查询 指定入职日期之后入职的员工信息-- 1.查询"方东白"的入职日期
select entrydate from tb_emp where name = '方东白';-- 2.查询指定入职日期之后入职的员工信息
select * from tb_emp where entrydate > '2012-11-01';-- 合并以上两条SQL语句
select * from tb_emp where entrydate > (select entrydate from tb_emp where name = '方东白');
列子查询(子查询结果为一列,但可以是多行)
常用的操作符:
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范围之内,多选一 |
| NOT IN | 不在指定的集合范围之内 |
案例:查询"教研部"和"咨询部"的所有员工信息
分解为两步:1. 查询 "销售部" 和 "市场部" 的部门ID2. 根据部门ID, 查询员工信息3.
-- 1.查询"销售部"和"市场部"的部门ID
select id from tb_dept where name = '教研部' or name = '咨询部';-- 2.根据部门ID, 查询员工信息
select * from tb_emp where dept_id in (3,2);-- 合并以上两条SQL语句
select * from tb_emp where dept_id in (select id from tb_dept where name = '教研部' or name = '咨询部');行子查询(子查询结果为一行,但可以是多列)
常用的操作符:= 、<> 、IN 、NOT IN
案例:查询与"韦一笑"的入职日期及职位都相同的员工信息
拆解为两步进行:1. 查询 "韦一笑" 的入职日期 及 职位2. 查询与"韦一笑"的入职日期及职位相同的员工信息-- 查询"韦一笑"的入职日期 及 职位
select entrydate , job from tb_emp where name = '韦一笑'; #查询结果:2007-01-01 , 2-- 查询与"韦一笑"的入职日期及职位相同的员工信息
select * from tb_emp where (entrydate,job) = ('2007-01-01',2);-- 合并以上两条SQL语句
select * from tb_emp where (entrydate,job) = (select entrydate , job from tb_emp where name = '韦一笑');
表子查询(子查询结果为多行多列[相当于子查询结果是一张表])
&emsp:子查询返回的结果是多行多列,常作为临时表,这种子查询称为表子查询。
查询入职日期是 "2006-01-01" 之后的员工信息 , 及其部门信息
分解为两步执行:1. 查询入职日期是 "2006-01-01" 之后的员工信息2. 基于查询到的员工信息,在查询对应的部门信息select * from emp where entrydate > '2006-01-01';
select e.*, d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id ;
事务
在实际的业务开发中,有些业务操作要多次访问数据库。一个业务要发送多条SQL语句给数据库执行。需要将多次访问数据库的操作视为一个整体来执行,要么所有的SQL语句全部执行成功。如果其中有一条SQL语句失败,就进行事务的回滚,所有的SQL语句全部执行失败。
简而言之:事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
事务作用:保证在一个事务中多次操作数据库表中数据时,要么全都成功,要么全都失败。
MYSQL中有两种方式进行事务的操作:1. 自动提交事务:即执行一条sql语句提交一次事务。(默认MySQL的事务是自动提交)2. 手动提交事务:先开启,再提交
事务操作有关的SQL语句:
| SQL语句 | 描述 |
|---|---|
| start transaction; / begin ; | 开启手动控制事务 |
| commit; | 提交事务 |
| rollback; | 回滚事务 |
手动提交事务使用步骤:第1种情况:开启事务 => 执行SQL语句 => 成功 => 提交事务第2种情况:开启事务 => 执行SQL语句 => 失败 => 回滚事务
--开启事务
start transaction--删除部门
delete from tb dept where id =3;--删除部门下的员工
delete from tb_emp where deptid =3;--提交事务
commit;回滚事务
rollback
索引
索引是帮助数据库高效获取数据的数据结构 。简单来讲,就是使用索引可以提高查询的效率。
使用索引优点:1. 提高数据查询的效率,降低数据库的IO成本。2. 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。使用索引缺点:1. 索引会占用存储空间。2. 索引大大提高了查询效率,同时却也降低了insert、update、delete的效率。
MySQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。我们平常所说的索引,如果没有特别指明,都是指默认的 B+Tree 结构组织的索引。
创建索引:create [ unique ] index 索引名 on 表名 (字段名,... ) ;
案例:为tb_emp表的name字段建立一个索引
create index idx_emp_name on tb_emp(name);在创建表时,如果添加了主键和唯一约束,就会默认创建:主键索引、唯一约束
查看索引:show index from 表名;
案例:查询 tb_emp 表的索引信息
show index from tb_emp;
删除索引:drop index 索引名 on 表名;
案例:删除 tb_emp 表中name字段的索引
drop index idx_emp_name on tb_emp;注意事项:主键字段,在建表时,会自动创建主键索引添加唯一约束时,数据库实际上会添加唯一索引
Mybatis
在前面学习MySQL数据库时,都是利用图形化客户端工具(如:idea、datagrip),来操作数据库的。做为后端程序开发人员,通常会使用Java程序来完成对数据库的操作。Java程序操作数据库,现在主流的方式是:Mybatis。
MyBatis是一款优秀的 持久层 框架,用于简化JDBC的开发。
持久层:指的是数据访问层(dao),是用来操作数据库的。
框架:是一个半成品软件,是一套可重用的、通用的、软件基础代码模型。在框架的基础上进行软件开发更加高效、规范、通用、可拓展。
Mybatis入门
Mybatis操作数据库的步骤:1. 准备工作(创建springboot工程、数据库表user、实体类User)2. 引入Mybatis的相关依赖,配置Mybatis(数据库连接信息)3. 编写SQL语句(注解/XML)
创建springboot工程:


在数据库中创建表user

在Java程序中创建实体类User
在创建实体类User时,实体类的属性名与表中的字段名一一对应。

配置Mybatis
连接数据库的四大参数:MySQL驱动类登录名密码数据库连接字符串
在springboot项目中,可以编写application.properties文件,配置数据库连接信息。要连接数据库,就需要配置数据库连接的基本信息,包括:driver-class-name、url 、username,password。
#驱动类名称
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#数据库连接的url
spring.datasource.url=jdbc:mysql://localhost:3306/mybatis
#连接数据库的用户名
spring.datasource.username=root
#连接数据库的密码
spring.datasource.password=1234
编写SQL语句
在创建出来的springboot工程中,在引导类所在包下,在创建一个包 mapper。在mapper包下创建一个接口 UserMapper ,这是一个持久层接口(Mybatis的持久层接口规范一般都叫XxxMapper)。

@Mapper // 在运行时,会自动生成该接口的实现类对象,并且将该对象交给IOC容器管理
public interface UserMapper {//查询所有用户数据@Select("select id, name, age, gender, phone from user")public List<Userff> list();
}
@Mapper注解:表示是mybatis中的Mapper接口
程序运行时:框架会自动生成接口的实现类对象(代理对象),并给交Spring的IOC容器管理
@Select注解:代表的就是select查询,用于书写select查询语句
单元测试
在创建出来的SpringBoot工程中,在src下的test目录下,已经自动帮我们创建好了测试类 ,并且在测试类上已经添加了注解 SpringBootTest,代表该测试类已经与SpringBoot整合。该测试类在运行时,会自动通过引导类加载Spring的环境(IOC容器)。我们要测试那个bean对象,就可以直接通过@Autowired注解直接将其注入进行,然后就可以测试了。
测试类代码如下:
@SpringBootTest
public class SpringbootMybatisQuickstartApplicationTests {@Autowiredprivate UserMapper userMapper;@Testpublic void testList(){List<Userff> userList = userMapper.list();for (Userff user : userList) {System.out.println(user);}}
}
数据库连接池
为了避免频繁的创建连接、销毁连接而带来的资源浪费,mybatis中使用了数据库连接池技术。
数据库连接池是个容器,负责分配、管理数据库连接(Connection)。
数据库连接池的好处:1. 资源重用2. 提升系统响应速度3. 避免数据库连接遗漏
官方(sun)提供了数据库连接池标准(javax.sql.DataSource接口)
获取连接: public Connection getConnection() throws SQLException;
第三方组织必须按照DataSource接口实现
常见的数据库连接池:C3P0、DBCP、Druid、Hikari (springboot默认)
现在使用更多的是:Hikari、Druid (性能更优越)
如果想把默认的数据库连接池切换为Druid数据库连接池:
1. 在pom.xml文件中引入依赖<dependency><!-- Druid连接池依赖 --><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.8</version></dependency>2. 在application.properties中引入数据库连接配置方式1:spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driverspring.datasource.druid.url=jdbc:mysql://localhost:3306/mybatisspring.datasource.druid.username=rootspring.datasource.druid.password=1234方式2:spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driverspring.datasource.url=jdbc:mysql://localhost:3306/mybatisspring.datasource.username=rootspring.datasource.password=1234
lombok
Lombok是一个实用的Java类库,可以通过简单的注解来简化和消除一些必须有但显得很臃肿的Java代码。

通过注解的形式自动生成构造器、getter/setter、equals、hashcode、toString等方法,并可以自动化生成日志变量,简化java开发、提高效率。
| 注解 | 作用 |
|---|---|
| @Getter/@Setter | 为所有的属性提供get/set方法 |
| @ToString | 会给类自动生成易阅读的 toString 方法 |
| @EqualsAndHashCode | 根据类所拥有的非静态字段自动重写 equals 方法和 hashCode方法 |
| @Data | 提供了更综合的生成代码功能(@Getter + @Setter +@ToString + EqualsAndHashCode) |
| @NoArgsConstructor | 为实体类生成无参的构造器方法 |
| @AllArgsConstructor | 为实体类生成除了static修饰的字段之外带有各参数的构造器方法。 |
lombok依赖
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId>
</dependency>
Mybatis基础操作
删除
@Mapper
public interface EmpMapper {// 根据id删除数据,占位符-动态删除@Delete("delete from emp where id=#{id}")public void delete(Integer id);
}
如果mapper接口方法形参只有一个普通类型的参数,#{…} 里面的属性名可以随便写,如:#{id}、#{value}。但是建议保持名字一致。
日志输入
在Mybatis当中可以借助日志,查看到sql语句的执行、执行传递的参数以及执行结果。
具体操作如下:1. 打开application.properties文件2. 开启mybatis的日志,并指定输出到控制台
#指定mybatis输出日志的位置, 输出控制台
mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
开启日志之后,我们再次运行单元测试,可以看到在控制台中,输出了以下的SQL语句信息:

我们发现输出的SQL语句:delete from emp where id = ?,输入的参数16并没有在后面拼接,id的值是使用?进行占位。那这种SQL语句我们称为预编译SQL。预编译SQL有两个优势:1. 性能更高、2. 更安全(防止SQL注入)
性能更高:预编译SQL,编译一次之后会将编译后的SQL语句缓存起来,后面再次执行这条语句时,不会再次编译。(只是输入的参数不同)
更安全(防止SQL注入):将敏感字进行转义,保障SQL的安全性。
SQL注入:是通过操作输入的数据来修改事先定义好的SQL语句,以达到执行代码对服务器进行攻击的方法。
参数占位符
在Mybatis中提供的参数占位符有两种:${…} 、#{…}
#{...}执行SQL时,会将#{…}替换为?,生成预编译SQL,会自动设置参数值使用时机:参数传递,都使用#{…}${...}拼接SQL。直接将参数拼接在SQL语句中,存在SQL注入问题使用时机:如果对表名、列表进行动态设置时使用注意事项:在项目开发中,建议使用#{...},生成预编译SQL,防止SQL注入安全。
新增
SQL语句:
insert into emp(username, name, gender, image, job, entrydate,
dept_id, create_time, update_time) values ('songyuanqiao','宋远桥',
1,'1.jpg',2,'2012-10-09',2,'2022-10-01 10:00:00','2022-10-01 10:00:00');
接口方法:
@Mapper
public interface EmpMapper {@Insert("insert into emp(username, name, gender, image, job,entrydate, dept_id, create_time, update_time) values (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})")public void insert(Emp emp);说明:#{...} 里面写的名称是对象的属性名
测试类:
@SpringBootTest
class SpringbootMybatisBasicApplicationTests {// 创建对象@Autowiredprivate EmpMapper empMapper;@Testpublic void testInsert() {//创建员工对象Emp emp = new Emp();emp.setUsername("tom");emp.setName("汤姆");emp.setImage("1.jpg");emp.setGender((short)1);emp.setJob((short)1);emp.setEntrydate(LocalDate.of(2000,1,1));emp.setCreateTime(LocalDateTime.now());emp.setUpdateTime(LocalDateTime.now());emp.setDeptId(1);empMapper.insert(emp);}}
主键返回:在数据添加成功后,需要获取插入数据库数据的主键。
默认情况下,执行插入操作时,是不会主键值返回的。如果我们想要拿到主键值,需要在Mapper接口中的方法上添加一个Options注解,并在注解中指定属性useGeneratedKeys=true和keyProperty=“实体类属性名”
主键返回代码实现:
// 新增员工,参数多-封装成一个对象//会自动将生成的主键值,赋值给emp对象的id属性@Options(useGeneratedKeys = true,keyProperty = "id")@Insert("insert into emp(username, name, gender, image, job,entrydate, dept_id, create_time, update_time) values" +" (#{username}, #{name}, #{gender}, #{image}, #{job}, #{entrydate}, #{deptId}, #{createTime}, #{updateTime})")public void insert(Emp emp);测试:
@SpringBootTest
class SpringbootMybatisBasicApplicationTests {// 创建对象@Autowiredprivate EmpMapper empMapper;@Testpublic void testInsert() {//创建员工对象Emp emp = new Emp();emp.setUsername("tom2");emp.setName("汤姆2");emp.setImage("1.jpg");emp.setGender((short)1);emp.setJob((short)1);emp.setEntrydate(LocalDate.of(2000,1,1));emp.setCreateTime(LocalDateTime.now());emp.setUpdateTime(LocalDateTime.now());emp.setDeptId(1);empMapper.insert(emp);System.out.println(emp.getDeptId());}}更新
SQL语句:
update emp set username = 'linghushaoxia', name = '令狐少侠', gender =1 ,
image = '1.jpg' , job = 2, entrydate = '2012-01-01', dept_id = 2,
update_time = '2022-10-01 12:12:12' where id = 18;
接口方法:
/*** 根据id修改员工信息*/
@Update("update emp set username=#{username}, name=#{name}, gender=#{gender}, image=#{image}, job=#{job}," +"entrydate=#{entrydate}, dept_id=#{deptId}, update_time=#{updateTime} where id=#{id}")
public void update(Emp emp);
测试类:
@SpringBootTest
class SpringbootMybatisBasicApplicationTests {// 创建对象@Autowiredprivate EmpMapper empMapper;@Testpublic void testUpdate() {//要修改的员工信息Emp emp = new Emp();emp.setId(20);emp.setUsername("songdaxia");emp.setPassword(null);emp.setName("老宋");emp.setImage("2.jpg");emp.setGender((short)1);emp.setJob((short)2);emp.setEntrydate(LocalDate.of(2012,1,1));emp.setCreateTime(null);emp.setUpdateTime(LocalDateTime.now());emp.setDeptId(2);//调用方法,修改员工数据empMapper.update(emp);}}
查询
SQL语句:
select id, username, password, name, gender, image, job, entrydate,dept_id, create_time, update_time from emp;
接口方法:
@Select("select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp where id=#{id}")
public Emp getById(Integer id);
测试类:
@Test
public void testGetById(){Emp emp = empMapper.getById(1);System.out.println(emp);
}
数据封装
我们看到查询返回的结果中大部分字段是有值的,但是deptId,createTime,updateTime这几个字段是没有值的,而数据库中是有对应的字段值的,这是为什么呢?

原因如下:实体类属性名和数据库表查询返回的字段名一致,mybatis会自动封装。如果实体类属性名和数据库表查询返回的字段名不一致,不能自动封装。解决方案: 1. 起别名2. 结果映射3. 开启驼峰命名
起别名:在SQL语句中,对不一样的列名起别名,别名和实体类属性名一样
@Select("select id, username, password, name, gender, image, job, entrydate, " +"dept_id AS deptId, create_time AS createTime, update_time AS updateTime " +"from emp " +"where id=#{id}")
public Emp getById(Integer id);
手动结果映射:通过 @Results及@Result 进行手动结果映射
@Results({@Result(column = "dept_id", property = "deptId"),@Result(column = "create_time", property = "createTime"),@Result(column = "update_time", property = "updateTime")})
@Select("select id, username, password, name, gender, image, job,entrydate, " +"dept_id, create_time, update_time from emp where id=#{id}")
public Emp getById(Integer id);
开启驼峰命名(推荐):如果字段名与属性名符合驼峰命名规则,mybatis会自动通过驼峰命名规则映射
# 在application.properties中添加:
mybatis.configuration.map-underscore-to-camel-case=true
要使用驼峰命名前提是 实体类的属性 与 数据库表中的字段名严格遵守驼峰命名。
条件查询
SQL语句:
select id, username, password, name, gender, image, job, entrydate,dept_id, create_time, update_time
from emp
where name like '%张%'
and gender = 1
and entrydate between '2010-01-01' and '2020-01-01 '
order by update_time desc;
接口方法:
方式一
@Mapper
public interface EmpMapper {
@Select("select * from emp " +"where name like '%${name}%' " +"and gender = #{gender} " +"and entrydate between #{begin} and #{end} " +"order by update_time desc")
public List<Emp> list(String name, Short gender, LocalDate begin,LocalDate end);
}方式二(解决SQL注入风险)
使用MySQL提供的字符串拼接函数:concat('%' , '关键字' , '%')
@Mapper
public interface EmpMapper {
@Select("select * from emp " +"where name like concat('%',#{name},'%') " +"and gender = #{gender} " +"and entrydate between #{begin} and #{end} " +"order by update_time desc")
public List<Emp> list(String name, Short gender, LocalDatebegin, LocalDate end);
}
Mybatis的XML配置文件
Mybatis的开发有两种方式:1. 注解、2. XML
使用Mybatis的注解方式,主要是来完成一些简单的增删改查功能。如果需要实现复杂的SQL功能,建议使用XML来配置映射语句,也就是将SQL语句写在XML配置文件中。
在Mybatis中使用XML映射文件方式开发,需要符合一定的规范:1. XML映射文件的名称与Mapper接口名称一致,并且将XML映射文件和Mapper接口放置在相同包下 (同包同名)2. XML映射文件的namespace属性为Mapper接口全限定名一致3. XML映射文件中sql语句的id与Mapper接口中的方法名一致,并保持返回类型一致。<select> 标签:就是用于编写select查询语句的。
resultType 属性,指的是查询返回的单条记录所封装的类型。

XML配置文件实现
第1步:创建XML映射文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.mapper.EmpMapper"><!--查询操作--><select id="list" resultType="com.example.pojo.Emp">select * from emp where name like concat('%',#{name},'%') and gender = #{gender}and entrydate between #{begin} and #{end} order by update_time desc</select></mapper>
Mybatis动态SQL
在页面原型中,列表上方的条件是动态的,是可以不传递的,也可以只传递其中的1个或者2个或者全部。SQL语句会随着用户的输入或外部条件的变化而变化,我们称为:动态SQL。
动态SQL-if
<if> :用于判断条件是否成立。<if test="条件表达式">要拼接的sql语句
</if><where>where元素只会在子元素有内容的情况下才插入where子句,而且会自动去除子句的开头的AND或OR<set>动态地在行首插入 SET 关键字,并会删掉额外的逗号。(用在update语句中)
条件查询
示例:把SQL语句改造为动态SQL方式
原有的SQL语句:
<select id="list" resultType="com.itheima.pojo.Emp">select * from empwhere name like concat('%',#{name},'%')and gender = #{gender}and entrydate between #{begin} and #{end}order by update_time desc
</select>动态SQL语句:
<select id="list" resultType="com.itheima.pojo.Emp">select * from emp<where><if test="name != null">name like concat('%',#{name},'%')</if><if test="gender != null">and gender = #{gender}</if><if test="begin != null and end != null">and entrydate between #{begin} and #{end}</if></where>order by update_time desc
</select><!--更新操作-->
<update id="update">
update emp
<!-- 使用set标签,代替update语句中的set关键字 -->
<set><if test="username != null">username=#{username},</if><if test="name != null">name=#{name},</if><if test="gender != null">gender=#{gender},</if><if test="image != null">image=#{image},</if><if test="job != null">job=#{job},</if><if test="entrydate != null">entrydate=#{entrydate},</if><if test="deptId != null">dept_id=#{deptId},</if><if test="updateTime != null">update_time=#{updateTime}</if></set>where id=#{id}
</update>
动态SQL-foreach
应用场景:删除功能(既支持删除单条记录,又支持批量删除)
使用 <foreach> 遍历指定方法中传递的参数集合
<foreach collection="" item="" separator="" open="" close=""> </foreach>collection:遍历的集合
item:遍历出来的元素
separator:分隔符
open:遍历开始前拼接的SQL片段
close:遍历结束后拼接的SQ工片段
<!--批量删除操作-->
<delete id="deleteByIds">delete from emp where id in<foreach collection="ids" item="id" separator="," open="(" close=")">#{id}</foreach>
</delete>
动态SQL-sql、include
在xml映射文件中配置的SQL,有时可能会存在很多重复的片段,此时就会存在很多冗余的代码。可以对重复的代码片段进行抽取,将其通过 标签封装到一个SQL片段,然后再通过 < include > 标签进行引用。
<sql> :定义可重用的SQL片段
<include> :通过属性refid,指定包含的SQL片段
SQL片段: 抽取重复的代码
<sql id="commonSelect">select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time from emp
</sql>
通过 <include> 标签在原来抽取的地方进行引用
<select id="list" resultType="com.itheima.pojo.Emp"><include refid="commonSelect"/><where><if test="name != null">name like concat('%',#{name},'%')</if><if test="gender != null">and gender = #{gender}</if><if test="begin != null and end != null">and entrydate between #{begin} and #{end}</if></where>order by update_time desc
</select>


)




)

)
 (64 位))








