随着数据以指数级的速度流入企业,强大且高性能的消息传递系统至关重要。Apache Kafka 因其速度和可扩展性而成为热门选择,但究竟是什么让它如此之快?
在本期中,我们将探讨:
-
Kafka 的架构及其核心组件,如生产者、代理和消费者
-
Kafka 如何优化数据存储和复制
-
这些优化使 Kafka 能够实现令人印象深刻的吞吐量和低延迟
让我们先深入了解一下 Kafka 的核心组件。
Kafka 架构提炼
在将 Kafka 用作 pub-sub 消息中间件的典型场景中,有 3 个重要组件:生产者、代理者和消费者。生产者是消息发送者,消费者是消息接收者。代理通常以集群模式部署,该模式处理传入的消息并将其写入代理分区,从而允许使用者从中读取数据。
请注意,Kafka 被定位为事件流平台,因此在消息队列中经常使用的术语“消息”在 Kafka 中不使用。我们称之为“事件”。
下图汇集了 Kafka 架构和客户端 API 结构的详细视图。我们可以看到,尽管生产者、消费者和代理仍然是架构的关键,但构建高吞吐量、低延迟的 Kafka 需要更多。让我们一一介绍这些组件。
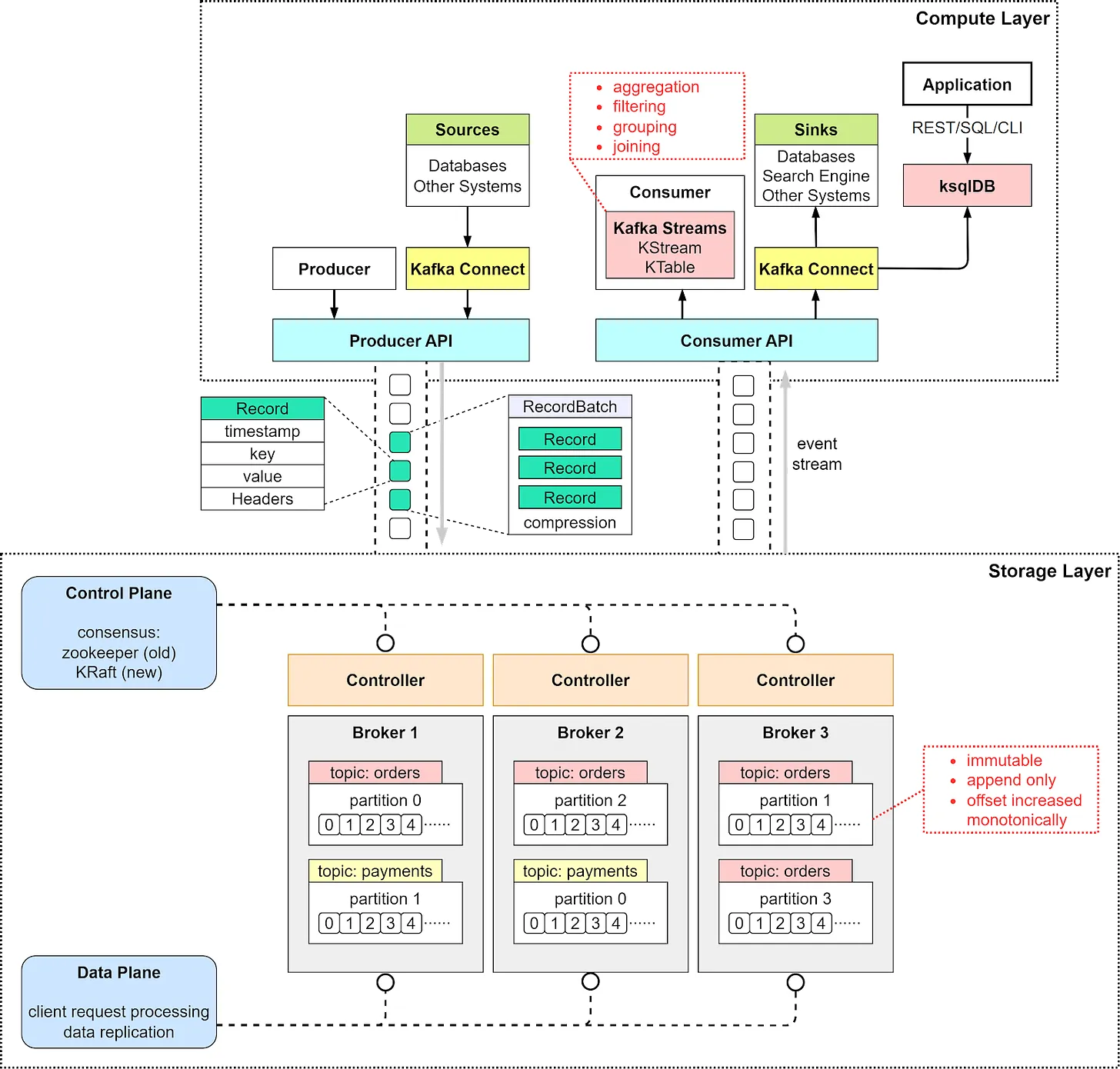
从高层次的角度来看,体系结构中有两层:计算层和存储层。
计算层
计算层或处理层允许各种应用程序通过 API 与 Kafka 代理进行通信。
生产者使用生产者 API。如果数据库等外部系统想要与 Kafka 通信,它还提供 Kafka Connect 作为集成 API。
消费者通过消费者 API 与经纪人交谈。为了将事件路由到其他数据接收器,如搜索引擎或数据库,我们可以使用 Kafka Connect API。此外,使用者可以使用 Kafka Streams API 执行流式处理。如果我们处理无限的记录流,我们可以创建一个 KStream。下面的代码片段为主题“orders”创建一个 KStream,其中 Serdes(序列化程序和反序列化程序)用于键和值。如果我们只需要更新日志中的最新状态,我们可以创建一个 KTable 来维护状态。Kafka Streams 允许我们对事件流执行聚合、过滤、分组和联接。
final KStreamBuilder builder = new KStreamBuilder();final KStream<String, OrderEvent> orderEvents = builder.stream(Serdes.String(), orderEventSerde, “orders”);
虽然 Kafka Streams API 适用于 Java 应用程序,但有时我们可能希望部署纯流处理作业,而不将其嵌入到应用程序中。然后,我们可以使用 ksqlDB,一个针对流处理优化的数据库集群。它还为我们提供了一个 REST API 来查询结果。
我们可以看到,通过计算层中的各种 API 支持,可以非常灵活地链接我们想要对事件流执行的操作。例如,我们可以订阅主题“orders”,根据产品聚合订单,并将订单计数发送回主题“ordersByProduct”中的 Kafka,另一个分析应用程序可以订阅并显示该主题。
存储层
该层由 Kafka 代理组成。Kafka 代理在服务器集群上运行。数据存储在不同主题的分区中。主题就像一个数据库表,一个主题中的分区可以分布在集群节点上。在分区中,事件严格按其偏移量排序。偏移量表示事件在分区中的位置,并单调增加。代理上持久化的事件是不可变的,并且仅追加,甚至删除也被建模为删除事件。因此,生产者只处理顺序写入,而使用者只按顺序读取。
Kafka 代理的职责包括管理分区、处理读取和写入以及管理分区的复制。它的设计很简单,因此易于扩展。我们将更详细地回顾代理架构。
由于 Kafka 代理是以集群模式部署的,因此管理节点需要两个组件:控制计划和数据平面。
控制平面
控制平面管理 Kafka 集群的元数据。过去是 Zookeeper 管理控制器:一个代理被选为控制器。现在,Kafka 使用一个名为 KRaft 的新模块来实现控制平面。选择一些代理作为控制器。
为什么 Zookeeper 被从集群依赖中剔除?使用 Zookeeper,我们需要维护两种不同类型的系统:一种是 Zookeeper,另一种是 Kafka。使用 KRaft,我们只需要维护一种类型的系统,这使得配置和部署比以前容易得多。此外,KRaft 在将元数据传播到代理方面效率更高。
我们不会在这里讨论 KRaft 共识的细节。需要记住的一点是,控制器和代理中的元数据缓存是通过 Kafka 中的特殊主题同步的。
数据平面处理数据复制。下图显示了一个示例。“orders”主题中的分区 0 在 3 个代理上有 3 个副本。Broker 1 上的分区是主分区,其中当前数据偏移量为 4;代理 2 和 3 上的分区是偏移量位于 2 和 3 处的跟随器。
第 1 步 - 为了赶上领导者,追随者 1 发出偏移量为 2 的 FetchRequest,追随者 2 发出偏移量为 3 的 FetchRequest。
第 2 步 - 然后,领导者将数据相应地发送给两个追随者。
第 3 步 - 由于追随者的请求隐式确认了先前获取的记录的接收,因此领导者随后在偏移量 2 之前提交记录。

记录
Kafka 使用 Record 类作为事件的抽象。无界事件流由许多 Records 组成。
记录中有 4 个部分:
-
Timestamp 时间戳
-
Key 键
-
Value 价值
-
Headers (optional) 标头(可选)
该密钥用于强制排序、对具有相同密钥的数据进行共置以及数据保留。键和值是字节数组,可以使用序列化程序和解串程序 (serdes) 进行编码和解码。
代理
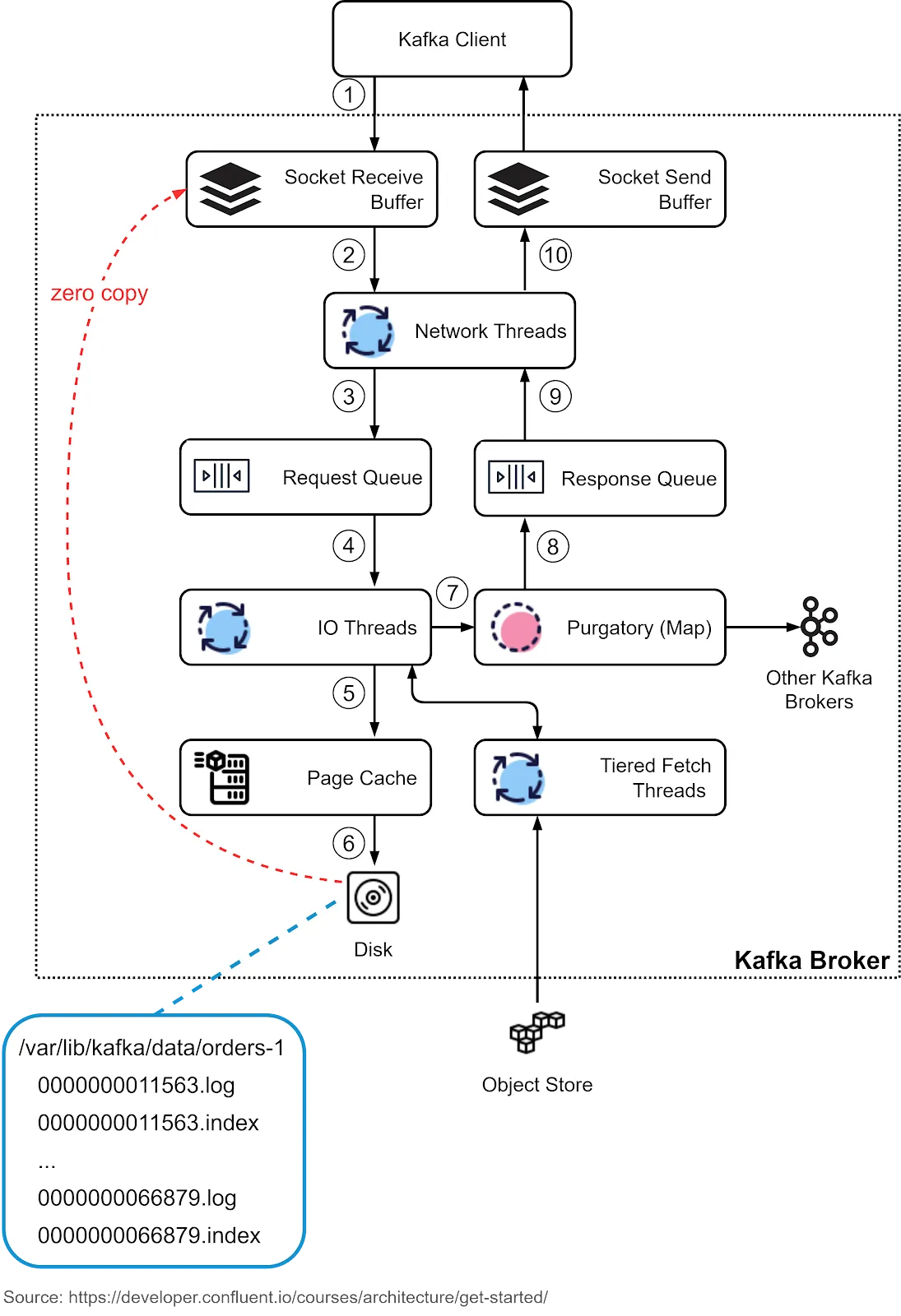
我们讨论了代理作为存储层。数据按主题进行组织,并作为分区存储在代理上。现在让我们详细了解经纪人是如何工作的。
第 1 步:生产者向代理发送请求,该请求首先进入代理的套接字接收缓冲区。
步骤 2 和 3:其中一个网络线程从套接字接收缓冲区中选取请求,并将其放入共享请求队列中。线程绑定到特定的生产者客户端。
第 4 步:Kafka 的 I/O 线程池从请求队列中获取请求。
步骤 5 和 6:I/O 线程验证数据的 CRC 并将其追加到提交日志中。提交日志在磁盘上按段进行组织。每个段中有两个部分:实际数据和索引。
第 7 步:将生产者请求隐藏在炼狱结构中以进行复制,因此可以释放 I/O 线程来获取下一个请求。
第 8 步:复制请求后,将其从炼狱中删除。 生成响应并将其放入响应队列中。
步骤 9 和 10:网络线程从响应队列中获取响应,并将其发送到相应的套接字发送缓冲区。请注意,网络线程绑定到某个客户端。只有在发出请求的响应后,网络线程才会从特定客户端接收另一个请求。




)
)














