前言
- 📚 笔记专栏:斯坦福CS231N:面向视觉识别的卷积神经网络(23)
- 🔗 课程链接:https://www.bilibili.com/video/BV1xV411R7i5
- 💻 CS231n: 深度学习计算机视觉(2017)中文笔记:https://zhuxiaoxia.blog.csdn.net/article/details/80155166
- 🔥 2023最新课程PPT:https://download.csdn.net/download/Julialove102123/88734395
⚠️ 本节重点内容:
- 卷积神经网络的历史
- 卷积神经网络与常规神经网络的对比;
- CNN 卷积层、池化层、ReLU层、全连接层;
- CNN 局部连接、参数共享、最大池化、步长、零填充 、数据体尺寸
- CNN 层的规律与尺寸设置
- CNN 经典案例
本章(lecture5)花了很大篇幅介绍了卷积网络发展进程和基础的一些信息,这里不做详细记录,感兴趣可以直接看PPT!我们直接结合第五节的部分内容进入卷积神经网络部分Lecture6。
一、卷积神经网络的历史(略)
可参考PPT回顾。
二、常规神经网络和卷积神经网络
2.1 常规神经网络
常规神经网络的输入是一个向量,比如把一张32x32x3的图片延展成3072x1的列向量x,然后在一系列的隐层中对它做变换。
每个隐层都是由若干的神经元组成,每个神经元都与前一层中的所有神经元连接(这就是全连接的概念)。 但是在一个隐层中,神经元相互独立不进行任何连接。
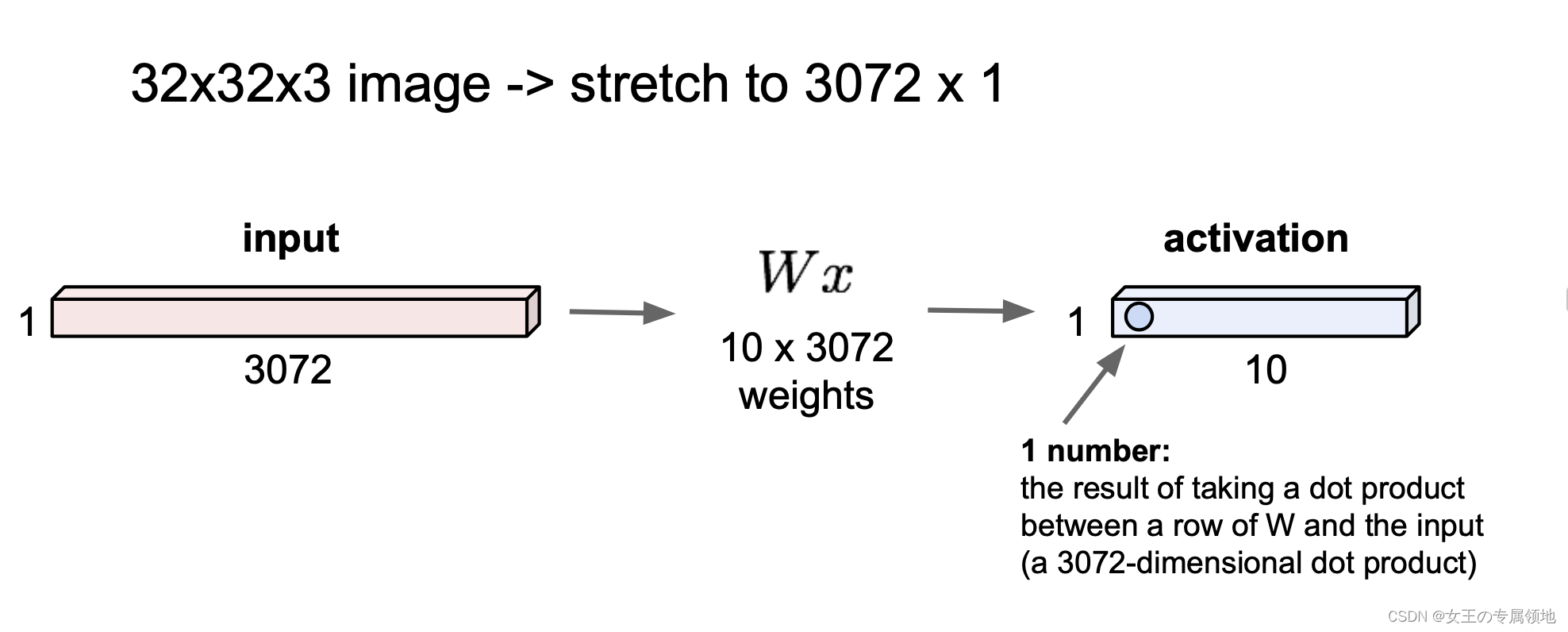
存在问题:全连接神经网络在处理大的图片数据时参数会急速增加,即全连接方式效率不高,且参数量大,可能会导致网络过拟合。。
2.2 卷积神经网络
与常规神经网络不同,卷积神经网络的各层中的神经元都是 3 维的:宽度、高度和深度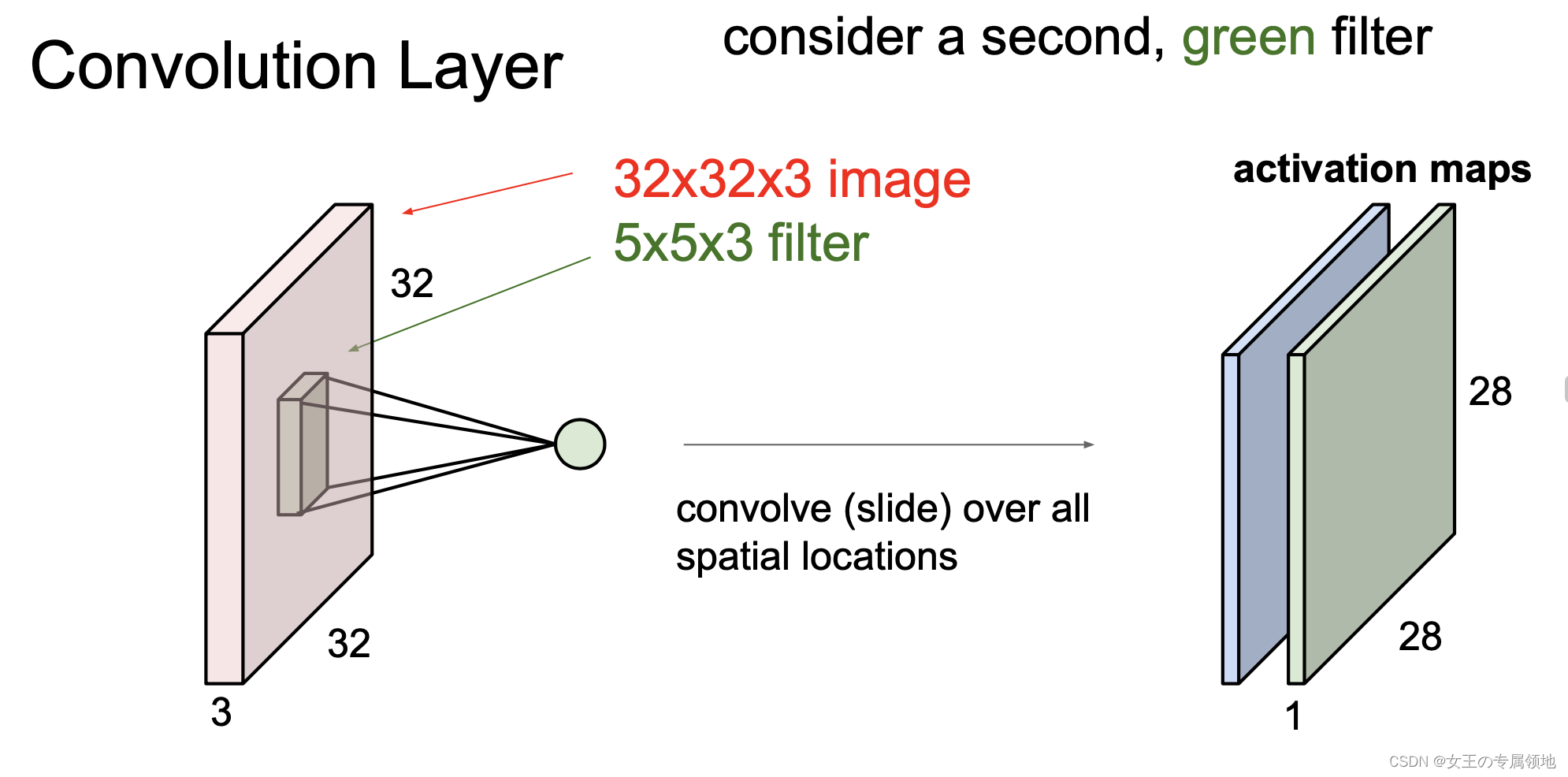

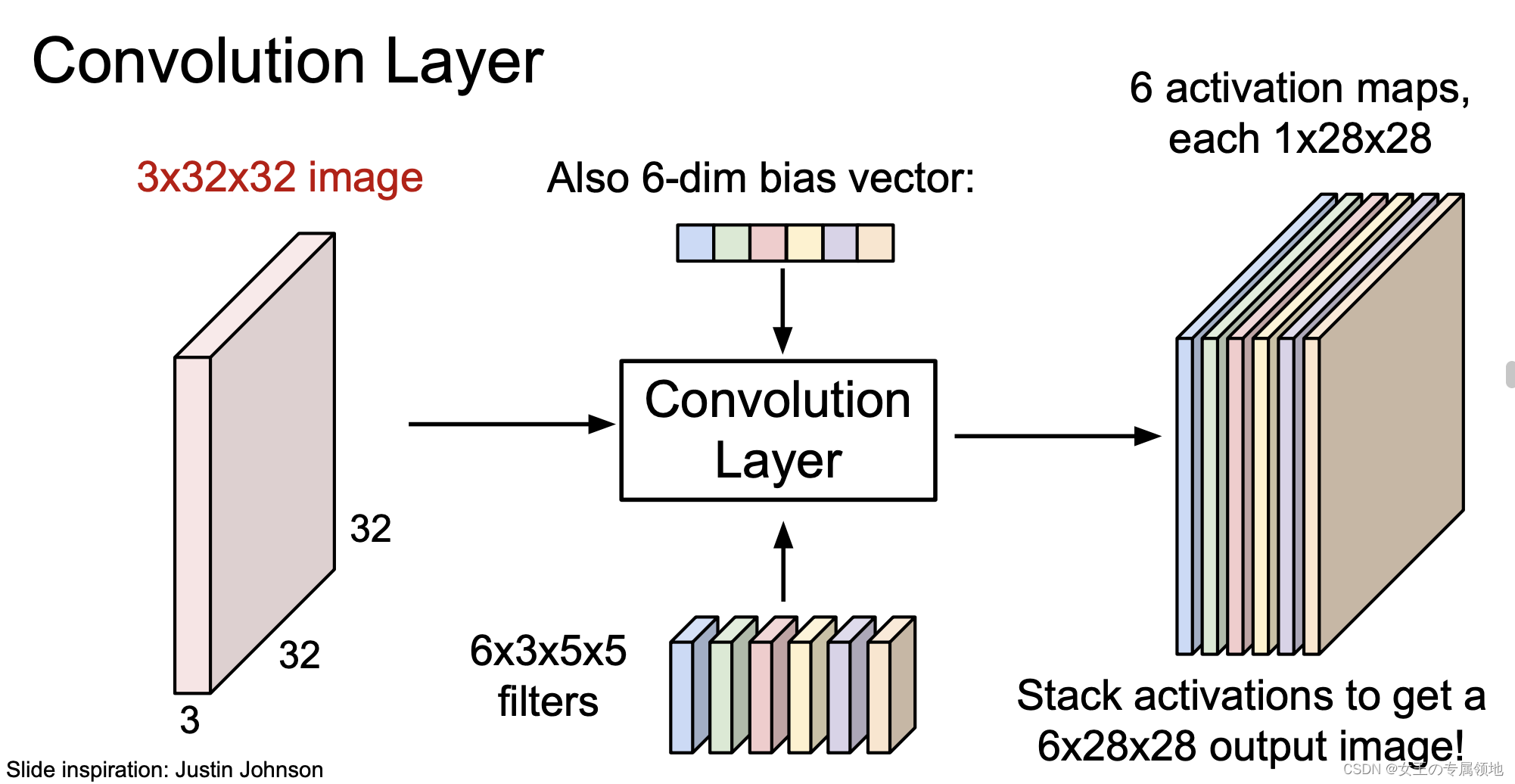
多个滤波器和多个偏置项;
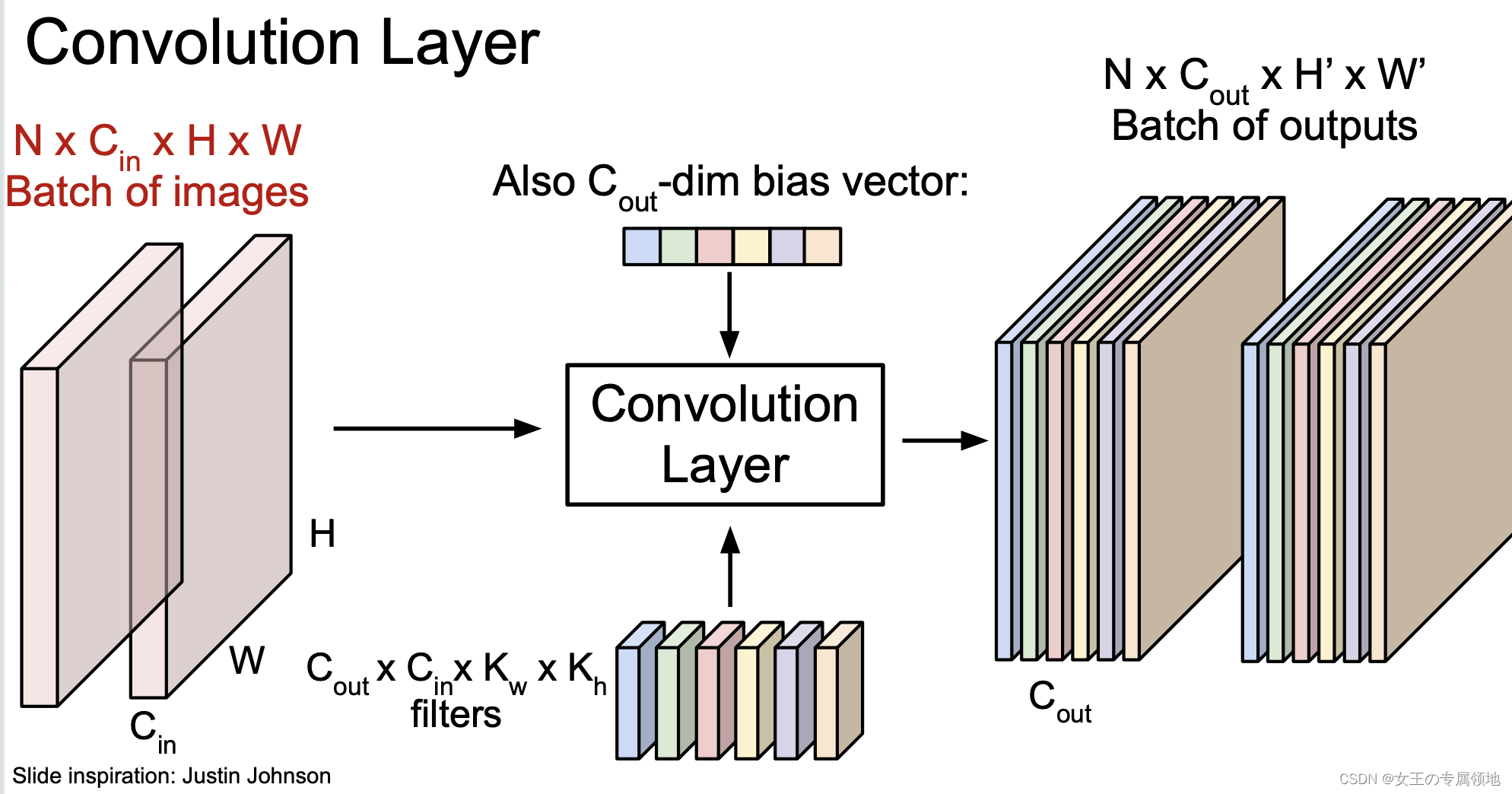
多个batch的输入
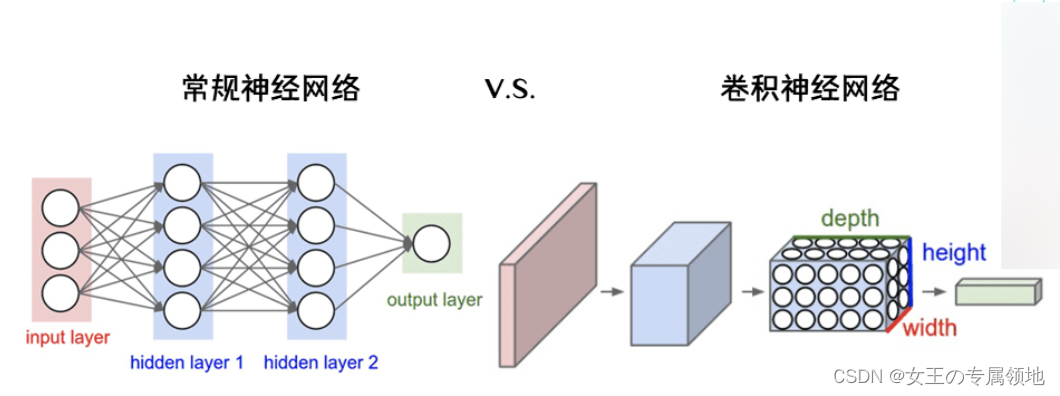
2.3 对比
卷积神经网络(CNN / ConvNet) 和常规神经网络非常相似:
相同点
- 都是由神经元组成,神经元中有具有学习能力的权重和偏置项。每个神经元都得到一些输入数据,进行内积运算后再进行激活函数运算;
- 整个网络依旧是一个可导的评分函数,该函数的输入是原始的图像像素,输出是不同类别的评分;
- 在最后一层(往往是全连接层),网络依旧有一个损失函数(比如 SVM 或 Softmax),并且在神经网络中我们实现的各种技巧和要点依旧适用于卷积神经网络。
卷积神经网络的结构基于输入数据是图像,向结构中添加了一些特有的性质,使得前向传播函数实现起来更高效,并且大幅度降低了网络中参数的数量。
差异点: 常规神经网络,每个神经元和上层的神经元都是全连接的;卷积神经网络,每个神经元都有三个维度,网络每一层都将 3D 的输入数据变化为神经元 3D 的激活数据并输出。红色的输入层装的是图像,所以它的宽度和高度就是图像的宽度和高度,它的深度是3(代表了R/红、G/绿、B/蓝3个颜色通道)。蓝色的部分是第一层卷积层的输出,表明有多种滤波器。
三、卷积神经网络
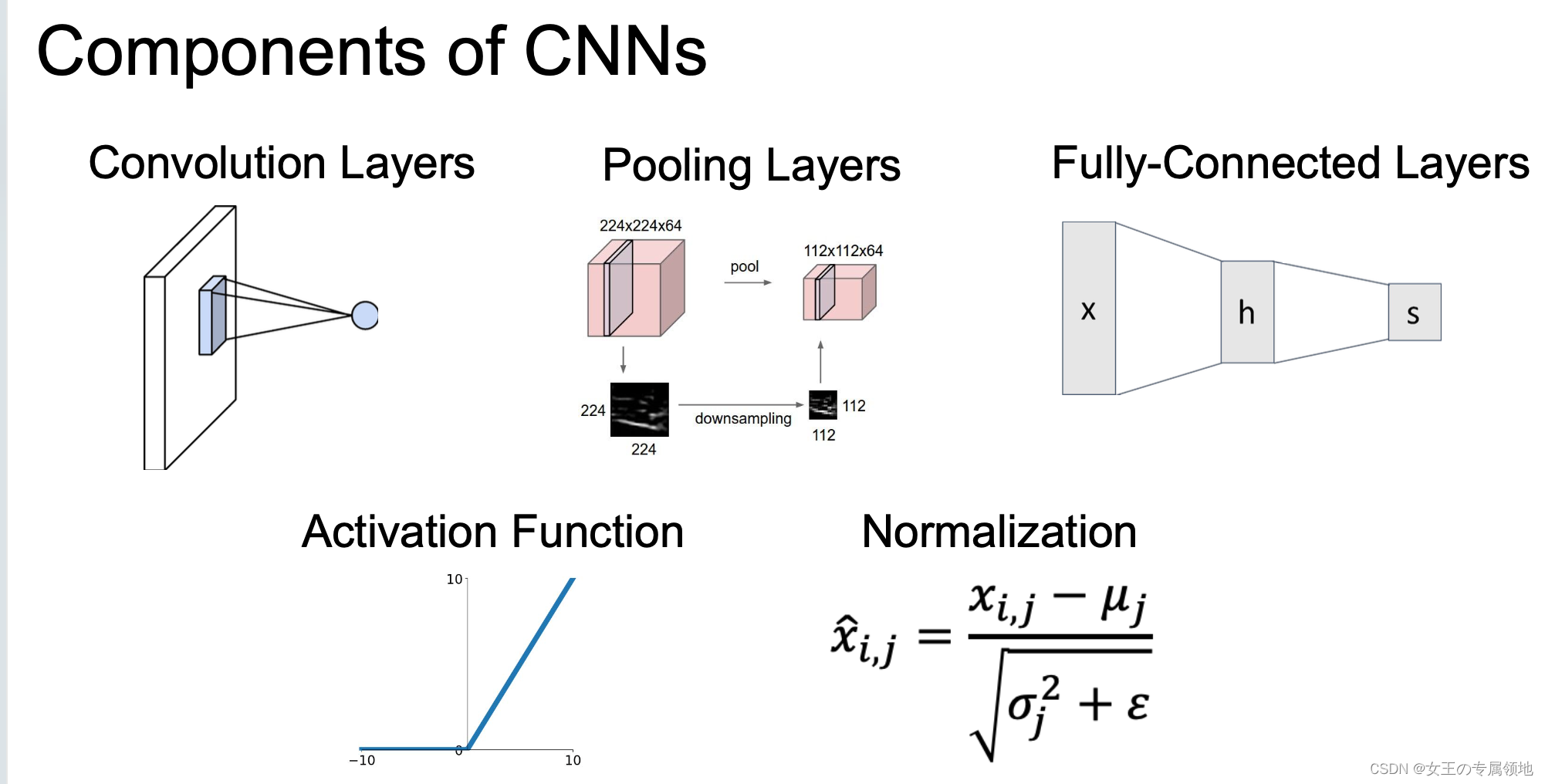
3.1 基础结构
一个简单的卷积神经网络是由各种层按照顺序排列组成,卷积神经网络主要由三种类型的层构成:卷积层,池化(Pooling)层和全连接层(全连接层和常规神经网络中的一样)。通过将这些层叠加起来,就可以构建一个完整的卷积神经网络。
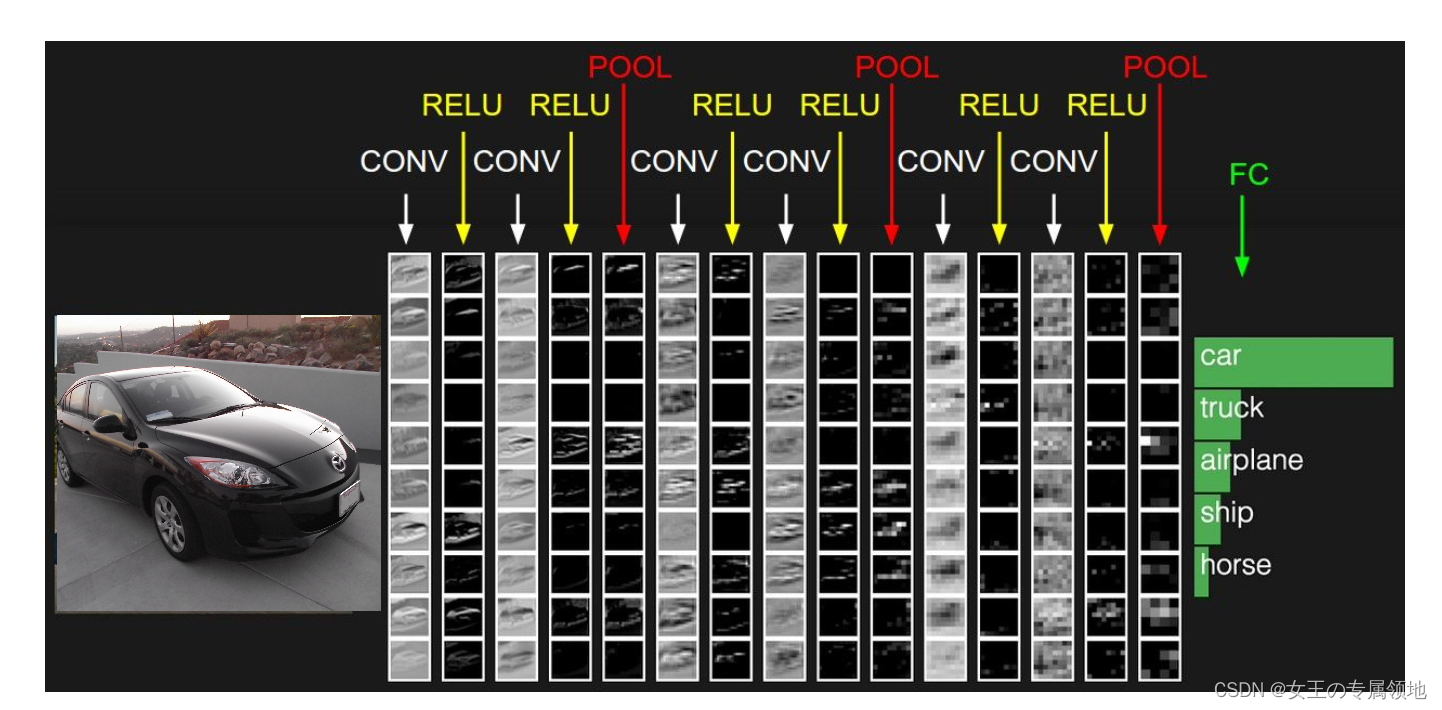

卷积神经网络一层一层地将图像从原始像素值变换成最终的分类评分值。
卷积层和全连接层(CONV/FC)对输入执行变换操作的时候,不仅会用到激活函数,还会用到很多参数(神经元的权值和偏置项)ReLU层和池化层进行一个固定的函数操作。卷积层、全连接层和池化层有超参数,ReLU 层没有。卷积层和全连接层中的参数利用梯度下降训练。
实际应用的时候,卷积网络是由多个卷积层依次堆叠组成的序列,然后使用激活函数(比如ReLU函数)对其进行逐一处理。然后这些卷积层、激活层、池化层会依次堆叠,上一层的输出作为下一层的输入。每一层都会使用多个卷积核,每个卷积核对用一个激活映射。
3.2 卷积可视化
卷积网络这些卷积层的所有卷积核完成训练后,会发现:
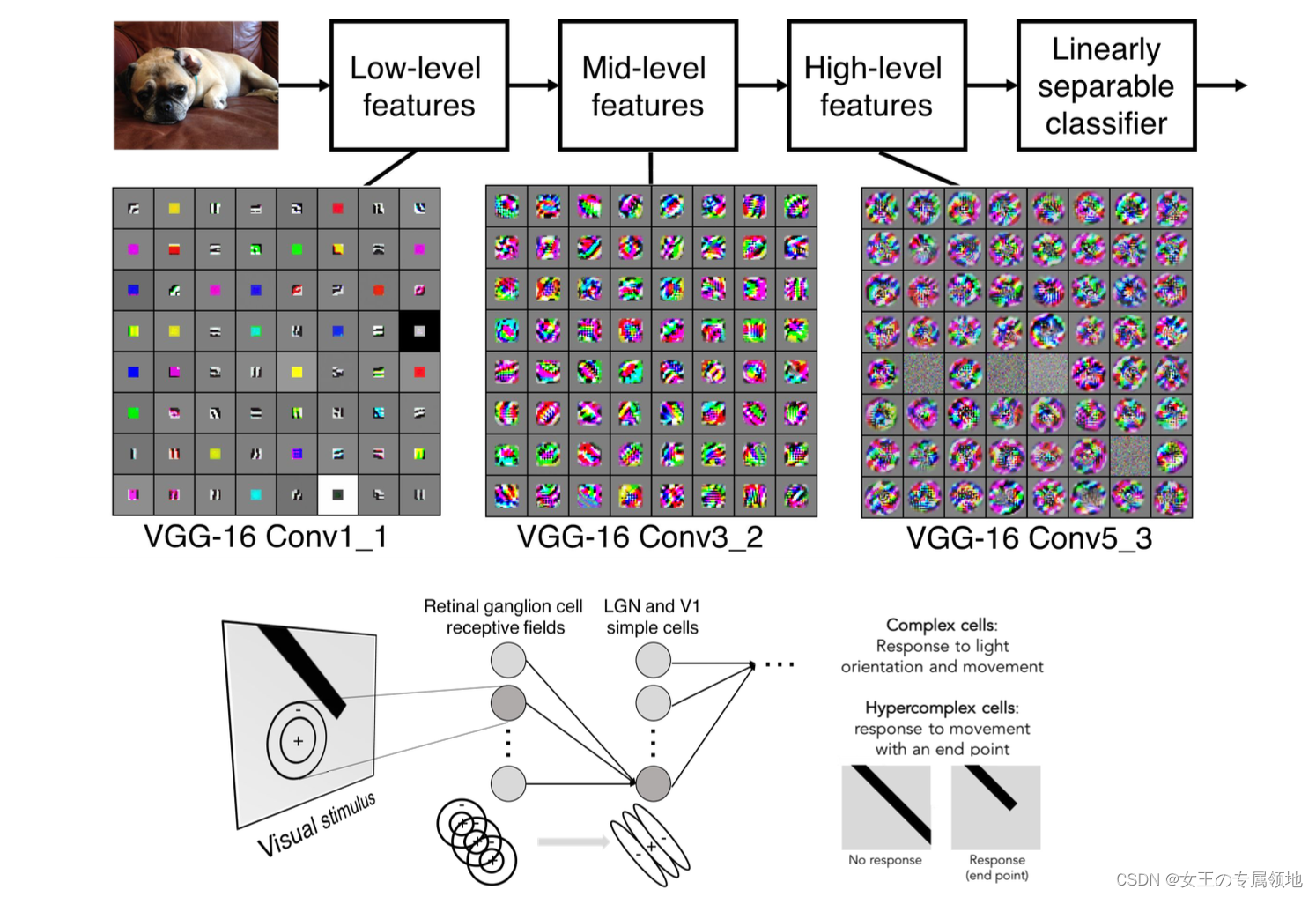
- 前面几个卷积层的卷积核捕捉和匹配的是一些比较简单的特征,比如边缘;
- 中间几层的卷积核代表的特征变得复杂一些,比如一些边角和斑点;
- 最后几层的特征就会变得特别丰富和复杂。
这些卷积核是从简单到复杂的特征序列。这实际上和 Hubel & Wiesel 的实验结果比较相似,即使在我们并没有明确的让网络去学习这些从简单到复杂的特征,但是给它这种层次结构并经过反向传播训练后,这些类型的卷积核最终也能学到。

比如图中上方红框中的第一个卷积核对应得到红框的激活映射,卷积核看起来像是一个定向边缘的模板,所以当其滑过图像,在那些有定向边缘的地方会得到较高的值。之所以称作卷积,只是计算形式上就是卷积,滤波器和信号(图像)的元素相乘后求和。
3.3 网络结构
1. 卷积层(Convolutional Layer,Conv layer)
卷积层是构建卷积神经网络的核心层,网络中大部分的计算量都由它产生。
卷积层的参数是由一些可学习的滤波器(filter) 集合构成的。每个滤波器在宽度和高度上都比较小,但是深度和输入数据一致。
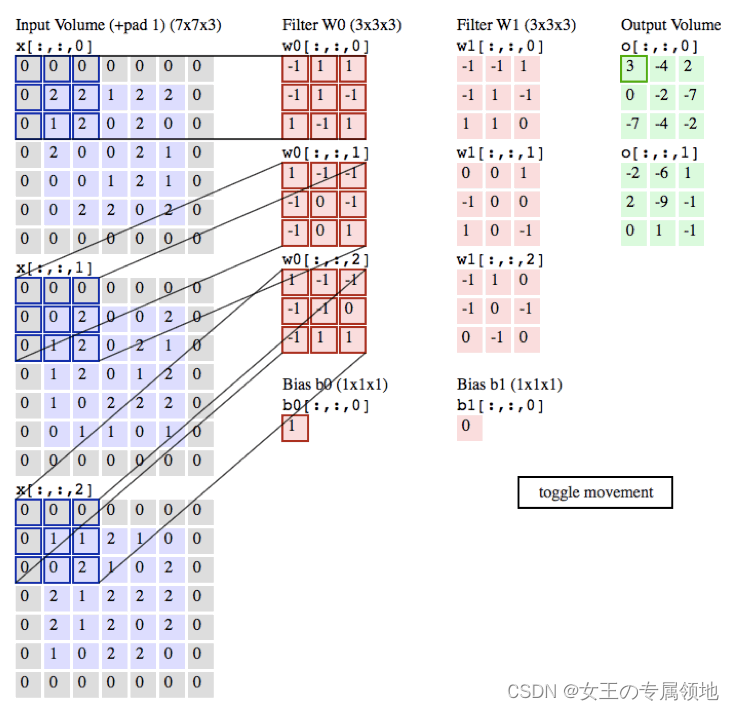
- 激活映射(activation map):图像和滤波器卷积计算生成的产物;
网络会让滤波器学习,结果是当它看到某些类型的视觉特征时就激活,具体的视觉特征可能是某些方位上的边界,或者在第一层上某些颜色的斑点,甚至可以是网络更高层上的蜂巢状或者车轮状图案
- 参数共享(Parameter sharing):在卷积层中使用参数共享是用来控制参数的数量。
一些参数相同的神经元在原图像的不同位置做内积得到的输出数据组成的。每张激活图对应的所有神经元参数都相同(因为实际上就是同一个滤波器在图像上不同位置滑动的结果,每到一个位置就是一个神经元)
- 稀疏连接(Sparsity of connections):卷积层每个神经元和原图像只在一个小区域进行全连接。因为在处理图像这样的高维度输入时,让每个神经元都与前一层中的所有神经元进行全连接是不现实的。
局部连接的空间大小叫做神经元的感受野(receptive field)
,它的尺寸(其实就是滤波器的空间尺寸)是一个超参数。在深度方向上,这个连接的大小总是和输入量的深度相等。即连接在空间(宽高)上是局部的,但是在深度上总是和输入数据的深度一致。
- 深度(Depth) :卷积层中使用的滤波器往往有多个,深度就是滤波器的数量。
每个滤波器在输入数据中匹配计算不同的模式。比如第一个卷积层的输入是原始图像,那么在深度维度上的不同神经元将可能被原图像上不同方向的边界,或者是颜色斑点激活。将这些沿着深度方向排列、感受野相同的神经元集合称为深度列(depth column),或者纤维(fibre)
- 步长(Stride):步长就是滤波器每次移动跨越的像素数量。
当步长为1,滤波器每次移动1个像素。当步长为2(实际中很少使用比2大的步长),滤波器滑动时每次移动2个像素。这个操作会让输出数据体在空间上变小。
- 零填充(Zero Padding):在图像的边界外填充零像素点。
滑动时会使输出数据体在空间上变小,我们不希望这样,于是引入了零填充,零填充有一个良好性质,可以控制输出数据体的空间尺寸(最常用的是用来保持输入数据体在空间上的尺寸,这样输入和输出的宽高都相等)。
- 输出尺寸: ( W + 2 P − F ) / S + 1 (W + 2P -F)/S + 1 (W+2P−F)/S+1
假如输入数据体WxW公式,卷积层中神经元的感受野尺寸FxF,步长 S和零填充的数量P,则输出数据体的空间尺寸为 ( W + 2 P − F ) / S + 1 (W + 2P -F)/S + 1 (W+2P−F)/S+1 。
- 反向传播:卷积操作的反向传播(同时对于数据和权重)还是一个卷积(但是是在空间上翻转的滤波器)。
在反向传播的时候,需要计算每个神经元对它的权重的梯度,所以需要把同一个深度切片上的所有神经元对权重的梯度进行累加,这样就得到了对这个共享权重的梯度。这样,每个切片只更新一个权重集。
- 其他卷积类型:
-
1 X 1 卷积:主要是起到升降维的作用。
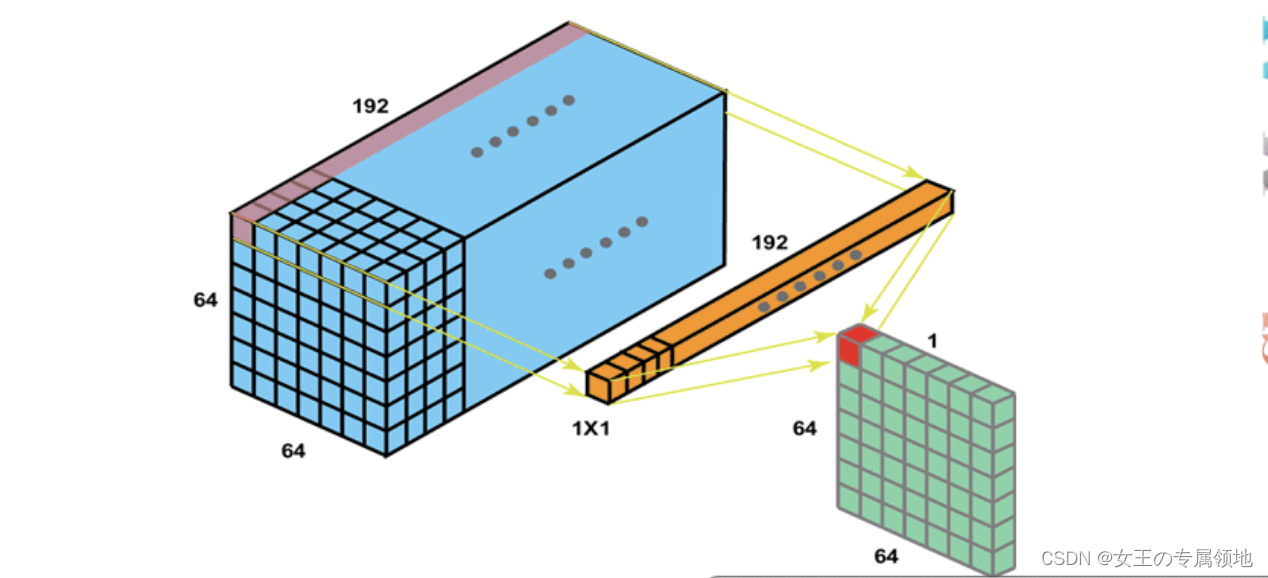
-
扩张(空洞)卷积:有效扩大感受野。(左:普通;右:空洞)
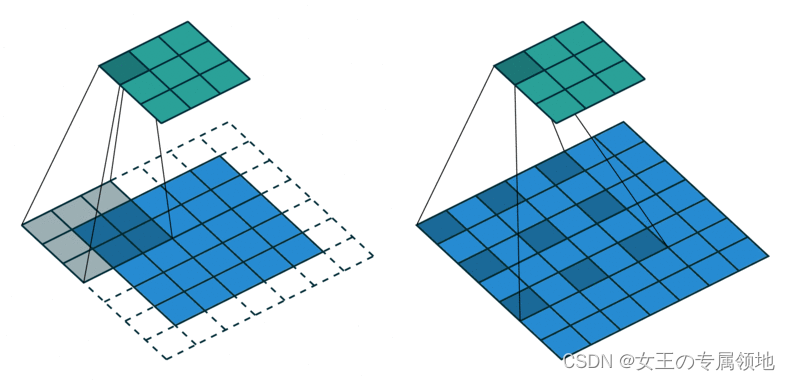
-
2. 池化层(Pooling Layer,POOL Layer)
通常在连续的卷积层之间会周期性地插入一个池化层。作用是逐渐降低数据体的空间(宽、高)尺寸,这样的话就能减少网络中参数的数量,使得计算资源耗费变少,也能有效控制过拟合。池化层也不用零填充,并且池化滤波器间一般没有重叠,步长等于滤波器尺寸。
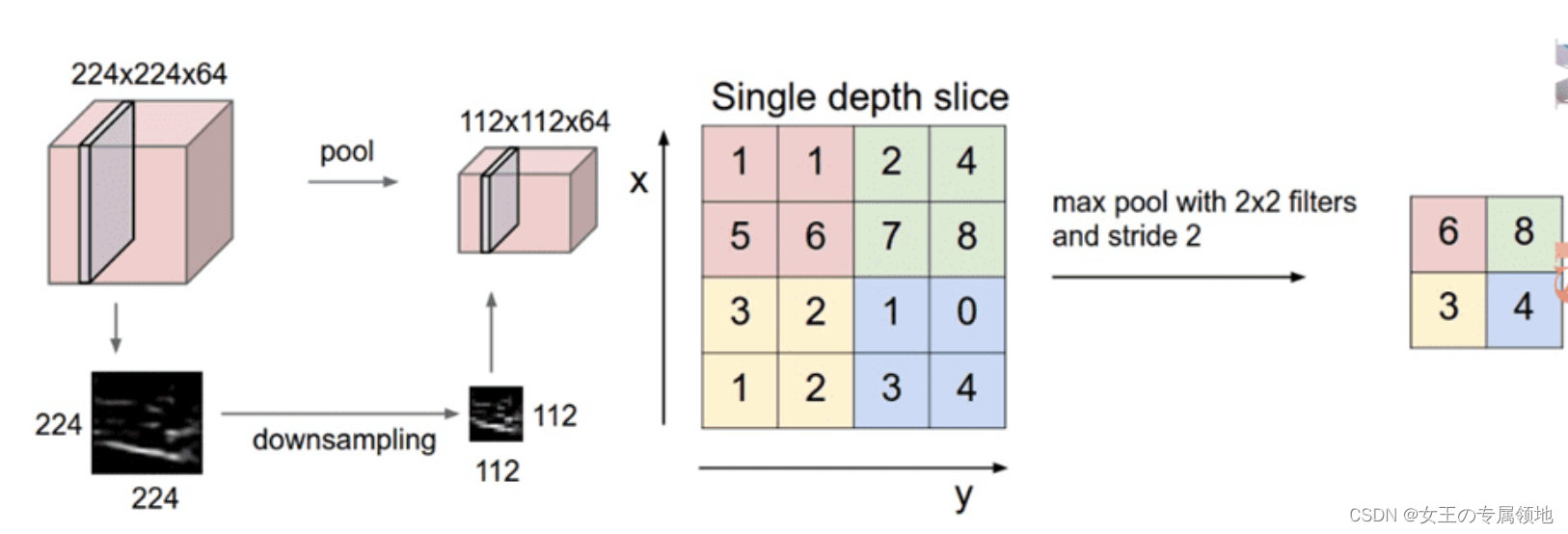
- 池化方式:最大池化(max pooling)、平均池化(average pooling)、 L2 范式池化(L2-norm pooling)
- 输出尺寸:

- 反向传播
m a x ( x , y ) max(x,y) max(x,y)函数的反向传播可以简单理解为将梯度只沿最大的数回传。> 在前向传播经过池化层的时候,通常会把池中最大元素的索引记录下来(有时这个也叫作道岔switches),这样在反向传播的时候梯度路由就很高效。
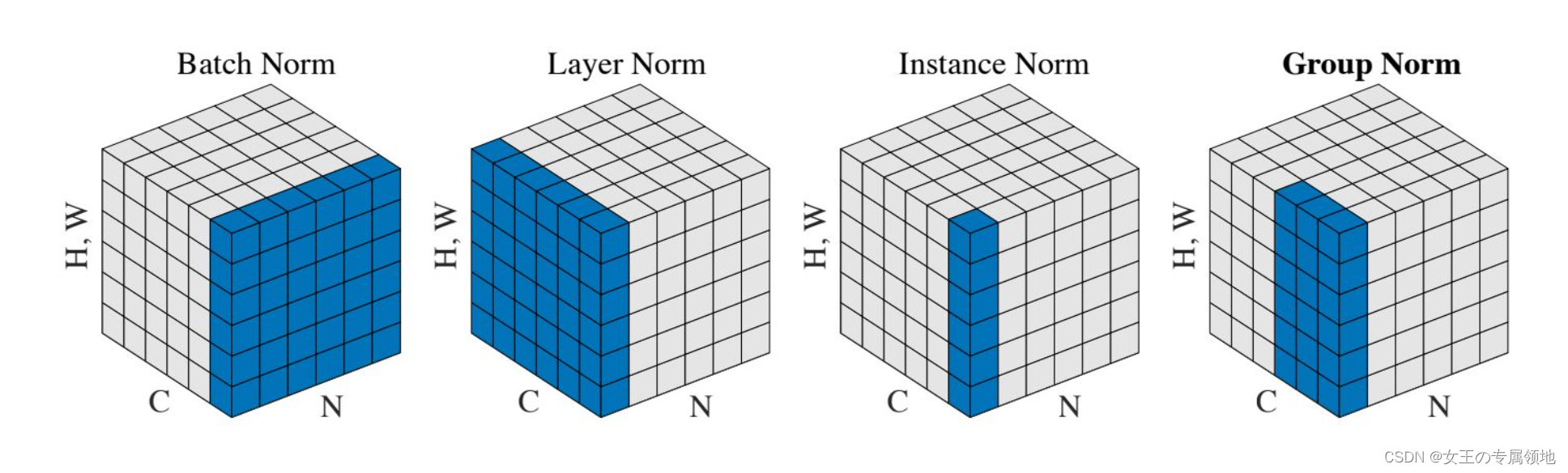
3. 归一化层(Normalization Layer)
在卷积神经网络的结构中,提出了一些归一化层的概念,想法是为了实现在生物大脑中观测到的抑制机制。但是这些层渐渐都不再流行,因为实践证明它们的效果即使存在,也是极其有限的。
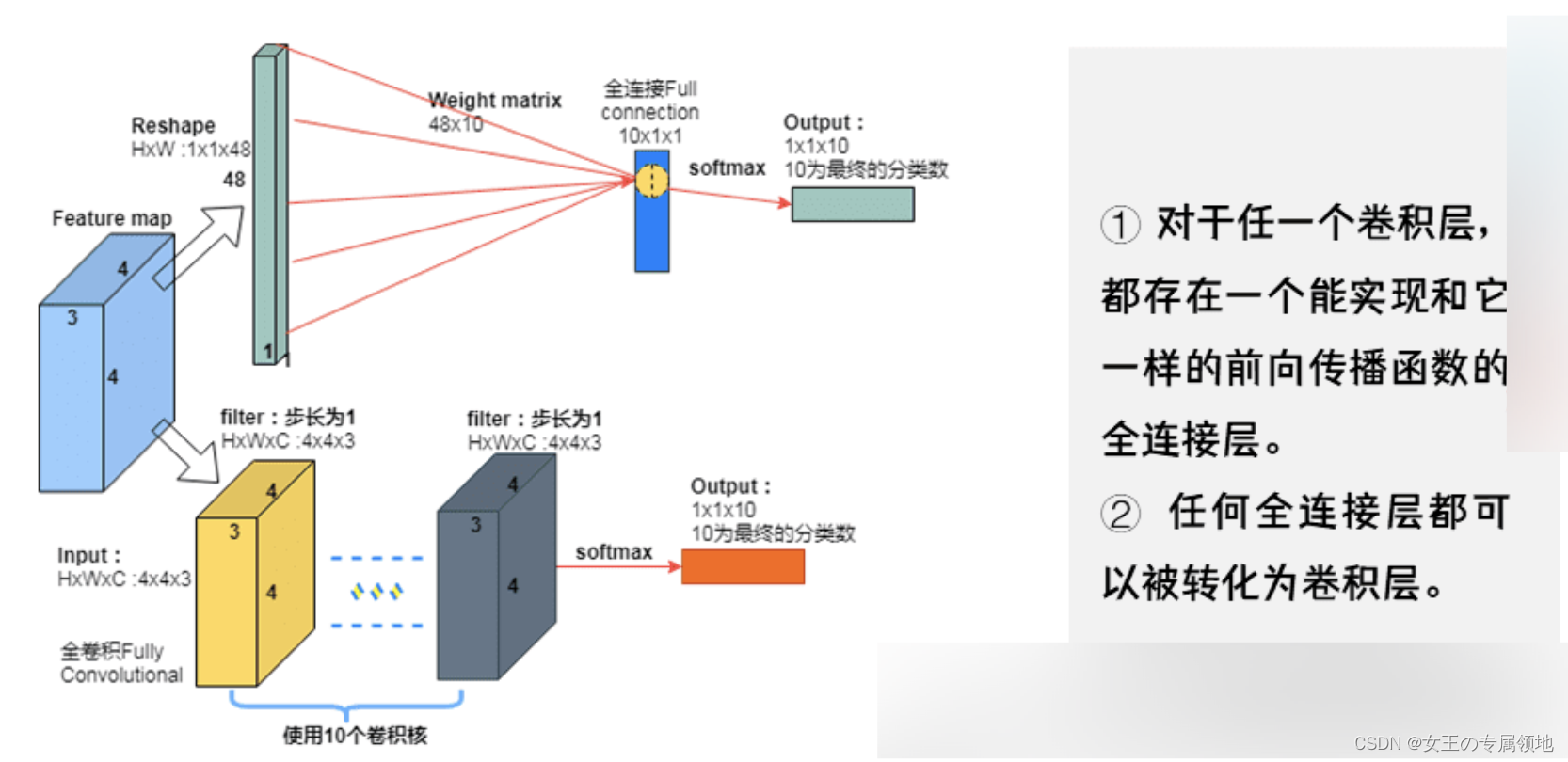
4. 全连接层(Fully-connected Layer,FC Layer)
神经元对于前一层中的所有激活数据是全连接的,这个和常规神经网络中一样,通常会把前一层数组拉成一个向量,与W的每个行向量进行点积,得到每一类的分数。
最后一个池化层输出的结果是数据经过整个网络累计得到的,前几个卷积层可能检测一些比较简单的特征比如边缘,得到边缘图后输入到下一个卷积层,然后进行更复杂的检测,这样层层下来,最后一层的结果可以看成是一组符合模板的激活情况,比较大的值表明之前的所有检测结果都比较大,激活程度高,这样就汇聚了大量的信息。
虽然输出的数据比较简单,但却是非常复杂的滤波器(或特征)激活后的情况,特征在卷积核中体现,所以输出的激活图看起来就会很简单,但是这个激活图却能说明复杂特征的激活程度,用来评分是非常合理的。
3.4 常见结构
卷积神经网络通常是由三种层构成:卷积层,池化层和全连接层(简称FC)。ReLU 激活函数也应该算是一层,它逐元素地进行激活函数操作。
卷积神经网络最常见的形式就是将一些卷积层和 ReLU 层放在一起,其后紧跟池化层,然后重复如此直到图像在空间上被缩小到一个足够小的尺寸,在某个地方过渡成成全连接层也较为常见。最后的全连接层得到输出,比如分类评分等。
换句话说,最常见的卷积神经网络结构如下:
INPUT → [[CONV → RELU]*N → POOL?]*M → [FC → RELU]*K → FC
其中 * 指的是重复次数,POOL? 指的是一个可选的池化层。其中 N>1(通常N≤3),M≥0,K≥0(通常K<3).
🔥经验:几个小滤波器卷积层的组合比一个大滤波器卷积层好。
四、常见神经网络
参看:https://www.showmeai.tech/article-detail/222
这里不会一个一个复习了,之前研究过,直接带过!
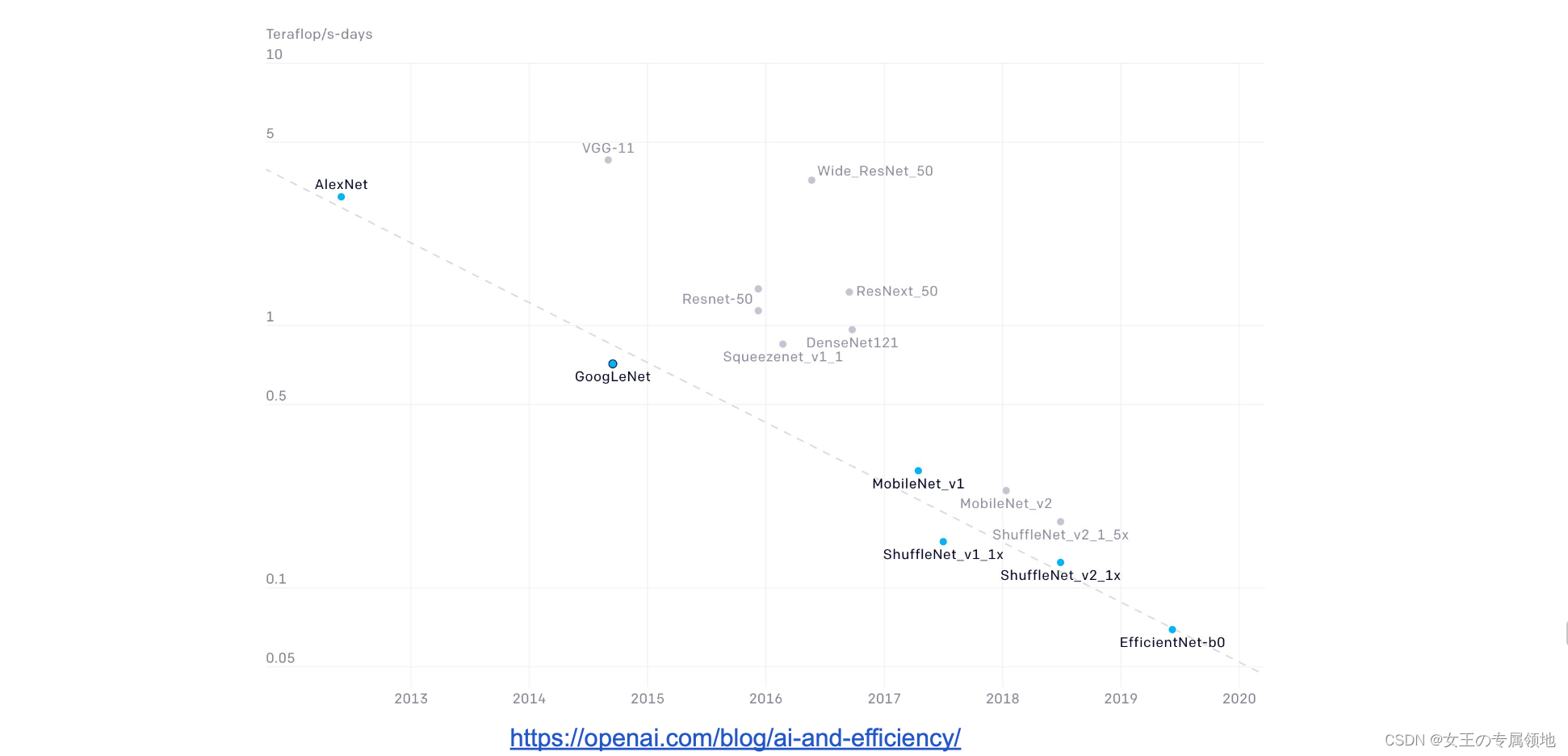
AlexNet 表明,可以使用 CNN 来训练计算机视觉模型。
ZFNet 和 VGG 表明,更大的网络效果更好
GoogLeNet 是最早使用 1x1 瓶颈卷积和全局平均池而不是 FC 层来提高效率的网络之一
ResNet 向我们展示了如何训练深度极高的网络
- 仅受 GPU 和内存限制!
- 随着网络规模的扩大,收益也在减少
ResNet 之后: CNN 优于人类指标,重点转向高效网络:
- 大量针对移动设备的微型网络: MobileNet、ShuffleNet 神经架构搜索现在可以自动进行架构设计。
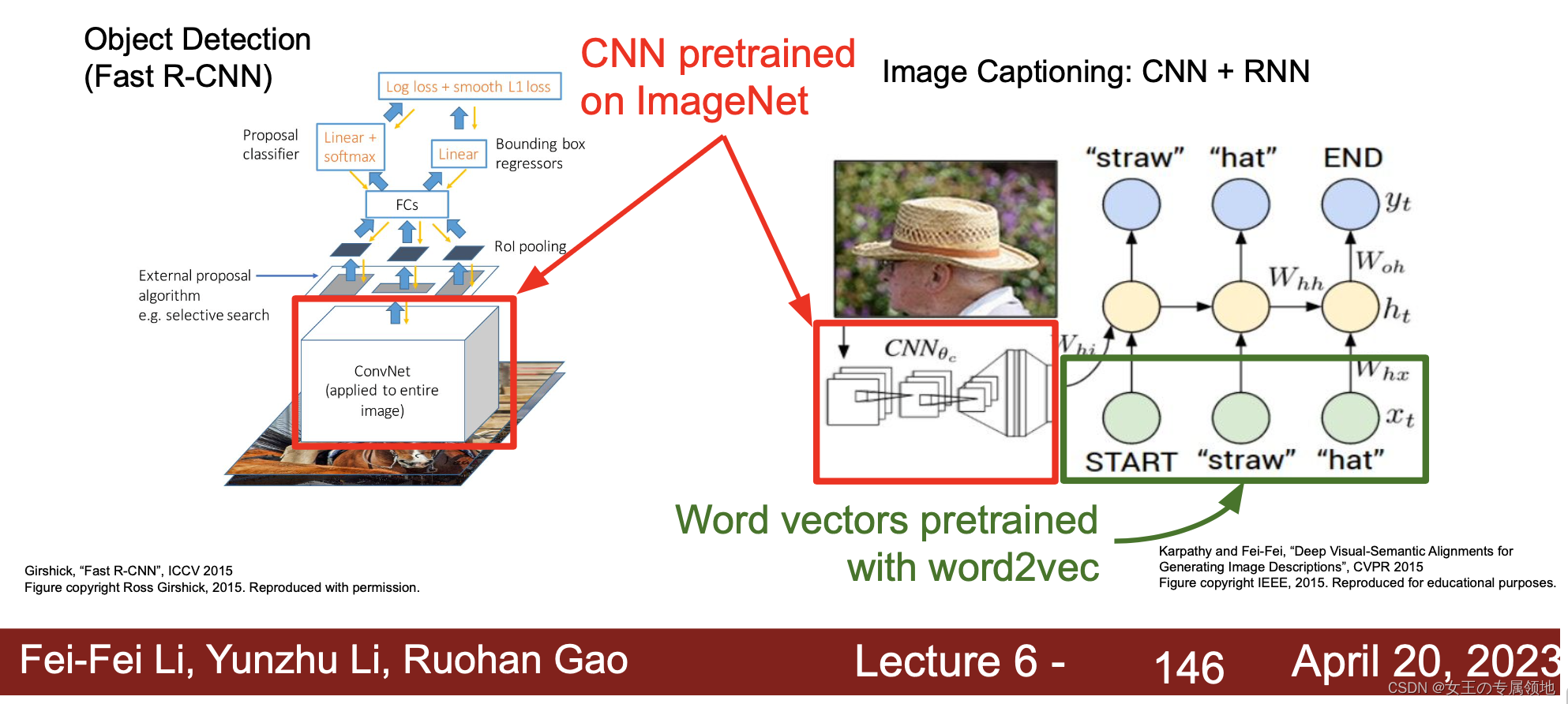
五、迁移学习
概念:基于新的数据微调未冻结的层。
计算机视觉是一个经常用到迁移学习的领域。在搭建计算机视觉的应用时,相比于从头训练权重,下载别人已经训练好的网络结构的权重,用其做预训练模型,然后转换到自己感兴趣的任务上,有助于加速开发。
对于类似前面提到的 VGG / ResNet / Inception 等训练好的卷积神经网络,可以冻结住所有层,只训练针对当前任务添加的 Softmax 分类层参数即可。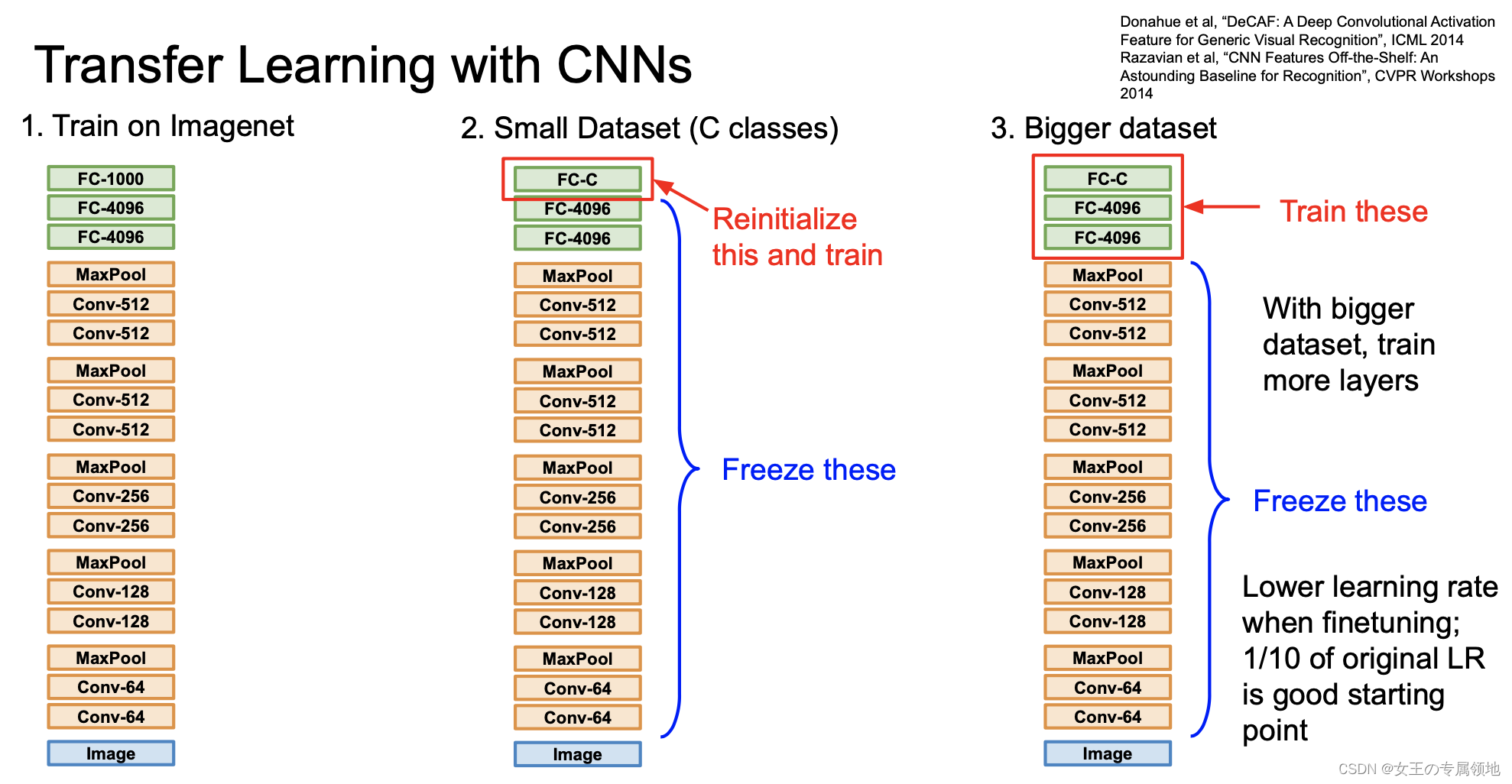
大多数深度学习框架都允许用户指定是否训练特定层的权重。冻结的层由于不需要改变和训练,可以看作一个固定函数。可以将这个固定函数存入硬盘,以便后续使用,而不必每次再使用训练集进行训练了。这个做法适用于小数据集场景。
如果你有一个更大的数据集,应该冻结更少的层,然后训练后面的层。越多的数据意味着冻结越少的层,训练更多的层。如果有一个极大的数据集,你可以将开源的网络和它的权重整个当作初始化 (代替随机初始化),然后训练整个网络。
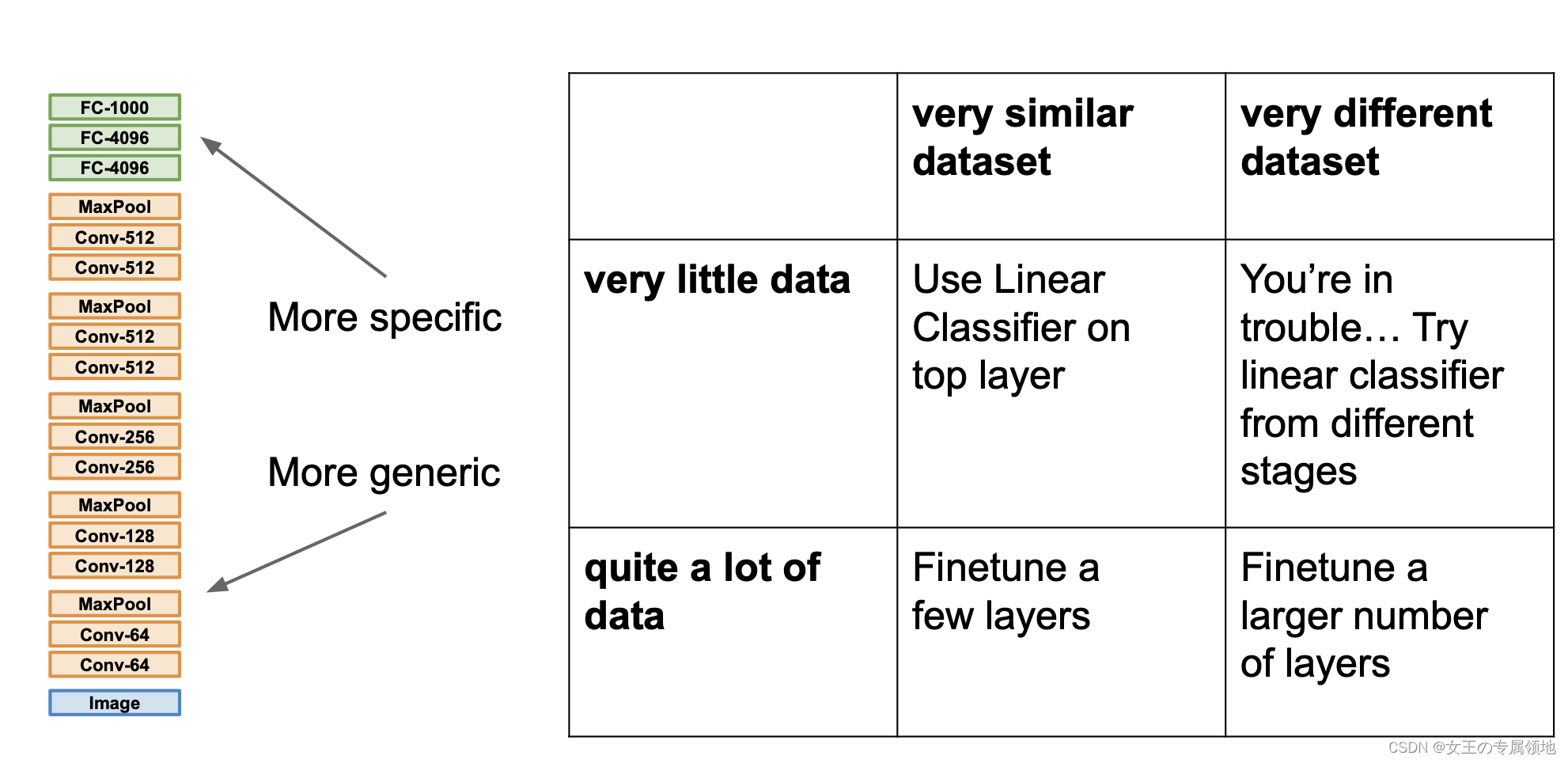
案例:
六、参考资料
- 🔥强推🔥ConvNetJS CIFAR-10 demo 可视化整个网络的训练过程以及中间产物