12 月 3 日,2023 IoTDB 用户大会在北京成功举行,收获强烈反响。本次峰会汇集了超 20 位大咖嘉宾带来工业互联网行业、技术、应用方向的精彩议题,多位学术泰斗、企业代表、开发者,深度分享了工业物联网时序数据库 IoTDB 的技术创新、应用效果,与各行业标杆用户的落地实践、解决方案,并共同探讨时序数据管理领域的行业趋势。
我们邀请到天谋科技联合创始人、CTO 乔嘉林参加此次大会,并做主题报告——《IoTDB 企业版 V1.3:时序数据管理一站式解决方案》。以下为内容全文。
大家好,我是乔嘉林。今天很荣幸能够和大家在这里分享我们 IoTDB 的企业版 V1.3。经过了 2023 年的打磨,我们从去年的 12.3 大会发布的分布式 1.0 版本开始,现在已经迭代了三个大的版本,在 IoTDB 的功能和性能,以及稳定性方面都有了大幅的提升。
那首先我们可以来看几个数字。在 2023 年一年的时间里面,我们一共更新了 80 多万行的代码,并且在开源的 GitHub Star 增幅了 57%。现在,Apache 基金会已经有 360 多个项目了,在这 360 多个项目里边,IoTDB 的活跃度从去年的第 7 名成长到了第 2 名。那一个更直观的效果也可以看到,在各个渠道的 IoTDB 的版本下载量已经达到了 10 倍以上的增长。

进步不仅是在代码和功能层面,也会体现在用户的选择上面。那现在 IoTDB 已经在我国的一些关键行业领域里面得到了广泛的应用。比如能源电力行业里面,我们有在华润电力,在中国核电,在大唐集团,有了深度的使用。那么在钢铁冶炼方面,我们有在宝武钢铁集团,在中冶赛迪集团,服务了国内的很多个钢厂、电厂。那么在航空航天方面,我们在商飞的飞机试飞场景,包括成飞的飞机制造场景,也有了落地的应用。
这样的场景有的是在今年选择了新建的平台,那这样的话就是在各个的时序数据库类里面,进行了广泛的选型,最终定下了 IoTDB。那么也有一种是去替换原有的系统,这种系统包括一些通用型的数据库,也包括以 PI 为代表的这种实时数据库,甚至以 InfluxDB 为代表的一些时序数据库等等。
那随着 IoTDB 的用户量逐渐的增加,我们的社区的技术交流群也达到了 300% 左右的增长量。

那么用户在选型时序数据库的时候,主要都在关注哪些维度呢?第一个是国产自研。前段时间我给一个老教授去介绍,说我是做数据库的,他问我的第一个问题是:“你们是基于哪一个数据库做出来的?”确实,之前可能有不少的国内的厂商是基于一些开源的数据库,来去进行的产品的设计和改造。但是 IoTDB 选择另一条路,我们没有基于任何一个数据库去进行设计,而是从最底层的文件数据开始,一行一行把代码写起来,包括数据库的引擎,包括分布式的处理结构。
我们经常说一句话,叫“要站在巨人的肩膀上去实现我们系统的设计”。那这里我认为在软件行业里面,其实应该是站在巨人思想的肩膀上面。而 IoTDB 想要从代码上从零开始做起,进行架构上的创新,这样的话我们才能够从架构层面进行全方位的超越,这样的话才能超越国外的这些竞品和数据库的厂商。那么也是得益于我们的这项坚持和选择,现在我们可以很荣幸地说,目前我们可以在我国的这些关键行业里面,提供一个国产的、更加安全的、而且性能更加优异的选择。
另外一个就是开源可信。那么 IoTDB 是 Apache 基金会里面唯一的时序数据库的顶级项目,那也得益于它 Apache 协议的这样一个稳定并且商业友好的开源协议,用友、华为、中冶赛迪等等,都在和 IoTDB 的开源社区一起合作,来去打造这个行业的特色的企业版本。
此外,IoTDB 也可以提供分布式的、高可用的服务,那也是唯一一个能够提供端边云架构的一个时序数据库。在性能方面,其实我们现在说用国产数据库,很多时候都在说,可能是不得已而采用国产的。但是我们希望使用 IoTDB 不仅仅是为了国产,更是为了更高效的性能体验。前段时间,我们和中核武汉的同事一起聊天,他们当时跟我说,在 2019 年去做时序数据库的选型的时候,去对比了国内外的 8 项数据库。那在性能方面,他当时的原话是:“IoTDB 的性能惊艳到我们了”,所以选择了 IoTDB 进入了中国核电的领域。

此外,在今年的国际权威数据库的公开基准测试中,是一个国际的 benchANT 的榜单,我们在读写性能,包括压缩比,以及整体的资源消耗和成本方面都排名第一名。这样一个榜单,它使用的是时序数据库的基准测试,叫 TSBS,应该大家可能听过。这项测试其实是比较权威的一个测试工具,那 benchANT 他们采用的是这个工具,而且所有的竞品、所有的产品都选择同样的参数,以及同样的 AWS 的机器,并且是由 benchANT 的官方人员来执行的这个测试,所以这个 benchANT 榜单会更具有公平性和参考性。

那么过去,我们主要是以开源社区的方式来对用户提供的技术支持,但是随着 IoTDB 进入到了各行各业的核心的生产区域,那么纯社区的支持方式已经不太能满足用户的需求了。大家也对 IoTDB 提出了更高的期待,主要有以下几个方面:
第一个就是企业级的服务。因为数据库是一个非常复杂的系统软件,同一个业务需求,不同的方案它的效果和性能可能会相差几倍甚至几十倍。那么这种方案的选择可能会涉及到数据库的建模,包括读写接口的选择、SQL 怎么写、索引怎么建,甚至数据库前后的系统的对接,以及数据的整体的流转方案上面。那也因此,我们也需要提供一个更加全面的解决方案和技术支持。
第二个是易用性的工具。IoTDB 社区过去更多的沉迷在核心技术的迭代和创新上,其实对于易用性的工具稍显薄弱,但是往往这些易用性的工具能够很大程度上提升我们用户的使用体验和幸福感。所以我们接下来也会更多关注在易用性的工具的打磨上面。
第三点就是行业特色的功能。因为 IoTDB 社区它是作为一个上游的分支,需要支持工业的时序数据这样一个很通用的版本,所以我们会保持一个最简洁、最高效以及最通用的内核。那么对于行业的一些特色的需求,我们就会维护一些专业的版本来去提供支持。

那为了做这件事情,我们就成立了 Timecho,中文叫天谋科技。三国演义里面有一句话,叫“谋事在人,成事在天”,主要强调的还是人努力之后,最终的结果还是取决于老天。但是我们把这句话的顺序给调整了一下,虽然“成事在天”,但是“谋事在人”,一切事在人为。未来,清华和开源社区会去继续进行技术的创新,而天谋则会围绕开源版进行产品的打磨,让技术创新不止停留在科研、论文,也要落地到祖国的大地上,落地到每一个用户的心里。

那么为了满足用户上面提到的这些期待,所以我们今年经过了打磨,正式推出了 IoTDB V1.3 的企业版,时序数据的一站式的管理解决方案。
那这里的一站式主要体现在两个方面。第一个是 IoTDB 的横向维度,我们可以提供单个平台的采、存、算、管、用等全生命周期的基础服务组件。首先,最左边可以看到是一个数据采集协议,这里面 PLC4X 是 Apache 基金会目前的一个工业数据采集的顶级项目。那这个项目的主席,也就是 Chris,他也是 Apache 董事会的成员,今年也加入了天谋科技,这样为我们整体的这个生态的版图向前推进了一大步。那目前我们已经支持工业常见的数十种的采集协议。
中间就是 IoTDB 的这样一个数据库的核心软件了。IoTDB 首先具备多种部署模式,比如说我们在端侧,可能资源比较少的时候,我们就可以去部署一个单机版。那当我们资源有限,能提供两台服务器,但是也希望能够使用一个高可用的服务的时候,我们就可以提供一个双活版本。当我们对于扩展性和性能有更多的要求,可能三五个节点都不能满足了,需要几十个节点,这个时候我们就可以去部署一个真正的分布式的一个架构。
最右侧是我们基于 IoTDB 的这个数据处理分析能力,去支持了一些工具,那么到底 IoTDB 有哪些数据处理的能力呢?首先,在这些数据的管理之上,我们提供了数据的基础的查询,包括数据的处理,以及更加智能的分析。这些工具包括大屏的展示、数据的报表,以及模型训练、趋势分析、设备的监控、告警等等。基于这些工具,我们就可以很方便的把一个单个平台的 IoTDB 给搭建出来。
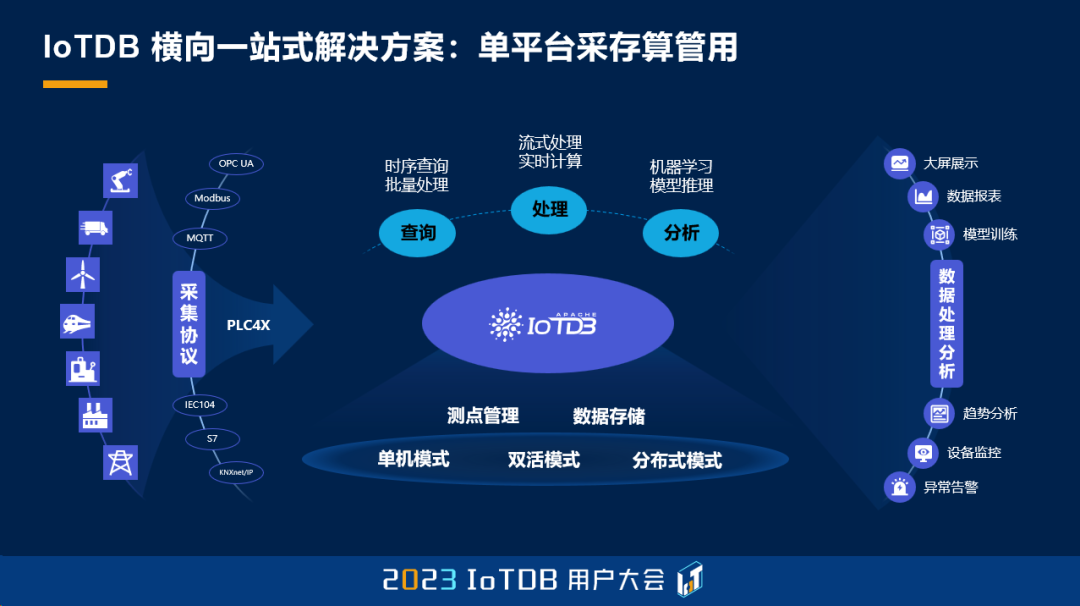
第二个是纵向维度,我们提供了一个端边云协同的这样一个能力。那我们一直在提 IoTDB 的架构是一个端边云协同的架构,那这样一个架构到底体现在什么方面呢?其实它的最核心的思想就是数据只被组织一次,而可以被多次使用。
因为假如说我们要做一个这种分布式的一个集团的架构,我们可能需要在最底层把数据处理一遍,整理一遍。那么当它传到边侧、场侧的时候,可能数据又需要被写一遍,在云侧可能继续需要进行一遍处理。所以我们希望把这个数据或者处理的阶段整体就推到边侧,把所有的边侧的计算能力给利用起来,它处理一次之后,这个数据就可以直接被上传到云端,这样的话就能够大大的节省网络的消耗和接收端的 CPU 的消耗。所以 IoTDB 也是自 2013 年以来吧,时序数据库这个名词诞生之后,在这一批的同类产品里面,唯一一个具备这种数据文件高效同步的时序数据库的一个产品。
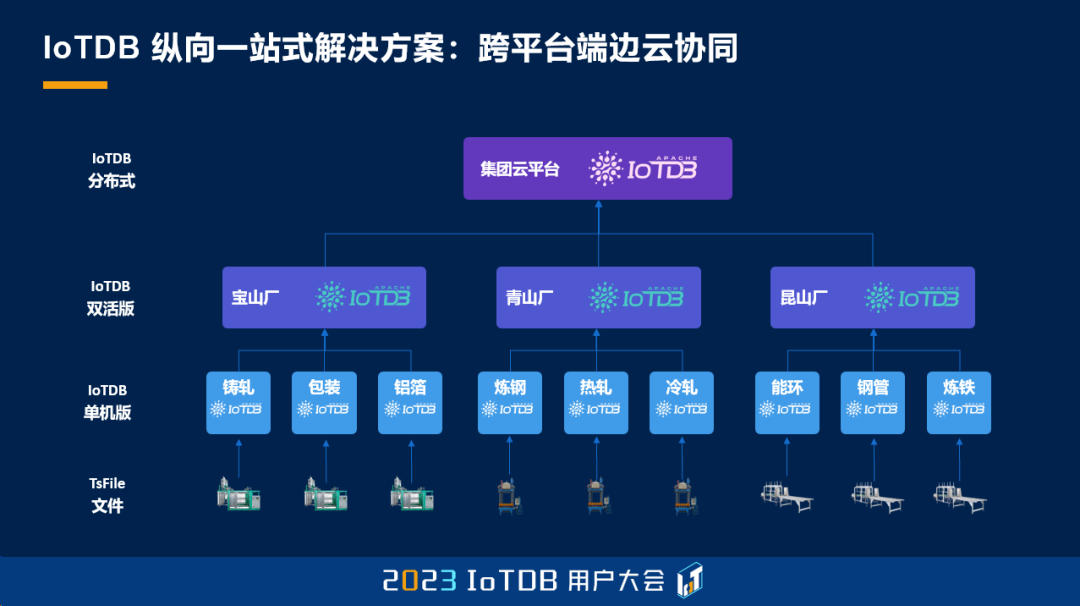
这张是 IoTDB 的系统架构图。其中蓝色的框是开源版的一些通用功能,黄色的框是企业版的特有功能,其中覆盖了数据的采集,数据的存储,包括三种处理引擎,以及应用工具,还有系统的管理以及生态集成的多个维度的方面。其中会涉及到多种的工业协议的采集,以及网闸的穿透,以及多级存储和查询的视图等等。
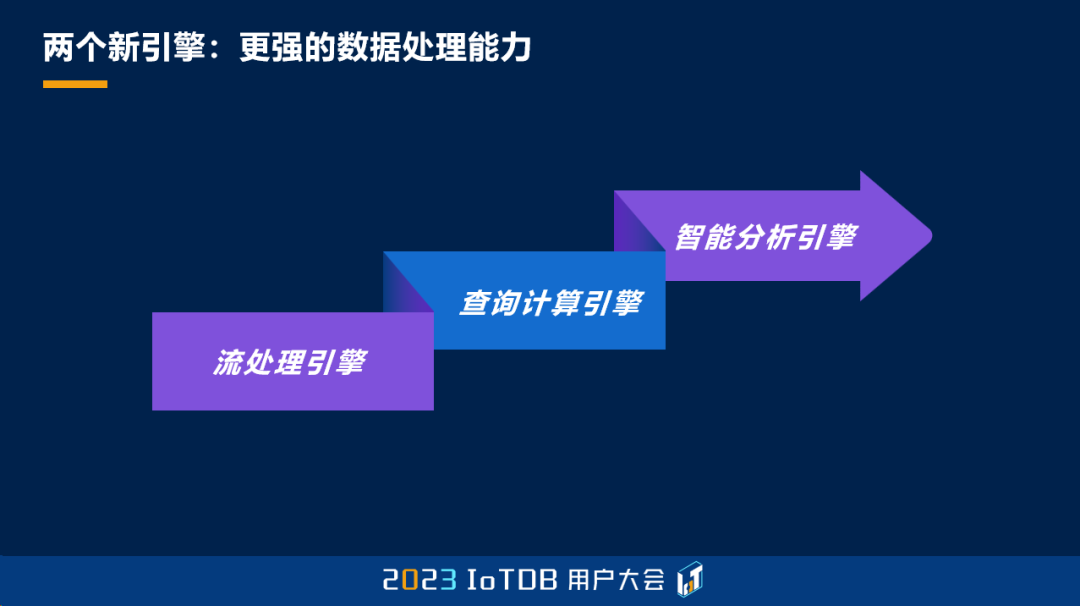
那其中的亮点可以总结成:三个新的工具,两个新的引擎和一个新的项目。

三个新的工具这里,我们分别在数据库的部署、调优和使用阶段分别推出了对应的工具,从而全方位地提升 IoTDB 的易用性。

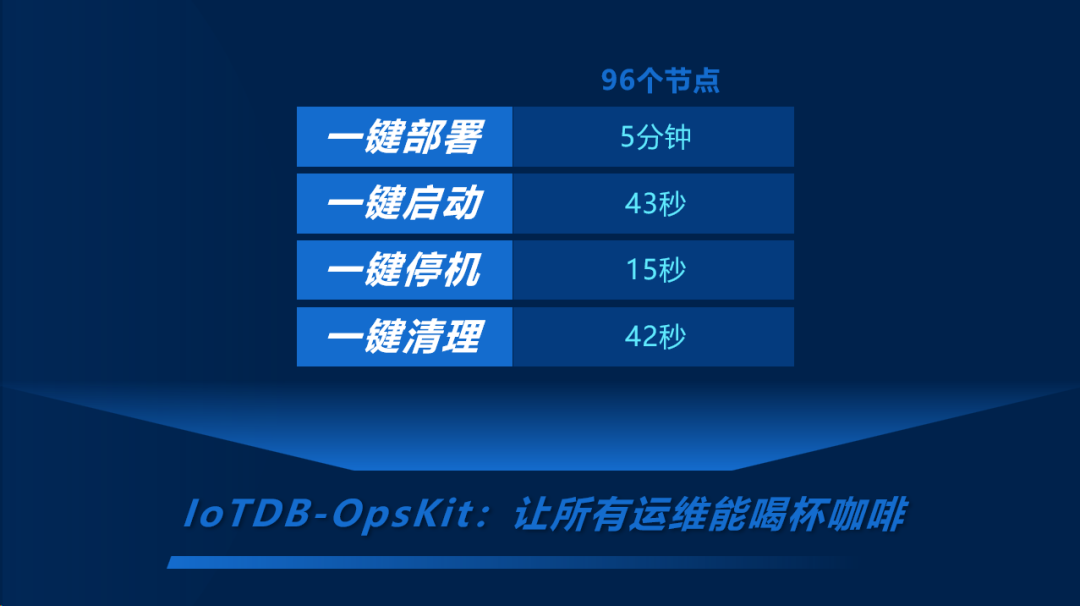
首先,因为 IoTDB 是一个分布式的架构,它的部署肯定需要涉及到多个节点的状态和服务的维护,会比单机更加复杂。因此我们开发了 IoTDB 的 OpsKit,它是一个 IoTDB 的集群管理工具。它的主要目的就是一句话:让所有的运维人员能够有时间来喝杯咖啡,所有的集群的部署、启动、停止都能够用一行命令来完成。在我们国内一个最大的集群规模的案例里面,我们有 96 个节点要去维护,那它的部署只需要 5 分钟,启动、停止和清理只需要几十秒,从而大大地解放了人力。
那么我们现在做的这个工业互联网的领域,其实就是把机器设备装上传感器来采集它的时序数据,通过对这些数据的分析,反推这个设备到底需要哪些优化。那这个思想能不能用到 IoTDB 本身的演进上面呢?答案也是可以的。所以我们也针对这个思想开发了一个全面的系统监控工具,不仅对 IoTDB 本身内部的各个模块进行了很丰富的监控,同时我们也对数据的规模、数据的读写的请求,包括 IoTDB 所在服务器的这些资源进行全面的监控。那目前我们已经实现了 400 多项的这些监控项,经过调优之后,我们通常能够将一个系统的性能提升 2 到 10 倍以上。通过这种方式,我们让所有的细节都能够被分析,所有的异常都能够被解释。
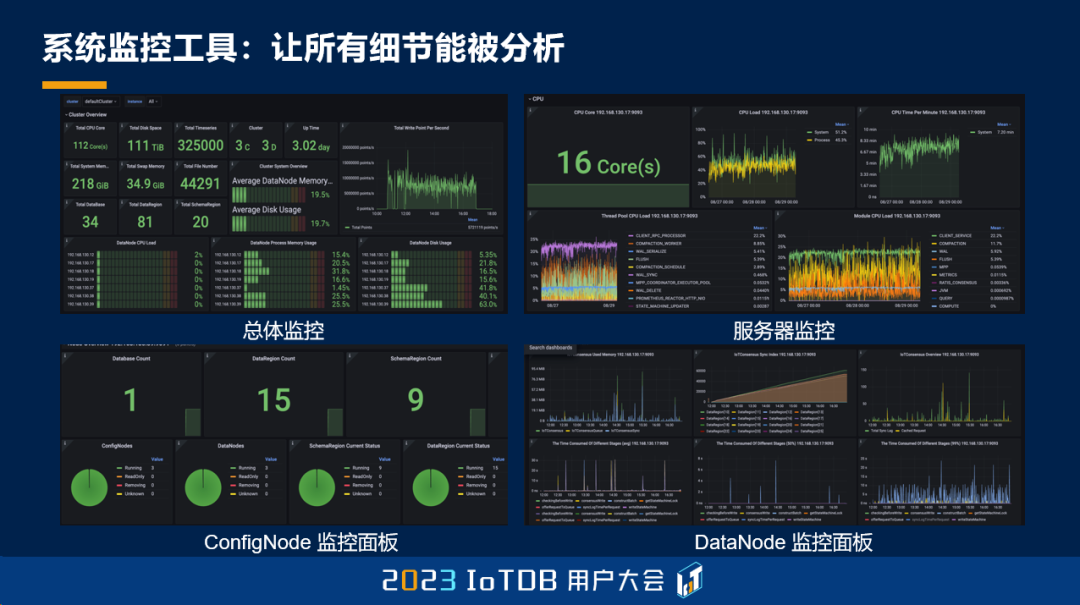
那在所有的计算机软件里面,我们说操作系统,它可以说是最底层的,最不被用户所接触到。但是操作系统现在每一个人都可以去用起来,这就得益于它的很良好的用户交互界面。那我们也是基于同样的思想,IoTDB 在数据库层面也提供了一个可视化的控制台,这样的话和 IoTDB 的交互就不再会像以前一样,我们去通过大黑框或者写代码的方式了。我们的目标是让所有 IoTDB 的功能能够被看到。

接下来是两个新的引擎。首先,中间是我们原来的查询计算引擎,这种引擎通常用户跟 IoTDB 的交互都是通过写一个 SQL 或者发一个命令过来,经过一些计算返回给用户,这种都是通过操作来去触发的。那我们希望这个数据处理的模式能够更加的丰富一些,所以我们向前扩展了流处理的引擎,这种引擎的处理方式是数据触发的,当数据到达的时候,就可以去做一些实时的处理。向后我们去增加了智能分析的引擎,它的这种方式是算法出发的,也就是我们会集成更丰富的一些数据处理的能力,从而在全方位的去挖掘数据的价值。
那首先,第一个是流处理的引擎。流处理引擎是一个 IoTDB 内置的、轻量化的、实时处理的一个框架。当数据接入的时候,就可以实时做一些异步的处理。这里包括 IoTDB 内部,我们可以做一些告警、预计算,包括一些统计、降采样等等的这些事情。在 IoTDB 之间,我们也可以利用这个功能去做数据库实例之间的数据同步,包括这种低延迟的、操作级的同步,以及高吞吐的、文件级的同步。在 IoTDB 的外部,我们可以将 IoTDB 和外部的系统进行一个打通,包括去做数据的备份,去做数据的订阅,以及数据的集成。所以通过流处理引擎,数据在 IoTDB 里面就不仅仅是一个静态的资产了,而是能够真正的流动起来。

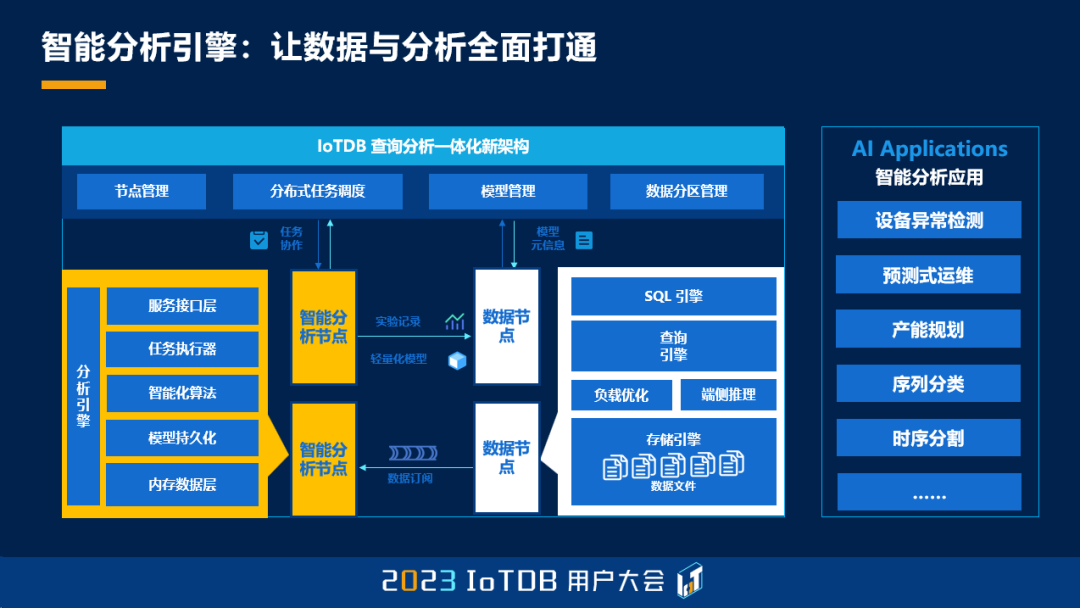
下一个是智能分析引擎。我们之前 IoTDB 有两类节点,第一类是数据库的管理节点,第二类是数据库的数据节点。那我们今年也增加了一个新的节点,叫 AINode,也就是智能分析节点。通过这种集成,使得一些智能的分析算法不再需要在外部去执行了,我们可以直接在数据库内部去做数据的分析,通过这种方式将数据和分析进行全面的打通,也就是现在说的 Data + AI 这样一个方向。
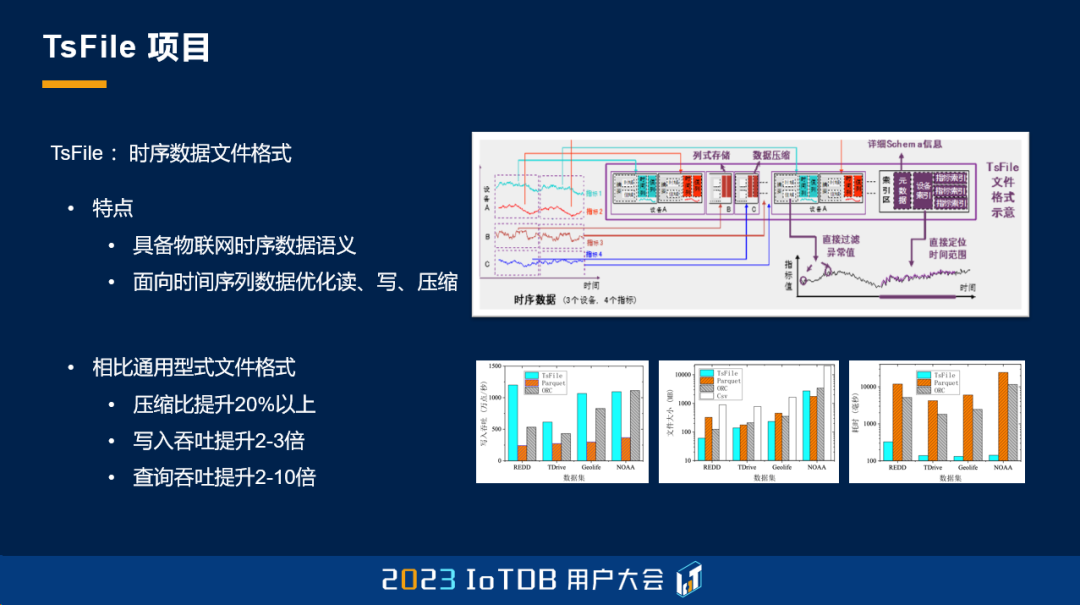
下面为大家介绍一个项目。这个项目是 IoTDB 项目的起点,它也是 IoTDB 的数据基座,也是 IoTDB 数据灵活迁移的一个秘诀。相信大家可能已经猜到这个项目是什么了,它就是 TsFile 项目。
TsFile 的全称是 Time Series File,时间序列的文件格式。它的特点就是针对物联网时序数据,提供了它的管理和处理的语义。那也针对这种物联网时序数据的负载,我们优化了文件的写入、查询,包括存储、压缩比等等。在这些维度上面,我们会相比一些通用的文件结构,包括 Parquet、ORC、CSV 等等,能够有 2 到 10 倍以上的性能提升。
那么,TsFile 一直是 IoTDB 的一个内部的模块,为什么说 TsFile 是一个项目呢?第一个原因就是 TsFile 本身是提供一个文件级的 API 的,我们可以不用 IoTDB,直接把数据写成 TsFile,同时能够去读这个文件的数据的内容。第二个原因就是,在上个月的 Apache 董事会上面,TsFile 被正式投票通过了,成为了一个 Apache 的顶级项目,这也是标志着时序数据领域第二个 Apache 的顶级项目。所以 TsFile 现在有了新的项目名字,叫 Apache TsFile。那它的定位就是时序数据的一个标准的文件格式,就可以独立于 IoTDB,可以去直接使用,也可以和 IoTDB 形成一个生化反应。

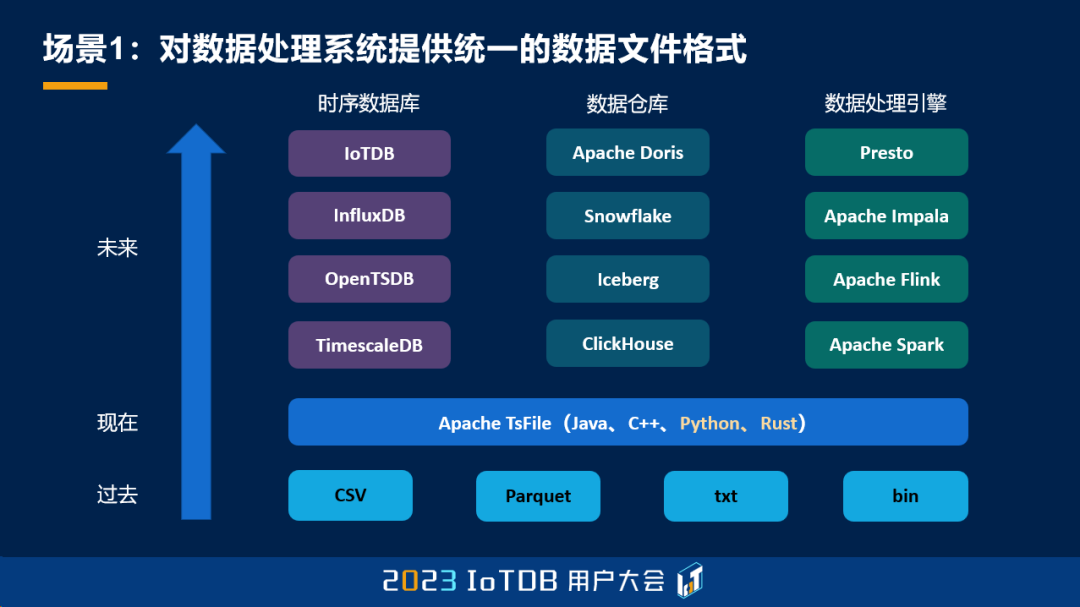
它的场景主要有两个,第一个是对数据处理系统,提供一个统一的数据文件格式。过去,我们可能在一个大的工业平台里面,会缺少一个专门管时序数据的文件,所以大家可能都去自己选择不同的文件格式来使用,包括 CSV、Parquet、txt,甚至一些厂家自定义的这种二进制的文件结构,那这些文件结构其实不太利于我们去做数据的统一的管控,以及数据的治理。现在有了 TsFile 之后,所有的时序数据就都可以写成 TsFile。我们可以提供一个标准的、统一的接口,那这个接口目前我们已经具备了 Java 和 C++ 版本,未来也会去扩展 Python 和 Rust 等版本。
再往后,TsFile 不仅可以统一这种数据文件层的数据管理,也可以在未来去集成不同的数据处理的系统。包括一些时序数据库可以直接利用 TsFile 来去做数据的读写和存储,也可以去交给这些数据仓库去做一些分析,包括利用数据处理的引擎,去做一些分布式的处理。这样的话,TsFile 可以放在一个分布式的文件系统里面,去提供一个直接的算法的读取。
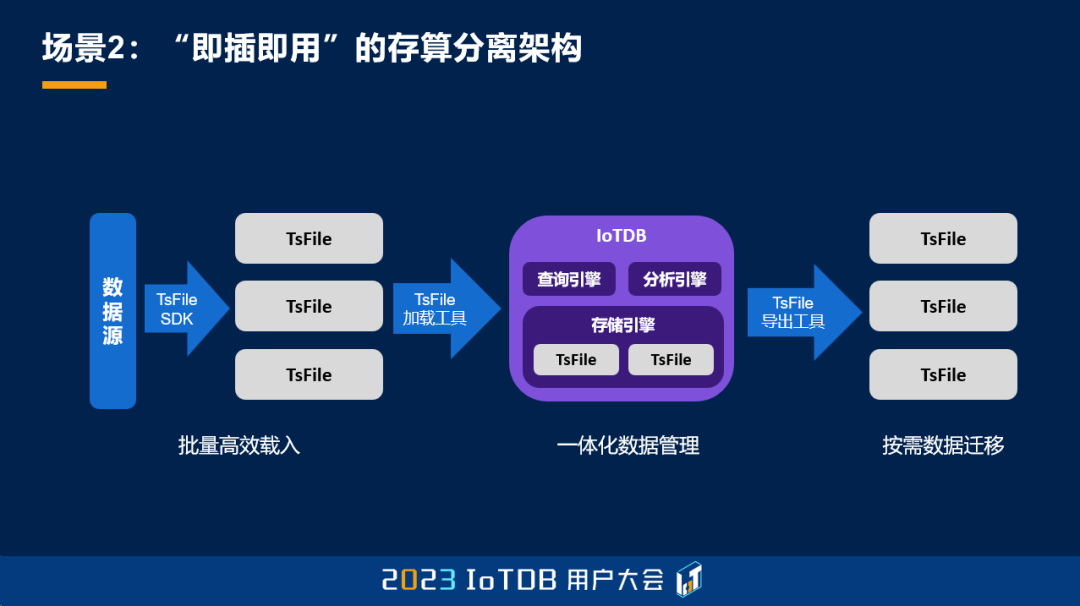
另外一个场景就是 TsFile 可以和 IoTDB 形成一个即插即用的、存算分离的架构。这种方式当我们把数据源整理成一些 TsFile 文件之后,我们发现这些文件可能我们需要进行一个统一的管理,希望使用一个 SQL 去访问它们。那这个时候就可以把它们去加载到 IoTDB 里面,进入一个存储引擎。这种加载其实只需要构建最简单的一些索引,就可以对上层提供查询、分析的这些服务,也就实现了查询和分析的一体化。
那我们也可以进一步把 IoTDB 中我们希望想要的这些数据,去给迁移出来,做一个导出。那这种导出不是像以前我们去导数据库的数据一样,去导成一个 CSV,或者导成一些 SQL,因为那种方式对于数据膨胀是非常大的。我们可以直接把数据库底层的 TsFile 给读取出来,通过这种方式我们就可以做灵活的数据迁移,数据的备份以及数据的分析。
最后,我们分享一下我们的一个整体的目标愿景,就是坚持全自研,坚持面向用户需求,坚持每年都有创新性的突破,并且坚持成为物联网领域的强力基建。
好,谢谢大家。

可加欧欧获取大会相关PPT
微信号:apache_iotdb

)

重学Java设计模式之设计模式介绍)
的数据时序预测)
—— 隐藏版本号)













的安装)
