资源下载: https://download.csdn.net/download/vvoennvv/88682033
一,概述
基于遗传算法优化BP神经网络 (GA-BP) 的数据时序预测是一种常用的机器学习方法,用于预测时间序列数据的趋势和未来值。
在使用这种方法之前,需要将时间序列数据转化为适合BP神经网络处理的形式。常用的方法是将时间序列数据转化为滞后观测值的矩阵形式,以便将其作为BP神经网络的输入。
然后,使用遗传算法对BP神经网络的权重和阈值进行优化。遗传算法通过模拟自然选择和遗传机制,使用种群中的个体来表示网络权重和阈值的不同组合。通过计算每个个体的适应度,根据适应度选择和交叉繁殖优秀的个体,并引入变异操作以增加种群的多样性。这个过程通过多次迭代,逐步优化网络的权重和阈值,使其能够更好地拟合时间序列数据的特征和趋势。
最后,使用优化后的GA-BP神经网络进行数据时序预测。通过将过去的时间序列数据传递给网络,网络将根据优化后的权重和阈值进行计算,并预测未来的数值。优化后的网络能够更准确地捕捉时间序列数据中的趋势和周期性,并提供更精确的预测结果。
综上所述,基于遗传算法优化BP神经网络的数据时序预测方法能够结合遗传算法的优化能力和BP神经网络的非线性拟合能力,实现更准确和可靠的时间序列预测。这种方法在各种时间序列预测问题中都有广泛的应用,例如股票价格预测、气象数据预测等。
二,代码
代码中文注释非常清晰,按照示例数据修改格式,替换数据集即可运行,数据集为excel。
部分代码示例如下:
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行%% 导入数据(时间序列的单列数据)
result = xlsread('数据集.xlsx');%% 添加路径
addpath('goat\')%% 数据分析
num_samples = length(result); % 样本个数
kim = 15; % 延时步长(kim个历史数据作为自变量)
zim = 1; % 跨zim个时间点进行预测%% 构造数据集
for i = 1: num_samples - kim - zim + 1res(i, :) = [reshape(result(i: i + kim - 1), 1, kim), result(i + kim + zim - 1)];
end%% 数据集分析
outdim = 1; % 最后一列为输出
num_size = 0.7; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);%% 建立模型
S1 = 5; % 隐藏层节点个数
net = newff(p_train, t_train, S1);......三,运行结果

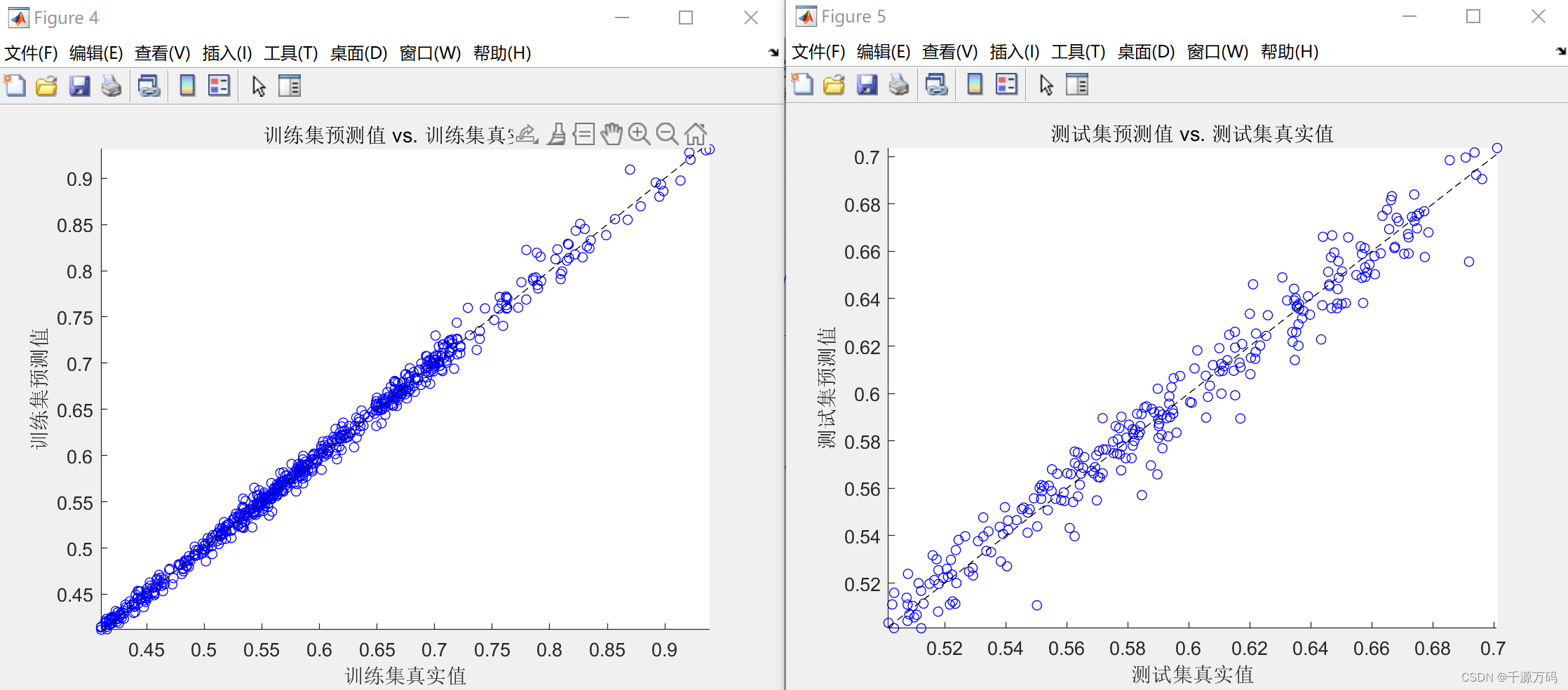
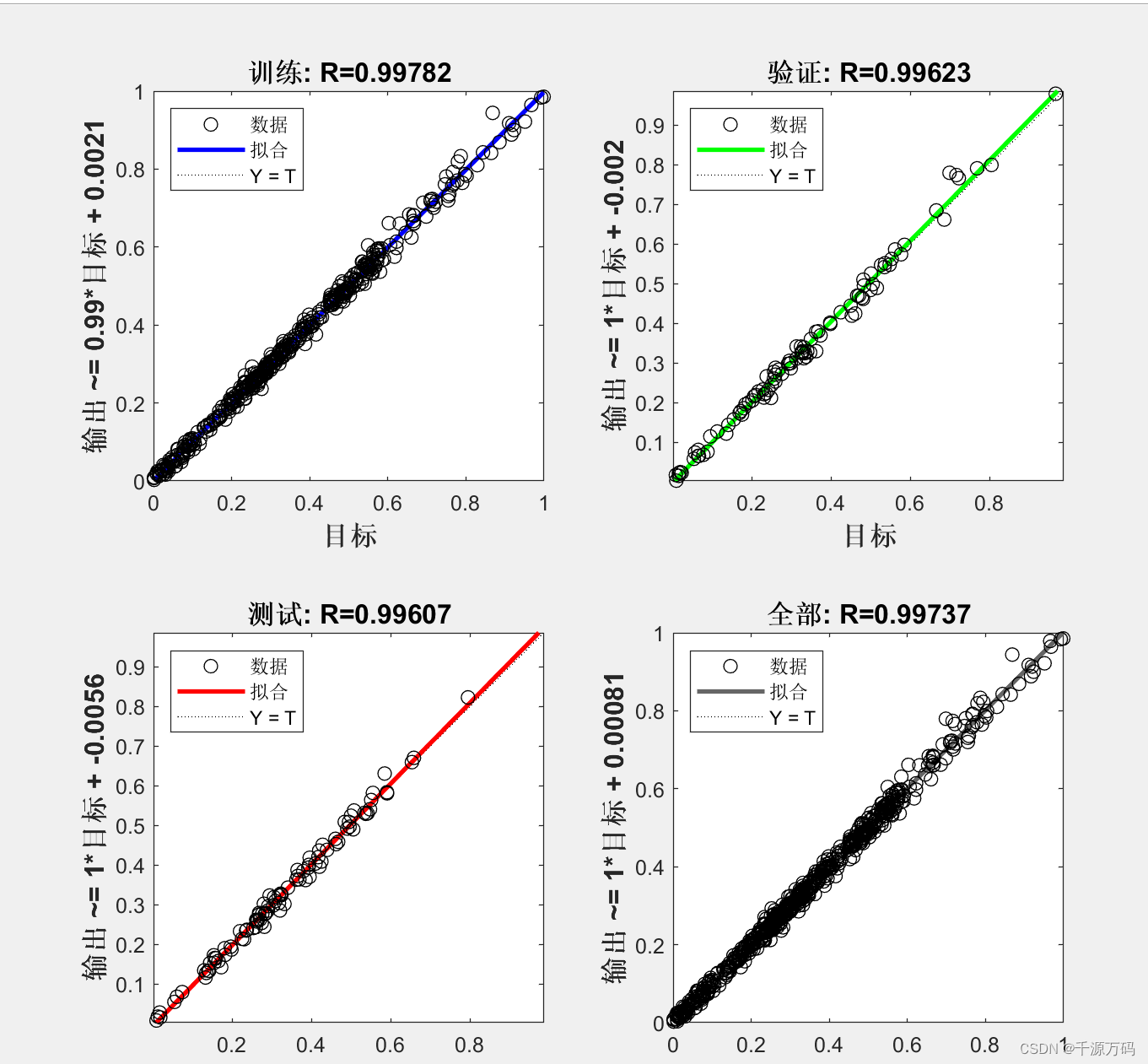
资源下载: https://download.csdn.net/download/vvoennvv/88682033
—— 隐藏版本号)













的安装)

QIcon派生,更易用的纯色Icon)


