作者:来自 Elastic Ashish Tiwari

为了利用 Elasticsearch® 提供的强大搜索功能,许多企业在 Elasticsearch 中保留可搜索数据的副本。 Elasticsearch 是一种经过验证的技术,适用于传统文本搜索以及用于语义搜索用例的向量搜索。 Elasticsearch Relevance EngineTM (ESRE) 使你能够在专有数据上添加语义搜索,这些数据可以与生成式 AI 技术集成以构建现代搜索体验。
Snowflake 是一种完全托管的 SaaS(软件即服务),为数据仓库、数据湖、数据工程、数据科学、数据应用程序开发以及实时/共享数据的安全共享和消费提供单一平台。
在本博客中,我们将了解如何使用以下方法将 snowflake 数据导入 Elasticsearch:
- 使用 Logstash®(定期同步)
- 使用 Snowflake Elasticsearch Python 脚本(一次性同步)
先决条件
Snowflake 凭证
注册后你将收到以下所有凭据,或者你可以从 Snowflake 面板获取它们。
- 账户用户名
- 账号密码
- 账户标识符
Elastic® 凭证
- 访问 https://cloud.elastic.co 并注册。
- 单击 Create deployment。 在弹出窗口中,你可以更改设置或保留默认设置。
- 下载或复制部署凭据(用户名和密码)。
- 同时复制 Cloud ID。
- 准备好部署后,单击 “Continue”(或单击 “Open Kibana”)。 它会将你重定向到 Kibana® 仪表板。
使用 Logstash
Logstash 是一个免费且开放的 ETL 工具,你可以在其中提供多个源作为输入、转换(修改)它并推送到你最喜欢的存储。 Logstash 的著名用例之一是从文件中读取日志并将其推送到 Elasticsearch。 我们还可以使用 filter 插件动态修改数据,它会将更新的数据推送到输出。
我们将使用 JDBC input plugin 从 Snowflake 中提取数据,并使用 Elasticsearch output plugin 将数据推送到 Elasticsearch。
- 参考文档安装 Logstash。
- 转到 Maven 中央存储库并下载:https://repo1.maven.org/maven2/net/snowflake/snowflake-jdbc。
- 单击你需要的版本的目录并下载 snowflake-jdbc-#.#.#.jar 文件。 就我而言,我已经下载了snowflake-jdbc-3.9.2.jar。 (有关 Snowflake JDBC 驱动程序的更多信息,请参阅官方文档。)
- 通过创建文件 sf-es.conf 创建管道。 添加以下代码片段并替换所有凭证。
sf-es.conf
input {jdbc {jdbc_driver_library => "/usr/share/logstash/logstash_external_configs/driver/snowflake-jdbc-3.9.2.jar"jdbc_driver_class => "net.snowflake.client.jdbc.SnowflakeDriver"jdbc_connection_string => "jdbc:snowflake://<account_identifier>.snowflakecomputing.com/?db=SNOWFLAKE_SAMPLE_DATA&warehouse=COMPUTE_WH&schema=TPCH_SF1"jdbc_user => "<snowflake_username>"jdbc_password => "<snowflake_password>"schedule => "* * * * *"statement => "select * from customer limit 10;"}
}filter {}output {elasticsearch {cloud_id => "<elastic cloud_id>"cloud_auth => "<elastic_username>:<elastic_password>"index => "sf_customer"}
}jdbc_connection_string :
db=SNOWFLAKE_SAMPLE_DATA
warehouse=COMPUTE_WH
schema=TPCH_SF1Schedule:你可以在此处计划使用 cron 语法定期运行此流程。 每次运行时,你的数据都会增量移动。 你可以查看有关 scheduling 的更多信息。
请根据你的要求进行更改。
JDBC 分页(可选):这将导致一条 sql 语句被分解为多个查询。 每个查询将使用限制和偏移量来共同检索完整的结果集。 你可以使用它在一次运行中移动所有数据。
通过添加以下配置来启用 JDBC 分页:
jdbc_paging_enabled => true,
jdbc_paging_mode => "explicit",
jdbc_page_size => 1000005. 运行 Logstash
bin/logstash -f sf-es.confSnowflake-Elasticsearch Python 脚本
如果 Logstash 当前尚未到位或尚未实现,我编写了一个小型 Python 实用程序(可在 GitHub 上找到)从 Snowflake 提取数据并将其推送到 Elasticsearch。 这将一次性提取你的所有数据。 因此,如果你有少量数据需要非定期迁移,则可以使用此实用程序。
注意:这不是官方 Elastic 连接器的一部分。 弹性连接器为各种数据源提供支持。 如果你需要从任何受支持的数据源同步数据,则可以使用此连接器。
1) 安装
git clone https://github.com/ashishtiwari1993/snowflake-elasticsearch-connector.git
cd snowflake-elasticsearch-connector2)安装依赖项
git clone https://github.com/ashishtiwari1993/snowflake-elasticsearch-connector.git
cd snowflake-elasticsearch-connector3)修改配置
- 打开 config/connector.yml。
- 将凭证替换为以下内容:
snowflake:username: <sf_username>password: <sf_password>account: <sf_account_identifier>database: <db_name>table: <table_name>columns: ""warehouse: ""scheme: ""limit: 50elasticsearch:host: https://localhost:9200username: elasticpassword: elastic@123ca_cert: /path/to/elasticsearch/config/certs/http_ca.crtindex: <sf_customer>4)运行 Connector
python __main__.py
验证数据
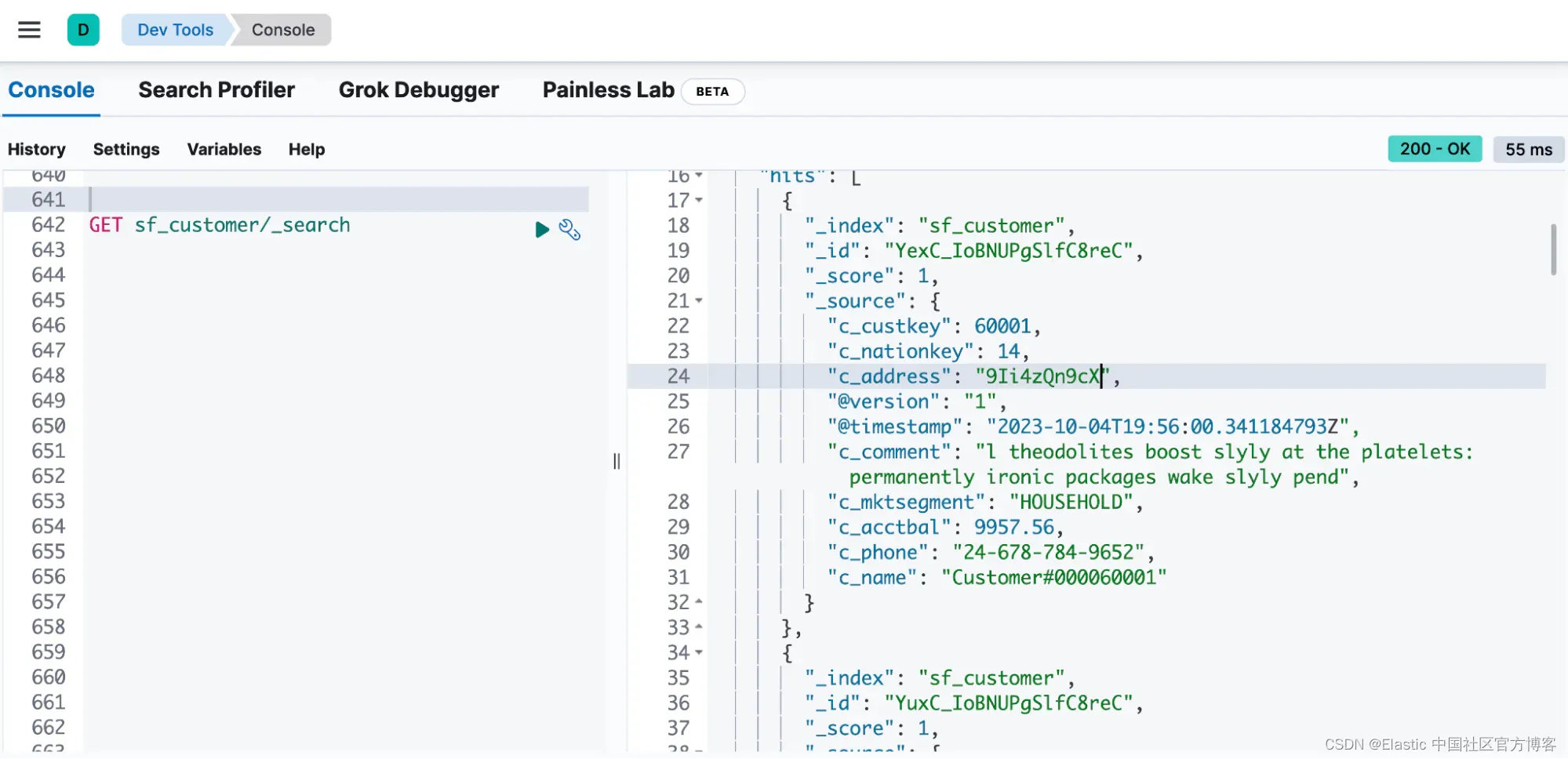
登录 Kibana 并转到 ☰ > Management > Dev Tools。
将以下 API GET 请求复制并粘贴到控制台窗格中,然后单击 ▶(播放)按钮。 这会查询新索引中的所有记录。
GET sf_customer/_search
{"query": {"match_all": {}}
}
结论
我们已成功将数据从 Snowflake 迁移到 Elastic Cloud。 你可以在任何 Elasticsearch 实例上实现相同的目标,无论是在云端还是在本地。
开始在你的数据集上利用全文和语义搜索功能。 你还可以将你的数据与 LLM 连接起来,以构建问答功能。
)

)




)










)
