摘要
存在 theoretical results show that SA and HL are conflicting measures
1 介绍
an algorithm usually performs well on some measures while poorly on others.There are a few works studying the behavior of various measures.Although they provide valuable insights, the generalization analysis of the algorithms on different measures is still largely open.本文 focus on kernel-based learning algorithms which have been widely-used for MLC,this is the first to provide the generalization error bounds for the learning algorithms between these measures for MLC
number of labels (i.e., c) plays an important role in the generalization error bounds
3 Generalization analysis techniques



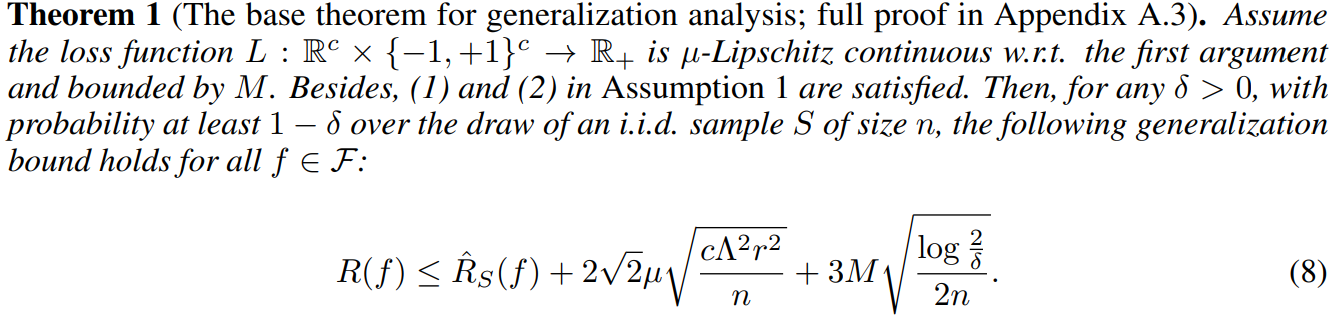
4 Learning guarantees between Hamming and Subset Loss
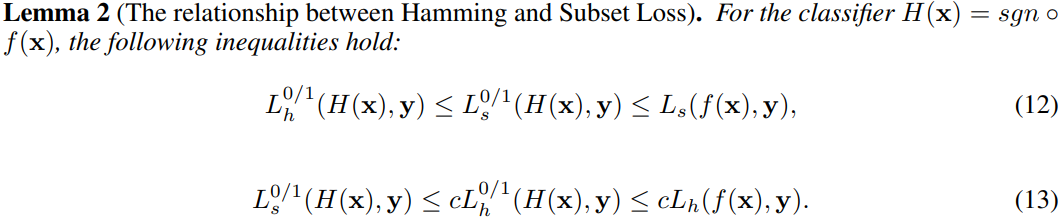
4.1 Learning guarantees of Algorithm A h A^h Ah
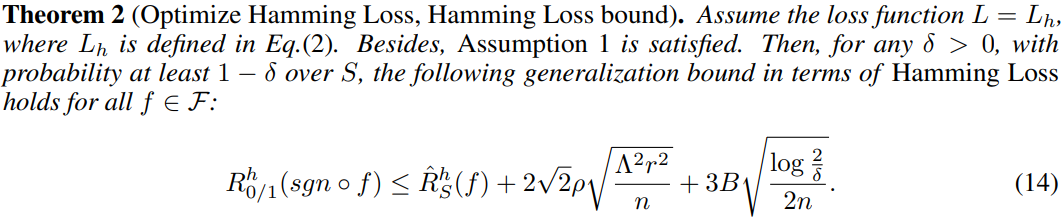
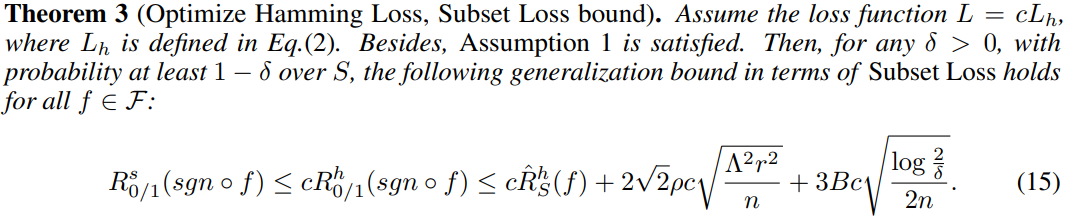
4.2 Learning guarantees of Algorithm A s A^s As
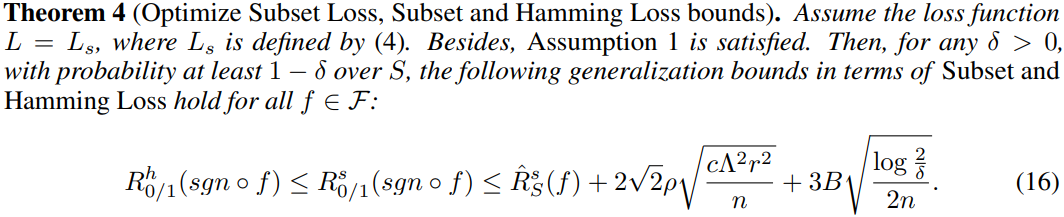
4.3 对比
For Hamming Loss, A h A^h Ah has tighter bound than A s A^s As, thus A h A^h Ah would perform better than A s A^s As
5 Learning guarantees between Hamming and Ranking Loss
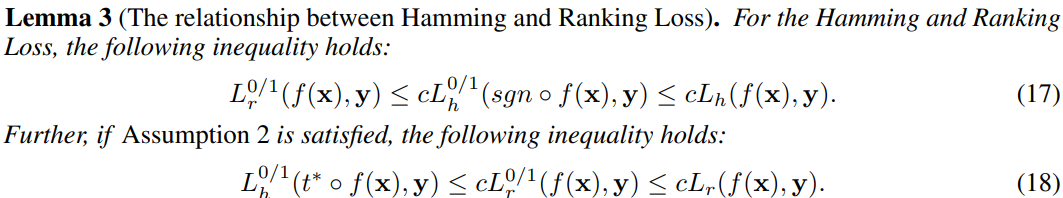
5.1 Learning guarantee of Algorithm A h A^h Ah
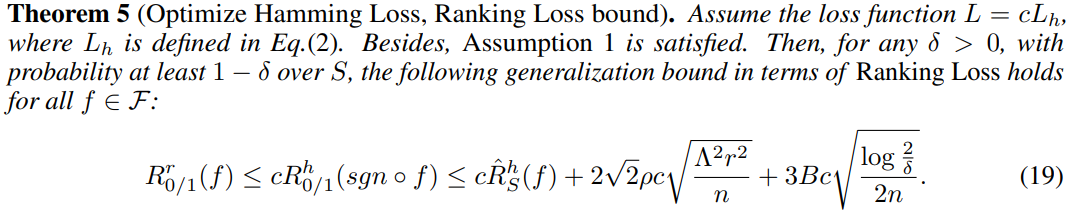
When c is small, A h A^h Ah can have promising performance for Ranking Loss
5.2 Learning guarantee of Algorithm A r A^r Ar
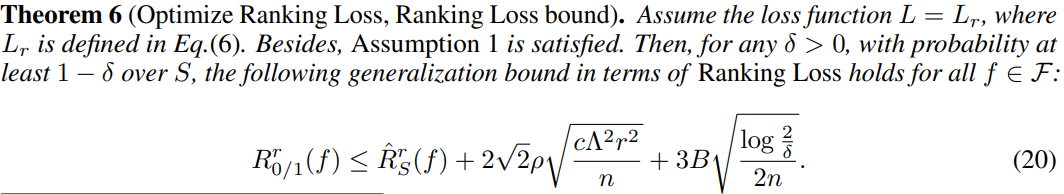
6 实验
for the experiments,the goal is to validate 本文 theoretical results rather than illustrating the performance superiority.For A h A^h Ah and A s A^s As, we take the linear models with the hinge base loss function for simplicity
表2

A h A^h Ah复现结果:
image: 0.192 ± 0.010 \textbf{0.192}\pm \textbf{0.010} 0.192±0.010,enron: 0.176 ± 0.013 \textbf{0.176}\pm \textbf{0.013} 0.176±0.013,rcv1-subset1: 0.109 ± 0.002 \textbf{0.109}\pm \textbf{0.002} 0.109±0.002
表3

复现结果: D a t a s e t i m a g e e n r o n r c v 1 − s u b s e t 1 A h 0.417 ± 0.021 0.051 ± 0.021 − − − A s − − − − − − 0.050 ± 0.004 \begin{array}{} Dataset&image&enron&rcv1-subset1\\ A^h&\textbf{0.417}\pm \textbf{0.021}&\textbf{0.051}\pm \textbf{0.021}& ---\\ A^s &--- & ---&\textbf{0.050}\pm \textbf{0.004} \end{array} DatasetAhAsimage0.417±0.021−−−enron0.051±0.021−−−rcv1−subset1−−−0.050±0.004
默认设置有误差很正常
感悟
第四篇完全复现的论文!



















