第 1 章:rdd概述
1.1 什么是rdd
rdd(resilient distributed dataset)叫做弹性分布式数据集,是spark中最基本的数据抽象。
代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
1.1.1 rdd类比工厂生产
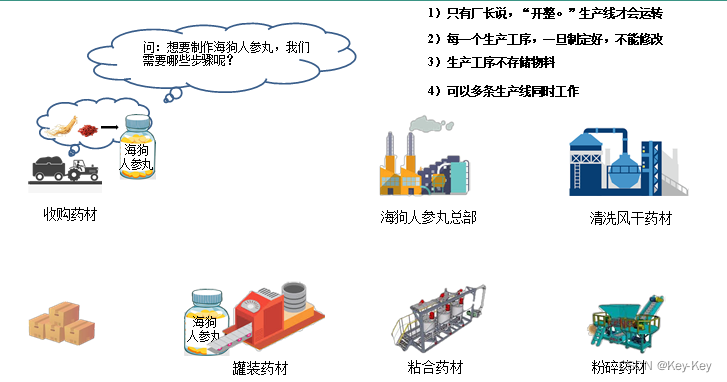
1.1.2 wordcount工作流程

1.2 rdd五大特性
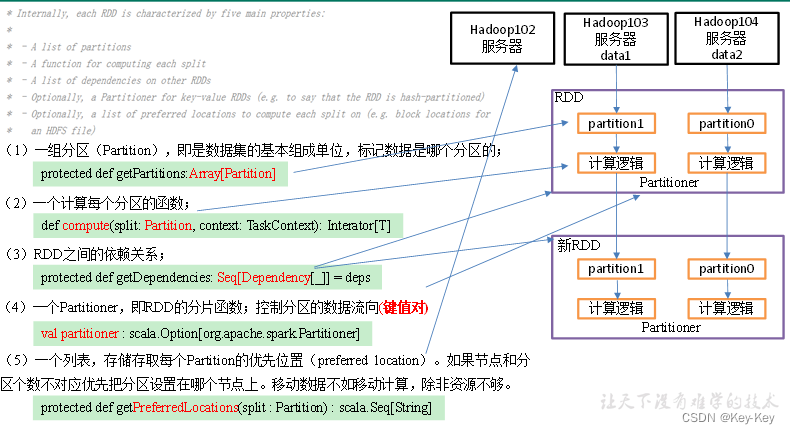
1、一组分区(partition),即是数据集的基本组成单位,标记数据是哪个分区的;
protected def getpartitions:array[partition]
2、一个计算每个分区的函数;
def compute(split:partition,context:taskcontext):inteator[t]
3、rdd之间的依赖关系;
protected def getdependencies:seq[dependency[ ]]=deps
4、一个partitioner,即rdd的分片函数;控制分区的数据流向(键值对)
val partitioner:scala.option[org.apache.sparkpartitioner]
5、一个列表,存储存取每个partition的优先位置(preferred location)。如果节点和分区个数不对应优先把分区设置在哪个节点上。移动数据不如移动计算,除非资源不够。
protect def getpreferredlocations(split:partition):scala.sea[string]
第 2 章:rdd编程
2.1 rdd的创建
在spark中创建rdd的创建方式可以分为三种:从集合中创建rdd、从外部存储创建rdd、从其它rdd创建。
2.1.1 idea环境准备
1、创建一个maven工程,工程名称叫sparkcoretest

2、添加scala框架支持
3、创建一个scala文件夹,并把它修改为sourceroot
4、创建包名:com.atguigu.createrdd
5、在pom文件中添加spark-core的依赖和scala的编译插件
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.1.3</version></dependency>
</dependencies><build><finalName>SparkCoreTest</finalName><plugins><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.4.6</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin></plugins>
</build>2.1.2 从集合中创建
1、从集合中创建rdd,spark主要提供了两种函数:parallelize和makerdd
package com.atguigu.createimport org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object Test01_FromList {def main(args: Array[String]): Unit = {// 1.创建sc的配置对象val conf: SparkConf = new SparkConf().setAppName("sparkCore").setMaster("local[*]")// 2. 创建sc对象val sc = new SparkContext(conf)// 3. 编写任务代码val list = List(1, 2, 3, 4)// 从集合创建rddval intRDD: RDD[Int] = sc.parallelize(list)intRDD.collect().foreach(println)// 底层调用parallelize 推荐使用 比较好记val intRDD1: RDD[Int] = sc.makeRDD(list)intRDD1.collect().foreach(println)// 4.关闭scsc.stop()}
}注意:makerdd有两种重构方法,重构方法一如下,makerdd和parallelize功能一样
def makeRDD[T: ClassTag](seq: Seq[T],numSlices: Int = defaultParallelism): RDD[T] = withScope {parallelize(seq, numSlices)
}2、makerdd的重构方法二,增加了位置信息
注意:只需要知道makerdd不完全等于parallelize即可
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] = withScope {assertNotStopped()val indexToPrefs = seq.zipWithIndex.map(t => (t._2, t._1._2)).toMapnew ParallelCollectionRDD[T](this, seq.map(_._1), math.max(seq.size, 1), indexToPrefs)
}2.1.3 从外部存储系统的数据集创建
由外部存储系统的数据集创建rdd包括:本地的文件系统,还有所有hadoop支持的数据集,比如hdfs、hbase等
1、数据准备
在新建的sparkcoretest项目名称上右键->新建input文件夹->在input文件夹上右键->分别新建1.txt和2.txt。每个文件里面准备一些word单词。
2、创建rdd
package com.atguigu.createimport org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object Test02_FromFile {def main(args: Array[String]): Unit = {// 1.创建sc的配置对象val conf: SparkConf = new SparkConf().setAppName("sparkCore").setMaster("local[*]")// 2. 创建sc对象val sc = new SparkContext(conf)// 3. 编写任务代码// 不管文件中存的是什么数据 读取过来全部当做字符串处理val lineRDD: RDD[String] = sc.textFile("input/1.txt")lineRDD.collect().foreach(println)// 4.关闭scsc.stop()}
}2.1.4 从其它rdd创建
主要是通过一个rdd运算完后,再产生新的rdd
2.1.5 创建idea快捷键
1、点击file->settings…->editor->live templates-output->live template
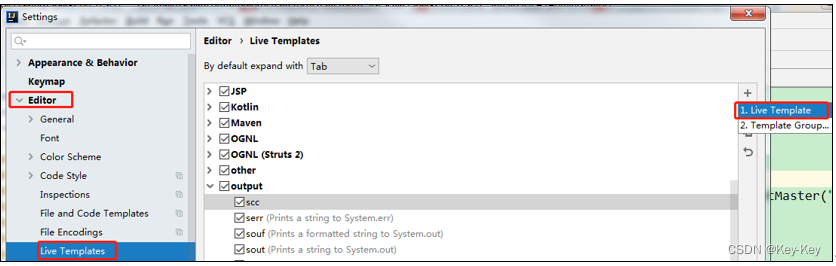
2、点击左下角的define->选择scala
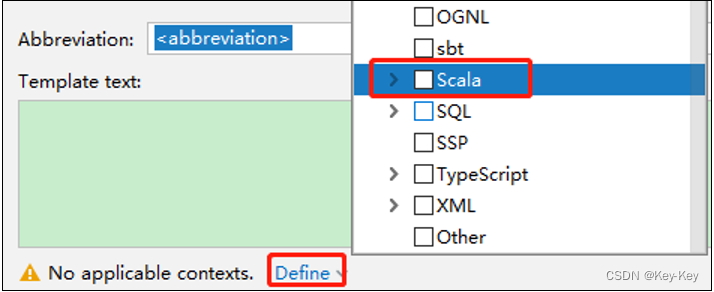
3、在abbreviation中输入快捷键名称scc,在template text中填写,输入快捷键后生成的内容

//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)//4.关闭连接
sc.stop()2.2 分区规则
2.2.1 从集合创建rdd
1、创建一个包名:com.atguigu.partition
2、代码验证
package com.atguigu.createimport org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object Test03_ListPartition {def main(args: Array[String]): Unit = {// 1.创建sc的配置对象val conf: SparkConf = new SparkConf().setAppName("sparkCore").setMaster("local[*]")// 2. 创建sc对象val sc = new SparkContext(conf)// 3. 编写任务代码// 默认环境的核数// 可以手动填写参数控制分区的个数val intRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5),2)// 数据分区的情况// 0 => 1,2 1 => 3,4,5// RDD的五大特性 getPartitions// 利用整数除机制 左闭右开// 0 => start 0*5/2 end 1*5/2// 1 => start 1*5/2 end 2*5/2// 将rdd保存到文件 有几个文件生成 就有几个分区intRDD.saveAsTextFile("output")// 4.关闭scsc.stop()}
}2.2.2 从文件创建rdd
1、分区测试
package com.atguigu.createimport org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object Test04_FilePartition {def main(args: Array[String]): Unit = {// 1.创建sc的配置对象val conf: SparkConf = new SparkConf().setAppName("sparkCore").setMaster("local[*]")// 2. 创建sc对象val sc = new SparkContext(conf)// 3. 编写任务代码// 默认填写的最小分区数 2和环境的核数取小的值 一般为2// math.min(defaultParallelism, 2)val lineRDD: RDD[String] = sc.textFile("input/1.txt",3)// 具体的分区个数需要经过公式计算// 首先获取文件的总长度 totalSize// 计算平均长度 goalSize = totalSize / numSplits// 获取块大小 128M// 计算切分大小 splitSize = Math.max(minSize, Math.min(goalSize, blockSize));// 最后使用splitSize 按照1.1倍原则切分整个文件 得到几个分区就是几个分区// 实际开发中 只需要看文件总大小 / 填写的分区数 和块大小比较 谁小拿谁进行切分lineRDD.saveAsTextFile("output")// 数据会分配到哪个分区// 如果切分的位置位于一行的中间 会在当前分区读完一整行数据// 0 -> 1,2 1 -> 3 2 -> 4 3 -> 空// 4.关闭scsc.stop()}
}2、分区源码
注意:getsplits文件返回的是切片规划,真正读取是在compute方法中创建linerecordreader读取的,有两个关键变量:start=split.getstart() end=start+split.getlength
1)分区数量的计算方式
totalsize=10
goalsize=10/3=3(byte)表示每个分区存储3字节的数据
分区数=totalsize/goalsize=10/3=3
4字节大于3字节的1.1倍,符合hadoop切片1.1倍的策略,因此会多创建一个分区,即一共4个分区 3,3,3,1
2)spark读取文件,采用的是hadoop的方式读取,所以一行一行读取,跟字节数没有关系
3)数据读取位置计算的以偏移量为单位来进行计算的
4)数据分区的偏移量范围的计算

2.3 transformation转换算子
rdd整体上分为value类型、双value类型和key-value类型。
2.3.1 value类型
1、创建包名:com.atguigu.value
2.3.1.1 map()映射
1、函数签名:def.map(u:classtag)(f:t=>u):rdd[u]
2、功能说明:参数f是一个函数,它可以接收一个参数。当某个rdd执行map方法时,会遍历该rdd中的每一个数据项,并依次应用f函数,从而产生一个新的rdd。即,这个新rdd中的每一个元素都是原来rdd中每一个元素依次应用f函数而得到的。
3、需求说明:创建一个1-4数组的rdd,两个分区,将所有元素*2形成新的rdd
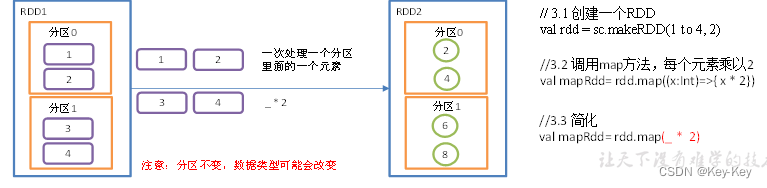
4、具体实现
object value01_map {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc = new SparkContext(conf)//3具体业务逻辑// 3.1 创建一个RDDval rdd: RDD[Int] = sc.makeRDD(1 to 4, 2)// 3.2 调用map方法,每个元素乘以2val mapRdd: RDD[Int] = rdd.map(_ * 2)// 3.3 打印修改后的RDD中数据mapRdd.collect().foreach(println)//4.关闭连接sc.stop()}
}2.3.1.2 mappartitions()以分区为单位执行map
mappartitions算子
1、函数签名:
def mappartitions[u:classtag](
f:iterator[t]=>iterator[u]
preservespartitioning:boolean=false):rdd[u]
2、功能说明:map是一次处理一个元素,而mappartitions一次处理一个分区数据
3、需求说明:创建一个rdd,4个元素,2个分区,使每个元素*2组成新的rdd
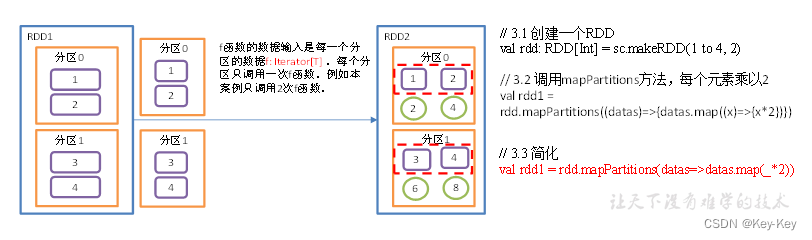
4、具体实现
object value02_mapPartitions {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc = new SparkContext(conf)//3具体业务逻辑// 3.1 创建一个RDDval rdd: RDD[Int] = sc.makeRDD(1 to 4, 2)// 3.2 调用mapPartitions方法,每个元素乘以2val rdd1 = rdd.mapPartitions(x=>x.map(_*2))// 3.3 打印修改后的RDD中数据rdd1.collect().foreach(println)// 将RDD中的一个分区作为几个集合 进行转换结构// 只是将一个分区一次性进行计算 最终还是修改单个元素的值// 可以将RDD中的元素个数减少 只需要保证一个集合对应一个输出集合即可val value: RDD[Int] = intRDD.mapPartitions(list => {println("mapPartition调用")// 对已经是集合的数据调用集合常用函数进行修改即可// 此处的map是集合常用函数list.filter(i => i % 2 == 0)})value.collect().foreach(println)//4.关闭连接sc.stop()}
}2.3.1.3 map()和mappartitions()区别
1、map():每次处理一条数据
2、mappartition():每次处理一个分区的数据,这个分区的数据处理完成后,原rdd中分区的数据才能释放,可能导致oom
3、开发经验:当内存空间较大的时候建议使用mappartition(),以提高效率
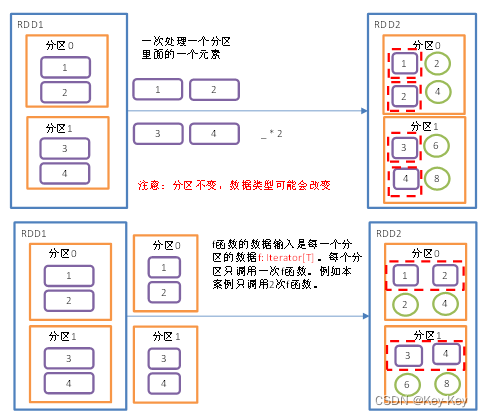
2.3.1.4 mappartitionswithindex()带分区号
1、函数签名

2、功能说明:类似mappartitions,比mappartitions多一个整数参数表示分区号
3、需求说明:创建一个rdd,使每个元素跟所在分区号形成一个元组,组成一个新的rdd
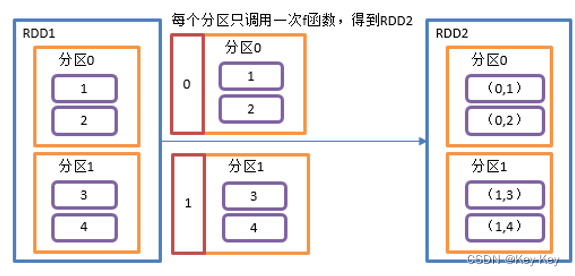
4、具体实现
object value03_mapPartitionsWithIndex {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc = new SparkContext(conf)//3具体业务逻辑// 3.1 创建一个RDDval rdd: RDD[Int] = sc.makeRDD(1 to 4, 2)// 3.2 创建一个RDD,使每个元素跟所在分区号形成一个元组,组成一个新的RDDval indexRdd = rdd.mapPartitionsWithIndex( (index,items)=>{items.map( (index,_) )} )// 3.3 打印修改后的RDD中数据indexRdd.collect().foreach(println)//4.关闭连接sc.stop()}
}2.3.1.5 flatmap()扁平化
1、函数签名
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]
2、功能说明
与map操作类似,将rdd中的每一个元素通过应用f函数依次转换为新的元素,并封装到rdd中。
区别:在flatmap操作中,f函数的返回值是一个集合,并且会将每一个该集合中的元素拆分出来放到新的rdd中。
3、需求说明:创建一个集合,集合里面存储的还是子集合,把所有子集合中数据取出放入到一个大的集合中。
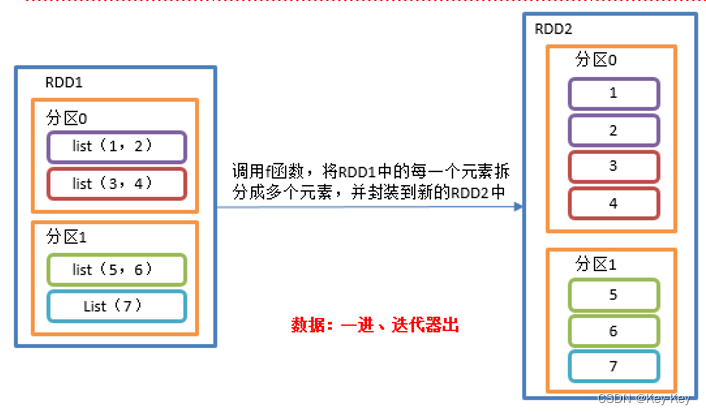
4、具体实现
object value04_flatMap {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc = new SparkContext(conf)//3具体业务逻辑// 3.1 创建一个RDDval listRDD=sc.makeRDD(List(List(1,2),List(3,4),List(5,6),List(7)), 2)// 3.2 把所有子集合中数据取出放入到一个大的集合中listRDD.flatMap(list=>list).collect.foreach(println)//4.关闭连接sc.stop()}
}2.3.1.6 groupby()分组
groupby算子
1、函数签名
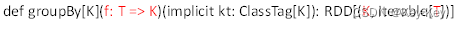
2、功能说明
分组,按照传入函数的返回值进行分组。将相同的key对应的值放入到一个迭代器。
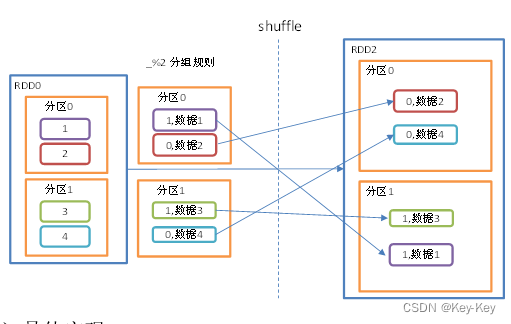
3、需求说明
创建一个rdd,按照元素模以2的值进行分组
4、具体实现
object value05_groupby {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc = new SparkContext(conf)//3具体业务逻辑// 3.1 创建一个RDDval rdd = sc.makeRDD(1 to 4, 2)// 3.2 将每个分区的数据放到一个数组并收集到Driver端打印rdd.groupBy(_ % 2).collect().foreach(println)// 3.3 创建一个RDDval rdd1: RDD[String] = sc.makeRDD(List("hello","hive","hadoop","spark","scala"))// 3.4 按照首字母第一个单词相同分组rdd1.groupBy(str=>str.substring(0,1)).collect().foreach(println)sc.stop()}
}groupby会存在shuffle过程
shuffle:将同步的分区数据进行打乱重组的过程
shuffle一定会落盘。可以在local模式下执行程序,通过4040看效果
2.3.1.7 filter()过滤
1、函数签名
def filter(f: T => Boolean): RDD[T]
2、功能说明
接收一个返回值为布尔类型的函数作为参数。当某个rdd调用filter方法时,会对该rdd中每一个元素应用f函数,如果返回值类型为true,则该元素会被添加到新的rdd中。
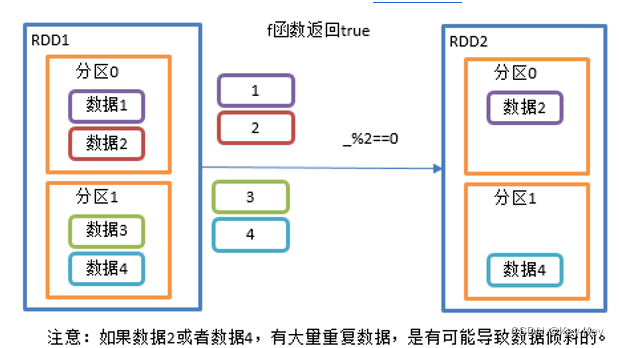
3、需求说明
创建一个rdd,过滤出对2取余等于0的数据
4、代码实现
def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3.创建一个RDDval rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4), 2)//3.1 过滤出符合条件的数据val filterRdd: RDD[Int] = rdd.filter(_ % 2 == 0)//3.2 收集并打印数据filterRdd.collect().foreach(println)//4 关闭连接sc.stop()}
}2.3.1.8 distinct()去重
distinct算子
1、函数签名
2、功能说明
对内部的元素去重,并将去重后的元素放到新的rdd中
3、源码解析
用分布式的方法去重比hashset集合方式不容易oom

4、函数签名
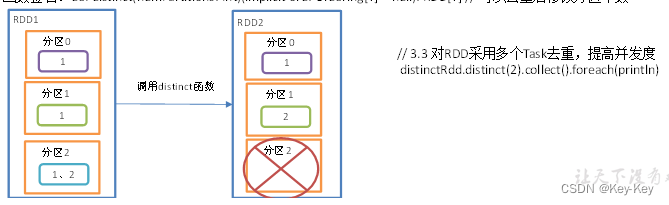
5、代码实现
object value07_distinct {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑// 3.1 创建一个RDDval distinctRdd: RDD[Int] = sc.makeRDD(List(1,2,1,5,2,9,6,1))// 3.2 打印去重后生成的新RDDdistinctRdd.distinct().collect().foreach(println)// 3.3 对RDD采用多个Task去重,提高并发度distinctRdd.distinct(2).collect().foreach(println)//4.关闭连接sc.stop()}
}注意:distinct会存在shuffle过程
2.3.1.9 coalesce()合并分区
coalesce算子包括:配置执行shuffle和配置不执行shuffle两种方式
1、不执行shuffle方式
1)函数签名
def coalesce(numPartitions: Int, shuffle: Boolean = false, //默认false不执行shufflepartitionCoalescer: Option[PartitionCoalescer] = Option.empty)(implicit ord: Ordering[T] = null) : RDD[T]2)功能说明
缩减分区数,用于大数据集过滤后,提高小数据集的执行效率
3)需求
4个分区合并为两个分区

4)代码实现
object value08_coalesce {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3.创建一个RDD//val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4), 4)//3.1 缩减分区//val coalesceRdd: RDD[Int] = rdd.coalesce(2)//4. 创建一个RDDval rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5, 6), 3)//4.1 缩减分区val coalesceRDD: RDD[Int] = rdd.coalesce(2)//5 查看对应分区数据val indexRDD: RDD[(Int, Int)] = coalesceRDD.mapPartitionsWithIndex((index, datas) => {datas.map((index, _))})//6 打印数据indexRDD.collect().foreach(println)//8 延迟一段时间,观察http://localhost:4040页面,查看Shuffle读写数据
Thread.sleep(100000)//7.关闭连接sc.stop()}
}2、执行shuffle方式
//3. 创建一个RDD
val rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5, 6), 3)
//3.1 执行shuffle
val coalesceRdd: RDD[Int] = rdd.coalesce(2, true)输出结果
(0,1)
(0,4)
(0,5)
(1,2)
(1,3)
(1,6) 2.3.1.10 repartition()重新分区(执行shuffle)
1、函数签名
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
2、功能说明
该操作内部其实执行的是coalesce操作,参数shuffle的默认值是true。无论是将分区数多的rdd转换为分区数少的rdd,还是将分区数少的erdd转换为分区数多的rdd,repartition操作都可以完成,因为无论如何都会经shuffle过程。分区规则不是hash,因为平时使用的分区都是按照hash来实现的,repartition一般是对hash的结果不满意,想要打散重新分区。
3、需求
创建一个4个分区的rdd,对其重新分区
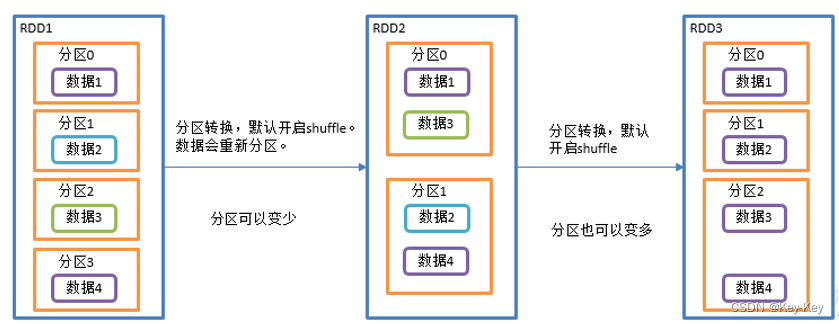
4、代码实现
object value09_repartition {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3. 创建一个RDDval rdd: RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5, 6), 3)//3.1 缩减分区//val coalesceRdd: RDD[Int] = rdd.coalesce(2, true)//3.2 重新分区val repartitionRdd: RDD[Int] = rdd.repartition(2)//4 打印查看对应分区数据val indexRdd: RDD[(Int, Int)] = repartitionRdd.mapPartitionsWithIndex((index, datas) => {datas.map((index, _))})//5 打印indexRdd.collect().foreach(println)//6. 关闭连接sc.stop()}
}2.3.1.11 coalesce和repartition区别
1、coalesce重新分区,可以选择是否进行shuffle过程。由参数shuffle:boolean=false/true决定。
2、repartition实际上是调用的coalesce,进行shuffle。源码如下
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {coalesce(numPartitions, shuffle = true)
}3、coalesce一般为缩减分区,如果扩大分区,不使用shuffle是没有意义的,repartition扩大分区执行shuffle
2.3.1.12 sortby()排序
1、函数签名
def sortBy[K]( f: (T) => K,ascending: Boolean = true, // 默认为正序排列numPartitions: Int = this.partitions.length)(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]2、功能说明
该操作用于排序数据。在排序之前,可以将数据通过f函数进行处理,之后按照f函数处理的结果进行排序,默认为正序排序。排序后新产生的rdd的分区数与原rdd的分区数一致。
3、需求
创建一个rdd,按照数字大小分别实现正序和倒叙排序

4、代码实现
object value10_sortBy {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑// 3.1 创建一个RDDval rdd: RDD[Int] = sc.makeRDD(List(2, 1, 3, 4, 6, 5))// 3.2 默认是升序排val sortRdd: RDD[Int] = rdd.sortBy(num => num)sortRdd.collect().foreach(println)// 3.3 配置为倒序排val sortRdd2: RDD[Int] = rdd.sortBy(num => num, false)sortRdd2.collect().foreach(println)// 3.4 创建一个RDDval strRdd: RDD[String] = sc.makeRDD(List("1", "22", "12", "2", "3"))// 3.5 按照字符的int值排序strRdd.sortBy(num => num.toInt).collect().foreach(println)// 3.5 创建一个RDDval rdd3: RDD[(Int, Int)] = sc.makeRDD(List((2, 1), (1, 2), (1, 1), (2, 2)))// 3.6 先按照tuple的第一个值排序,相等再按照第2个值排rdd3.sortBy(t=>t).collect().foreach(println)//4.关闭连接sc.stop()}
}2.3.2 双value类型交互
1、创建包名:com.atguigu.doublevalue
2.3.2.1 intersection()交集
1、函数签名
def intersection(other: RDD[T]): RDD[T]
2、功能说明
对源rdd和参数rdd求交集后返回一个新的rdd
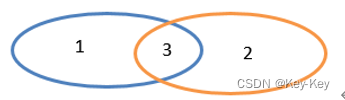
交集:只有3
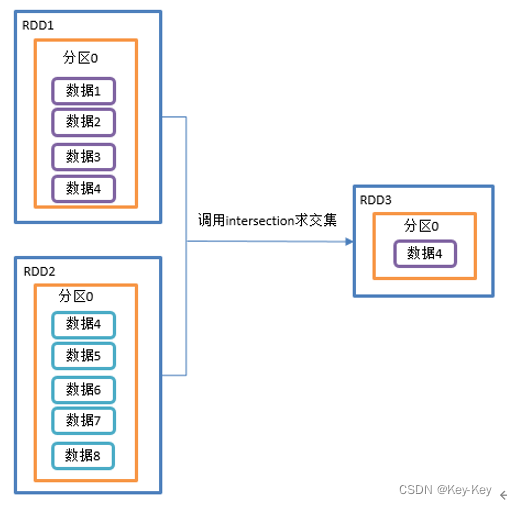
3、需求
创建两个rdd,求两个rdd的交集
4、代码实现
object DoubleValue01_intersection {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd1: RDD[Int] = sc.makeRDD(1 to 4)//3.2 创建第二个RDDval rdd2: RDD[Int] = sc.makeRDD(4 to 8)//3.3 计算第一个RDD与第二个RDD的交集并打印// 利用shuffle的原理进行求交集 需要将所有的数据落盘shuffle 效率很低 不推荐使用rdd1.intersection(rdd2).collect().foreach(println)//4.关闭连接sc.stop()}
}2.3.2.2 union()并集不去重
1、函数签名
def union(other: RDD[T]): RDD[T]
2、功能说明
对源rdd和参数rdd求并集后返回一个新的rdd

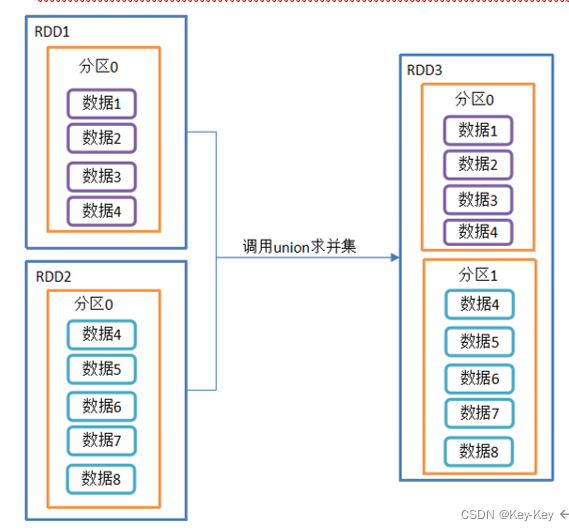
并集:1、2、3全包括
3、需求
创建两个rdd,求并集
4、代码实现
object DoubleValue02_union {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd1: RDD[Int] = sc.makeRDD(1 to 4)//3.2 创建第二个RDDval rdd2: RDD[Int] = sc.makeRDD(4 to 8)//3.3 计算两个RDD的并集// 将原先的RDD的分区和数据都保持不变 简单的将多个分区合并在一起 放到一个RDD中// 由于不走shuffle 效率高 所有会使用到rdd1.union(rdd2).collect().foreach(println)//4.关闭连接sc.stop()}
}2.3.2.3 subtract()差集
1、函数签名
def subtract(other: RDD[T]): RDD[T]
2、功能说明
计算差的一种函数,去除两个rdd中相同元素,不同的rdd将保留下来
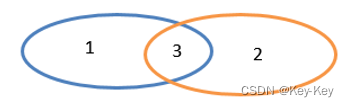
差集:只有1
3、需求说明:创建两个rdd,求第一个rdd与第二个rdd的差集

4、代码实现
object DoubleValue03_subtract {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd: RDD[Int] = sc.makeRDD(1 to 4)//3.2 创建第二个RDDval rdd1: RDD[Int] = sc.makeRDD(4 to 8)//3.3 计算第一个RDD与第二个RDD的差集并打印// 同样使用shuffle的原理 将两个RDD的数据写入到相同的位置 进行求差集// 需要走shuffle 效率低 不推荐使用rdd.subtract(rdd1).collect().foreach(println)//4.关闭连接sc.stop()}
}2.3.2.4 zip()拉链
1、函数签名
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]
2、功能说明
该操作可以将两个rdd中的元素,以键值对的形式进行合并。其中,键值对中的key为第1个rdd中的元素,value为第2个rdd中的元素。
将两个rdd组合成key/value形式的rdd,这里默认两个rdd的partition数量以及元素数量都相同,否则会抛出异常。
3、需求说明
创建两个rdd,并将两个rdd组合到一起形成一个(k,v)rdd
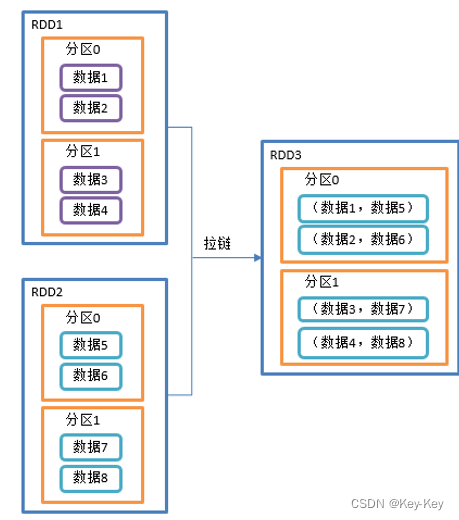
4、代码实现
object DoubleValue04_zip {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd1: RDD[Int] = sc.makeRDD(Array(1,2,3),3)//3.2 创建第二个RDDval rdd2: RDD[String] = sc.makeRDD(Array("a","b","c"),3)//3.3 第一个RDD组合第二个RDD并打印rdd1.zip(rdd2).collect().foreach(println)//3.4 第二个RDD组合第一个RDD并打印rdd2.zip(rdd1).collect().foreach(println)//3.5 创建第三个RDD(与1,2分区数不同)val rdd3: RDD[String] = sc.makeRDD(Array("a","b"), 3)//3.6 元素个数不同,不能拉链// Can only zip RDDs with same number of elements in each partitionrdd1.zip(rdd3).collect().foreach(println)//3.7 创建第四个RDD(与1,2分区数不同)val rdd4: RDD[String] = sc.makeRDD(Array("a","b","c"), 2)//3.8 分区数不同,不能拉链// Can't zip RDDs with unequal numbers of partitions: List(3, 2)rdd1.zip(rdd4).collect().foreach(println)//4.关闭连接sc.stop()}
}2.3.3 key-value类型
1、创建包名:com.atguigu.keyvalue
2.3.3.1 partitionby()按照k重新分区
1、函数签名
def partitionBy(partitioner: Partitioner): RDD[(K, V)]
2、功能说明
将rdd[k,v]中的k按照指定partitioner重新进行分区;
如果原有的rdd和新的rdd是一致的话就不进行分区,否则会产生shuffle过程。
3、需求说明
创建一个3个分区的rdd,对其重新分区
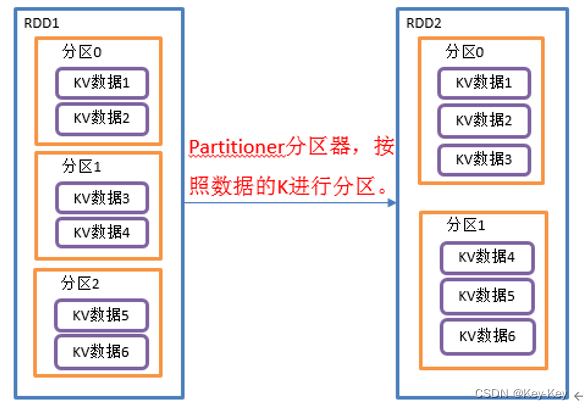
4、代码实现:
object KeyValue01_partitionBy {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd: RDD[(Int, String)] = sc.makeRDD(Array((1,"aaa"),(2,"bbb"),(3,"ccc")),3)//3.2 对RDD重新分区val rdd2: RDD[(Int, String)] = rdd.partitionBy(new org.apache.spark.HashPartitioner(2))//3.3 打印查看对应分区数据 (0,(2,bbb)) (1,(1,aaa)) (1,(3,ccc))val indexRdd = rdd2.mapPartitionsWithIndex((index, datas) => datas.map((index,_)))indexRdd.collect().foreach(println)//4.关闭连接sc.stop()}
}2.3.3.2 自定义分区
1、hashpartitioner源码解读
class HashPartitioner(partitions: Int) extends Partitioner {require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")def numPartitions: Int = partitionsdef getPartition(key: Any): Int = key match {case null => 0case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)}override def equals(other: Any): Boolean = other match {case h: HashPartitioner =>h.numPartitions == numPartitionscase _ =>false}override def hashCode: Int = numPartitions
}2、自定义分区器
要实现自定义分区器,需要继承org.apache.spark.partitioner类,并实现下面三个方法。
1)numpartitions:int:返回创建出来的分区数
2)getpartition(key:any):int:返回给定键的分区编号(0到numpartitions-1)
3)equals():java判断相等性的标准方法。这个方法的实现非常重要,spark需要用这个方法来检查你的分区器对象是否和其它分区器实例相同,这样spark才可以判断两个rdd的分区方式是否相同
object KeyValue01_partitionBy {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "aaa"), (2, "bbb"), (3, "ccc")), 3)//3.2 自定义分区val rdd3: RDD[(Int, String)] = rdd.partitionBy(new MyPartitioner(2))//4 打印查看对应分区数据rdd3.mapPartitionsWithIndex((index,list) => list.map((index,_))).collect().foreach(println)//5.关闭连接sc.stop()}
}// 自定义分区
class MyPartitioner(num: Int) extends Partitioner {// 设置的分区数override def numPartitions: Int = num// 具体分区逻辑// 根据传入数据的key 输出目标的分区号// spark中能否根据value进行分区 => 不能 只能根据key进行分区override def getPartition(key: Any): Int = {// 使用模式匹配 对类型进行推断// 如果是字符串 放入到0号分区 如果是整数 取模分区个数key match {case s:String => 0case i:Int => i % numPartitionscase _ => 0}}}2.3.3.3 groupbykey()按照k重新分组
1、函数签名
def groupByKey(): RDD[(K, Iterable[V])]
2、功能说明
groupbykey对每个key进行操作,但只生成一个seq,并不进行聚合。
该操作可以指定分区器或者分区数(默认使用hashpartitioner)
3、需求说明
统计单词出现次数

4、代码实现
object KeyValue03_groupByKey {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd = sc.makeRDD(List(("a",1),("b",5),("a",5),("b",2)))//3.2 将相同key对应值聚合到一个Seq中val group: RDD[(String, Iterable[Int])] = rdd.groupByKey()//3.3 打印结果group.collect().foreach(println)//3.4 计算相同key对应值的相加结果group.map(t=>(t._1,t._2.sum)).collect().foreach(println)//4.关闭连接sc.stop()}
}2.3.3.4 reducebykey()按照k聚合v
1、函数签名
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]2、功能说明:该操作可以将rdd[k,v]中的元素按照相同的k对v进行聚合。其存在多种重载形式,还可以设置新的rdd的分区数。
3、需求说明:统计单词出现次数
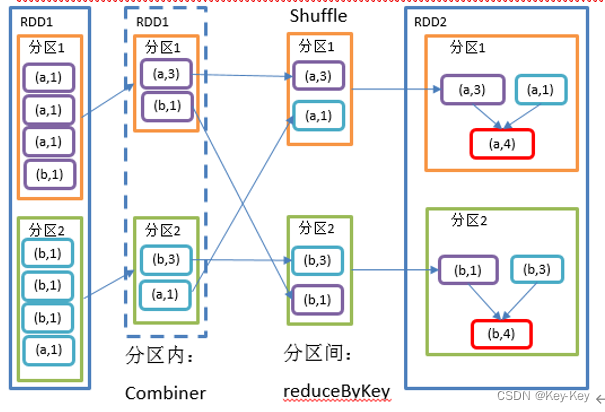
4、代码实现
object KeyValue02_reduceByKey {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd = sc.makeRDD(List(("a",1),("b",5),("a",5),("b",2)))//3.2 计算相同key对应值的相加结果val reduce: RDD[(String, Int)] = rdd.reduceByKey((v1,v2) => v1+v2)//3.3 打印结果reduce.collect().foreach(println)//4.关闭连接sc.stop()}
}2.3.3.5 reducebykey和groupbykey区别
1、reducebykey
按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是rdd[k,v]。
2、groupbykey
按照key进行分组,直接进行shuffle。
3、开发指导
在不影响业务逻辑的前提下,优先选择reducebykey。求和操作不影响业务逻辑,求平均值影响业务逻辑,后续会学习功能更加强大的规约算子,能够在预聚合的情况下实现求平均值。
2.3.3.6 aggregatebykey()分区内和分区间逻辑不同的规约
aggregatebykey算子
1、函数签名
1)zerovalue(初始值):给每一个分区中的每一种key一个初始值
2)seqop(分区内):函数用于在每一个分区中用初始值逐步迭代value
3)combop(分区间):函数用于合并每个分区中的结果

2、代码实现
object KeyValue04_aggregateByKey {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd: RDD[(String, Int)] = sc.makeRDD(List(("a",1),("a",3),("a",5),("b",7),("b",2),("b",4),("b",6),("a",7)), 2)//3.2 取出每个分区相同key对应值的最大值,然后相加rdd.aggregateByKey(0)(math.max(_, _), _ + _).collect().foreach(println)//4.关闭连接sc.stop()}
}2.3.3.7 sortbykey()按照k进行排序
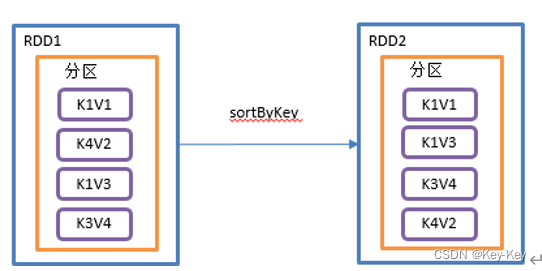
1、函数签名
def sortByKey(ascending: Boolean = true, // 默认,升序numPartitions: Int = self.partitions.length) : RDD[(K, V)]2、功能说明
在一个(k,v)的rdd上调用,k必须实现ordered接口,返回一个按照key进行排序的(k,v)的rdd。
3、需求说明
创建一个pairrdd,按照key的正序和倒叙进行排序
4、代码实现:
object KeyValue07_sortByKey {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd: RDD[(Int, String)] = sc.makeRDD(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))//3.2 按照key的正序(默认顺序)rdd.sortByKey(true).collect().foreach(println)//3.3 按照key的倒序rdd.sortByKey(false).collect().foreach(println)// 只会按照key来排序 最终的结果是key有序 value不会排序// spark的排序是全局有序 不会进行hash shuffle处理// 使用range分区器// new RangePartitioner(numPartitions, self, ascending)//4.关闭连接sc.stop()}
}2.3.3.8 mapvalues()只对v进行操作
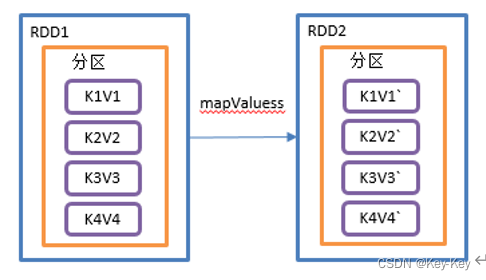
1、函数签名
def mapValues[U](f: V => U): RDD[(K, U)]
2、功能说明
针对(k,v)形式的类型只对v进行操作
3、需求说明
创建一个pairrdd,并将value添加字符串"|||"
4、代码实现
object KeyValue08_mapValues {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (1, "d"), (2, "b"), (3, "c")))//3.2 对value添加字符串"|||"rdd.mapValues(_ + "|||").collect().foreach(println)//4.关闭连接sc.stop()}
}2.3.3.9 join()等同于sql里的内连接,关联上的要,关联补上的舍弃
1、函数签名
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, W))] 2、功能说明
在类型为(k,v)和(k,w)的rdd上调用,返回一个相同key对应的所有元素对在一起的(k,(v,w))的rdd
3、需求说明
创建两个pairrdd,并将key相同的数据聚合到一个元组
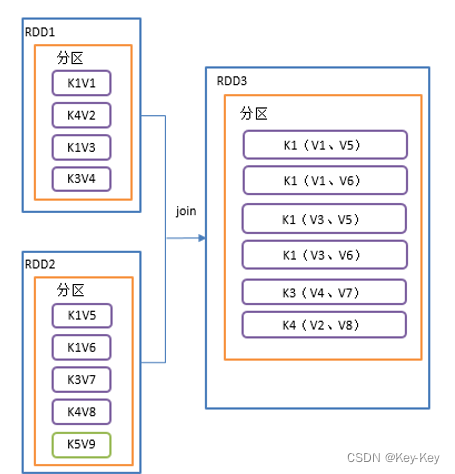
注意:如果key只是某一个rdd有,这个key不会关联
4、代码实现
object KeyValue09_join {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))//3.2 创建第二个pairRDDval rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 5), (4, 6)))//3.3 join操作并打印结果rdd.join(rdd1).collect().foreach(println)//4.关闭连接sc.stop()}
}2.3.3.10 cogroup()类似于sql的全连接,但是在同一个rdd中对key聚合
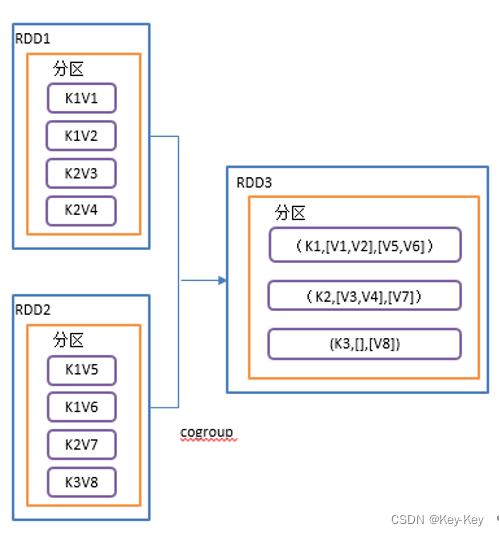
1、函数签名
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]
2、功能说明
在类型为(k,v)和(k,w)的rdd上调用,返回(k,(iterable,iterable))类型的rdd。
操作两个rdd中的kv元素,每个rdd中相同的key中的元素分别聚合成一个集合。
3、需求说明
创建两个pairrdd,并将key相同的数据聚合到一个迭代器
4、代码实现
object KeyValue10_cogroup {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd: RDD[(Int, String)] = sc.makeRDD(Array((1,"a"),(2,"b"),(3,"c")))//3.2 创建第二个RDDval rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1,4),(2,5),(4,6)))//3.3 cogroup两个RDD并打印结果
// (1,(CompactBuffer(a),CompactBuffer(4)))
// (2,(CompactBuffer(b),CompactBuffer(5)))
// (3,(CompactBuffer(c),CompactBuffer()))
// (4,(CompactBuffer(),CompactBuffer(6)))rdd.cogroup(rdd1).collect().foreach(println)//4.关闭连接sc.stop()}
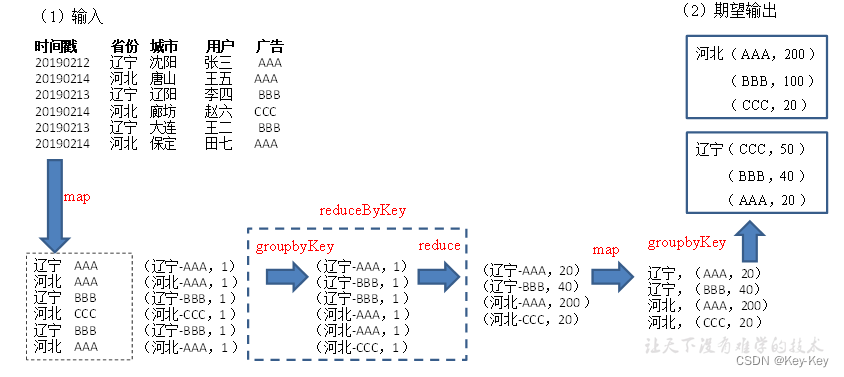
}2.3.4 案例实操(省份广告被点击top3)
1、数据准备:时间戳,省份,城市,用户,广告,中间字段使用空格分割。

2、需求:统计出每一个省份广告被点击次数的top3
3、需求分析:
4、实现过程
object Test01_DemoTop3 {def main(args: Array[String]): Unit = {// 1. 创建配置对象val conf: SparkConf = new SparkConf().setAppName("coreTest").setMaster("local[*]")// 2. 创建scval sc = new SparkContext(conf)// 3. 编写代码 执行操作val lineRDD: RDD[String] = sc.textFile("input/agent.log")// 步骤一: 过滤出需要的数据val tupleRDD: RDD[(String, String)] = lineRDD.map(line => {val data: Array[String] = line.split(" ")(data(1), data(4))})// 将一行的数据转换为(省份,广告)// tupleRDD.collect().foreach(println)// 步骤二: 对省份加广告进行wordCount 统计val provinceCountRDD: RDD[((String, String), Int)] = tupleRDD.map((_, 1)).reduceByKey(_ + _)// 一步进行过滤数据加wordCountval tupleRDD1: RDD[((String, String), Int)] = lineRDD.map(line => {val data: Array[String] = line.split(" ")((data(1), data(4)), 1)})val provinceCountRDD1: RDD[((String, String), Int)] = tupleRDD1.reduceByKey(_ + _)// 统计单个省份单条广告点击的次数 ((省份,广告id),count次数)// provinceCountRDD.collect().foreach(println)// 步骤三:分省份进行聚合// ((省份,广告id),count次数)// 使用groupBY的方法 数据在后面会有省份的冗余// val provinceRDD: RDD[(String, Iterable[((String, String), Int)])] = provinceCountRDD1.groupBy(tuple => tuple._1._1)// provinceRDD.collect().foreach(println)// 推荐使用groupByKey => 前面已经聚合过了// ((省份,广告id),count次数) => (省份,(广告id,count次数))// 使用匿名函数的写法val value: RDD[(String, (String, Int))] = provinceCountRDD1.map(tuple =>(tuple._1._1, (tuple._1._2, tuple._2)))// 偏函数的写法provinceCountRDD1.map({case ((province,id),count) => (province,(id,count))})val provinceRDD1: RDD[(String, Iterable[(String, Int)])] = value.groupByKey()// (省份,(广告id,count次数)) => (省份,List((广告1,次数),(广告2,次数),(广告3,次数)))// provinceRDD1.collect().foreach(println)//步骤四: 对单个二元组中的value值排序取top3// 相当于只需要对value进行处理val result: RDD[(String, List[(String, Int)])] = provinceRDD1.mapValues(it => {// 将list中的广告加次数排序取top3即可val list1: List[(String, Int)] = it.toList// 此处调用的sort是集合常用函数// 对rdd调用的是算子 对list调用的是集合常用函数list1.sortWith(_._2 > _._2).take(3)})result.collect().foreach(println)Thread.sleep(60000)// 4. 关闭scsc.stop()}
}2.4 action行动算子
行动算子是触发了整个作业的执行。因为转换算子都是懒加载,并不会立即执行。
1、创建包名:com.atguigu.action
2.4.1 collect()以数组的形式返回数据集
1、函数签名
def collect(): Array[T]
2、功能说明
在驱动程序中,以数组array的形式返回数据集的所有元素
注意:所有的数据都会被拉取到driver端,慎用。
3、需求说明
创建一个rdd,并将rdd内存收集到driver端打印
object action01_collect {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))//3.2 收集数据到Driverrdd.collect().foreach(println)//4.关闭连接sc.stop()}
}2.4.2 count()返回rdd中元素个数
1、函数签名
def count(): Long
2、功能说明:返回rdd中元素的个数
3、需求说明:创建一个rdd,统计该rdd的条数
object action02_count {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))//3.2 返回RDD中元素的个数val countResult: Long = rdd.count()println(countResult)//4.关闭连接sc.stop()}
}2.4.3 first()返回rdd中的第一个元素
1、函数签名
def first(): T
2、功能说明
返回rdd中的第一个元素
3、需求说明
创建一个rdd,返回该rdd中的第一个元素
object action03_first {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))//3.2 返回RDD中元素的个数val firstResult: Int = rdd.first()println(firstResult)//4.关闭连接sc.stop()}
}2.4.4 take()返回由rdd前n个元素组成的数组
1、函数签名
def take(num: Int): Array[T]
2、功能说明
返回一个由rdd的前n个元素组成的数组

3、需求说明:创建一个rdd,取出前两个元素
object action04_take {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))//3.2 返回RDD中前2个元素val takeResult: Array[Int] = rdd.take(2)println(takeResult.mkString(","))//4.关闭连接sc.stop()}
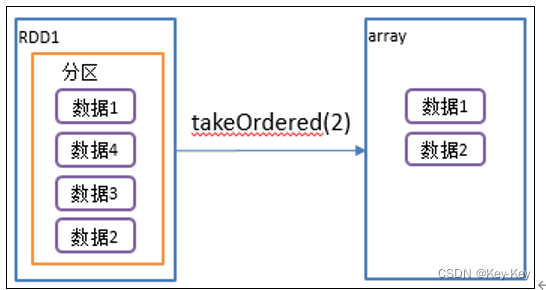
}2.4.5 takeordered()返回该rdd排序后前n个元素组成的数组
1、函数签名
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]
2、功能说明
返回该rdd排序后的前n个元素组成的数组
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T] = withScope {......if (mapRDDs.partitions.length == 0) {Array.empty} else {mapRDDs.reduce { (queue1, queue2) =>queue1 ++= queue2queue1}.toArray.sorted(ord)}
}3、需求说明
创建一个rdd,获取该rdd排序后的前两个数据
object action05_takeOrdered{def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd: RDD[Int] = sc.makeRDD(List(1,3,2,4))//3.2 返回RDD中排完序后的前两个元素val result: Array[Int] = rdd.takeOrdered(2)println(result.mkString(","))//4.关闭连接sc.stop()}
}2.4.6 countbykey()统计每种key的个数
1、函数签名
def countByKey(): Map[K, Long]
2、功能说明
统计每种key的个数
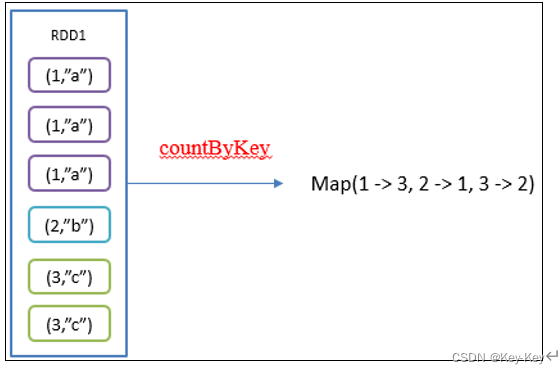
3、需求说明:创建一个pairrdd,统计每种key的个数
object action06_countByKey {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2, "b"), (3, "c"), (3, "c")))//3.2 统计每种key的个数val result: collection.Map[Int, Long] = rdd.countByKey()println(result)//4.关闭连接sc.stop()}
}2.4.7 save相关算子
1、saveastextfile(path)保存成text文件
1)函数签名
2)功能说明
将数据集的元素以textfile的形式保存到hdfs文件系统或者其它支持的文件系统,对于每个元素,spark将会调用tostring方法,将它转换为文件中的文本
2、saveassequencefile(path)
1)函数签名
2)功能说明
将数据集中的元素以hadoop sequencefile的格式保存到指定的目录下,可以使hdfs或者其它hadoop支持的文件系统。
注意:只有kv类型rdd有该操作,单值的没有。
3、saveasobjectfile(path)序列化成对象保存到文件
1)函数签名
2)功能说明
用于将rdd中的元素序列化成对象,存储到文件中。
4、代码实现
object action07_save {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDDval rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4), 2)//3.2 保存成Text文件rdd.saveAsTextFile("output")//3.3 序列化成对象保存到文件rdd.saveAsObjectFile("output1")//3.4 保存成Sequencefile文件rdd.map((_,1)).saveAsSequenceFile("output2")//4.关闭连接sc.stop()}
}2.4.8 foreach()遍历rdd中每一个元素
1、函数签名
2、功能说明
遍历rdd中的每一个元素,并依次应用f函数
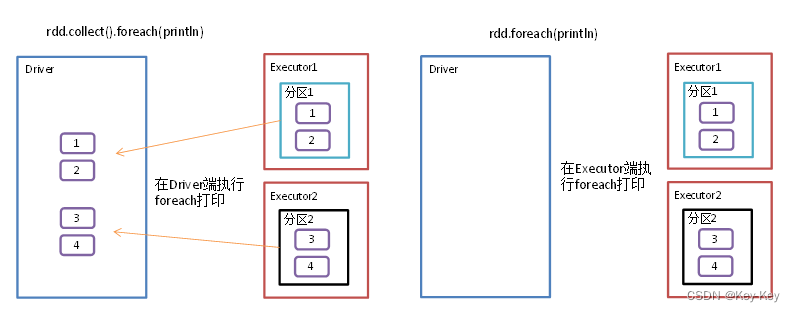
3、需求说明
创建一个rdd,对每个元素进行打印
object action08_foreach {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3具体业务逻辑//3.1 创建第一个RDD// val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),2)val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))//3.2 收集后打印rdd.collect().foreach(println)println("****************")//3.3 分布式打印rdd.foreach(println)//4.关闭连接sc.stop()}
}2.5 rdd序列化
在实际开发中我们往往需要自己定义一些对于rdd的操作,那么此时需要注意的是,初始化工作是在driver端进行的,而实际运行程序是在executor端进行的,这就涉及到了跨进程通信,是需要序列化的。下面我们看几个例子:

2.5.1 闭包检查
1、创建闭包
com.atguigu.serializable
2、闭包引入(有闭包就需要进行序列化)
object serializable01_object {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3.创建两个对象val user1 = new User()user1.name = "zhangsan"val user2 = new User()user2.name = "lisi"val userRDD1: RDD[User] = sc.makeRDD(List(user1, user2))//3.1 打印,ERROR报java.io.NotSerializableException//userRDD1.foreach(user => println(user.name))//3.2 打印,RIGHT (因为没有传对象到Executor端)val userRDD2: RDD[User] = sc.makeRDD(List())//userRDD2.foreach(user => println(user.name))//3.3 打印,ERROR Task not serializable
//注意:此段代码没执行就报错了,因为spark自带闭包检查userRDD2.foreach(user => println(user.name+" love "+user1.name))//4.关闭连接sc.stop()}
}//case class User() {
// var name: String = _
//}
class User extends Serializable {var name: String = _
}2.5.2 kryo序列化框架
参考地址:https://github.com/esotericsoftware/kryo
java的序列化能够序列化任何的类。但是比较重,序列化后对象的体积也比较大。
spark出于性能的考虑,spark2.0开始支持另外一种kryo序列化机制。kryo速度是serializable的10倍。当rdd在shuffle数据的时候,简单数据类型、数组和字符串类型已经在spark内部使用kryo来序列化。
object serializable02_Kryo {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("SerDemo").setMaster("local[*]")// 替换默认的序列化机制.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")// 注册需要使用kryo序列化的自定义类.registerKryoClasses(Array(classOf[Search]))val sc = new SparkContext(conf)val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello atguigu", "atguigu", "hahah"), 2)val search = new Search("hello")val result: RDD[String] = rdd.filter(search.isMatch)result.collect.foreach(println)
}// 关键字封装在一个类里面// 需要自己先让类实现序列化 之后才能替换使用kryo序列化class Search(val query: String) extends Serializable {def isMatch(s: String): Boolean = {s.contains(query)}}
}2.6 rdd依赖关系
2.6.1 查看血缘关系
rdd只支持粗粒度转换,即在大量记录上执行的单个操作。将创建rdd的一系列lineage(血统)记录下来,以便恢复丢失的分区。rdd的lineage会记录rdd的元数据信息和转换行为,当该rdd的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。

1、创建包名:com.atguigu.dependency
2、代码实现
object Lineage01 {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)val fileRDD: RDD[String] = sc.textFile("input/1.txt")println(fileRDD.toDebugString)println("----------------------")val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))println(wordRDD.toDebugString)println("----------------------")val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))println(mapRDD.toDebugString)println("----------------------")val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)println(resultRDD.toDebugString)resultRDD.collect()//4.关闭连接sc.stop()}
}3、打印结果
(2) input/1.txt MapPartitionsRDD[1] at textFile at Lineage01.scala:15 []| input/1.txt HadoopRDD[0] at textFile at Lineage01.scala:15 []
----------------------
(2) MapPartitionsRDD[2] at flatMap at Lineage01.scala:19 []| input/1.txt MapPartitionsRDD[1] at textFile at Lineage01.scala:15 []| input/1.txt HadoopRDD[0] at textFile at Lineage01.scala:15 []
----------------------
(2) MapPartitionsRDD[3] at map at Lineage01.scala:23 []| MapPartitionsRDD[2] at flatMap at Lineage01.scala:19 []| input/1.txt MapPartitionsRDD[1] at textFile at Lineage01.scala:15 []| input/1.txt HadoopRDD[0] at textFile at Lineage01.scala:15 []
----------------------
(2) ShuffledRDD[4] at reduceByKey at Lineage01.scala:27 []+-(2) MapPartitionsRDD[3] at map at Lineage01.scala:23 []| MapPartitionsRDD[2] at flatMap at Lineage01.scala:19 []| input/1.txt MapPartitionsRDD[1] at textFile at Lineage01.scala:15 []| input/1.txt HadoopRDD[0] at textFile at Lineage01.scala:15 []注意:圆括号中的数字表示rdd的并行度,也就是有几个分区
2.6.2 查看依赖关系
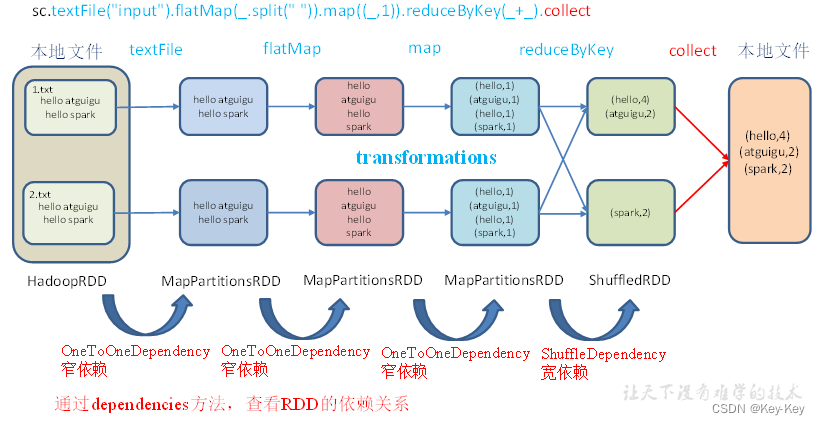
1、代码实现
object Lineage02 {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)val fileRDD: RDD[String] = sc.textFile("input/1.txt")println(fileRDD.dependencies)println("----------------------")val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))println(wordRDD.dependencies)println("----------------------")val mapRDD: RDD[(String, Int)] = wordRDD.map((_,1))println(mapRDD.dependencies)println("----------------------")val resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_+_)println(resultRDD.dependencies)resultRDD.collect()// 查看localhost:4040页面,观察DAG图
Thread.sleep(10000000)//4.关闭连接sc.stop()}
}2、打印结果
List(org.apache.spark.OneToOneDependency@f2ce6b)
----------------------
List(org.apache.spark.OneToOneDependency@692fd26)
----------------------
List(org.apache.spark.OneToOneDependency@627d8516)
----------------------
List(org.apache.spark.ShuffleDependency@a518813)3、全局搜索(ctrl+n)org.apache.spark.onetoonedependency
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {override def getParents(partitionId: Int): List[Int] = List(partitionId)
}注意:要想理解rdds是如何工作的,最重要的就是理解transformations
rdd之间的关系可以从两个维度来理解:一个是rdd是从哪些rdd转换而来,也就是rdd的parentrdd(s)是什么(血缘);另一个就是rdd依赖parentrdd(s)的哪些partition(s),这种关系就是rdd之间的依赖(依赖)。
rdd和它依赖的父rdd(s)的依赖关系有两种不同的类型,即窄依赖(narrowdepency)和宽依赖(shuffledependency)
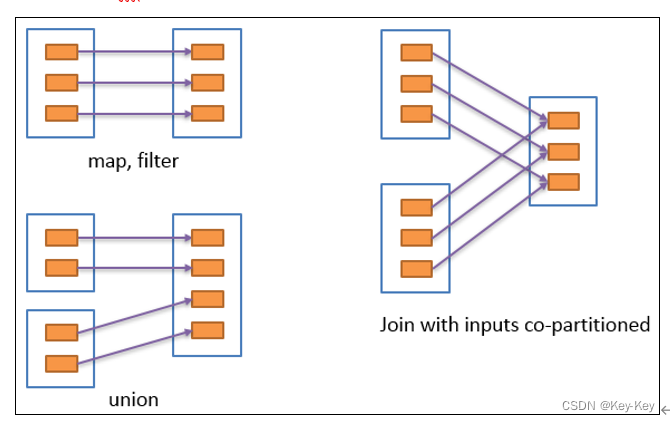
2.6.3 窄依赖
窄依赖表示每一个父rdd的partition最多被子rdd的一个partition使用(一对一 or 多对一),窄依赖我们形象的比喻为独生子女。
2.6.4 宽依赖
宽依赖表示同一个父rdd的partition被多个子rdd的partition依赖(只能是一对多),会引起shuffle,总结:宽依赖我们形象的比喻为超生。
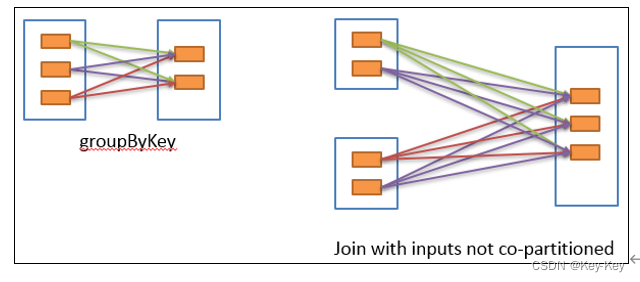
具有宽依赖的transformations包括:sort、reducebykey、groupbykey、join和调用repartition函数的任何操作。
宽依赖对spark去评估一个transformations有更加重要的影响,比如对性能的影响。在不影响业务要求的情况下,要尽量避免使用有宽依赖的转换算子,因为有宽依赖,就一定会走shuffle,影响性能。
2.6.5 stage任务划分
1、dag有向无环图
dag(directed acyclic graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。例如,dag记录了rdd的转换过程和任务的阶段。

2、任务运行的整体流程
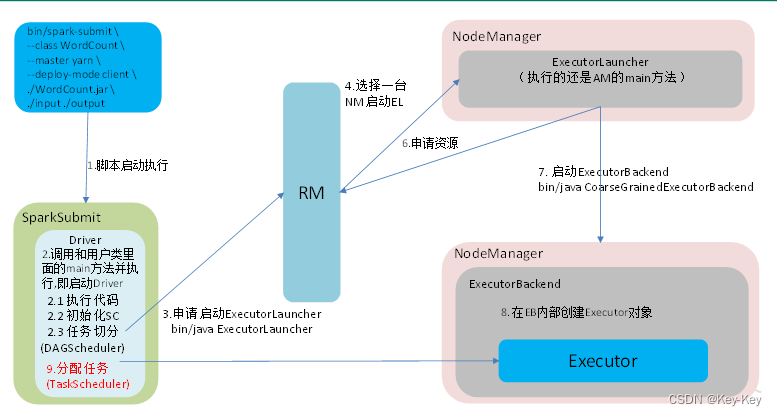
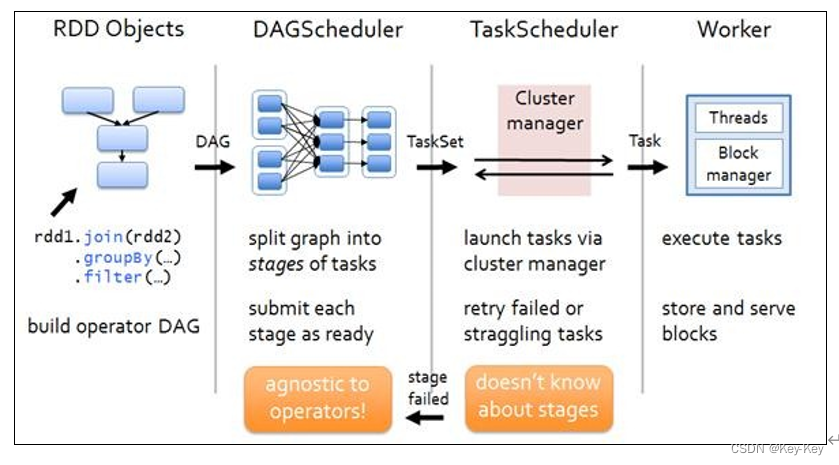
3、rdd任务切分中间分为:application、job、stage和task
1)application:初始化一个sparkcontext即生成一个application
2)job:一个action算子就会生成一个job
3)stage:stage等于宽依赖的个数加1
4)task:一个stage阶段中,最后一个rdd的分区个数就是task的个数
注意:application->job->stage-task每一层都是1对n的关系
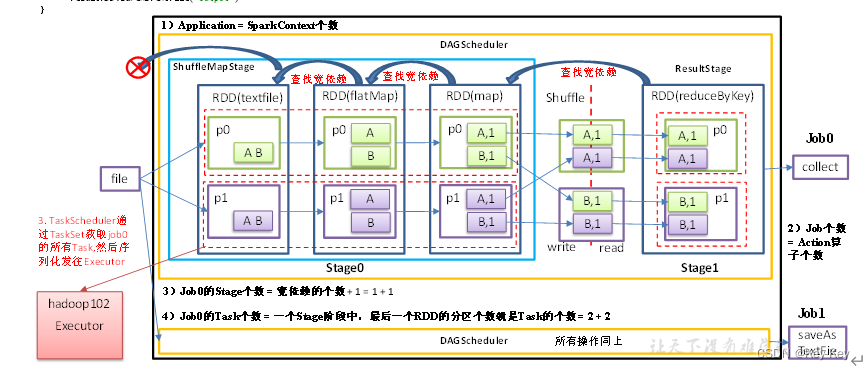
4、代码实现
object Lineage03 {def main(args: Array[String]): Unit = {//TODO 1 创建SparkConf配置文件,并设置App名称val conf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//TODO 2 利用SparkConf创建sc对象//Application:初始化一个SparkContext即生成一个Applicationval sc = new SparkContext(conf)//textFile,flatMap,map算子全部是窄依赖,不会增加stage阶段val lineRDD: RDD[String] = sc.textFile("D:\\IdeaProjects\\SparkCoreTest\\input\\1.txt")val flatMapRDD: RDD[String] = lineRDD.flatMap(_.split(" "))val mapRDD: RDD[(String, Int)] = flatMapRDD.map((_, 1))//reduceByKey算子会有宽依赖,stage阶段加1,2个stageval resultRDD: RDD[(String, Int)] = mapRDD.reduceByKey(_ + _)//Job:一个Action算子就会生成一个Job,2个Job//job0打印到控制台resultRDD.collect().foreach(println)//job1输出到磁盘resultRDD.saveAsTextFile("D:\\IdeaProjects\\SparkCoreTest\\out")//阻塞线程,方便进入localhost:4040查看Thread.sleep(Long.MaxValue)//TODO 3 关闭资源sc.stop()}
}5、查看Job个数
查看http://localhost:4040/jobs/,发现job有两个
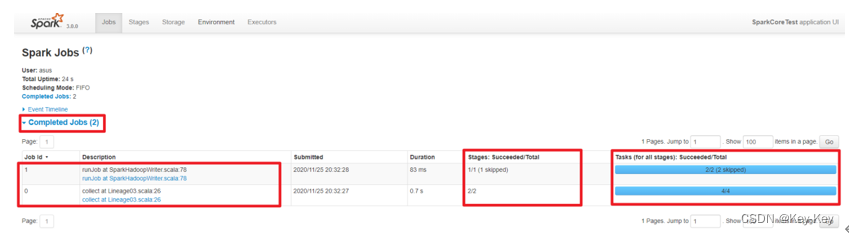
6、查看stage个数
查看job0的stage。由于只有1个shuffle阶段,所以stage个数为2
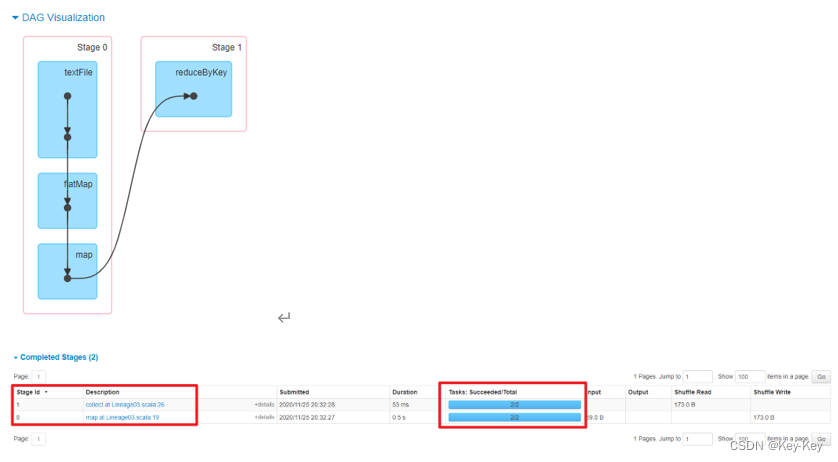
查看job1的stage。由于只有1个shuffle阶段,所以stage个数为2

7、task个数
查看job0的stage0的task个数,2个

查看job0的stage1的task个数,2个

查看job1的stage2的task个数,0个(2个跳过skipped)

查看job1的stage3的task个数,2个

注意:如果存在shuffle过程,系统会自动进行缓存,ui界面显示skipped的部分
2.7 rdd持久化
2.7.1 rdd cache缓存
rdd通过cache或者persist方法将前面的计算结果缓存,默认情况下会把数据以序列化的形式缓存在jvm的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的eaction算子时,该rdd将被缓存在计算节点的内存中,并供后面重用。

1、创建包名:com.atguigu.cache
2、代码实现
object cache01 {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3. 创建一个RDD,读取指定位置文件:hello atguigu atguiguval lineRdd: RDD[String] = sc.textFile("input1")//3.1.业务逻辑val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))val wordToOneRdd: RDD[(String, Int)] = wordRdd.map {word => {println("************")(word, 1)}}//3.5 cache缓存前打印血缘关系println(wordToOneRdd.toDebugString)//3.4 数据缓存。
//cache底层调用的就是persist方法,缓存级别默认用的是MEMORY_ONLYwordToOneRdd.cache()//3.6 persist方法可以更改存储级别// wordToOneRdd.persist(StorageLevel.MEMORY_AND_DISK_2)//3.2 触发执行逻辑wordToOneRdd.collect().foreach(println)//3.5 cache缓存后打印血缘关系
//cache操作会增加血缘关系,不改变原有的血缘关系println(wordToOneRdd.toDebugString)println("==================================")//3.3 再次触发执行逻辑wordToOneRdd.collect().foreach(println)Thread.sleep(1000000)//4.关闭连接sc.stop()}
}3、源码解析
mapRdd.cache()
def cache(): this.type = persist()
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)object StorageLevel {val NONE = new StorageLevel(false, false, false, false)val DISK_ONLY = new StorageLevel(true, false, false, false)val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)val MEMORY_ONLY = new StorageLevel(false, true, false, true)val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)val OFF_HEAP = new StorageLevel(true, true, true, false, 1)注意:默认的存储级别都是仅在内存存储一份。在存储级别的末尾加上"_2"表示持久化的数据存为两份。ser:表示序列化。
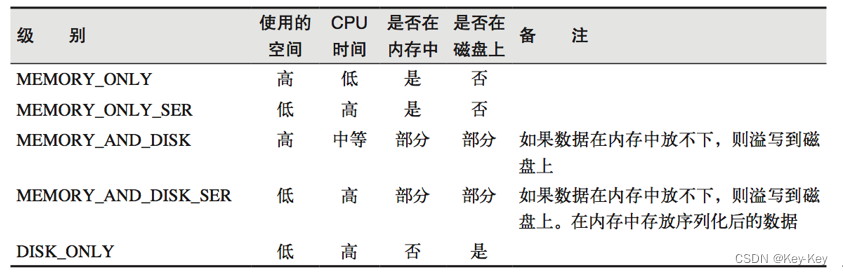
缓存有可能丢失,或者存储在内存的数据由于内存不足而被删除,rdd的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于rdd的一系列转换,丢失的数据会被重算,由于rdd的各个partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部partition。
4、自带缓存算子
spark会自动对一些shuffle操作的中间数据做持久化操作(比如:reducebykey)。这样做的目的是为了当一个节点shuffle失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用persist或cache。
object cache02 {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3. 创建一个RDD,读取指定位置文件:hello atguigu atguiguval lineRdd: RDD[String] = sc.textFile("input1")//3.1.业务逻辑val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))val wordToOneRdd: RDD[(String, Int)] = wordRdd.map {word => {println("************")(word, 1)}}// 采用reduceByKey,自带缓存val wordByKeyRDD: RDD[(String, Int)] = wordToOneRdd.reduceByKey(_+_)//3.5 cache操作会增加血缘关系,不改变原有的血缘关系println(wordByKeyRDD.toDebugString)//3.4 数据缓存。//wordByKeyRDD.cache()//3.2 触发执行逻辑wordByKeyRDD.collect()println("-----------------")println(wordByKeyRDD.toDebugString)//3.3 再次触发执行逻辑wordByKeyRDD.collect()Thread.sleep(1000000)//4.关闭连接sc.stop()}
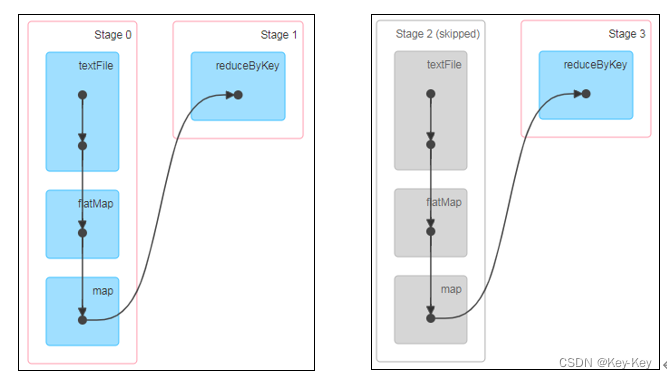
}访问http://localhost:4040/jobs/页面,查看第一个和第二个job的dag图。说明:增加缓存后血缘依赖关系仍然有,但是,第二个job取的数据是从缓存中取得。
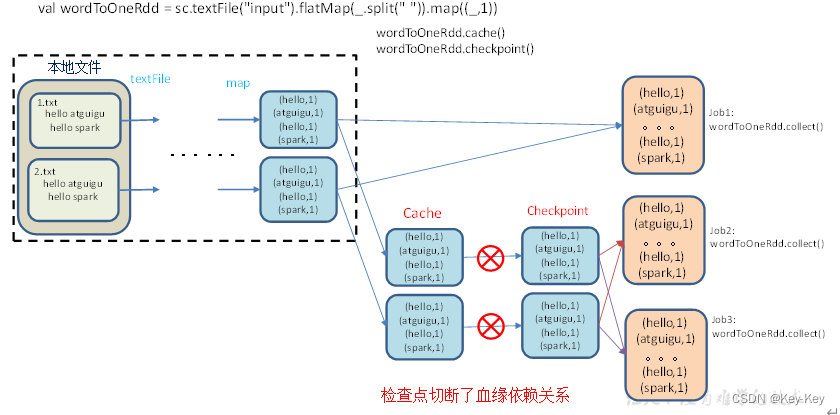
2.7.2 rdd checkpoint检查点
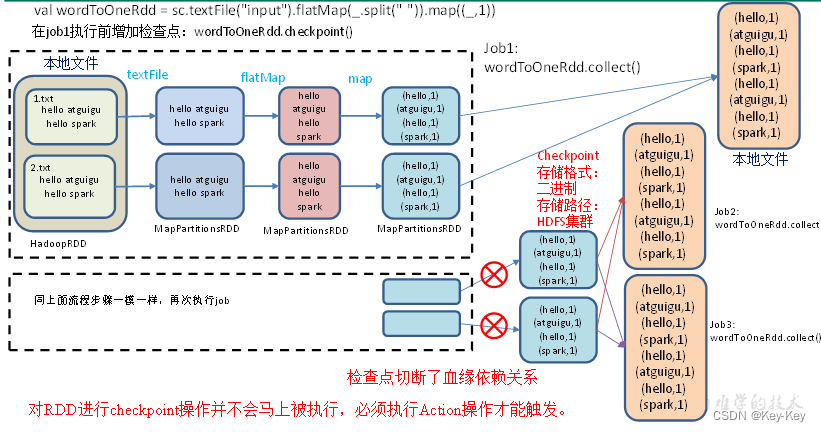
1、检查点:是通过将rdd中间结果写入磁盘。
2、为什么要做检查点?
由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。
3、检查点存储路径:checkpoint的数据通常是存储在hdfs等容错、高可用的文件系统
4、检查点数据存储格式为:二进制的文件
5、检查点切断血缘:在checkpoint的过程中,该rdd的所有依赖与父rdd中的信息将全部被溢出。
6、检查点触发事件:对rdd进行checkpoint操作并不会马上被执行,必须执行action操作才能触发。但是检查点为了数据安全,会从血缘关系的最开始执行一遍。
checkpoint检查点
7、设置检查点步骤
1)设置检查点数据存储路径:sc.setcheckpointdir(“./checkpoint1”)
2)调用检查点方法:wordtoonerdd.checkpoint()
8、代码实现
object checkpoint01 {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)// 需要设置路径,否则抛异常:Checkpoint directory has not been set in the SparkContextsc.setCheckpointDir("./checkpoint1")//3. 创建一个RDD,读取指定位置文件:hello atguigu atguiguval lineRdd: RDD[String] = sc.textFile("input1")//3.1.业务逻辑val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {word => {(word, System.currentTimeMillis())}}//3.5 增加缓存,避免再重新跑一个job做checkpoint
// wordToOneRdd.cache()//3.4 数据检查点:针对wordToOneRdd做检查点计算wordToOneRdd.checkpoint()//3.2 触发执行逻辑wordToOneRdd.collect().foreach(println)// 会立即启动一个新的job来专门的做checkpoint运算//3.3 再次触发执行逻辑wordToOneRdd.collect().foreach(println)wordToOneRdd.collect().foreach(println)Thread.sleep(10000000)//4.关闭连接sc.stop()}
}9、执行结果
访问http://localhost:4040/jobs/页面,查看4个job的dag图。其中第2个图是checkpoint的job运行dag图。第3、4张图说明,检查点切断了血缘依赖关系。
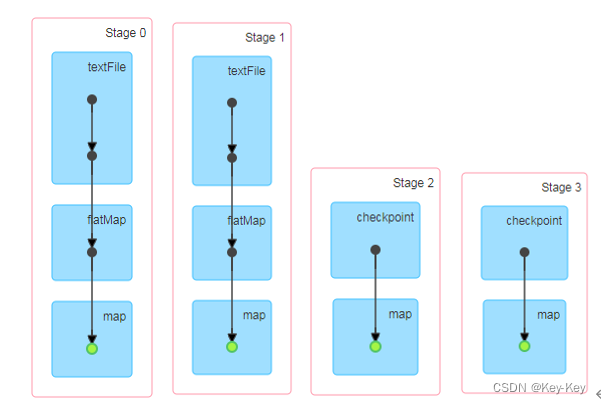
1)只增加checkpoint,没有增加cache缓存打印
第一个job执行完,触发了checkpoint,第2个job运行checkpoint,并把数据存储在检查点上。第3、4个job,数据从检查点上直接读取。

2)增加checkpoint,也增加cache缓存打印
第1个job执行完,数据就保存到Cache里面了,第2个job运行checkpoint,直接读cache里面的数据,并把数据存储在检查点上。第3、4个job,数据从检查点上直接读取。

checkpoint检查点+缓存
2.7.3 缓存和检查点区别
1、cache缓存只是将数据保存起来,不切断血缘依赖。checkpoint检查点切断血缘依赖。
2、cache缓存的数据通常存储在磁盘、内存等地方,可靠性低。checkpoint的数据通常存储在hdfs等容错、高可用的文件系统,可靠性高。
3、建议对checkpoint()的rdd使用cache缓存,这样checkpoint的job只需从cache缓存中读取数据即可,否则需要再从头计算一次rdd。
4、如果使用完了缓存,可用通过unpersist()方法释放缓存。
2.7.4 检查点存储到hdfs集群
如果检查点数据存储到hdfs集群,要注意配置访问集群的用户名。否则会报访问权限异常。
object checkpoint02 {def main(args: Array[String]): Unit = {// 设置访问HDFS集群的用户名System.setProperty("HADOOP_USER_NAME","atguigu")//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)// 需要设置路径.需要提前在HDFS集群上创建/checkpoint路径sc.setCheckpointDir("hdfs://hadoop102:8020/checkpoint")//3. 创建一个RDD,读取指定位置文件:hello atguigu atguiguval lineRdd: RDD[String] = sc.textFile("input1")//3.1.业务逻辑val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" "))val wordToOneRdd: RDD[(String, Long)] = wordRdd.map {word => {(word, System.currentTimeMillis())}}//3.4 增加缓存,避免再重新跑一个job做checkpointwordToOneRdd.cache()//3.3 数据检查点:针对wordToOneRdd做检查点计算wordToOneRdd.checkpoint()//3.2 触发执行逻辑wordToOneRdd.collect().foreach(println)//4.关闭连接sc.stop()}
}2.8 键值对rdd数据分区
spark目前支持hash分区、range分区和用户自定义分区。hash分区为当前的默认分区。分区器直接决定了rdd中分区的个数、rdd中每条数据经过shuffle后进入哪个分区和reduce的个数。
1、注意:
1)只有Key-value类型的rdd才有分区号,非key-value类型的rdd分区的值是none
2)每个rdd的分区id范围:0~numpartitions-1,决定这个值是属于哪个分区的
2、获取rdd分区
1)创建包名:com.atguigu.partitioner
2)代码实现
object partitioner01_get {def main(args: Array[String]): Unit = {//1.创建SparkConf并设置App名称val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")//2.创建SparkContext,该对象是提交Spark App的入口val sc: SparkContext = new SparkContext(conf)//3 创建RDDval pairRDD: RDD[(Int, Int)] = sc.makeRDD(List((1,1),(2,2),(3,3)))//3.1 打印分区器println(pairRDD.partitioner)//3.2 使用HashPartitioner对RDD进行重新分区val partitionRDD: RDD[(Int, Int)] = pairRDD.partitionBy(new HashPartitioner(2))//3.3 打印分区器println(partitionRDD.partitioner)//4.关闭连接sc.stop()}
}2.8.1 hash分区
hashpartitioner分区的原理:对于给定的key,计算其hashcode,并除以分区的个数取余,如果余数小于0,则用余数+分区的个数(否则加0),最后返回的值就是这个key所属分区

hashpartitioner分区弊端:可能导致每个分区中数据量的不均匀,极端情况下会导致某个分区拥有rdd的全部数据。
2.8.2 ranger分区
rangepartitioner作用:将一定范围内的数映射到某一个分区内,尽量保证每个分区中数据量均匀,而且分区与分区之间是有序的,一个分区中的元素肯定都是比另一个分区内的元素小或者大,但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。
实现过程为:
1、先从整个rdd中采用水塘抽样算法,抽取出样本数据,将样本数据排序,计算出每个分区最大key值,形成一个array[key]类型的数组变量rangebounds。
2、判断key在rangebounds中所处的范围,给出该key值再下一个rdd中的分区id下表;该分区器要求rdd中的key类型必须是可以排序的。




:核心内容与学习收获(附大会核心PPT下载))
)









)
)


)
