文本标注
现在让我们考虑词元级任务,比如文本标注(text tagging),其中每个词元都被分配了一个标签。在文本标注任务中,词性标注为每个单词分配词性标记(例如,形容词和限定词)。 根据单词在句子中的作用。如,在Penn树库II标注集中,句子“John Smith‘s car is new”应该被标记为“NNP(名词,专有单数)NNP POS(所有格结尾)NN(名词,单数或质量)VB(动词,基本形式)JJ(形容词)”。
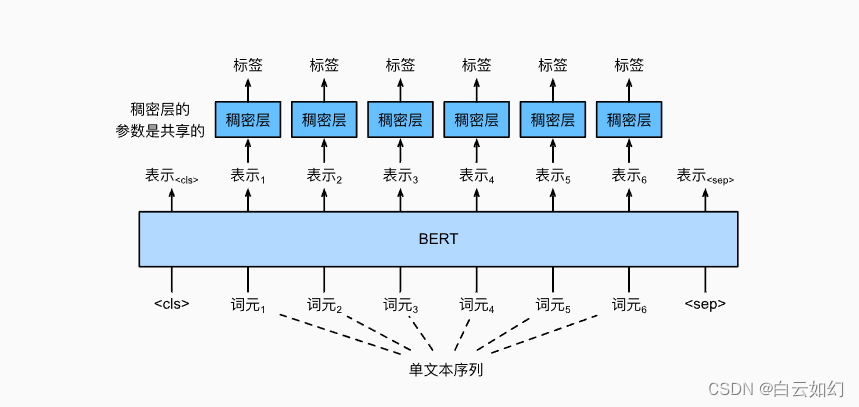
上图中说明了文本标记应用的BERT微调。与 文本对分类或回归相比,唯一的区别在于,在文本标注中,输入文本的每个词元的BERT表示被送到相同的额外全连接层中,以输出词元的标签,例如词性标签。
问答
作为另一个词元级应用,问答反映阅读理解能力。 例如,斯坦福问答数据集(Stanford Question Answering Dataset,SQuAD v1.1)由阅读段落和问题组成,其中每个问题的答案只是段落中的一段文本(文本片段)。举个例子,考虑一段话:“Some experts report that a mask’s efficacy is inconclusive.However,mask makers insist that their products,such as N95 respirator masks,can guard against the virus.”(“一些专家报告说面罩的功效是不确定的。然而,口罩制造商坚持他们的产品,如N95口罩,可以预防病毒。”)还有一个问题“Who say that N95 respirator masks can guard against the virus?”(“谁说N95口罩可以预防病毒?”)。答案应该是文章中的文本片段“mask makers”(“口罩制造商”)。因此,SQuAD v1.1的目标是在给定问题和段落的情况下预测段落中文本片段的开始和结束。
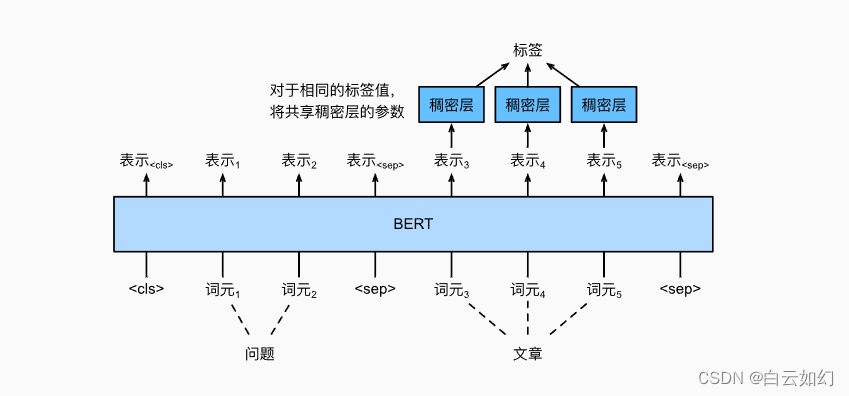
为了微调BERT进行问答,在BERT的输入中,将问题和段落分别作为第一个和第二个文本序列。为了预测文本片段开始的位置,相同的额外的全连接层将把来自位置的任何词元的BERT表示转换成标量分数
。文章中所有词元的分数还通过softmax转换成概率分布,从而为文章中的每个词元位置
分配作为文本片段开始的概率
。预测文本片段的结束与上面相同,只是其额外的全连接层中的参数与用于预测开始位置的参数无关。当预测结束时,位置
的词元由相同的全连接层变换成标量分数
。上图描述了用于问答的微调BERT。
对于问答,监督学习的训练目标就像最大化真实值的开始和结束位置的对数似然一样简单。当预测片段时,我们可以计算从位置到位置
的有效片段的分数
,并输出分数最高的跨度。