一、介绍
由美团开发,开源项目链接:https://github.com/Meituan-Dianping/Leaf
Leaf同时支持号段模式和snowflake算法模式,可以切换使用。ID号码是趋势递增的8byte的64位数字,满足上述数据库存储的主键要求。
Leaf的snowflake模式依赖于ZooKeeper,不同于原始snowflake算法也主要是在workId的生成上,Leaf中workId是基于ZooKeeper的顺序Id来生成的,每个应用在使用Leaf-snowflake时,启动时都会都在Zookeeper中生成一个顺序Id,相当于一台机器对应一个顺序节点,也就是一个workId。
Leaf的号段模式是对直接用数据库自增ID充当分布式ID的一种优化,减少对数据库的频率操作。相当于从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,业务服务将号段在本地生成1~1000的自增ID并加载到内存.。
二、特性:
1)全局唯一,绝对不会出现重复的ID,且ID整体趋势递增。
2)高可用,服务完全基于分布式架构,即使MySQL宕机,也能容忍一段时间的数据库不可用。
3)高并发低延时,在CentOS 4C8G的虚拟机上,远程调用QPS可达5W+,TP99在1ms内。
4)接入简单,直接通过公司RPC服务或者HTTP调用即可接入。
Leaf采用双buffer的方式,它的服务内部有两个号段缓存区segment。当前号段已消耗10%时,还没能拿到下一个号段,则会另启一个更新线程去更新下一个号段。
简而言之就是Leaf保证了总是会多缓存两个号段,即便哪一时刻数据库挂了,也会保证发号服务可以正常工作一段时间。
三、案例记录
<dependency><artifactId>leaf-boot-starter</artifactId><groupId>com.sankuai.inf.leaf</groupId><version>1.0.1-RELEASE</version></dependency><dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId><version>2.6.0</version><exclusions><exclusion><artifactId>log4j</artifactId><groupId>log4j</groupId></exclusion></exclusions></dependency></dependencies>
属性文件配置:
`
``properties
leaf.name=com.boge.vip
leaf.segment.enable=false
#leaf.segment.url=
#leaf.segment.username=
#leaf.segment.password=leaf.snowflake.enable=true
#leaf.snowflake.address=
#leaf.snowflake.port=
leaf.snowflake.address=192.168.56.100
leaf.snowflake.port=2181
启动类增加@EnableLeafServer注解
注意你还需要启动一个Zookeeper服务。
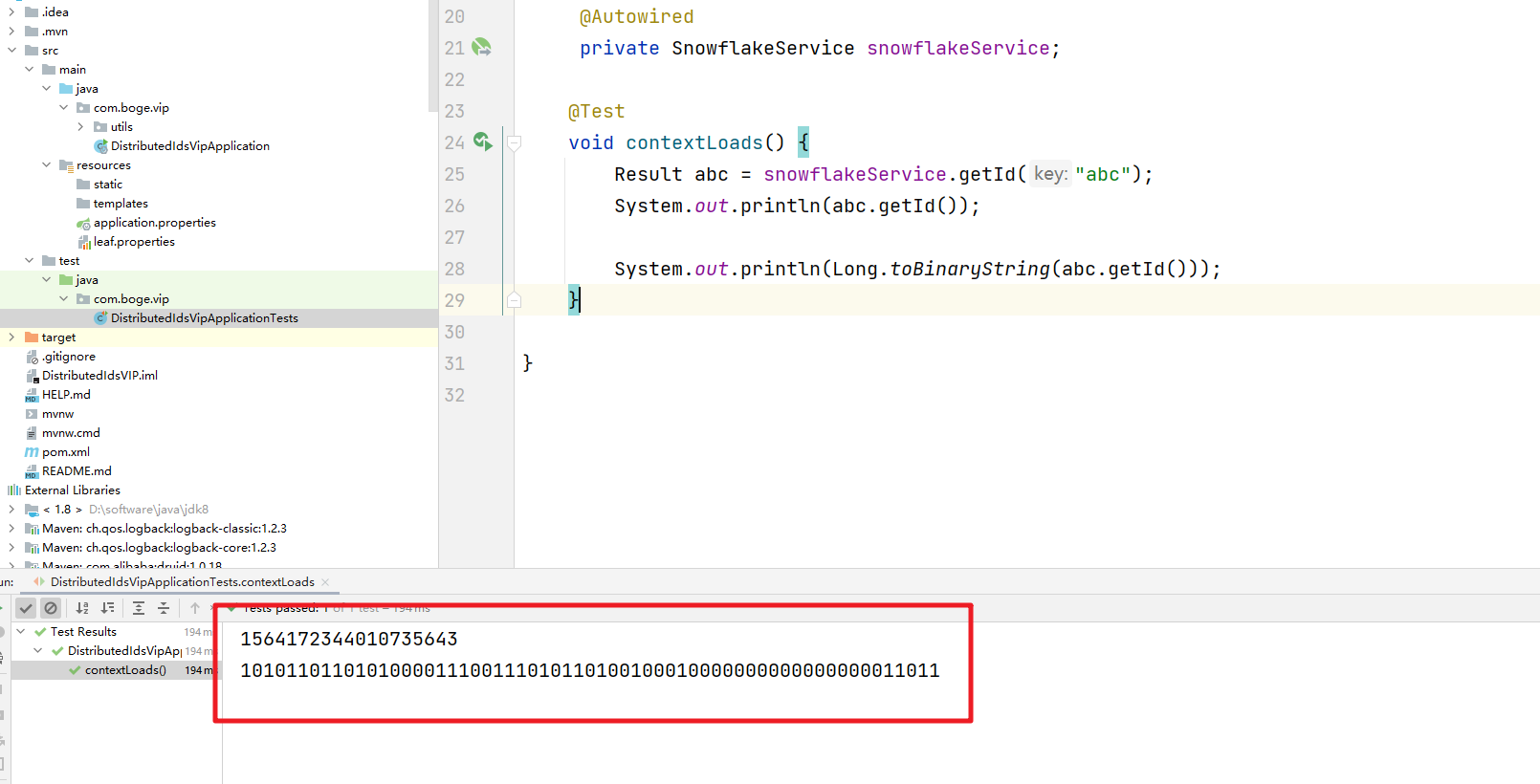
测试代码
@SpringBootTest
class DistributedIdsVipApplicationTests {@AutowiredRedisDistributedId redisDistributedId;@Autowiredprivate SnowflakeService snowflakeService;@Testvoid contextLoads() {Result abc = snowflakeService.getId("abc");System.out.println(abc.getId());System.out.println(Long.toBinaryString(abc.getId()));}}
如果对你有帮助,可以关注博主(不定期更新各种技术文档) 给博主一个免费的点赞以示鼓励,谢谢 !
欢迎各位🔎点赞👍评论收藏⭐️



















