import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.decomposition import PCA # 主成分分析
from sklearn.preprocessing import LabelEncoder, StandardScaler # 类别标签编码,标准化处理
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score # 分类报告,正确率
import seaborn as snswdbc = pd.read_csv("breast+cancer+wisconsin+diagnostic/wdbc.data", header=None)
X, y = wdbc.loc[:, 2:].values, wdbc.loc[:, 1] # 提取特征数据和样本标签集
X = StandardScaler().fit_transform(X) # 对样本特征数据进行标准化
lab_en = LabelEncoder() # 对目标值进行编码,创建对象
y = lab_en.fit_transform(y) # 拟合和转换
lab_en.classes_, lab_en.transform(["B", "M"])
pca = PCA(n_components=6).fit(X) # 选取6个主成分, 30维-->6维,信息损失了约11%
X_pca = pca.transform(X)
def bootstrapping(m):"""自助法:param m::return:"""bootstrap = [] # 存储每次采样的样本索引编号for i in range(m):bootstrap.append(np.random.randint(0, m, 1)) # 随机产生一个样本的索引编号return np.asarray(bootstrap).reshape(-1)print("样本总体正例与反例的比:%d : %d = %.2f" % (len(y[y == 0]), len(y[y == 1]), len(y[y == 0])/len(y[y == 1])))n_samples = X_pca.shape[0] # 样本量
ratio_bs = [] # 存储每次未划分到训练集中的样本比例
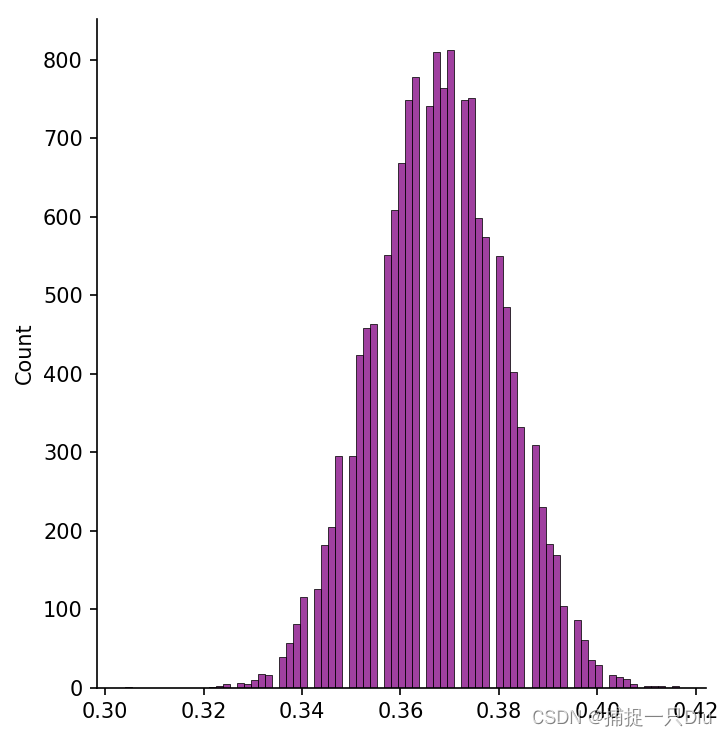
for i in range(15000):train_idx = bootstrapping(n_samples) # 一次自助采样获得训练集样本索引idx_all = np.linspace(0, n_samples - 1, n_samples, dtype=np.int64) # 总体样本的索引编号test_idx = np.setdiff1d(idx_all, train_idx) # 测试样本的索引编号ratio_bs.append(len(test_idx) / n_samples) # 测试样本占所有样本的比例y_train = y[train_idx] #其中一次自助采样后的训练样本目标集
print("抽样后,正例与反例的比例:%.5f" % (len(y_train[y_train == 0]) / len(y_train[y_train == 1])))
print("自主采样后,未出现在训练集中的数据比例:%.5f" % np.mean(ratio_bs)) # 15000次自助采样的均值sns.displot(ratio_bs, kind="hist", color="purple")
plt.show()X_train, y_train = X_pca[train_idx, :], y[train_idx]
X_test, y_test = X_pca[train_idx, :], y[train_idx]KNeighborsClassifier()
knn = KNeighborsClassifier(n_neighbors=9)
knn.fit(X_train, y_train)
y_test_pred = knn.predict(X_test)
print("Test score is %.5f" % accuracy_score(y_test, y_test_pred))





)

![openlayers [七] 地图控件controls详解](http://pic.xiahunao.cn/openlayers [七] 地图控件controls详解)

算法的全称是什么,分别是什么意思,分别是用来干什么的?)
层的实现)

![[M数学] lc2171. 拿出最少数目的魔法豆(数学+前缀和)](http://pic.xiahunao.cn/[M数学] lc2171. 拿出最少数目的魔法豆(数学+前缀和))
)





