时态表(Temporal Table)
文章目录
- 时态表(Temporal Table)
- 数据库时态表的实现逻辑
- 时态表的实现原理
- 时态表的查询实现
- 时态表的意义
- Flink中的时态表
- 设计初衷
- 产品价格的例子——时态表
- 汇率的例子——普通表
- 声明版本表
- 声明版本视图
- 声明普通表
- 一个完整的例子
- 测试数据
- 代码实现
- 测试结果
- 总结
数据库时态表的实现逻辑
这里我们需要注意一下的是虽然我们介绍的是Flink 的 Temporal Table 但是这个概念最早是在数据库中提出的
在ANSI-SQL 2011 中提出了Temporal 的概念,Oracle,SQLServer,DB2等大的数据库厂商也先后实现了这个标准。Temporal Table记录了历史上任何时间点所有的数据改动,Temporal Table的工作流程如下:
- 创建时态表
- 执行DML 操作
- 执行基于时态表的查询
这里我们先介绍一下什么是时态表,时态表(Temporal Table)是一张随时间变化的表,其实这是句废话,因为所有的表都随着时间变化,那时态表的意义在那里呢,时态表有一个功能就是可以返回当时表的状态(数据),也就是说我们可以查询任意时间点的数据,有点类似快照,只不过这个快照是根据我们提供的时间筛选出来的,也就是说时态表做到是时间旅行。
Temporal table 相比普通的表会做多一个 history table, 把所有修改/删除的结果存起来, 所以任何数据都不会丢失,要找回也比较容易,有点类似WAL 日志,但是不是,WAL存储的是操作本身,Temporal table 存储的是操作结果,和普通的表很像,只不过是每一条记录提供了一个有效期的状态
版本: 时态表可以划分成一系列带版本的表快照集合,表快照中的版本代表了快照中所有记录的有效区间,有效区间的开始时间和结束时间可以通过用户指定,根据时态表是否可以追踪自身的历史版本与否,时态表可以分为 版本表 和 普通表。
版本表: 如果时态表中的记录可以追踪和并访问它的历史版本,这种表我们称之为版本表,来自数据库的 changelog 可以定义成版本表。
普通表: 如果时态表中的记录仅仅可以追踪并和它的最新版本,这种表我们称之为普通表,来自数据库 或 HBase 的表可以定义成普通表。
时态表的实现原理
时态表是有一对表而不是一个表,当前表和历史表。这些表都包含2个额外的datetime2字段用来定义每个行的可用期限:
- 期限开始列:系统把行的开始时间记录在这个列上,称为SysStartTime
- 期限结束列:系统把行的结束时间记录在这个列上,称为SysEndTime
当前表包含了每个行的当前值。历史表包含每个行的之前的只,starttime,endtime表示行的可用期限。
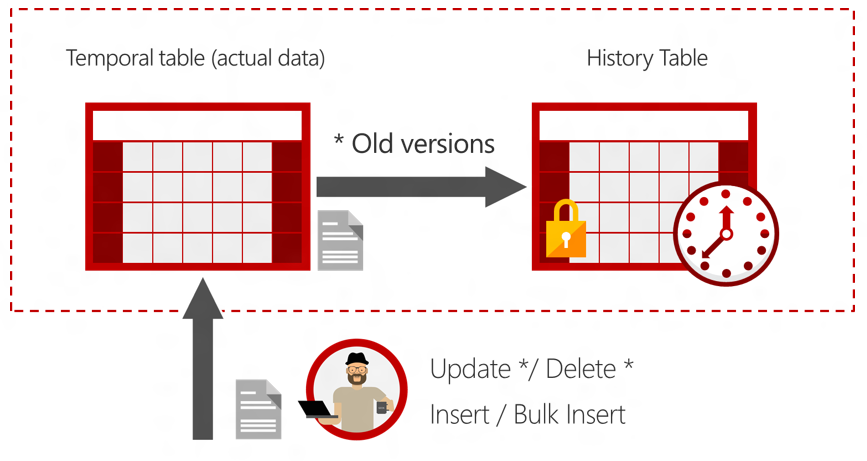
对于每个操作时态表都进行相应的操作
- INSERT:对于一个insert,系统会设置SysStartTime列为当前事务的开始时间,SysEndTime为最大的值9999-12-31
- UPDATE:对于update,系统会报之前的行保存到历史表并且设置SysEndTime为当前事务的启动时间。行被关闭,这个期限就是这个行的可用期限。这个行在当前表上的值被修改,那么SysStartTime被设置为当前事务的开始时间。SysEndTime被设置为最大时间。
- DELETE:对于删除,系统把之前的行保存到history表,并且设置SysEndtime为事务的开始时间。标记行关闭,期限记录表示行的可用期限。当前表中行被删除。当前的查询不会被查到当前行。只有带时间的查询,或者直接查询历史表才能查到这个行。
- MERGE:对于MERGE涉及到3个操作INSERT,UPDATE,DELETE,根据操作的不同做不同的记录(有的数据库没有这个操作)
时态表的查询实现
可以使用select from的for system_time子句来查询当前表和历史表的数据。其实这里我们可以看到就涉及到一个路由的问题就是这个查询事发生在当前表和历史表上的
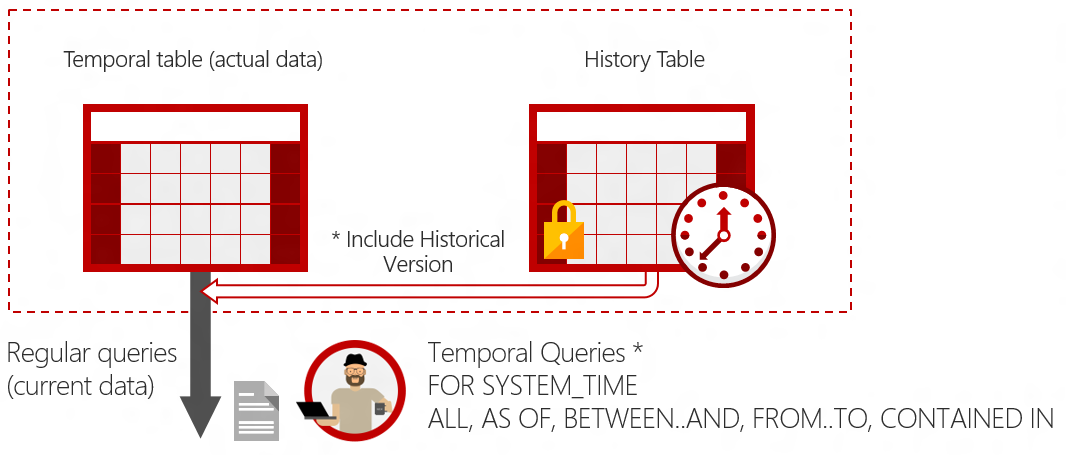
SELECT * FROM Employee FOR SYSTEM_TIME BETWEEN '2014-01-01 00:00:00.0000000' AND '2015-01-01 00:00:00.0000000' WHERE EmployeeID = 1000 ORDER BY ValidFrom ;
FOR SYSTEM_TIME会过滤掉SysStartTime=SysEndTime的数据。这些行在同一个事务里面操作了同一行儿产生。只能通过查询历史表才能返回
关于SYSTEM_TIME过滤
| 表达式 | 符合条件的行 | Description |
|---|---|---|
| AS OF<date_time> | SysStartTime <= date_time AND SysEndTime > date_time | 返回一个表,其行中包含过去指定时间点的实际(当前)值。 在内部,临时表及其历史记录表之间将进行联合,然后筛选结果以返回在 <date_time> 参数指定的时间点有效的行中的值。 如果 system_start_time_column_name 值小于或等于 <date_time> 参数值,并且 system_end_time_column_name 值大于 <date_time> 参数值,则此行的值视为有效。 |
| FROM<start_date_time>TO<end_date_time> | SysStartTime < end_date_time AND SysEndTime > start_date_time | 返回一个表,其中包含在指定的时间范围内保持活动状态的所有行版本的值,不管这些版本是在 FROM 自变量的 <start_date_time> 参数之前开始活动,还是在 TO 自变量的 <end_date_time> 参数值之后停止活动。 在内部,将在临时表及其历史记录表之间进行联合,然后筛选结果,以返回在指定时间范围内任意时间保持活动状态的所有行版本的值。 正好在 FROM 终结点定义的下限时间停止活动的行将被排除,正好在 TO 终结点定义的上限时间开始活动的记录也将被排除。 |
| BETWEEN<start_date_time>AND<end_date_time> | SysStartTime <= end_date_time AND SysEndTime > start_date_time | 与上面的 FOR SYSTEM_TIME FROM <start_date_time>TO<end_date_time> 描述相同,不过,返回的行表包括在 <end_date_time> 终结点定义的上限时间激活的行。 |
| CONTAINED IN (<start_date_time> , <end_date_time>) | SysStartTime >= start_date_time AND SysEndTime <= end_date_time | 返回一个表,其中包含在 CONTAINED IN 参数的两个日期时间值定义的时间范围内打开和关闭的所有行版本的值。 正好在下限时间激活的记录,或者在上限时间停止活动的行将包括在内。 |
| ALL | 所有行 | 返回属于当前表和历史记录表的行的联合。 |
时态表的意义
- 审核所有数据更改并在必要时执行数据取证
- 重建过去任何时间的数据状态
- 计算一段时间内的趋势
- 为决策支持应用程序维护缓慢变化的维度
- 从意外的数据更改和应用程序错误中恢复
时态表是一种用户表,旨在保存数据更改的完整历史记录,从而实现轻松的时间点分析。这种类型的时态又被称为系统版本的时态表,因为每一行的有效期都由系统(即数据库引擎)管理。
Flink中的时态表
时态表中的每条记录都关联了一个或多个时间段,所有的 Flink 表都是动态,这里的动态和动态表的概念一致,就是说数据是不断变化更新的,只不过时态表在动态表的基础上提供了更加强大的功能时间旅行——历史数据回溯。
Flink 使用主键约束和事件时间来定义一张时态表,我们有时候也称之为版本表,对应的历史表也称为版本试图
设计初衷
这里我们看一下Flink中为什么要引入时态表,因为我们的数据是实时进来的,而且我们的维度表是会发生变化的,所以对于实时进来的数据我们希望在关联的时候关联上的是当时的维度数据,而不是当前的
产品价格的例子——时态表
以订单流关联产品表这个场景举例,orders 表包含了来自 Kafka 的实时订单流,product_changelog 表来自数据库表 products 的 changelog , 产品的价格在数据库表 products 中是随时间实时变化的。
SELECT * FROM product_changelog;(changelog kind) update_time product_id product_name price
================= =========== ========== ============ =====
+(INSERT) 00:01:00 p_001 scooter 11.11
+(INSERT) 00:02:00 p_002 basketball 23.11
-(UPDATE_BEFORE) 12:00:00 p_001 scooter 11.11
+(UPDATE_AFTER) 12:00:00 p_001 scooter 12.99
-(UPDATE_BEFORE) 12:00:00 p_002 basketball 23.11
+(UPDATE_AFTER) 12:00:00 p_002 basketball 19.99
-(DELETE) 18:00:00 p_001 scooter 12.99
表 product_changelog 表示数据库表 products不断增长的 changelog, 比如,产品 scooter 在时间点 00:01:00的初始价格是 11.11, 在 12:00:00 的时候涨价到了 12.99, 在 18:00:00 的时候这条产品价格记录被删除。
如果我们想输出 product_changelog 表在 10:00:00 对应的版本,表的内容如下所示:
update_time product_id product_name price
=========== ========== ============ =====
00:01:00 p_001 scooter 11.11
00:02:00 p_002 basketball 23.11
如果我们想输出 product_changelog 表在 13:00:00 对应的版本,表的内容如下所示:
update_time product_id product_name price
=========== ========== ============ =====
12:00:00 p_001 scooter 12.99
12:00:00 p_002 basketball 19.99
上述例子中,products 表的版本是通过 update_time 和 product_id 进行追踪的,product_id 对应 product_changelog 表的主键,update_time 对应事件时间。
汇率的例子——普通表
另一方面,某些用户案列需要连接变化的维表,该表是外部数据库表。
假设 LatestRates 是一个物化的最新汇率表 (比如:一张 HBase 表),LatestRates 总是表示 HBase 表 Rates 的最新内容。
我们在 10:15:00 时查询到的内容如下所示:
10:15:00 > SELECT * FROM LatestRates;currency rate
========= ====
US Dollar 102
Euro 114
Yen 1
我们在 11:00:00 时查询到的内容如下所示:
11:00:00 > SELECT * FROM LatestRates;currency rate
========= ====
US Dollar 102
Euro 116
Yen 1
其实我们可以看到我们的汇率是实时变化的,如果是普通表的话我们永远只能查询当前最新的状态,无法获取历史的数据情况
声明版本表
在 Flink 中,定义了主键约束和事件时间属性的表就是版本表。
-- 定义一张版本表
CREATE TABLE product_changelog (product_id STRING,product_name STRING,product_price DECIMAL(10, 4),update_time TIMESTAMP(3) METADATA FROM 'value.source.timestamp' VIRTUAL,PRIMARY KEY(product_id) NOT ENFORCED, -- (1) 定义主键约束WATERMARK FOR update_time AS update_time -- (2) 通过 watermark 定义事件时间
) WITH ('connector' = 'kafka','topic' = 'products','scan.startup.mode' = 'earliest-offset','properties.bootstrap.servers' = 'localhost:9092','value.format' = 'debezium-json'
);
行 (1) 为表 product_changelog 定义了主键, 行 (2) 把 update_time 定义为表 product_changelog 的事件时间,因此 product_changelog 是一张版本表。
注意: METADATA FROM 'value.source.timestamp' VIRTUAL 语法的意思是从每条 changelog 中抽取 changelog 对应的数据库表中操作的执行时间,强烈推荐使用数据库表中操作的 执行时间作为事件时间 ,否则通过时间抽取的版本可能和数据库中的版本不匹配。
声明版本视图
Flink 也支持定义版本视图只要一个视图包含主键和事件时间便是一个版本视图。
假设我们有表 RatesHistory 如下所示:
-- 定义一张 append-only 表
CREATE TABLE RatesHistory (currency_time TIMESTAMP(3),currency STRING,rate DECIMAL(38, 10),WATERMARK FOR currency_time AS currency_time -- 定义事件时间
) WITH ('connector' = 'kafka','topic' = 'rates','scan.startup.mode' = 'earliest-offset','properties.bootstrap.servers' = 'localhost:9092','format' = 'json' -- 普通的 append-only 流
)
表 RatesHistory 代表一个兑换日元货币汇率表(日元汇率为1),该表是不断增长的 append-only 表。 例如,欧元 兑换 日元 从 09:00:00 到 10:45:00 的汇率为 114。从 10:45:00 到 11:15:00 的汇率为 116。
SELECT * FROM RatesHistory;currency_time currency rate
============= ========= ====
09:00:00 US Dollar 102
09:00:00 Euro 114
09:00:00 Yen 1
10:45:00 Euro 116
11:15:00 Euro 119
11:49:00 Pounds 108
为了在 RatesHistory 上定义版本表,Flink 支持通过去重查询定义版本视图, 去重查询可以产出一个有序的 changelog 流,去重查询能够推断主键并保留原始数据流的事件时间属性。
CREATE VIEW versioned_rates AS
SELECT currency, rate, currency_time -- (1) `currency_time` 保留了事件时间FROM (SELECT *,ROW_NUMBER() OVER (PARTITION BY currency -- (2) `currency` 是去重 query 的 unique key,可以作为主键ORDER BY currency_time DESC) AS rowNum FROM RatesHistory )
WHERE rowNum = 1; -- 视图 `versioned_rates` 将会产出如下的 changelog:(changelog kind) currency_time currency rate
================ ============= ========= ====
+(INSERT) 09:00:00 US Dollar 102
+(INSERT) 09:00:00 Euro 114
+(INSERT) 09:00:00 Yen 1
+(UPDATE_AFTER) 10:45:00 Euro 116
+(UPDATE_AFTER) 11:15:00 Euro 119
+(INSERT) 11:49:00 Pounds 108
行 (1) 保留了事件时间作为视图 versioned_rates 的事件时间,行 (2) 使得视图 versioned_rates 有了主键, 因此视图 versioned_rates 是一个版本视图。
视图中的去重 query 会被 Flink 优化并高效地产出 changelog stream, 产出的 changelog 保留了主键约束和事件时间。
如果我们想输出 versioned_rates 表在 11:00:00 对应的版本,表的内容如下所示:
currency_time currency rate
============= ========== ====
09:00:00 US Dollar 102
09:00:00 Yen 1
10:45:00 Euro 116
如果我们想输出 versioned_rates 表在 12:00:00 对应的版本,表的内容如下所示:
currency_time currency rate
============= ========== ====
09:00:00 US Dollar 102
09:00:00 Yen 1
10:45:00 Euro 119
11:49:00 Pounds 108
声明普通表
普通表的声明和 Flink 建表 DDL 一致,参考 create table 页面获取更多如何建表的信息。
-- 用 DDL 定义一张 HBase 表,然后我们可以在 SQL 中将其当作一张时态表使用
-- 'currency' 列是 HBase 表中的 rowKeyCREATE TABLE LatestRates ( currency STRING, fam1 ROW<rate DOUBLE> ) WITH ( 'connector' = 'hbase-1.4', 'table-name' = 'rates', 'zookeeper.quorum' = 'localhost:2181' );
注意 理论上讲任意都能用作时态表并在基于处理时间的时态表 Join 中使用,但当前支持作为时态表的普通表必须实现接口 LookupableTableSource。接口 LookupableTableSource 的实例只能作为时态表用于基于处理时间的时态 Join 。
一个完整的例子
举个例子,假设你在Mysql中有两张表: browse_event、product_history_info。
- browse_event: 事件表,某个用户在某个时刻浏览了某个商品,以及商品的价值。如下
SELECT * FROM browse_event;+--------+---------------------+-----------+-----------+--------------+
| userID | eventTime | eventType | productID | productPrice |
+--------+---------------------+-----------+-----------+--------------+
| user_1 | 2016-01-01 00:00:00 | browse | product_5 | 20 |
| user_1 | 2016-01-01 00:00:01 | browse | product_5 | 20 |
| user_1 | 2016-01-01 00:00:02 | browse | product_5 | 20 |
| user_1 | 2016-01-01 00:00:03 | browse | product_5 | 20 |
| user_1 | 2016-01-01 00:00:04 | browse | product_5 | 20 |
| user_1 | 2016-01-01 00:00:05 | browse | product_5 | 20 |
| user_1 | 2016-01-01 00:00:06 | browse | product_5 | 20 |
| user_2 | 2016-01-01 00:00:01 | browse | product_3 | 20 |
| user_2 | 2016-01-01 00:00:02 | browse | product_3 | 20 |
| user_2 | 2016-01-01 00:00:05 | browse | product_3 | 20 |
| user_2 | 2016-01-01 00:00:06 | browse | product_3 | 20 |
+--------+---------------------+-----------+-----------+--------------+- product_history_info:商品基础信息表,记录了商品历史以来的基础信息。如下:
SELECT * FROM product_history_info;
+-----------+-------------+-----------------+---------------------+
| productID | productName | productCategory | updatedAt |
+-----------+-------------+-----------------+---------------------+
| product_5 | name50 | category50 | 2016-01-01 00:00:00 |
| product_5 | name52 | category52 | 2016-01-01 00:00:02 |
| product_5 | name55 | category55 | 2016-01-01 00:00:05 |
| product_3 | name32 | category32 | 2016-01-01 00:00:02 |
| product_3 | name35 | category35 | 2016-01-01 00:00:05 |
+-----------+-------------+-----------------+---------------------+此刻,你想获取事件发生时,对应的最新的商品基础信息。可能需要借助以下SQL实现:
SELECT l.userID,l.eventTime,l.eventType,l.productID,l.productPrice,r.productID,r.productName,r.productCategory,r.updatedAt
FROMbrowse_event AS l,product_history_info AS r
WHERE r.productID = l.productIDAND r.updatedAt = (SELECT max(updatedAt)FROM product_history_info AS r2WHERE r2.productID = l.productIDAND r2.updatedAt <= l.eventTime
)// 结果
+--------+---------------------+-----------+-----------+--------------+-----------+-------------+-----------------+---------------------+
| userID | eventTime | eventType | productID | productPrice | productID | productName | productCategory | updatedAt |
+--------+---------------------+-----------+-----------+--------------+-----------+-------------+-----------------+---------------------+
| user_1 | 2016-01-01 00:00:00 | browse | product_5 | 20 | product_5 | name50 | category50 | 2016-01-01 00:00:00 |
| user_1 | 2016-01-01 00:00:01 | browse | product_5 | 20 | product_5 | name50 | category50 | 2016-01-01 00:00:00 |
| user_1 | 2016-01-01 00:00:02 | browse | product_5 | 20 | product_5 | name52 | category52 | 2016-01-01 00:00:02 |
| user_1 | 2016-01-01 00:00:03 | browse | product_5 | 20 | product_5 | name52 | category52 | 2016-01-01 00:00:02 |
| user_1 | 2016-01-01 00:00:04 | browse | product_5 | 20 | product_5 | name52 | category52 | 2016-01-01 00:00:02 |
| user_1 | 2016-01-01 00:00:05 | browse | product_5 | 20 | product_5 | name55 | category55 | 2016-01-01 00:00:05 |
| user_1 | 2016-01-01 00:00:06 | browse | product_5 | 20 | product_5 | name55 | category55 | 2016-01-01 00:00:05 |
| user_2 | 2016-01-01 00:00:02 | browse | product_3 | 20 | product_3 | name32 | category32 | 2016-01-01 00:00:02 |
| user_2 | 2016-01-01 00:00:05 | browse | product_3 | 20 | product_3 | name35 | category35 | 2016-01-01 00:00:05 |
| user_2 | 2016-01-01 00:00:06 | browse | product_3 | 20 | product_3 | name35 | category35 | 2016-01-01 00:00:05 |
+--------+---------------------+-----------+-----------+--------------+-----------+-------------+-----------------+---------------------+Temporal Table可以简化和加速此类查询,并减少对状态的使用。Temporal Table是将一个Append-Only表(如上product_history_info)中追加的行,根据设置的主键和时间(如上productID、updatedAt),解释成Chanlog,并在特定时间提供数据的版本。
测试数据
自己造的测试数据,browse log和product history info,如下:
// browse log
{"userID": "user_1", "eventTime": "2016-01-01 00:00:00", "eventType": "browse", "productID": "product_5", "productPrice": 20}
{"userID": "user_1", "eventTime": "2016-01-01 00:00:01", "eventType": "browse", "productID": "product_5", "productPrice": 20}
{"userID": "user_1", "eventTime": "2016-01-01 00:00:02", "eventType": "browse", "productID": "product_5", "productPrice": 20}
{"userID": "user_1", "eventTime": "2016-01-01 00:00:03", "eventType": "browse", "productID": "product_5", "productPrice": 20}
{"userID": "user_1", "eventTime": "2016-01-01 00:00:04", "eventType": "browse", "productID": "product_5", "productPrice": 20}
{"userID": "user_1", "eventTime": "2016-01-01 00:00:05", "eventType": "browse", "productID": "product_5", "productPrice": 20}
{"userID": "user_1", "eventTime": "2016-01-01 00:00:06", "eventType": "browse", "productID": "product_5", "productPrice": 20}
{"userID": "user_2", "eventTime": "2016-01-01 00:00:01", "eventType": "browse", "productID": "product_3", "productPrice": 20}
{"userID": "user_2", "eventTime": "2016-01-01 00:00:02", "eventType": "browse", "productID": "product_3", "productPrice": 20}
{"userID": "user_2", "eventTime": "2016-01-01 00:00:05", "eventType": "browse", "productID": "product_3", "productPrice": 20}
{"userID": "user_2", "eventTime": "2016-01-01 00:00:06", "eventType": "browse", "productID": "product_3", "productPrice": 20}// product history info
{"productID":"product_5","productName":"name50","productCategory":"category50","updatedAt":"2016-01-01 00:00:00"}
{"productID":"product_5","productName":"name52","productCategory":"category52","updatedAt":"2016-01-01 00:00:02"}
{"productID":"product_5","productName":"name55","productCategory":"category55","updatedAt":"2016-01-01 00:00:05"}
{"productID":"product_3","productName":"name32","productCategory":"category32","updatedAt":"2016-01-01 00:00:02"}
{"productID":"product_3","productName":"name35","productCategory":"category35","updatedAt":"2016-01-01 00:00:05"}代码实现
package com.bigdata.flink.tableSqlTemporalTable;import com.alibaba.fastjson.JSON;
import com.bigdata.flink.beans.table.ProductInfo;
import com.bigdata.flink.beans.table.UserBrowseLog;
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TemporalTableFunction;
import org.apache.flink.types.Row;
import org.apache.flink.util.Collector;import java.time.LocalDateTime;
import java.time.OffsetDateTime;
import java.time.ZoneOffset;
import java.time.format.DateTimeFormatter;
import java.util.Properties;/*** Summary:* 时态表(Temporal Table)*/
@Slf4j
public class Test {public static void main(String[] args) throws Exception{args=new String[]{"--application","flink/src/main/java/com/bigdata/flink/tableSqlTemporalTable/application.properties"};//1、解析命令行参数ParameterTool fromArgs = ParameterTool.fromArgs(args);ParameterTool parameterTool = ParameterTool.fromPropertiesFile(fromArgs.getRequired("application"));//browse logString kafkaBootstrapServers = parameterTool.getRequired("kafkaBootstrapServers");String browseTopic = parameterTool.getRequired("browseTopic");String browseTopicGroupID = parameterTool.getRequired("browseTopicGroupID");//product history infoString productInfoTopic = parameterTool.getRequired("productHistoryInfoTopic");String productInfoGroupID = parameterTool.getRequired("productHistoryInfoGroupID");//2、设置运行环境StreamExecutionEnvironment streamEnv = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().useBlinkPlanner().build();StreamTableEnvironment tableEnv = StreamTableEnvironment.create(streamEnv, settings);streamEnv.setParallelism(1);//3、注册Kafka数据源//注意: 为了在北京时间和时间戳之间有直观的认识,这里的UserBrowseLog中增加了一个字段eventTimeTimestamp作为eventTime的时间戳Properties browseProperties = new Properties();browseProperties.put("bootstrap.servers",kafkaBootstrapServers);browseProperties.put("group.id",browseTopicGroupID);DataStream<UserBrowseLog> browseStream=streamEnv.addSource(new FlinkKafkaConsumer010<>(browseTopic, new SimpleStringSchema(), browseProperties)).process(new BrowseKafkaProcessFunction()).assignTimestampsAndWatermarks(new BrowseTimestampExtractor(Time.seconds(0)));tableEnv.registerDataStream("browse",browseStream,"userID,eventTime,eventTimeTimestamp,eventType,productID,productPrice,browseRowtime.rowtime");//tableEnv.toAppendStream(tableEnv.scan("browse"),Row.class).print();//4、注册时态表(Temporal Table)//注意: 为了在北京时间和时间戳之间有直观的认识,这里的ProductInfo中增加了一个字段updatedAtTimestamp作为updatedAt的时间戳Properties productInfoProperties = new Properties();productInfoProperties.put("bootstrap.servers",kafkaBootstrapServers);productInfoProperties.put("group.id",productInfoGroupID);DataStream<ProductInfo> productInfoStream=streamEnv.addSource(new FlinkKafkaConsumer010<>(productInfoTopic, new SimpleStringSchema(), productInfoProperties)).process(new ProductInfoProcessFunction()).assignTimestampsAndWatermarks(new ProductInfoTimestampExtractor(Time.seconds(0)));tableEnv.registerDataStream("productInfo",productInfoStream, "productID,productName,productCategory,updatedAt,updatedAtTimestamp,productInfoRowtime.rowtime");//设置Temporal Table的时间属性和主键TemporalTableFunction productInfo = tableEnv.scan("productInfo").createTemporalTableFunction("productInfoRowtime", "productID");//注册TableFunctiontableEnv.registerFunction("productInfoFunc",productInfo);//tableEnv.toAppendStream(tableEnv.scan("productInfo"),Row.class).print();//5、运行SQLString sql = ""+ "SELECT "+ "browse.userID, "+ "browse.eventTime, "+ "browse.eventTimeTimestamp, "+ "browse.eventType, "+ "browse.productID, "+ "browse.productPrice, "+ "productInfo.productID, "+ "productInfo.productName, "+ "productInfo.productCategory, "+ "productInfo.updatedAt, "+ "productInfo.updatedAtTimestamp "+ "FROM "+ " browse, "+ " LATERAL TABLE (productInfoFunc(browse.browseRowtime)) as productInfo "+ "WHERE "+ " browse.productID=productInfo.productID";Table table = tableEnv.sqlQuery(sql);tableEnv.toAppendStream(table,Row.class).print();//6、开始执行tableEnv.execute(Test.class.getSimpleName());}/*** 解析Kafka数据*/static class BrowseKafkaProcessFunction extends ProcessFunction<String, UserBrowseLog> {@Overridepublic void processElement(String value, Context ctx, Collector<UserBrowseLog> out) throws Exception {try {UserBrowseLog log = JSON.parseObject(value, UserBrowseLog.class);// 增加一个long类型的时间戳// 指定eventTime为yyyy-MM-dd HH:mm:ss格式的北京时间DateTimeFormatter format = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");OffsetDateTime eventTime = LocalDateTime.parse(log.getEventTime(), format).atOffset(ZoneOffset.of("+08:00"));// 转换成毫秒时间戳long eventTimeTimestamp = eventTime.toInstant().toEpochMilli();log.setEventTimeTimestamp(eventTimeTimestamp);out.collect(log);}catch (Exception ex){log.error("解析Kafka数据异常...",ex);}}}/*** 提取时间戳生成水印*/static class BrowseTimestampExtractor extends BoundedOutOfOrdernessTimestampExtractor<UserBrowseLog> {BrowseTimestampExtractor(Time maxOutOfOrderness) {super(maxOutOfOrderness);}@Overridepublic long extractTimestamp(UserBrowseLog element) {return element.getEventTimeTimestamp();}}/*** 解析Kafka数据*/static class ProductInfoProcessFunction extends ProcessFunction<String, ProductInfo> {@Overridepublic void processElement(String value, Context ctx, Collector<ProductInfo> out) throws Exception {try {ProductInfo log = JSON.parseObject(value, ProductInfo.class);// 增加一个long类型的时间戳// 指定eventTime为yyyy-MM-dd HH:mm:ss格式的北京时间DateTimeFormatter format = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");OffsetDateTime eventTime = LocalDateTime.parse(log.getUpdatedAt(), format).atOffset(ZoneOffset.of("+08:00"));// 转换成毫秒时间戳long eventTimeTimestamp = eventTime.toInstant().toEpochMilli();log.setUpdatedAtTimestamp(eventTimeTimestamp);out.collect(log);}catch (Exception ex){log.error("解析Kafka数据异常...",ex);}}}/*** 提取时间戳生成水印*/static class ProductInfoTimestampExtractor extends BoundedOutOfOrdernessTimestampExtractor<ProductInfo> {ProductInfoTimestampExtractor(Time maxOutOfOrderness) {super(maxOutOfOrderness);}@Overridepublic long extractTimestamp(ProductInfo element) {return element.getUpdatedAtTimestamp();}}}测试结果
在对应Kafka Topic中发送如上测试数据后,得到结果。
// 可以看到,获取到了,事件发生时,对应的历史最新的商品基础信息
user_1,2016-01-01 00:00:01,1451577601000,browse,product_5,20,product_5,name50,category50,2016-01-01 00:00:00,1451577600000
user_1,2016-01-01 00:00:04,1451577604000,browse,product_5,20,product_5,name52,category52,2016-01-01 00:00:02,1451577602000
user_1,2016-01-01 00:00:02,1451577602000,browse,product_5,20,product_5,name52,category52,2016-01-01 00:00:02,1451577602000
user_1,2016-01-01 00:00:05,1451577605000,browse,product_5,20,product_5,name55,category55,2016-01-01 00:00:05,1451577605000
user_1,2016-01-01 00:00:00,1451577600000,browse,product_5,20,product_5,name50,category50,2016-01-01 00:00:00,1451577600000
user_1,2016-01-01 00:00:03,1451577603000,browse,product_5,20,product_5,name52,category52,2016-01-01 00:00:02,1451577602000
user_2,2016-01-01 00:00:02,1451577602000,browse,product_3,20,product_3,name32,category32,2016-01-01 00:00:02,1451577602000
user_2,2016-01-01 00:00:05,1451577605000,browse,product_3,20,product_3,name35,category35,2016-01-01 00:00:05,1451577605000
总结
Temporal Table可以简化和加速我们对历史状态数据的查询,并减少对状态的使用。Temporal Table是将一个Append-Only表(如上product_history_info)中追加的行,根据设置的主键和时间(如上productID、updatedAt),解释成Chanlog,并在特定时间提供数据的版本。
在使用时态表(Temporal Table)时,要注意以下问题。
- Temporal Table可提供历史某个时间点上的数据。
- Temporal Table根据时间来跟踪版本。
- Temporal Table需要提供时间属性和主键。
- Temporal Table一般和关键词LATERAL TABLE结合使用。
- Temporal Table在基于ProcessingTime时间属性处理时,每个主键只保存最新版本的数据。
- Temporal Table在基于EventTime时间属性处理时,每个主键保存从上个Watermark到当前系统时间的所有版本。
- 左侧Append-Only表Join右侧Temporal Table,本质上还是左表驱动Join,即从左表拿到Key,根据Key和时间(可能是历史时间)去右侧Temporal Table表中查询。



异常日志)


)



)


)


)

)
