
标题:《GenFusion: Closing the Loop between Reconstruction and Generation via Videos》
来源:西湖大学;慕尼黑工业大学;上海科技大学;香港大学;图宾根大学
项目主页:https://genfusion.sibowu.com
文章目录
- 摘要
- 一、前言
- 二、 Reconstruction-driven Generation
- 三、 Cyclic Fusion 循环融合
- 四、实验
- 4.1 实验设置
- 4.2 视频生成
- 4.3 视图插值
- 4.4 视图外推
- 总结
摘要
最近,3D重建和生成展示了令人印象深刻的新型视图合成结果,实现了高保真度和高效性。然而,在这 两个领域之间可以观察到显著的条件差距 ,例如,可扩展的3D场景重建通常需要密集捕捉的视图,而3D生成则通常依赖于单个或没有输入视图,这极大地限制了它们的应用。原因在于3D约束与生成先验之间的不匹配。为了解决这个问题,我们 提出了一种重建驱动的视频扩散模型,该模型学习讲易产生伪影的RGB-D渲染图像作为视频帧的条件 。此外,我们 提出了一种循环融合管道(cyclical fusion pipeline),迭代地将生成模型的修复帧添加到训练集中,逐步扩展并解决先前重建和生成管道中出现的视角饱和问题 。评估实验包括稀疏视角和mask输入的视图合成,验证了方法有效性。
一、前言
生成3D资产是计算机视觉和计算机图形学中的基础任务,在增强现实/虚拟现实、自动驾驶和机器人技术中有着广泛的应用。最近,神经辐射场(NeRF [36],Mildenhall等人于2020年)和高斯喷射(GS [27],Kerbl等人于2023年)的进展使得高保真3D场景重建和新颖视图合成成为可能。这些方法使用MLP或高斯基元来表示场景,并通过光度损失优化3D表示。然而,这一系列工作继承了一个关键限制:忠实重建依赖于丰富的视角覆盖;未充分观察到的区域或视角可能导致显著的伪影或缺失内容。
这主要是因为从多视角图像重建NeRF或GS本质上是欠约束的,因为输入图像可能存在无数个照片一致性解释[41,64]。因此,即使提供了密集且高质量捕捉的图像[47],重建模型也倾向于生成“漂浮物”或“背景塌陷”伪影,以模拟视图依赖效应。这一观察结果激发了一系列正则化技术来约束神经场训练,包括稀疏正则化器[22,57]、平滑损失[37,56,63]和单目几何线索[62]。例如,ReconFusion [49]通过在新颖的随机相机姿态与由PixelNeRF风格图像扩散模型预测的图像之间引入样本损失,来正则化基于NeRF的3D重建流程,在稀疏设置下显著提升了性能。
相比之下,前馈重建方法[5,6,10,14,58,61]直接从数据集中学习归纳偏置。尽管最近的技术进步使得可以从单张图像进行三维重建,但现有的前馈重建方法在处理超过4-8张图像时表现出性能饱和。这一限制主要源于传统前馈网络在有效聚合和利用多视角信息方面的架构约束。同时,生成方法展示了无需多视角捕捉即可获得3D资产的潜力。利用大规模数据集和可扩展架构,像Stable Diffusion(SD)这样的模型在图像和视频生成方面取得了显著进展[3,21,23]。最近的研究将这些方法应用于生成3D资产。例如,DreamFusion [39]引入了Score Distillation Sampling(SDS),使用预训练的2D文本到图像扩散模型进行文本到3D的合成,而另一条研究线[4,30,60]则通过逐步in/out painting 分层深度图像来探索单视角场景外推。
尽管在三维重建和生成方面取得了进展,但一个显著的条件差距仍然存在:可扩展的三维重建通常需要密集的视图覆盖,而生成方法往往仅使用单个或甚至没有输入视图。我们的论文探讨了如何以可扩展的方式使三维重建和生成相互补充,从而放宽对输入视图数量的限制。
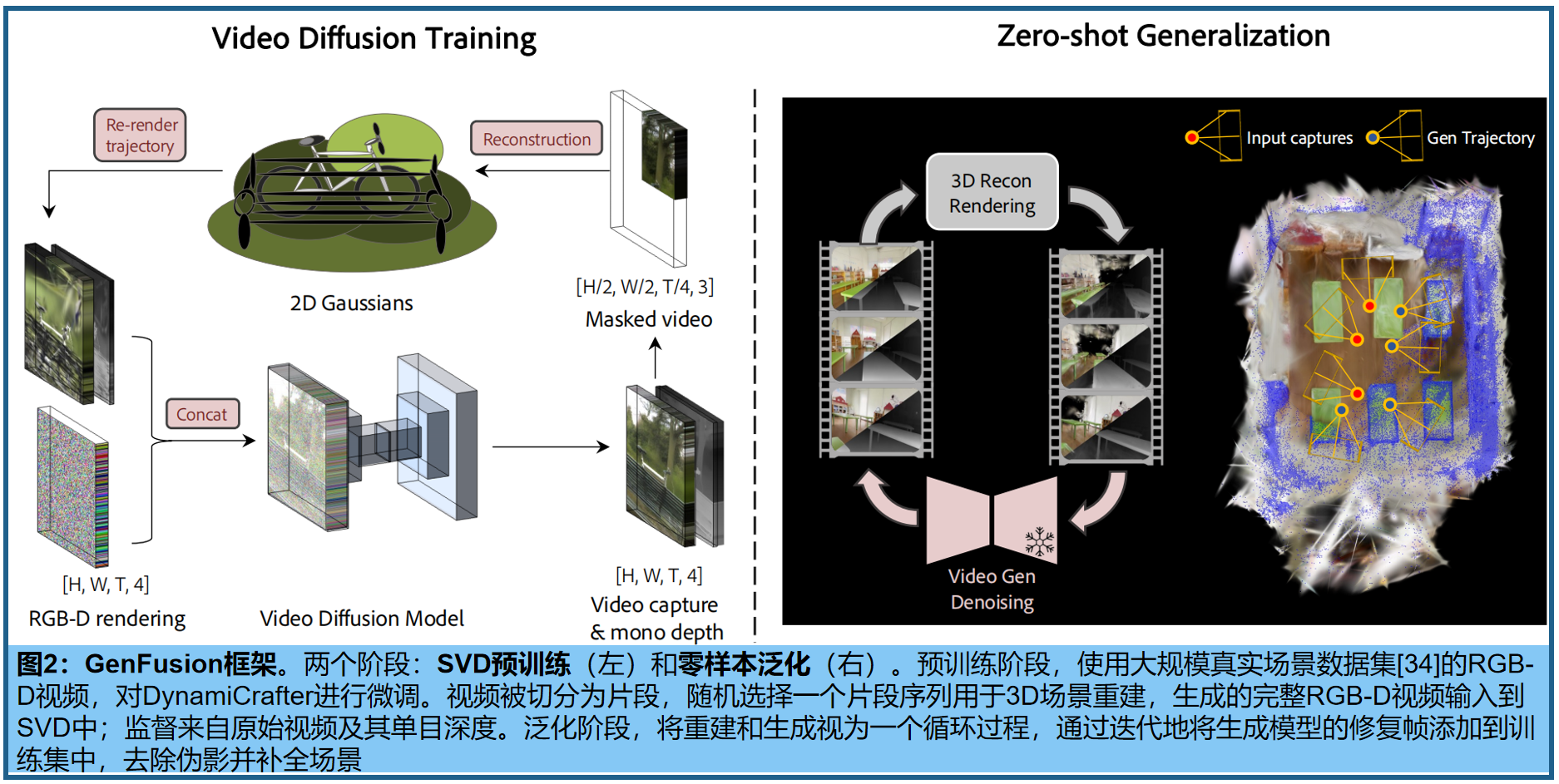
GenFusion核心是一个简单且可扩展的基于重建的视频生成架构,能够从易产生伪影的渲染图中预测出逼真的视频。 其目标是构建无伪影的3D场景,并通过条件视图{ I i I_i Ii} ( i > = 1 ) (i >= 1) (i>=1)进行内容增强。核心思想是通过视频渲染来对齐3D重建和生成。此方法中,3D重建和生成相互促进形成良性循环:重建过程,迭代利用生成模型的信息以提高重建质量;同时,更准确的重建结果有助于生成模型 产生更加真实和一致的内容。这种双向增强机制形成了一个正反馈回路。
预训练阶段目标:训练一个扩散模型,从大规模场景中学习。(该模型已从易产生伪影的3D重建的渲染上进行了预训练)。具体来说,通过最大化(从mask输入生成完整图像)的期望对数似然,来训练生成模型 G φ G_φ Gφ:
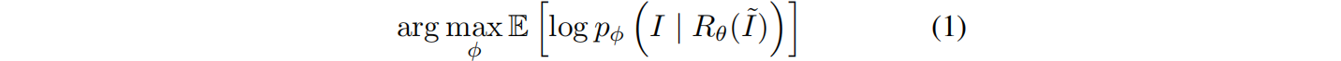
其中, R θ R_θ Rθ表示重建和渲染函数(如NeRF或3DGS), I ~ \tilde{I} I~ 表示mask后的真实图像。为了使生成过程具有三维感知能力,视频扩散模型以带伪影的渲染视频 R θ ( I ~ ) R_θ(\tilde{I}) Rθ(I~)为条件,来学习捕捉图像的底层分布。
公式1的拓展:通过视频扩散模型优化三维场景表示 θ θ θ,该表示同时受输入图像条件和新场景生成视频的指导。具体采用最大化 (3D渲染器渲染的k+1新视图) 与 (扩散模型基于当前k帧的渲染图像生成的下一帧预测) 之间的L2误差,因此三维表示的梯度从光度损失中传播(k 表示iteration索引):
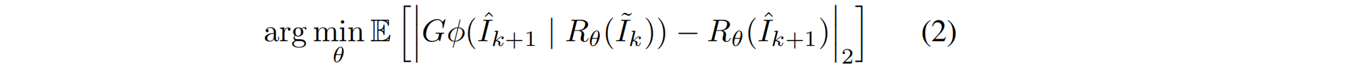
二、 Reconstruction-driven Generation
基于mask的3D重建 。 我们现在讨论如何在开放世界的大型视频重建范式中学习新颖视角的泛化能力。给定场景的视频片段,一种直接的方法是均匀间隔地降采样帧或在输入序列的中点分割为训练/测试段以进行场景重建,然后从测试相机视角渲染重建的场景以生成易产生伪影的数据。将渲染序列和原始视频片段随后作为视频扩散模型训练的输入和输出对。然而,我们观察到这些采样方案将模型限制在视图插值或纯生成上。具体来说,场景通常被采样的视图完全覆盖,目标视图位于这些视图附近,而另一种方法往往导致训练段中的大部分内容未被看到。 我们的工作旨在学习正则化,并在显著偏离捕捉轨迹的路径中生成新内容。
为此,我们提出了一种 掩码3D重建技术,从空间和时间维度的观测中获取受损的3D场景,然后渲染整个输入序列的图像,来生成训练数据集 。具体来说,我们将输入图像捕捉分为4个规则且不重叠的区域,即左上、右上、左下和右下,如图3所示。然后我们对每个场景的左上或右下区域进行采样,并遮住(即移除)其余三个区域。所采样的补丁序列用于通过标准方法进行三维重建,即二维高斯喷射(2DGS)。mask区域在同一场景中相同,迫使重建过程具有有限的视图覆盖范围。实际上,由于我们在训练中使用了开放世界的大型视频序列capture I I I,这进一步增加了稀疏性−视图仅在轨迹上密集,但在角度覆盖上极其稀疏−与标准多视图数据集如Mip-NeRF 360 [1]不同。
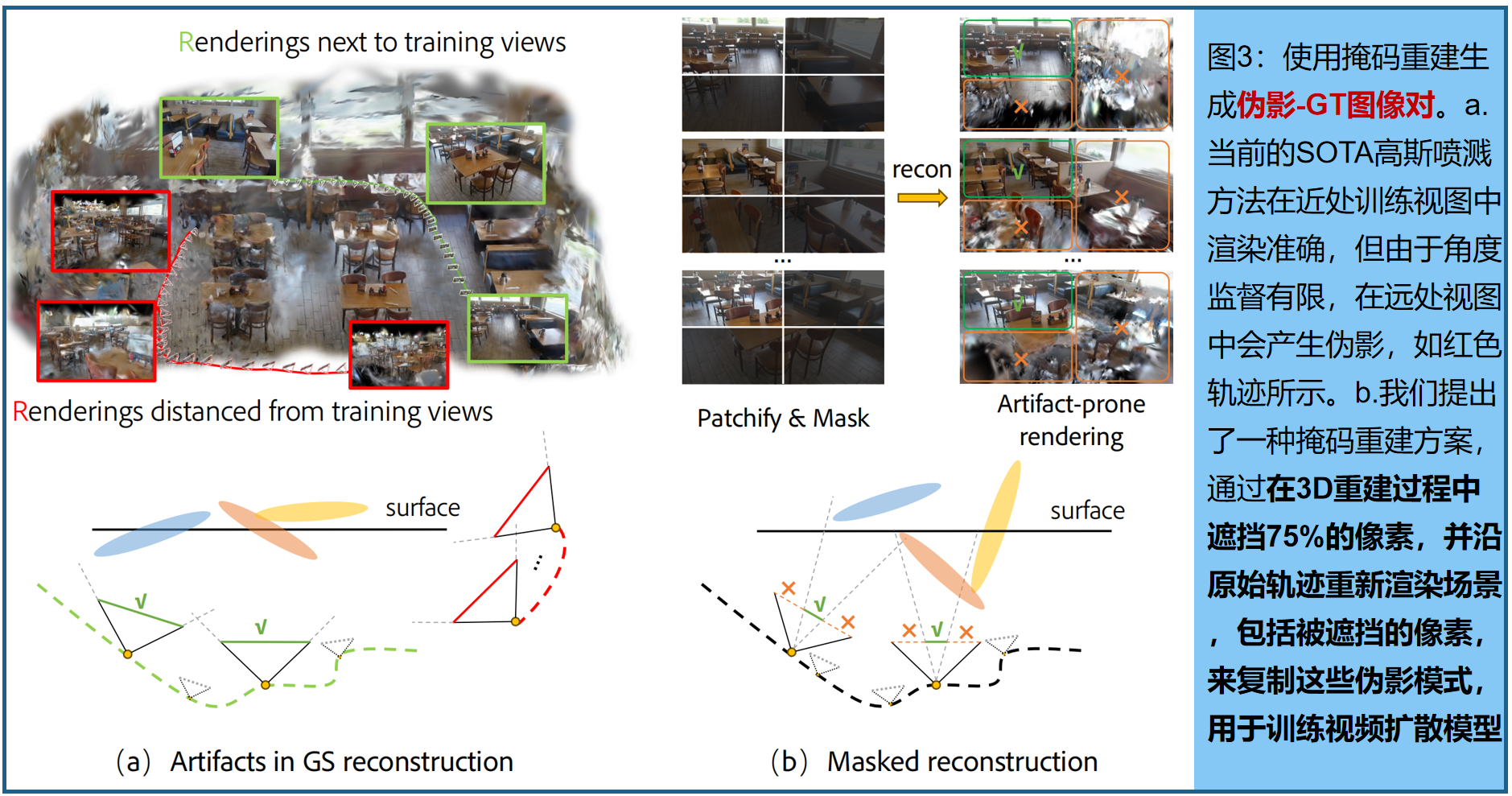
掩码重建:沿着与输入相同的相机位姿渲染更大视图的视频,以形成真实和重建的图像对,用于SVD训练。我们的见解是, 从掩码图像中重建模拟了一个视野较窄的相机,需要从偏离当前视角的视图中推断出掩码外的上下文,这促进了视图外推 。此外,渲染到全视图引入了不受约束的区域,背景广泛为黑色,有助于内容外填充。
视频扩散模型 。具体采用预训练的DynamiCrafter [52](图像到动画模型)的基础上构建视频生成模型,通过在生成过程中融入几何信息来增强帧一致性。其中,将预训练的RGB-D VAE替换base模型中的VAE,来整合深度信息;编码器和解码器分别表示为𝓔和 D D D。训练时,真实RGBD视频 I R G B − D I_{RGB−D} IRGB−D被编码到潜在空间 z : = z:= z:=𝓔 ( I R G B − D ) (I_{RGB−D}) (IRGB−D),在不同的时间步 t t t 中加入噪声,从而获得 z t z_t zt。为生成提供两个条件:首先,编码有伪影的RGB-D视频 I R G B − D ′ I'_{RGB−D} IRGB−D′,并逐帧加入初始噪声,作为序列的条件,利用视觉细节影响生成过程;此外,选择最接近渲染轨迹的输入视图,并将对应的真实图像嵌入为CLIP特征,提供高层次的整体场景信息。视频去噪网络%ϵ_θ%优化为:
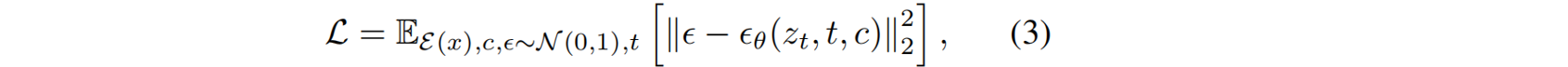
通过预训练的VAE解码器 V ^ = D ( z ) \hat{V}= D(z) V^=D(z) [44],refined latent 解码成最终的RGB-D视频。
三、 Cyclic Fusion 循环融合
我们基于2DGS来融合三维重建和视频扩散的输出,使用多个面向二维的平面高斯圆盘来表示三维场景。高斯圆盘通过中心位置 p ∈ R 3 × 1 p∈R^{3×1} p∈R3×1、不透明度(尺度) α ∈ [ 0 , 1 ] α∈[0,1] α∈[0,1]、两个主切向量 t u t_u tu和 t v t_v tv用于方向、calling vector S = ( s u , s v ) S=(s_u,s_v) S=(su,sv) 以及球谐重构生成(SH)系数进行参数化。
融合。按照原始3DGS方法初始化高斯及属性,并根据渲染损失端到端地更新高斯。优化过程是重建和生成的循环,同时利用输入条件和新生成的视图监督高斯。具体来说,每K次迭代首先生成新轨迹,基于当前的重建渲染RGB-D视频;然后将渲染序列输入到SVD中,生成无伪影的视频,并添加到监督集中,如图2。循环过程能够在观察不足的区域进行伪影校正,并为在输入视图中不可见的区域生成新内容。
其中,我们发现新的轨迹采样是最关键的组成部分。为了确保全面的视角和角度覆盖,我们采用了两种类型的轨迹:邻近输入视图之间的视角插值和在所有输入相机姿态之间生成的螺旋/球形路径(spiral/spherical path)。
内容扩展。大型未观察区域在采样轨迹远离输入视图时,可能会表现为黑色或噪点像素。尽管我们使用生成输出作为这些区域的监督,但由于周围没有高斯分布,我们将新的高斯[27]拆分和克隆变得非常困难。我们通过在优化过程中自适应地向场景中添加新的高斯点来解决这个问题,使用了 unreliable depth-based mapping。像素满足以下公式时,被认定是 unreliable :
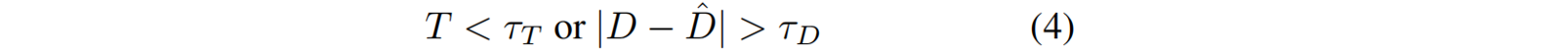
其中, T T T是累积不透明度, D D D和 D ^ \hat{D} D^分别是渲染深度和对齐的生成深度。 τ T τ_T τT和 τ D τ_D τD是阈值。
对于这些不可靠的区域,我们将生成的RGB-D点反投影到三维空间中来添加新的高斯,类似于初始化阶段。注意,对于新添加的高斯,位置和颜色值直接从RGB-D视频中获得,而其他属性则按照2DGS初始化。
损失函数。在Cyclic Fusion过程,冻结SVD,并使用渲染的RGB-D图像和输入( L r e c o n L_{recon} Lrecon)以及生成视图( L g e n L_{gen} Lgen)之间的简单光度损失,对3D表示进行端到端优化。
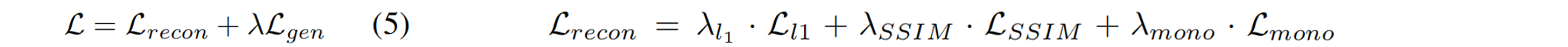
L m o n o L_{mono} Lmono是一种尺度不变的深度损失,如[Monosdf]所使用的,它强制渲染深度 D ^ \hat{D} D^ˆ与SVD预测的单目深度 D D D之间的一致性。生成损失 L g e n L{gen} Lgen共享组件,但应用于生成的图像。
为了稳定优化过程,使用正弦warm-up及退火策略来生成损失权重 λ λ λ,其定义为:
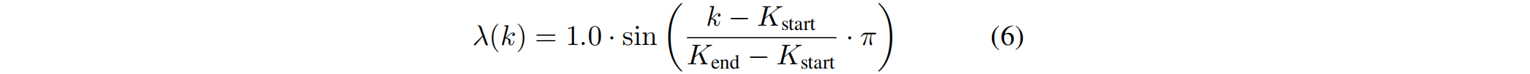
四、实验
4.1 实验设置
训练集:训练扩散模型的数据集为DL3DV- 10K [34],包含10,510个视频,140个基准场景。使用3.1节介绍的掩码3D重建方案,每个场景优化7,000步。为了确保足够的稀疏性,每个视频的训练视图数量均匀降采样至四分之一,并以960×540的分辨率沿原始轨迹渲染重建场景,同时使用当前的SOTA单目深度估计器Depthcrafter[24]增强数据集的深度信息。评估数据集:DL3DV-Benchmark [34]的24个场景、Tanks and Temples(TnT)[28]的7个场景以及来自Mip-NeRF360 [1]数据集的9个场景。
实施细节:采用DynamiCrafter [52]作为SVD的主干,并在伪影-GT RGB-D视频对上微调模型。微调过程包括粗调和精调两个阶段:在粗调阶段,视频分辨率设置为16×320×512×4,潜在空间维度为16×40×64×4。我们在四块H100 GPU上以 1 × 1 0 − 5 1×10^{−5} 1×10−5的学习率和2的批量大小训练此阶段30K步。然后,模型在精调阶段进一步微调至更高的分辨率16×512×960×4,再训练34K步。为了处理RGB-D格式,我们使用了来自LDM3D [44]的冻结RGB-D VAE。在推理过程中,我们应用DDIM采样,步数为25,并将无分类器引导尺度设置为3.2。
对于零样本泛化,我们使用2DGS作为三维表示,并用COLMAP点云初始化。在我们的实验中,视图被屏蔽,帧被下采样;我们过滤并仅保留从训练视图可见的点,用于点云初始化。
4.2 视频生成
本文介绍的基于重建的视频扩散架构,能够实现新视角的正则化和内容生成。表1中报告了VAE的设计及其对视频分辨率的影响,使用RGB-D VAE微调的模型在FID得分上优于RGB VAE(尽管扩散主干最初是在RGB VAE潜在空间上预训练的)。当空间分辨率从512×320增加到960×512时,可以观察到显著的改进。图4中展示了扩散模型的可视化结果:有效地去除了输入视频中的“漂浮物”,同时在黑色像素区域生成逼真的内容。


4.3 视图插值
目标场景完全被输入视图覆盖,测试视图介于输入之间——这是先前正则化评估中的常见设置。我们使用3、6和9个输入视图,在Mip-NeRF 360测试集上将我们的方法与之前的正则化技术进行了比较,如表2所示。

结果表明,我们的方法在新颖视角合成方面比3DGS和2DGS基线以及最近的FSGS取得了显著优势。值得注意的是,高斯喷溅训练难度通常高于NeRF,尤其是在稀疏视角设置下。我们大幅缩小了这一差距,并首次证明,在稀疏视角设置下的Mip-NeRF360数据集上,高斯喷溅的性能可与最先进的NeRF相媲美。(见表2和图5)。

4.4 视图外推
不同于稀疏视图,从视频中生成完整且无伪影的3D场景更实际。视频沿轨迹提供了密集的采样,但视角覆盖高度稀疏。虽然视频易于捕捉和校准,但对于3D重建来说却颇具挑战性,即使使用最先进的重建方法,也容易过度拟合训练视图,并在远离训练视图的视角上产生严重的伪影,见图3。因此,我们关注 far field 的新视角合成质量
为此,我们提出了一种新的评估协议,并重用掩码重建来模拟远场渲染,同时保留参考。具体来说,按照不同的时间比例分割训练/测试集,对视频序列进行降采样(例如表3中的1/2和1/4),并选择覆盖训练视角约25%像素块进行重建;同时在测试视角的全视场进行评估。固定路径位置可能会导致许多不可见和黑色区域,从而在我们的生成方法中产生偏差,基线在这些区域可能有显著误差。为了确保合理的比较,我们为masked path分配了一条轨迹,以提供更完整的内容覆盖,详见补充视频。表3和图6展示了我们的方法与基线在DL3DV-benchmark和TnT场景上的定量和定性结果。GenFusion凭借扩散模型的强大先验,显著提升了渲染质量,有效去除了针状伪影,并为不可见区域增强了逼真的3D内容。


场景 Completion。此外,GenFusion不仅在3D场景边界提供内容增强,而且实现了场景级完成,如图1所示。
总结
GenFusion,一种新颖的无伪影3D资产生成模型。首先,我们将现有的训练良好的2D视频扩散模型进行了最小修改,以驱动强大的3D引导。其次,循环融合实现了可扩展且稳健的3D提升,通过视频合成高效地闭合了3D重建与生成之间的循环。然而,该方法存在一些局限性:需要额外的去噪步骤,训练时间略有增加(每个场景约40分钟)。填充大型不可见区域会导致模糊,因为视频片段之间存在不一致。在融合模块中建模并解决这种不一致性将是实现更高质量的关键步骤


)







)

:基于大语言模型的语音合成革新者!!!)






