XTuner 大模型单卡低成本微调实战

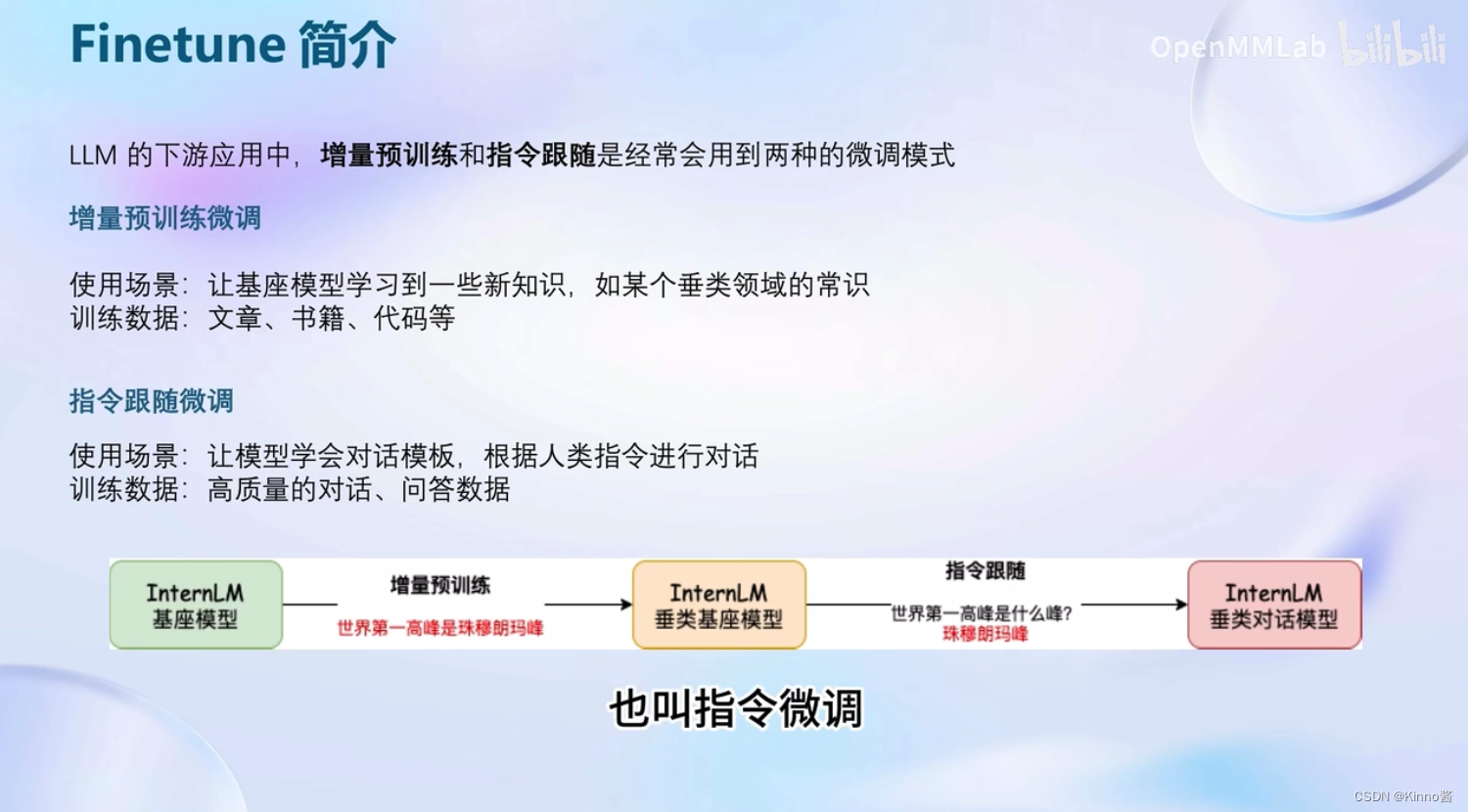
Finetune简介
常见的两种微调策略:增量预训练、指令跟随
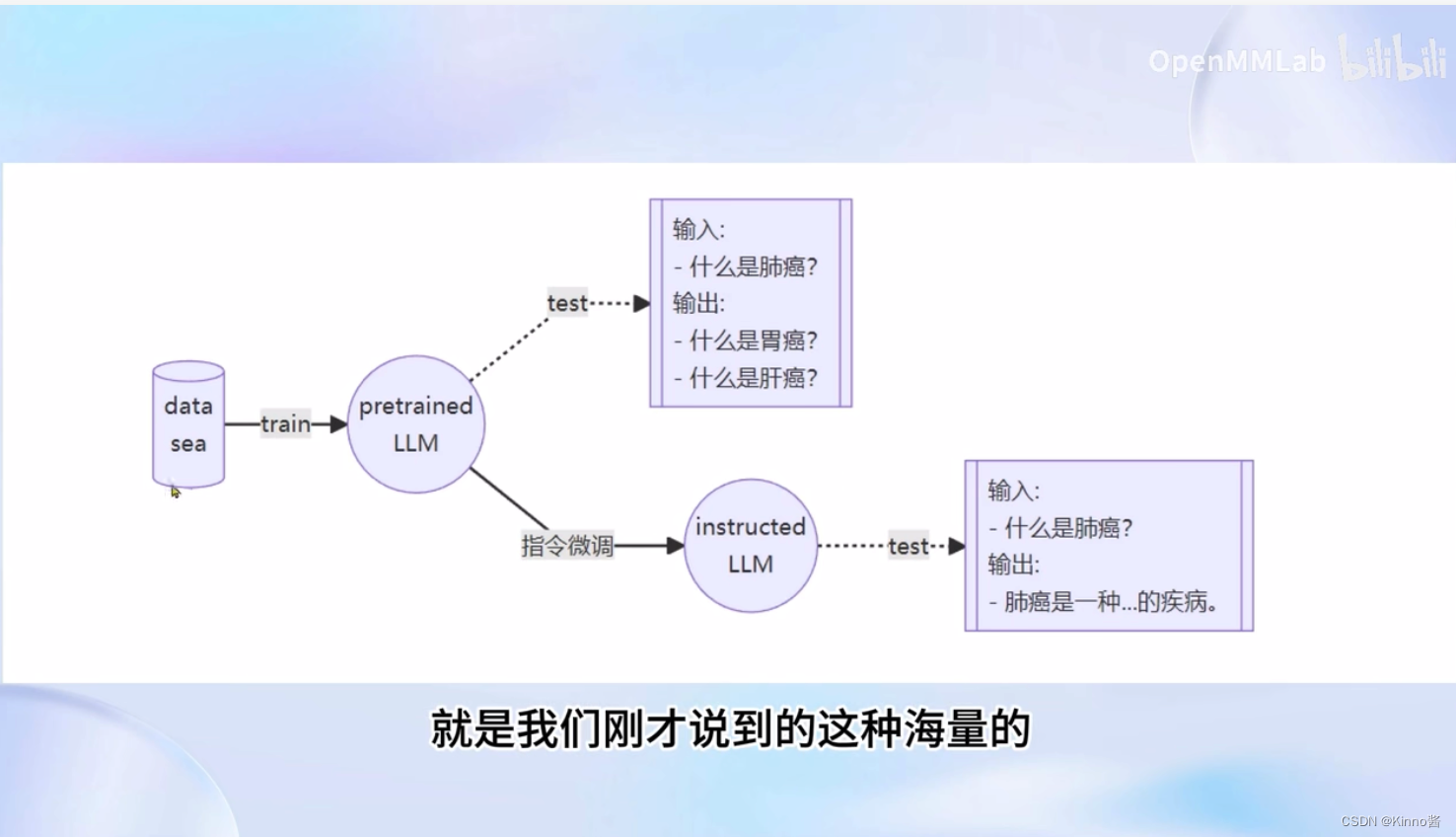
指令跟随微调
数据是一问一答的形式
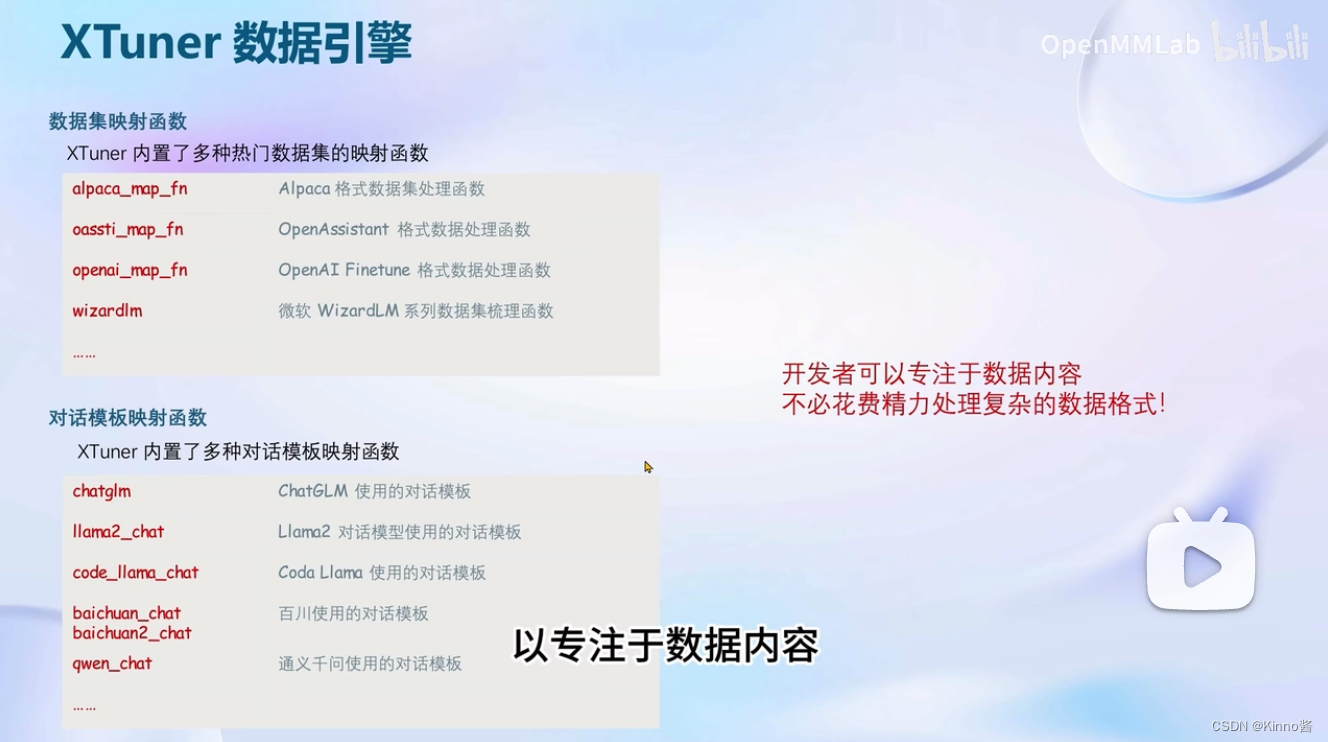
对话模板构建
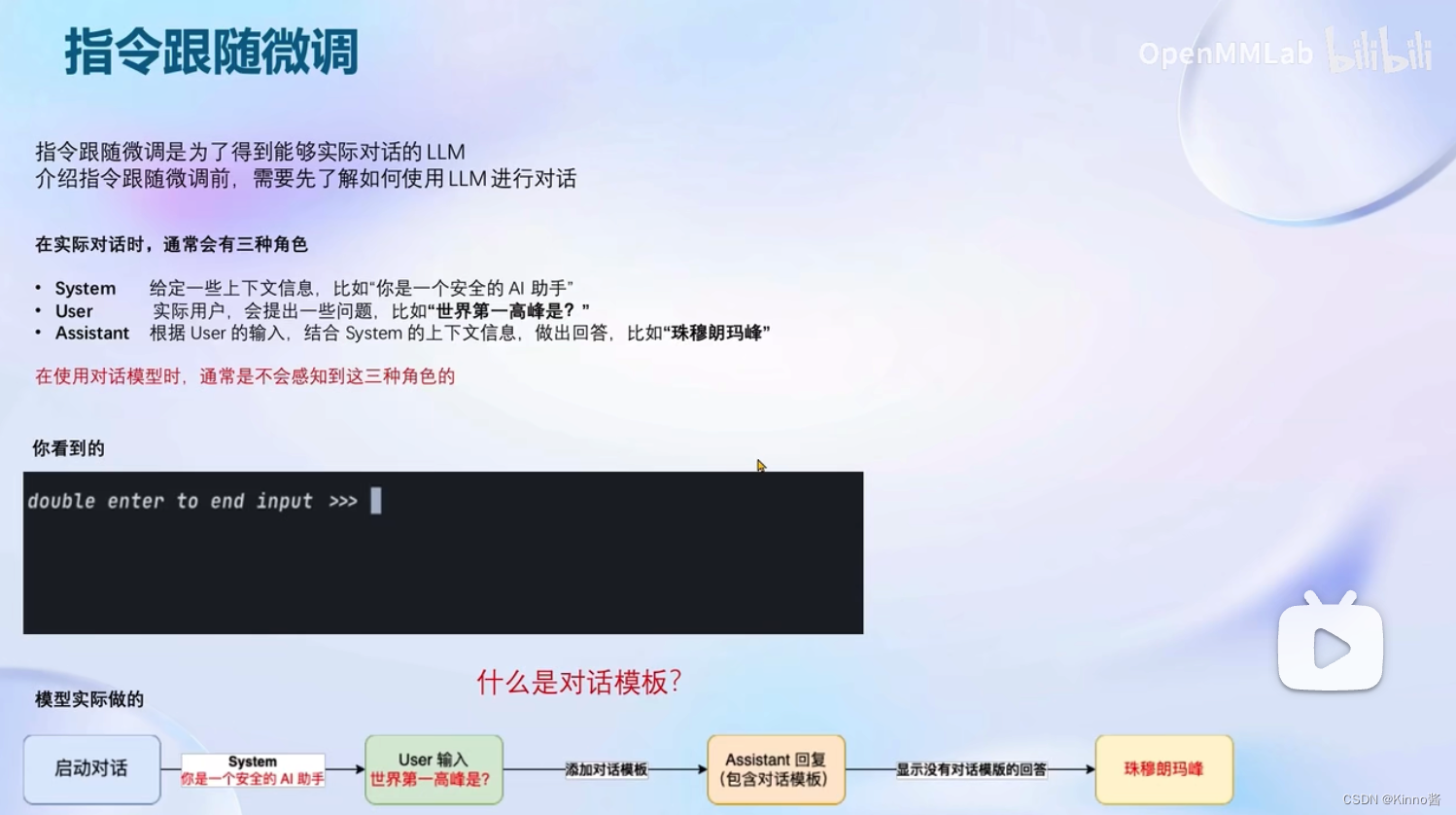
每个开源模型使用的对话模板都不相同
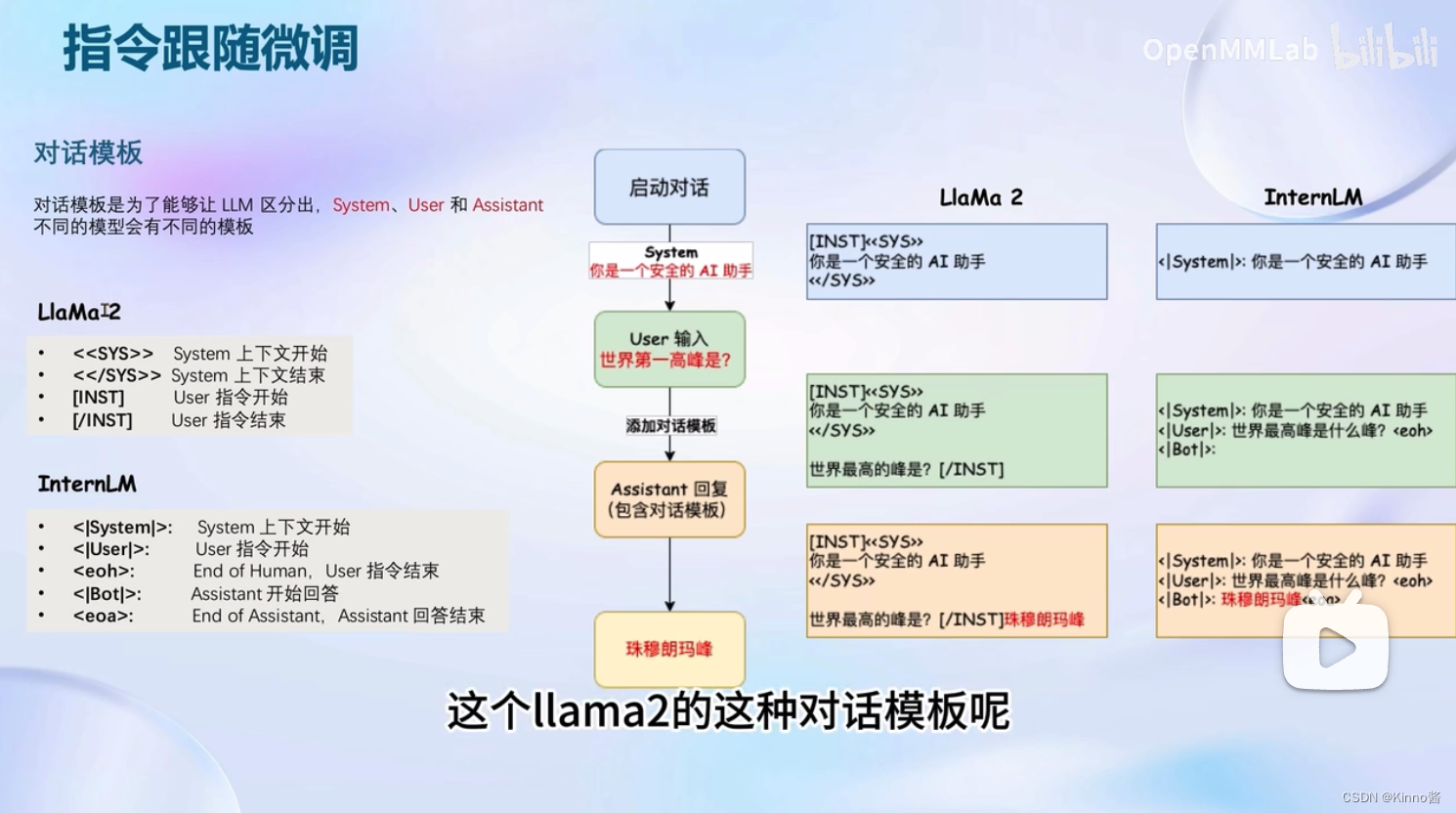
指令微调原理:
由于只有答案部分是我们期望模型来进行回答的内容,所以我们只对答案部分进行损失的计算

增量预训练微调
数据都是陈述句,没有问答形式


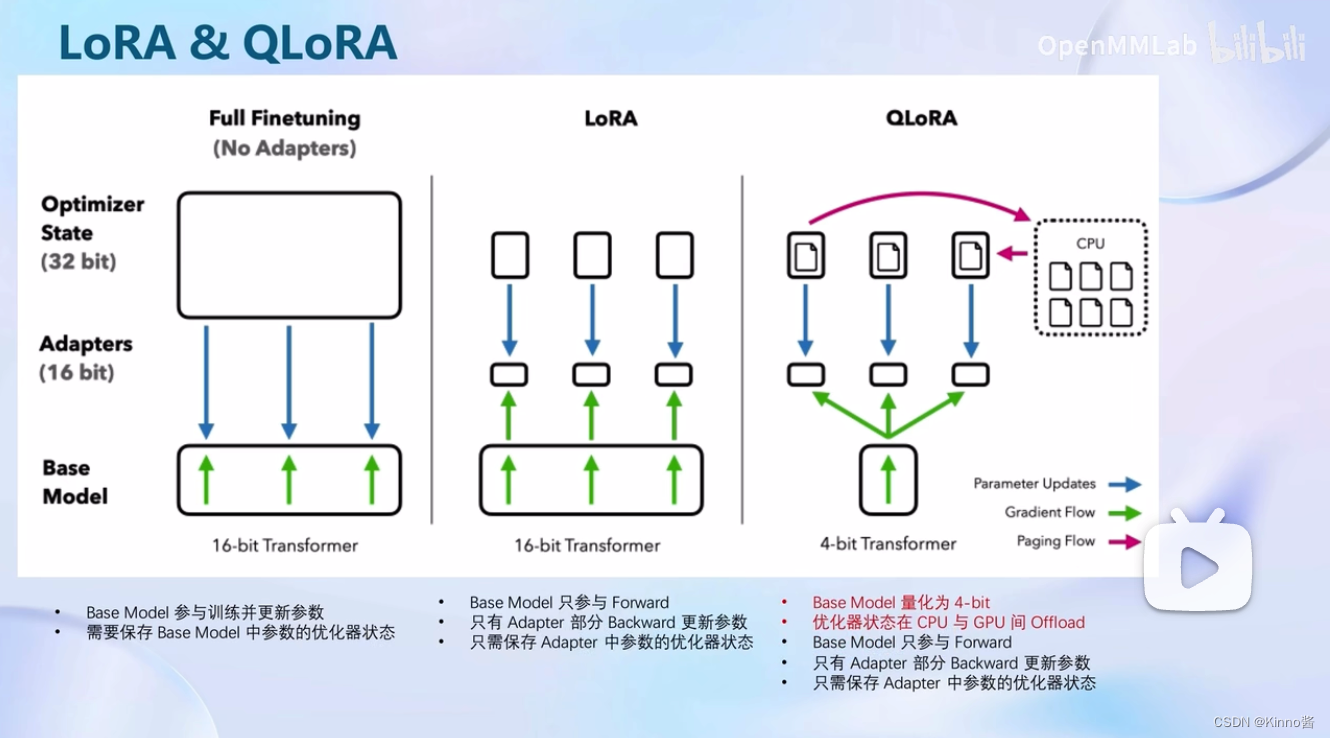
LoRA & QLoRA
XTuner中使用的微调原理:LoRA & QLoRA
如果我们要对整个模型的所有参数都进行调整的话,需要非常大的显存才能够进行训练,但是用LoRA的方法就不需要这么大的显存开销了

比较:全参数微调、LoRA、QLoRA
全参数微调:整个模型都要加载到显存中,所有模型参数的优化器也都要加载到显存中,显存不够根本无法进行·
LoRA:模型也是要先加载到显存中,但是我们只需要保存LoRA部分的参数优化器,大大减小了显存占用
QLoRA:加载模型时就使用4bit量化的方式加载(相当于不那么精确的加载),但是可以节省显存开销,QLoRA部分的参数优化器,还可以在GPU和CPU之间进行调度【这是Xtunner进行整合的功能 】,显存满了就自动去内存中去跑。
XTuner介绍

XTuner快速上手
- 安装
pip install xtuner
- 挑选配置模版
xtuner list-cfg -p internlm_20b
- 一键训练
xtuner train internlm_20b_qlora_oasst1_512_e3
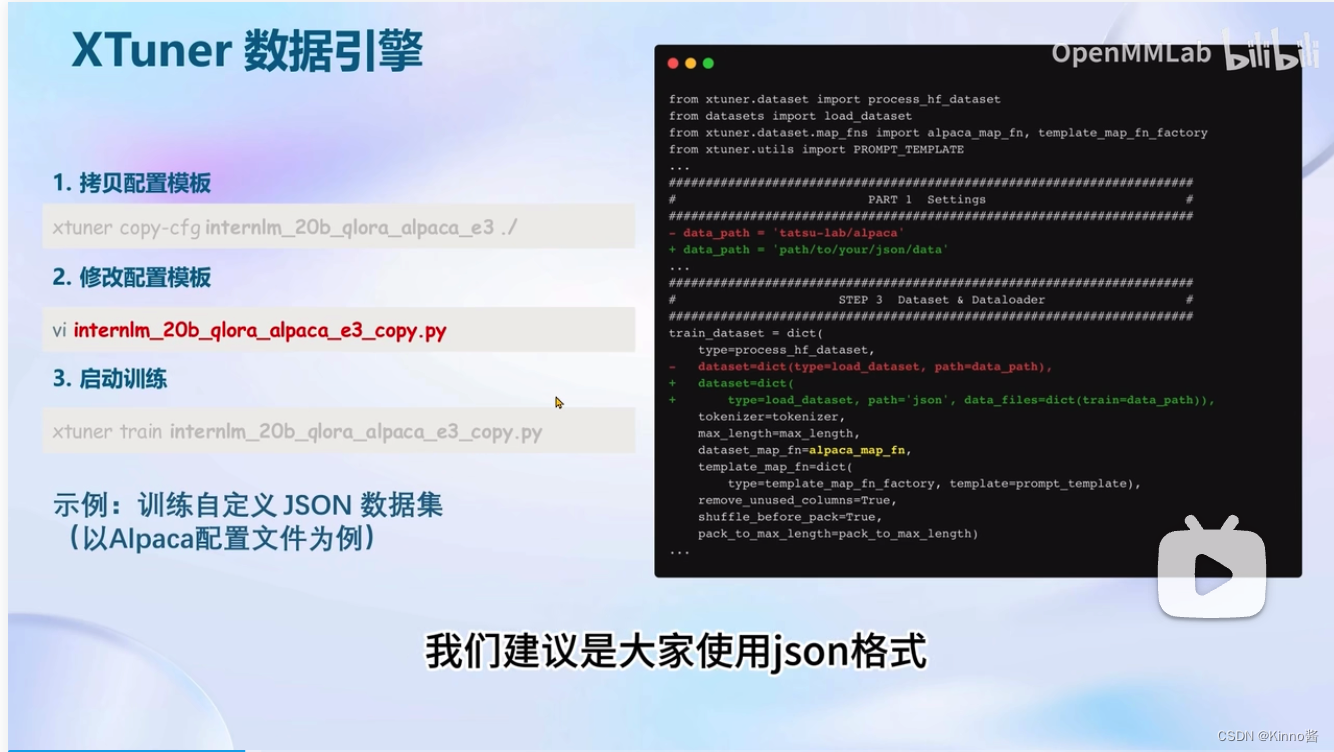
- Config 命名规则
| 模型名 | internlm_20b ( 无 chat 代表是基座模型 ) |
| 使用算法 | qlora |
| 数据集 | oasst1 |
| 数据长度 | 512 |
| Epoch | e3, epoch 3 |

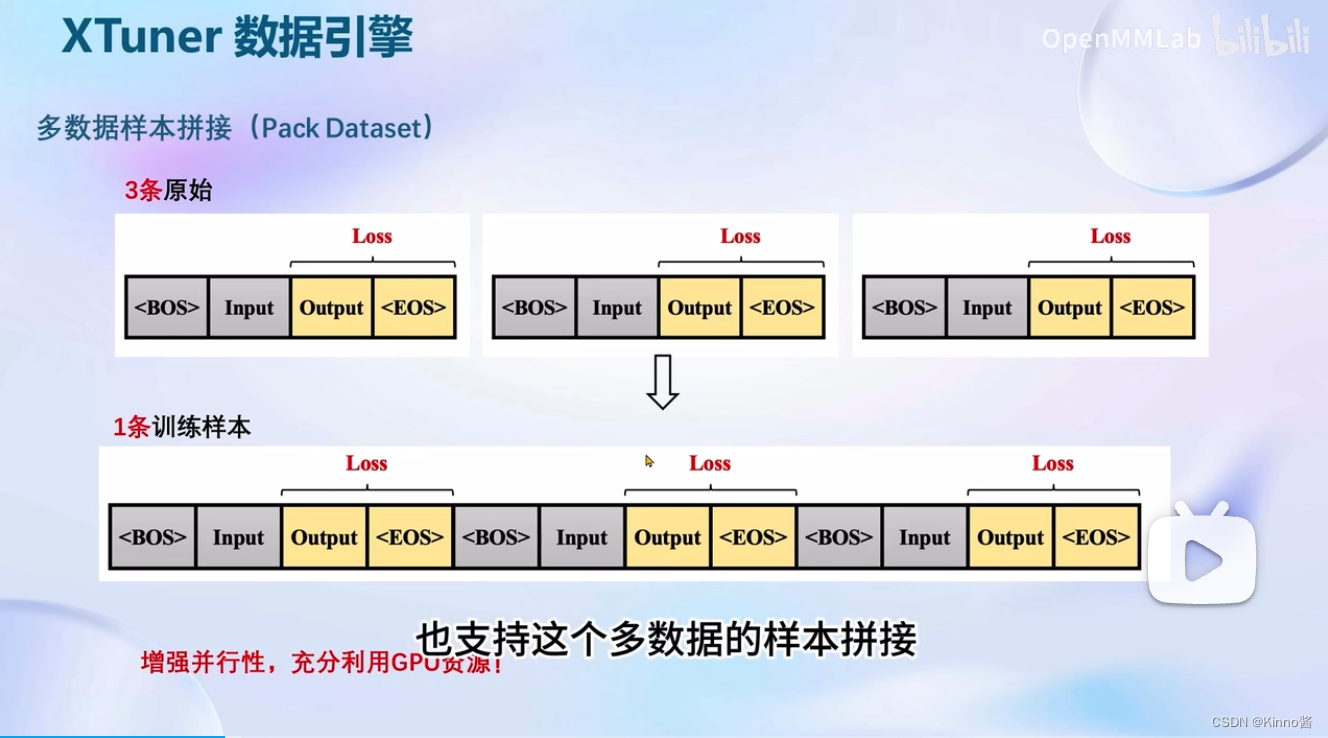
XTunner支持多数据的样本拼接,增加运行效率,输入模型,统一的进行梯度的传播
自定义数据集建议使用json格式
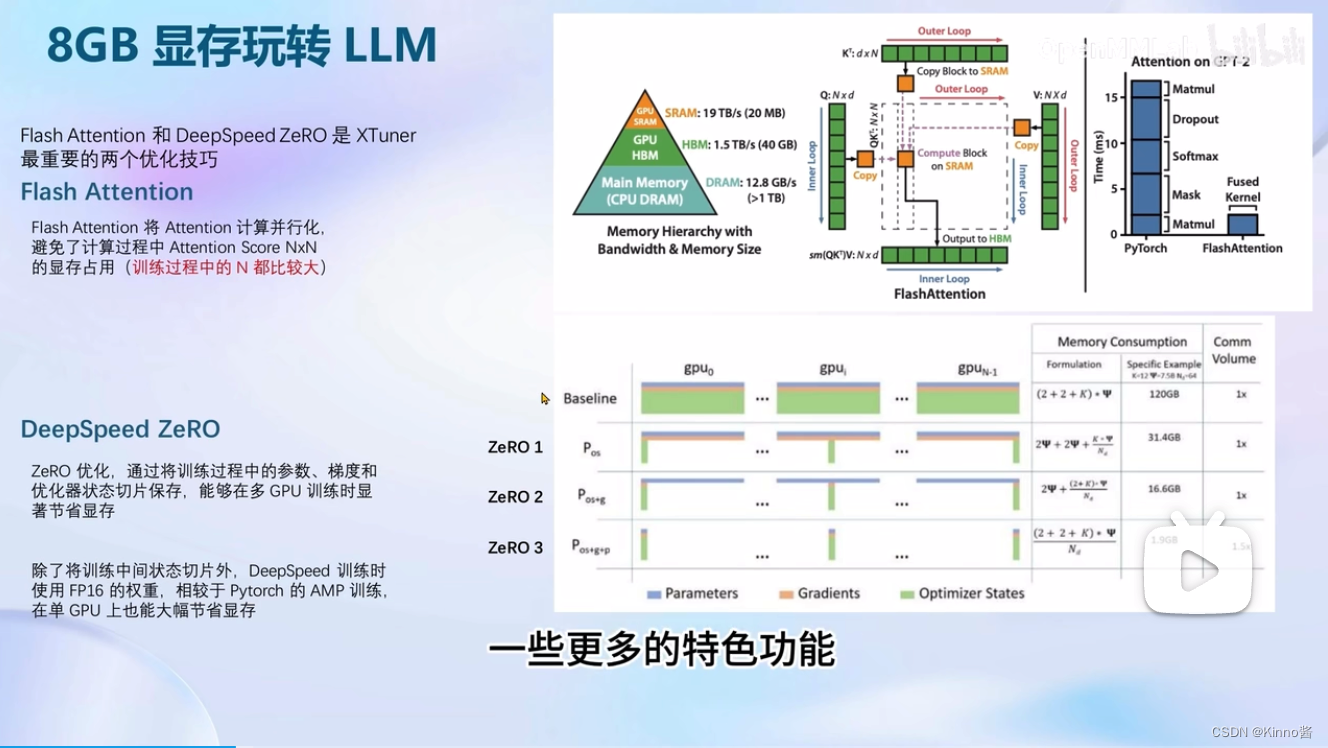
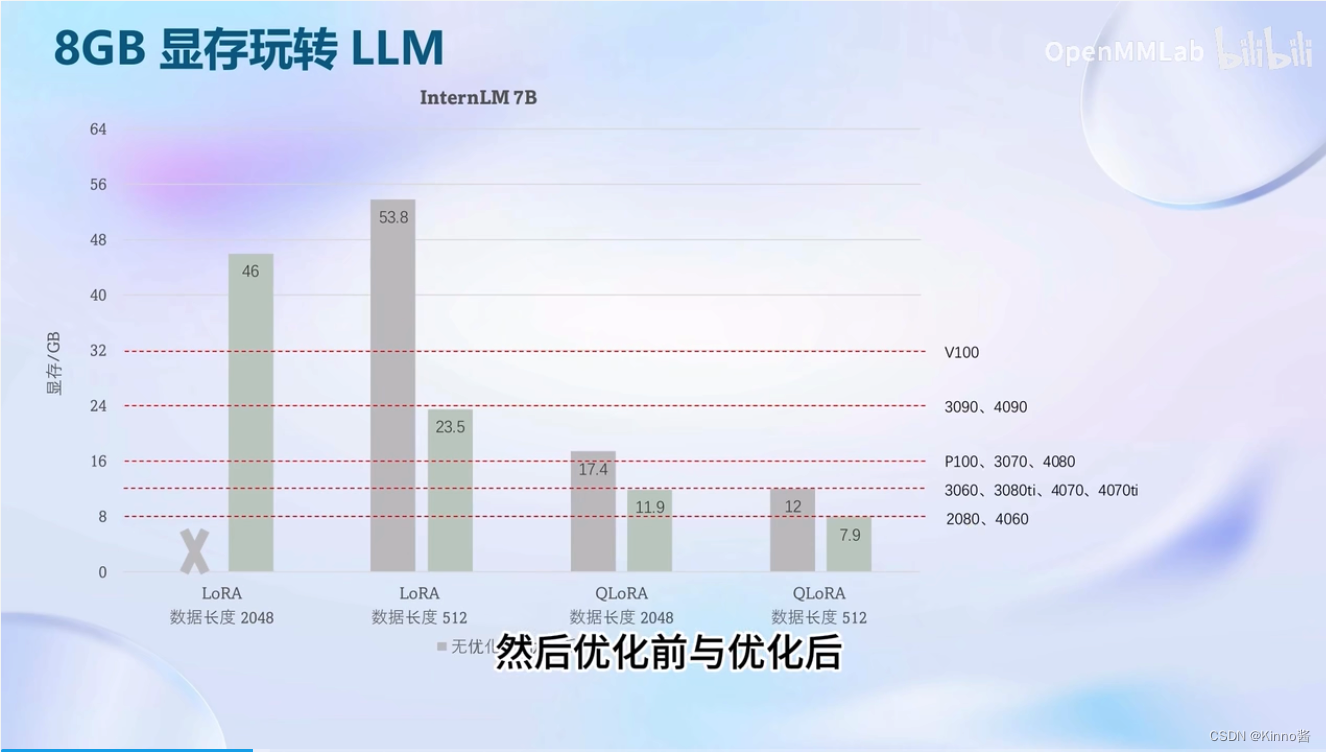
8GB显卡玩转LLM

动手实战环节
https://github.com/InternLM/tutorial/blob/main/xtuner/README.md





![[Linux使用] 库依赖分析 LDD](http://pic.xiahunao.cn/[Linux使用] 库依赖分析 LDD)




-帖子详情页实现)







-Java+Python+JavaScript)
