AI芯片: 神经网络研发加速器、神经网络压缩简化、通用芯片 CPU 加速、专用芯片 GPU 加速
- 神经网络研发加速器
- 神经网络编译器
- 神经网络编译器
- 神经网络加速与压缩(算法层面)
- 知识蒸馏
- 低秩分解
- 轻量化网络
- 剪枝
- 量化
- 通用芯片 CPU 加速
- x86 加速
- arm 加速
- 卷积优化
- 神经网络加速库
- 专用芯片 GPU 加速
- dsp加速
- faga加速
- npu加速
- K210人工智能微控制器
- 神经网络加速库: Vulkan图形计算
神经网络研发加速器
神经网络编译器组成:编译器、图表示、图优化、计算优化、代码生成。
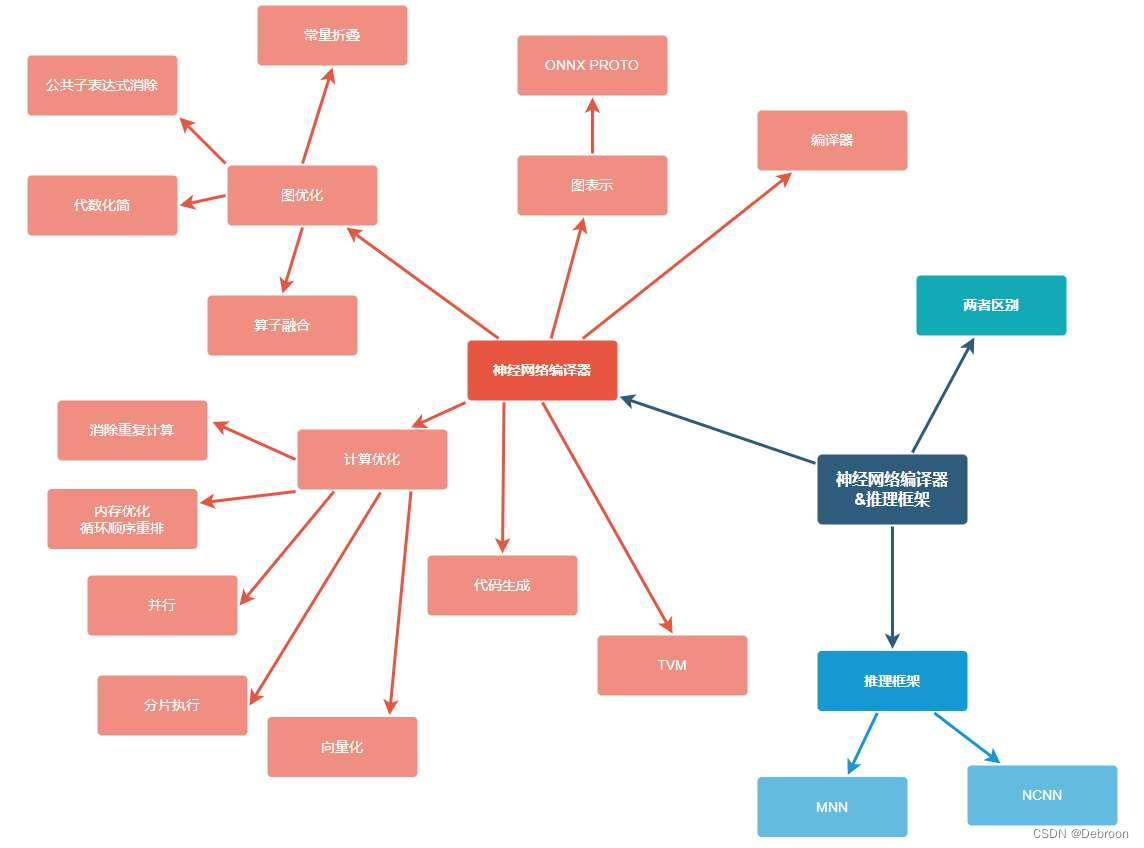
神经网络编译器
问题: 如何将高级别的神经网络模型有效转换为在多种硬件上运行的优化代码?
ONNX的角色:
- 统一格式:ONNX提供了一个标准化的格式来表示不同深度学习框架中的模型。它使模型可以在不同的框架和工具之间轻松转换,从而增强了模型的可移植性和互操作性。
- 模型交换:ONNX使得开发者可以选择最适合他们需求的工具和框架来训练模型,并且能够轻松地将这些模型转换为ONNX格式,用于部署。
神经网络编译器的角色:
- 优化和转换:神经网络编译器接收特定格式(如ONNX)的深度学习模型,并将其编译和优化以在特定硬件上运行。这包括转换模型为硬件特定的指令集,进行图优化、算子融合等。
- 跨平台部署:编译器使得模型不仅可以在不同的框架中移植,还可以在不同的硬件平台上高效运行,如CPU、GPU、FPGA或专用AI加速器。
协同工作流程:
- 模型训练:
- 开始于:深度学习模型首先在特定的框架(如TensorFlow, PyTorch, MXNet等)中进行训练。
- 输出:训练完成后的模型通常以该框架的特定格式存储。
- 模型转换(使用ONNX):
- 转换工具:使用ONNX提供的工具将模型从原始框架转换成ONNX格式。这一步骤涉及将模型的结构和权重导出到ONNX定义的统一格式中。
- 输出:转换后的模型现在在一个标准化的ONNX格式中,使得它可以跨不同的深度学习框架和工具共享。
- 模型优化和编译(使用神经网络编译器):
- 编译器输入:编译器接收ONNX格式的模型。
- 优化过程:编译器对模型进行一系列优化,如算子融合、图优化、消除冗余计算等,以提高模型在目标硬件上的运行效率。
- 硬件特定优化:编译器还会针对特定的目标硬件(如CPU, GPU, FPGA等)进行优化,生成适合该硬件的低级代码。
- 部署和执行:
- 部署:优化后的模型被部署到目标硬件上。
- 执行:模型在目标设备上执行,进行推理任务,如图像识别、语音识别等。
总结:
- ONNX的作用:提供了一个中间桥梁,允许不同框架中训练的模型被统一表示和共享。
- 神经网络编译器的作用:进一步优化ONNX格式的模型,确保它们在特定硬件上高效运行。
【图表示】:
ONNX 两个主要的 Protobuf 协议对象:TensorProto、AttributeProto。
-
TensorProto:
- 这个结构用于定义神经网络中的张量(多维数组),它包含张量的维度(dims)、数据类型(data_type)、数据本身(float_data, int32_data, string_data, int64_data, raw_data等),以及数据存储顺序(通常为行主序)。
- TensorProto可以包含任何类型的数据,包括原始的字节数据,这在存储复杂的或非标准格式的张量时非常有用。
-
AttributeProto:
- 用于定义图中节点属性的结构,它可以包含单个的数据值(如浮点数、整数、字符串、图、张量)或这些数据类型的数组。
- 每个属性都有一个名字(name)和一个类型(AttributeType),类型决定了属性值可以是哪种数据。
这些协议对象是ONNX标准的一部分,使得ONNX能够以一种跨平台、跨语言的方式精确地表示神经网络模型的结构和权重。
它们使得模型可以从一个框架转换并在另一个框架中使用,这对于深度学习模型的共享和部署至关重要。
【图优化】:
- 节点融合: 将多个操作符(Op)融合为单个复合操作符,以减少内存访问次数和计算开销。例如,将卷积、批量归一化和激活函数合并为一个操作。

- 常量折叠: 在编译时预计算那些以常量输入进行的操作,减少运行时的计算量。

-
死代码消除: 移除那些不会影响最终输出的操作,比如未使用的变量或操作。
-
公共子表达式消除: 检测并合并计算图中重复的表达式,以节省计算资源。
-
内存优化: 优化数据的存储和访问方式,减少内存使用量,例如通过就地操作(in-place operations)来减少不必要的数据复制。
-
层次融合: 类似节点融合,但在更高的层次上,比如将多层网络结构融合以减少中间数据的存储和传递。
-
操作调度: 优化操作的执行顺序,以提高硬件的使用效率,减少等待时间。
-
数据布局转换: 改变数据在内存中的排列方式(如NCHW到NHWC),以适配硬件特性,提高内存访问效率。
-
算子融合: 把能够一起执行的多个算子合并为一个算子,以减少内存访问和改善缓存使用。
-
精度优化: 根据需要将数据类型从高精度(如float64)降低到低精度(如float16或INT8),以加快计算速度并减少内存使用,特别是在支持低精度计算的硬件上。
所有这些优化都是为了减少计算量、提高执行速度、减少内存占用,并最大化硬件利用率。
【计算优化】:
- 向量化(Vectorization):
- 利用SIMD指令集对操作进行向量化处理,同时处理多个数据点,提高了数据处理速率。
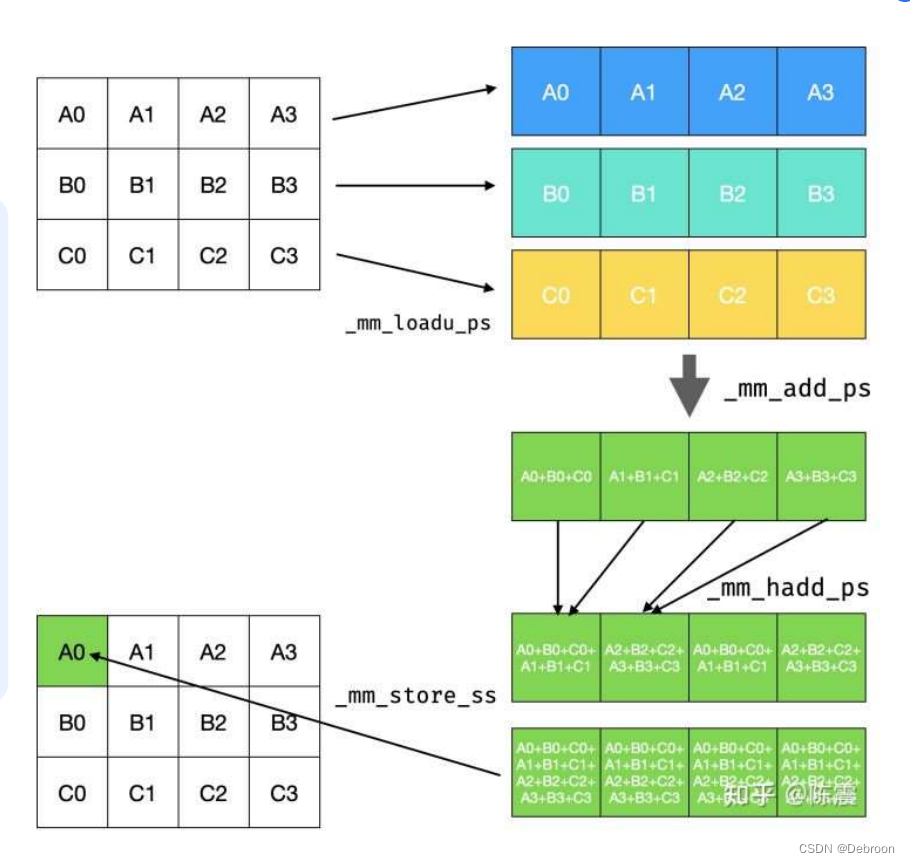
-
首先,三个独立的数据向量(A0, A1, A2, A3),(B0, B1, B2, B3),和(C0, C1, C2, C3)被加载到SIMD寄存器中。这通常使用如
_mm_loadu_ps这样的指令完成,它可以从非对齐的内存地址加载多个浮点数到一个SIMD寄存器。 -
接下来,使用SIMD加法指令(如
_mm_add_ps)对这些向量进行逐元素加法操作。这样,每个数据向量中相应的元素将被加在一起。 -
然后,使用SIMD水平加法指令(如
_mm_hadd_ps),对加法的结果进行进一步的组合。水平加法将一个SIMD寄存器中的相邻元素加在一起。 -
最后,使用如
_mm_store_ss这样的指令,将计算的结果存回内存中。
- 并行化(Parallelization):
- 分布计算工作负载,利用多核CPU、GPU的多个计算单元,或者其他硬件加速器(如FPGA、TPU)的并行处理能力。

- 利用缓存,所需的数据可以被连续地加载到缓存中,而不是随机地从内存中读取,提取加速
-
循环展开(Loop Unrolling):
- 展开循环结构以减少循环控制的开销,并可能使编译器能够进一步优化。
-
内存访问优化:
- 通过优化数据存储模式和访问模式来减少缓存未命中和内存延迟。
-
算术强度提升(Increase Arithmetic Intensity):
- 通过减少内存操作和增加计算操作的比例,提高计算与内存传输的比率。
-
算子融合(Operator Fusion):
- 将多个操作融合为一个复合操作,以减少内存访问次数和提高缓存利用率。
-
内核融合(Kernel Fusion):
- 在GPU编程中,将多个内核操作融合成单个内核,减少GPU内核启动的开销。
-
延迟执行(Lazy Evaluation):
- 操作只在必要时执行,避免不必要的计算,节省资源。
-
精确度与混合精度训练(Precision and Mixed-Precision Training):
- 适当降低计算的精度来加快速度,如使用半精度浮点数(float16)代替全精度(float32)。
-
特定硬件优化:
- 根据目标硬件的特定特性(如GPU的共享内存大小、CPU的缓存行大小)进行优化。
-
编译时优化(Compile-time Optimizations):
- 利用编译器的高级优化,如去除冗余计算、优化分支预测等。
-
动态张量重用(Dynamic Tensor Rematerialization):
- 在运行时动态决定数据结构的生命周期,以减少内存占用。
-
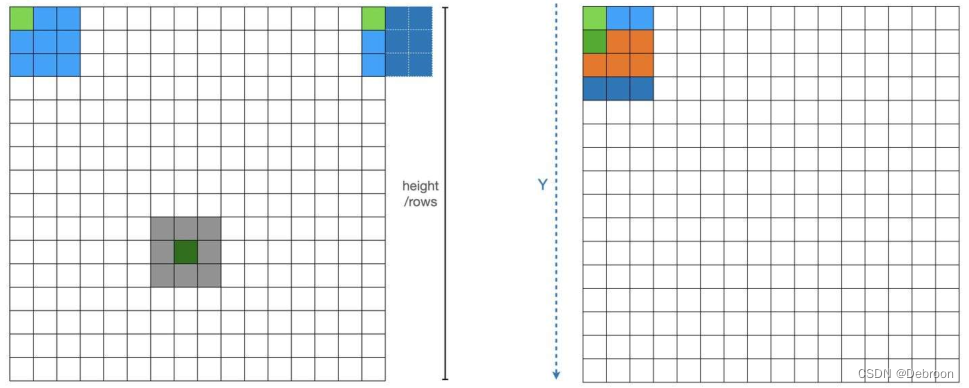
消除重复计算:对于一个均值池化,那么橘色部分就是重复计算的,可以通过优化消除重复计算
神经网络编译器
所以,就有了 — 神经网络编译器。
- TVM 神经网络编译器
- NCNN 神经网络推理框架
- MNN 移动神经网络引擎
是专门用于优化和部署神经网络模型的编译器。
可以将训练好的神经网络模型转换成针对特定硬件(如CPU、GPU、移动设备等)优化的执行代码。
-
TVM:https://tvm.apache.org/docs/install/index.html
是一个开源的神经网络编译器框架,它可以将各种深度学习模型(如TensorFlow、PyTorch、MXNet等的模型)编译成优化的代码,以在多种硬件上运行,包括CPU、GPU、FPGA等。
TVM特别强调自动化的性能优化,使用了一种叫做AutoTVM的系统自动调整模型参数以适应不同的硬件配置。
-
NCNN:https://github.com/Tencent/ncnn/wiki/how-to-build#build-for-linux
由腾讯优化的一个轻量级深度学习框架,专门用于移动设备和边缘计算设备。
它不依赖于第三方库,非常适合于移动应用。
NCNN特别关注于在低功耗设备上的高性能运行,它通过优化网络的内存使用和计算速度,使得模型在移动设备上能够快速且有效地执行。
-
MNN:https://www.yuque.com/mnn/cn
由阿里巴巴开源的深度学习框架,旨在帮助开发者在端侧设备上部署AI模型。
MNN的主要特点是支持多平台和多后端,能够在各种设备上运行,如iOS和Android手机、服务器和IoT设备。
它通过优化计算图,减少内存占用,并提供多种量化方案以适应不同的应用需求。
神经网络加速与压缩(算法层面)
- 矩阵低秩分解
- 概念:将神经网络的参数(例如,全连接层的二维矩阵、卷积层的四维矩阵)通过矩阵分解和低秩近似,分解为多个计算总量更小的小矩阵。
- 目的:加速网络计算过程。
- 方法:例如SVD分解、Tucker分解。
- 影响:分解为多层可能增加数据读取次数,影响速度。
- 剪枝
- 类型:包括非结构化剪枝和结构化剪枝,以及自动化剪枝。
- 非结构化剪枝:去除权重矩阵中不重要的元素,形成稀疏矩阵,通过稀疏存储减少模型大小。
- 结构化剪枝:删除整个网络结构的一部分(如通道、过滤器、层),在现有框架上实现加速。
- 自动化剪枝:自动确定剪枝结构,如AMC(自动化模型压缩)和MetaPruning。
- 量化
- 概念:将网络参数和激活值从高精度(如FP32)转化为低精度(如INT8),以加快推理速度。
- 挑战:量化可能导致精度损失,需精心设计,如数值对齐、对称和非对称量化等。
- 知识蒸馏
- 概念:从大型模型(教师网络)到小型模型(学生网络)的知识迁移。
- 目的:保持小模型在减少计算量的同时获得较高性能。
- 发展:许多方法被提出,如FitNet、Attention Transfer,以及无数据网络压缩。
- 轻量化模型设计
- 目标:设计高效、轻量的网络,替代传统大型网络。
- 方法:使用高效操作,如深度可分离卷积,减少参数量。
- 代表模型:Google的MobileNet系列,旷视的ShuffleNet。
从结构调整到参数精度的多个层面。
目标是在保持模型性能的同时,减少模型的计算负担和存储需求,特别适用于资源受限的环境,如移动设备和边缘计算平台。
每种技术都有其独特的优点和适用场景,在实际应用中往往需要结合多种技术来达到最佳效果。
知识蒸馏
低秩分解
轻量化网络
剪枝
量化
通用芯片 CPU 加速
x86 加速
arm 加速
卷积优化
神经网络加速库
专用芯片 GPU 加速
dsp加速
faga加速
npu加速
K210人工智能微控制器





)






)






