Mixtral-8x7B是最好的开放大型语言模型(LLM)之一,但它是一个具有46.7B参数的庞大模型。即使量化为4位,该模型也无法在消费级GPU上完全加载(例如,24 GB VRAM是不够的)。
Mixtral-8x7B是混合专家(MoE)。它由8个专家子网组成,每个子网有60亿个参数。8位专家中只有2位在解码期间有效,因此可以将其余6位专家移动或卸载到另一个设备,例如CPU RAM,可以释放一些GPU VRAM。但在实践中这种操作是非常复杂的。
选择激活哪个专家是在对每个输入令牌和模型的每个层进行推理时做出的决定。如果暴力的将模型的某些部分移到CPU RAM中,会在CPU和GPU之间造成通信瓶颈。
Mixtral-offloading提出了一个更有效的解决方案,以减少VRAM消耗,同时保持合理的推理速度。
在本文中,我将解释Mixtral-offloading的工作过程,使用这个框架可以节省内存并保持良好的推理速度,我们将看到如何在消费者硬件上运行Mixtral-8x7B,并对其推理速度进行基准测试。
缓存和Speculative Offloading
MoE语言模型通常为子任务分配不同的专家,但在长标记序列上的专家并不唯一。一些专家在短的2-4个令牌序列中激活,而另一些专家则在剩下的令牌激活。下图可以看到这一点:
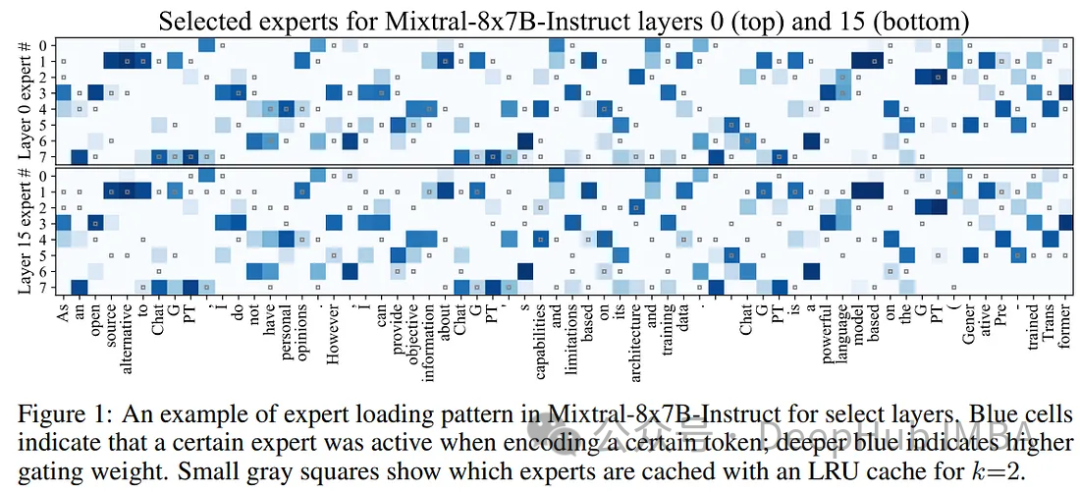
为了利用这种模式,Mixtral-offloading的作者建议将活跃的专家保存在GPU内存中,作为未来令牌的“缓存”。这确保了如果再次需要相同的专家时可以快速获得帮助。GPU内存限制了存储专家的数量,并使用了一个简单LRU(Least Recently Used )缓存,在所有层上统一维护k个最近使用的专家。
尽管它很简单,但LRU缓存策略显著加快了Mixtral-8x7B等MoE模型的推理速度。
尽管LRU缓存提高了专家的平均加载时间,但很大一部分推理时间仍然需要等待下一个专家加载。专家加载与计算之间缺乏有效的重叠。
在标准(非moe)模型中,有效的卸载包括在前一层运行时预加载下一层。这种方法对于MoE模型来说是不可行的,因为专家是在计算的时候选择的。在确定要加载哪些专家之前,系统无法预取下一层。尽管无法可靠地预取,但作者发现可以在处理前一层时猜测下一个专家,如果猜测是正确的,可以加速下一层的推理。
综上所述,LRU缓存和推测卸载可以节省VRAM。
专家感知的积极量化
除了Speculative Offloading之外,量化模型是在消费者硬件上运行必不可少的操作。使用bitsandbytes的NF4进行就简单的4位量化可以将模型的大小减少到23.5 GB。如果我们假设消费级GPU最多有24 GB的VRAM,这还是不够的。
先前的研究表明,在不影响模型性能的情况下,MoE专家可以量化到较低的精度。可以采用混合精度量化,将非专家的参数保持在4位。
在Mixtral-8x7B的467亿个参数中,96.6%(451亿个)用于专家,其余的分配给嵌入、注意力、MoE门和其他次要层,如LayerNorm。
对于量化,可以选择使用 Half Quadratic Quantization(HQQ) (Badri & Shaji, 2023),这是一种适应各种比特率的无数据算法。
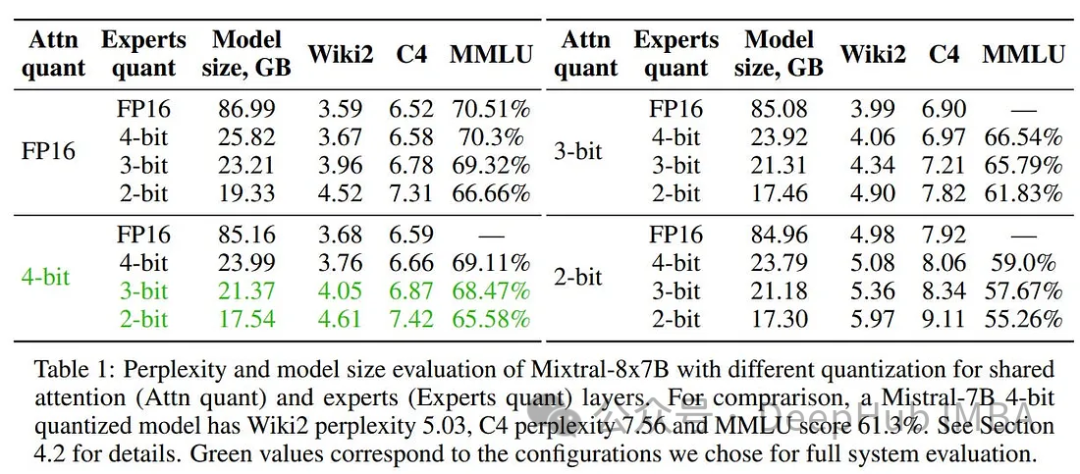
Mixtral-offloading的作者尝试了各种量化配置:FP16(不量化),HQQ 4位(组大小64,规模组大小256),HQQ 3位(组大小64,规模组大小128),HQQ 2位(组大小16,规模组大小128)。
下表所示,将专家量化为3位或2位,同时将注意力层保持在更高的位(16位或4位)得到的结果是非常好的。
在应用量化和Speculative Offloading后,推理速度比使用Accelerate (device_map)实现的Offloading快2到3倍:

在16gb GPU VRAM上运行Mixtral-7x8B
为了验证Mixtral-offloading,我们使用Google Colab的T4 GPU,因为它只有15gb的VRAM可用。这是一个很好的基线配置来测试生成速度。
首先,我们需要安装需要的包
git clone https://github.com/dvmazur/mixtral-offloading.git --quietcd mixtral-offloading && pip install -q -r requirements.txt
安装完成后需要重新运行ldconfig:
export LD_LIBRARY_PATH="/usr/lib64-nvidia"export LIBRARY_PATH="/usr/local/cuda/lib64/stubs"ldconfig /usr/lib64-nvidia
我们直接使用已经量化的模型(模型也可以用AWQ或GPTQ自己进行量化)。
Mixtral-offloading还不支持直接从HuggFace Hub加载模型。所以需要将模型保存在本地。
huggingface-cli download lavawolfiee/Mixtral-8x7B-Instruct-v0.1-offloading-demo --quiet --local-dir Mixtral-8x7B-Instruct-v0.1-offloading-demo
然后导入以下内容:
import syssys.path.append("mixtral-offloading")import torchfrom hqq.core.quantize import BaseQuantizeConfigfrom transformers import AutoConfig, AutoTokenizerfrom src.build_model import OffloadConfig, QuantConfig, build_mode
设置模型名称,得到量化模型的配置:
model_name = "mistralai/Mixtral-8x7B-Instruct-v0.1"quantized_model_name = "lavawolfiee/Mixtral-8x7B-Instruct-v0.1-offloading-demo"state_path = "Mixtral-8x7B-Instruct-v0.1-offloading-demo"config = AutoConfig.from_pretrained(quantized_model_name)device = torch.device("cuda:0")num_experts = config.num_local_experts
设置给卸载CPU的专家数量:
offload_per_layer = 3
这是一个非常重要的参数,如果降低这个数字,解码会更快,但也会消耗更多的VRAM。“3”适用于具有16 GB VRAM的GPU。
剩下则使用了mixtral-offloading建议的默认配置:
offload_config = OffloadConfig(main_size=config.num_hidden_layers * (num_experts - offload_per_layer),offload_size=config.num_hidden_layers * offload_per_layer,buffer_size=4,offload_per_layer=offload_per_layer,)
注意力模块被量化到更高的4精度,因为它们被所有专家共享和使用:
attn_config = BaseQuantizeConfig(nbits=4,group_size=64,quant_zero=True,quant_scale=True,)attn_config["scale_quant_params"]["group_size"] = 256
对于参数量专家模型,参数则被量化为2位:
ffn_config = BaseQuantizeConfig(nbits=2,group_size=16,quant_zero=True,quant_scale=True,
)
quant_config = QuantConfig(ffn_config=ffn_config, attn_config=attn_config)
下面就是建立混合模型:
model = build_model(device=device,quant_config=quant_config,offload_config=offload_config,state_path=state_path,
)
“模型”可以与Transformers库一起使用。
下面使用4种不同的提示对推理速度进行基准测试:
import time
tokenizer = AutoTokenizer.from_pretrained(model_name)
duration = 0.0
total_length = 0
prompt = []
prompt.append("Write the recipe for a chicken curry with coconut milk.")
prompt.append("Translate into French the following sentence: I love bread and cheese!")
prompt.append("Cite 20 famous people.")
prompt.append("Where is the moon right now?")
for i in range(len(prompt)):model_inputs = tokenizer(prompt[i], return_tensors="pt").to("cuda:0")start_time = time.time()with torch.autocast(model.device.type, dtype=torch.float16, enabled=True):output = model.generate(**model_inputs, max_length=500)[0]duration += float(time.time() - start_time)total_length += len(output)tok_sec_prompt = round(len(output)/float(time.time() - start_time),3)print("Prompt --- %s tokens/second ---" % (tok_sec_prompt))print(tokenizer.decode(output, skip_special_tokens=True))
tok_sec = round(total_length/duration,3)
print("Average --- %s tokens/second ---" % (tok_sec))
它消耗13gb的VRAM,每秒生成1.7个令牌。看着速度很慢,但是这对于T4的GPU是相当快的。如果每层卸载4个专家而不是3个,则VRAM消耗降低到11.7 GB,推理速度降低到1.4个令牌/秒。
如果用A100 GPU测试(A100可以加载整个量化模型),但为了测试,每层还是卸载3个专家。使用A100,该模型每秒生成2.6个令牌。这也差不多也是消费类GPU(例如RTX 4080)的最快速度了。
总结
mixtral-offloading 是一个新的项目,但它已经能够很好的运行。它结合了两种思想来显著减少内存使用并能够保持推理速度
随着Mixtral-8x7b的成功,MoE模型会在在未来变得越来越受欢迎。为消费者硬件优化推理的框架对于使moe更易于访问至关重要的。
https://avoid.overfit.cn/post/43ee6bb2c402448698fc7c67e2a9bd60
作者:Benjamin Marie




中的数据)






)




)
● 322. 零钱兑换 ● 279.完全平方数)
:各省份订单个数及订单总额分析开发)
清华大学出版社)