BERT
BERT模型本质上是结合了 ELMo 模型与 GPT 模型的优势。
- 相比于ELMo,BERT仅需改动最后的输出层,而非模型架构,便可以在下游任务中达到很好的效果;
- 相比于GPT,BERT在处理词元表示时考虑到了双向上下文的信息;
BERT 结构
BERT(Bidirectional Encoder Representation from Transformers)是一个仅有 Encoder 的Transformer。
我们调用 BertModel 来搭建BERT模型,并通过 BertConfig 配置模型相关参数。
from pretrain.src.bert import BertModel
from pretrain.src.config import BertConfig
BERT 输入
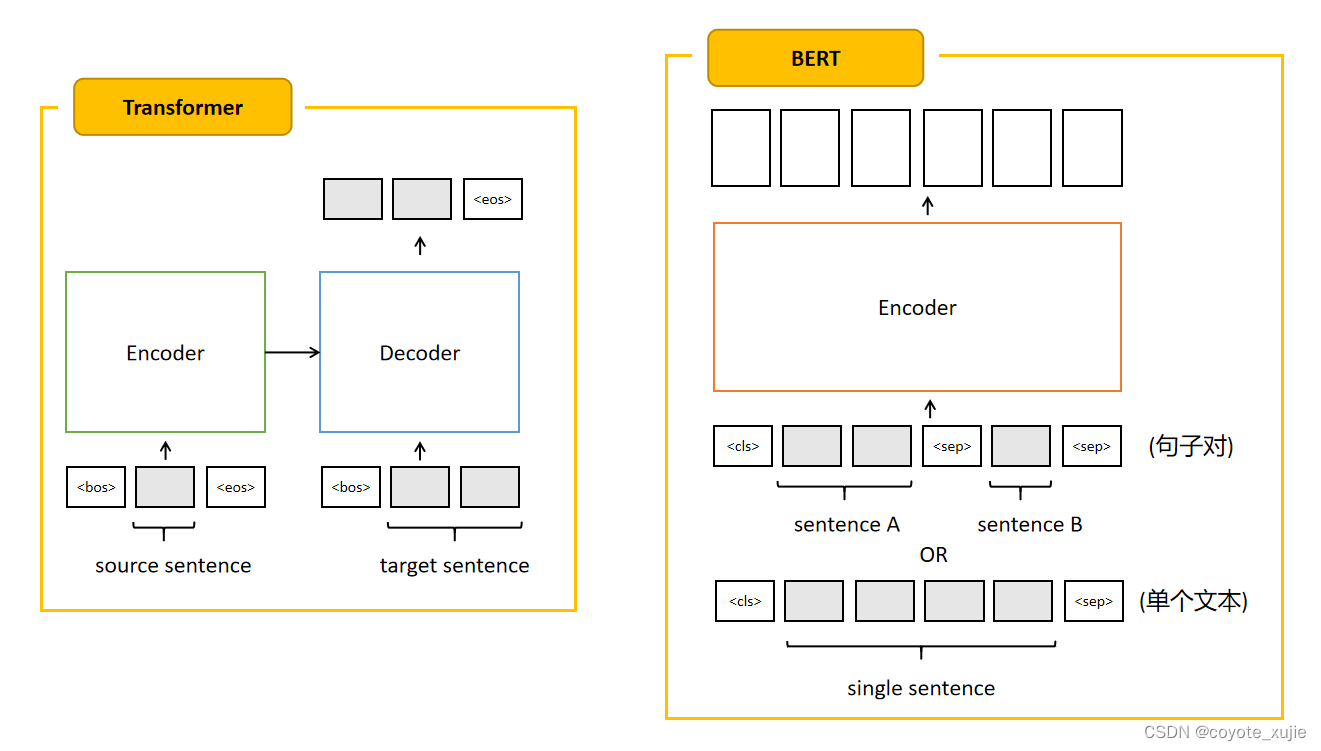
Transformer:Encoder接受源句子(source sentence),Decoder接受目标句子(target sentence);
- BERT:
- 针对句子对相关任务,将两个句子合并为一个句子对输入到Encoder中,<cls> + 第一个句子 + <sep> + 第二个句子 + <sep>;
- 针对单个文本相关任务,<cls> + 句子 + <sep>。
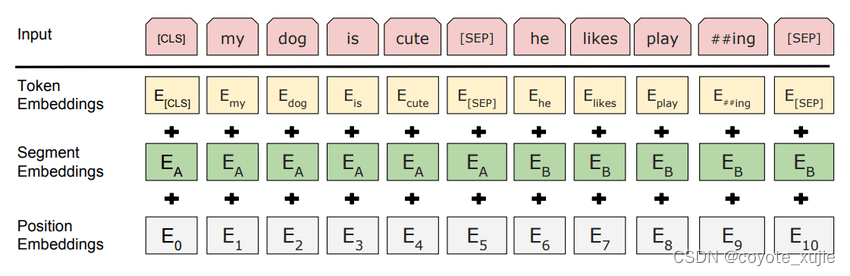
BERT Embedding
BERT Embedding与Transformer中的Embedding操作类似,包含词嵌入(word embedding)与位置嵌入(positional embedding)。
但与Transformer不同的是,BERT使用了可学习的位置信息,并额外增加了表示区分不同句子的段嵌入(segment embedding)。
import mindspore
from mindspore import nn
import mindspore.common.dtype as mstype
from mindspore.common.initializer import initializer, TruncatedNormalclass BertEmbeddings(nn.Cell):"""Embeddings for BERT, include word, position and token_type"""def __init__(self, config):super().__init__()self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, embedding_table=TruncatedNormal(config.initializer_range))self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size, embedding_table=TruncatedNormal(config.initializer_range))self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size, embedding_table=TruncatedNormal(config.initializer_range))self.layer_norm = nn.LayerNorm((config.hidden_size,), epsilon=config.layer_norm_eps)self.dropout = nn.Dropout(1 - config.hidden_dropout_prob)def construct(self, input_ids, token_type_ids=None, position_ids=None):seq_len = input_ids.shape[1]if position_ids is None:position_ids = mnp.arange(seq_len)position_ids = position_ids.expand_dims(0).expand_as(input_ids)if token_type_ids is None:token_type_ids = ops.zeros_like(input_ids)words_embeddings = self.word_embeddings(input_ids)position_embeddings = self.position_embeddings(position_ids)token_type_embeddings = self.token_type_embeddings(token_type_ids)embeddings = words_embeddings + position_embeddings + token_type_embeddingsembeddings = self.layer_norm(embeddings)embeddings = self.dropout(embeddings)return embeddings
BERT 模型构建
BERT模型的构建与上一节课程的Transformer Encoder构建类似。
分别构建multi-head attention层,feed-forward network,并在中间用add&norm连接,最后通过线性层与softmax层进行输出。
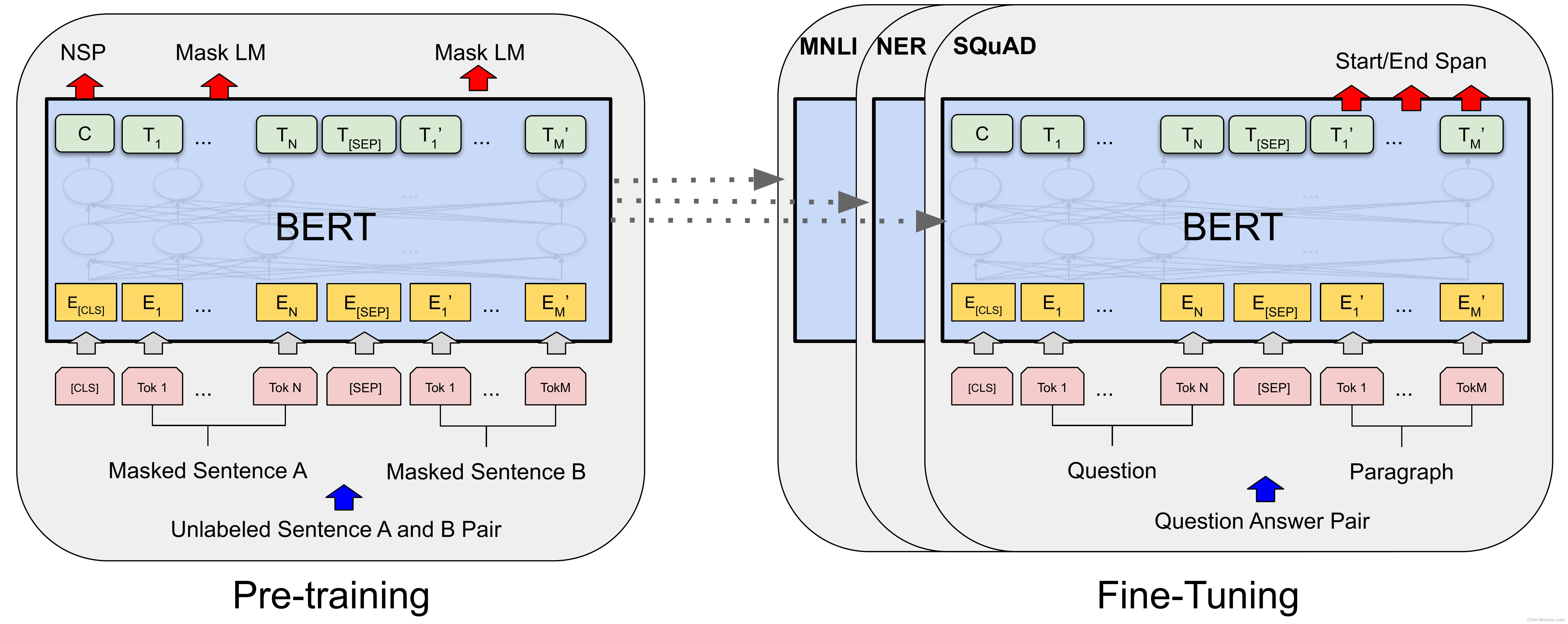
BERT 预训练
BERT通过Masked LM(masked language model)与NSP(next sentence prediction)获取词语和句子级别的特征。
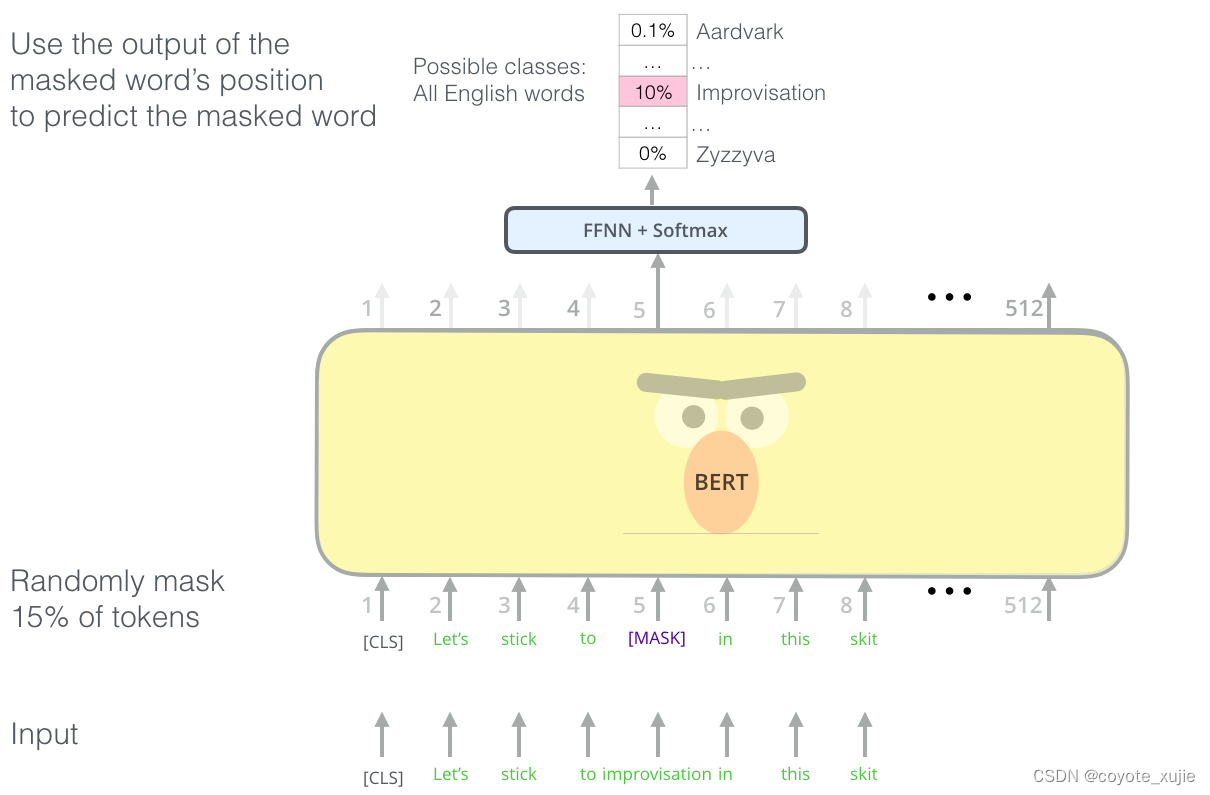
Masked Language Model (Masked LM)
BERT模型通过Masked LM捕捉词语层面的信息。
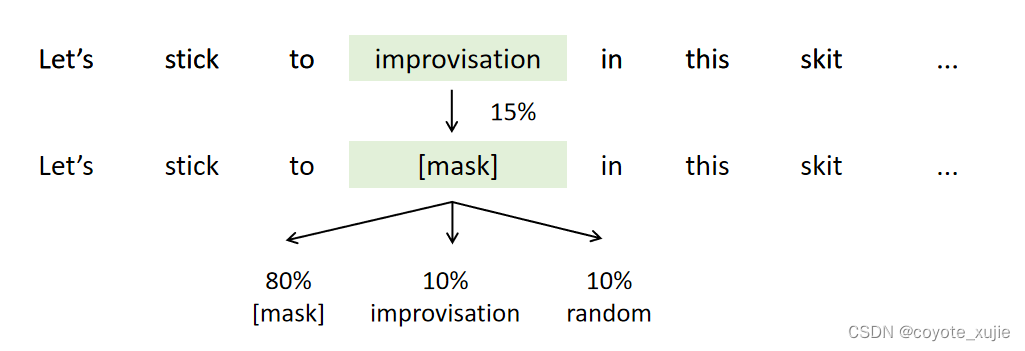
我们随机将每个句子中15%的词语进行遮盖,替换成掩码。在训练过程中,模型会对句子进行“完形填空”,预测这些被遮盖的词语是什么,通过减小被mask词语的损失值来对模型进行优化。
由于<mask>仅在预训练中出现,为了让预训练和微调中的数据处理尽可能接近,我们在随机mask的时候进行如下操作:
- 80%的概率替换为<mask>
- 10%的概率替换为文本中的随机词
- 10%的概率不进行替换,保持原有的词元
我们通过BERTPredictionHeadTranform实现单层感知机,对被遮盖的词元进行预测。在前向网络中,我们需要输入BERT模型的编码结果hidden_states。
activation_map = {'relu': nn.ReLU(),'gelu': nn.GELU(False),'gelu_approximate': nn.GELU(),'swish':nn.SiLU()
}class BertPredictionHeadTransform(nn.Cell):def __init__(self, config):super().__init__()self.dense = nn.Dense(config.hidden_size, config.hidden_size, weight_init=TruncatedNormal(config.initializer_range))self.transform_act_fn = activation_map.get(config.hidden_act, nn.GELU(False))self.layer_norm = nn.LayerNorm((config.hidden_size,), epsilon=config.layer_norm_eps)def construct(self, hidden_states):hidden_states = self.dense(hidden_states)hidden_states = self.transform_act_fn(hidden_states)hidden_states = self.layer_norm(hidden_states)return hidden_states
根据被遮盖的词元位置masked_lm_positions,获得这些词元的预测输出。
import mindspore.ops as ops
import mindspore.numpy as mnp
from mindspore import Parameter, Tensorclass BertLMPredictionHead(nn.Cell):def __init__(self, config):super(BertLMPredictionHead, self).__init__()self.transform = BertPredictionHeadTransform(config)self.decoder = nn.Dense(config.hidden_size, config.vocab_size, has_bias=False, weight_init=TruncatedNormal(config.initializer_range))self.bias = Parameter(initializer('zeros', config.vocab_size), 'bias')def construct(self, hidden_states, masked_lm_positions):batch_size, seq_len, hidden_size = hidden_states.shapeif masked_lm_positions is not None:flat_offsets = mnp.arange(batch_size) * seq_lenflat_position = (masked_lm_positions + flat_offsets.reshape(-1, 1)).reshape(-1)flat_sequence_tensor = hidden_states.reshape(-1, hidden_size)hidden_states = ops.gather(flat_sequence_tensor, flat_position, 0)hidden_states = self.transform(hidden_states)hidden_states = self.decoder(hidden_states) + self.biasreturn hidden_states
Next Sentence Prediction (NSP)
BERT通过NSP捕捉句子级别的信息,使其可以理解句子与句子之间的联系,从而能够应用于问答或者推理任务。
NSP本质上是一个二分类任务,通过输入一个句子对,判断两句话是否为连续句子。输入的两个句子A和B中,B有50%的概率是A的下一句。
另外,输入的内容最好是document-level的语料,而非sentence-level的语料,这样训练出的模型可以具备抓取长序列特征的能力。
在这里,我们使用一个单隐藏层的多层感知机 BERTPooler 进行二分类预测。因为特殊占位符 <cls>在预训练中对应了句子级别的特征信息,所以多层感知机分类器只需要输出 <cls>对应的隐藏层输出。
class BertPooler(nn.Cell):def __init__(self, config):super(BertPooler, self).__init__()self.dense = nn.Dense(config.hidden_size, config.hidden_size, activation='tanh', weight_init=TruncatedNormal(config.initializer_range))def construct(self, hidden_states):first_token_tensor = hidden_states[:, 0]pooled_output = self.dense(first_token_tensor)return pooled_output
最后,多层感知机分类器的输出通过一个线性层self.seq_relationship,输出对nsp的预测。
在BERTPreTrainingHeads中,我们对以上提到的两种方式进行整合。最终输出Maked LM(prediction scores)和NSP(seq_realtionship_score)的预测结果
class BertPreTrainingHeads(nn.Cell):def __init__(self, config):super(BertPreTrainingHeads, self).__init__()self.predictions = BertLMPredictionHead(config)self.seq_relationship = nn.Dense(config.hidden_size, 2, weight_init=TruncatedNormal(config.initializer_range))def construct(self, sequence_output, pooled_output, masked_lm_positions):prediction_scores = self.predictions(sequence_output, masked_lm_positions)seq_relationship_score = self.seq_relationship(pooled_output)return prediction_scores, seq_relationship_score
BERT预训练代码整合
我们将上述的类进行实例化,并借此回顾一下BERT预训练的整体流程。
- BertModel构建BERT模型;
- BertPretrainingHeads整合了Masked LM与NSP两个训练任务, 输出预测结果;
- BertLMPredictionHead:输入BERT编码与的位置,输出对应位置词元的预测;
- BERTPooler:输入BERT编码,输出对的隐藏状态,并在BertPretrainingHeads中通过线性层输出预测结果;
class BertForPretraining(nn.Cell):def __init__(self, config, *args, **kwargs):super().__init__(config, *args, **kwargs)self.bert = BertModel(config)self.cls = BertPreTrainingHeads(config)self.vocab_size = config.vocab_sizeself.cls.predictions.decoder.weight = self.bert.embeddings.word_embeddings.embedding_tabledef construct(self, input_ids, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None, masked_lm_positions=None):outputs = self.bert(input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids,position_ids=position_ids,head_mask=head_mask)sequence_output, pooled_output = outputs[:2]prediction_scores, seq_relationship_score = self.cls(sequence_output, pooled_output, masked_lm_positions)outputs = (prediction_scores, seq_relationship_score,) + outputs[2:]return outputs














)




)