eBPF是监控云原生应用的强大工具,本文介绍了DoorDash构建基于eBPF的监控系统的实践。原文: BPFAgent: eBPF for Monitoring at DoorDash
随着DoorDash在过去几年中经历了快速增长,我们开始看到传统监控方法的局限性。度量、日志和跟踪提供了服务生态系统的重要信息,但这些信号几乎完全依赖应用程序级别的检测,不同系统可能会互相冲突。因此我们决定寻找能够提供更完整、统一的网络拓扑的潜在解决方案。
其中一种解决方案是基于eBPF进行监控,该机制允许开发人员编写直接注入内核的程序,并能够跟踪内核操作。这些程序可以轻量级访问大多数内核组件,程序运行在内核沙箱内,并且在执行之前会进行安全性验证。DoorDash对通过名为kprobes(内核动态跟踪)和跟踪点(tracepoint)的钩子跟踪网络流量特别感兴趣,通过这些钩子,可以拦截和理解跨多个Kubernetes集群的TCP、UDP连接。
通过在内核构建基础设施级别的网络流量监控,让我们对DoorDash独立于服务业务流的后端生态系统有了新的认识。
为了运行这些eBPF探针,我们开发了一个名为BPFAgent的Golang应用程序,将其作为所有Kubernetes集群中的守护进程运行。本文将介绍如何构建BPFAgent,构建和维护探针的过程,以及各个DoorDash团队如何使用收集到的数据。
构建BPFAgent
我们用bcc和iovisor/gobpf库开发了第一版BPFAgent,这个初始版本帮助我们了解了如何在Kubernetes环境中开发和部署eBPF探针。
虽然可以很快确认投资开发BPFAgent的价值,但我们也经历了糟糕的开发生命周期以及缓慢的启动时间等多个痛点。使用bcc意味着探针是在运行时编译的,这会大大增加部署新版本的启动时间,从而使得新版本的平滑升级变得困难,因为部署监控需要相当长时间。此外,探针对Kubernetes节点的Linux内核版本有很强的依赖性,所有内核版本都必须在Docker镜像中考虑。很多情况下,对Kubernetes节点底层操作系统的升级会导致BPFagent停止工作,直到更新到支持新的Linux版本为止。
我们很高兴的发现,社区已经开始通过BPF CO-RE(一次编译,到处运行)来解决这些痛点。使用CO-RE,我们从运行时的bcc编译,转变为在BPFAgent Golang应用程序的构建过程中使用Clang编译。这一更改依赖于Clang支持以BPF类型格式(BTF,BPF Type Format)编译的能力,这种能力通过利用libbpf和内存重定位信息创建可执行的探针版本,这些版本在很大程度上独立于内核版本。这个更改可以防止大多数操作系统和内核更新影响到BPFAgent应用或探针。有关BPF可移植性和CO-RE的更详细介绍,请参阅Andrii Nakryiko关于该主题的博客文章[1]。
Cilium项目有一个特殊的cilium/ebpf Golang库,可以编译Golang代码中的eBPF探针并与之交互。它提供了易于使用的go:generate集成,可以通过Clang将eBPF C代码编译成BTF格式,然后将BTF工件封装在易于使用的go包中以加载探针。
在切换到CO-RE和cilium/ebpf后,我们发现内存使用量减少了40%,由于oomkill导致的容器重启减少了98%,每个Kubernetes集群的部署时间减少了80%。总的来说,单个BPFAgent实例保留的CPU内核和内存不到典型节点的0.3%。
BPFAgent内部组件
BPFAgent应用由三个主要组件组成。如图1所示,BPFAgent首先通过eBPF探针检测内核,以捕获和生成事件。然后将这些事件发送给处理器,以根据进程和Kubernetes信息进行填充。最后,通过导出器将丰富的事件发送到数据存储。
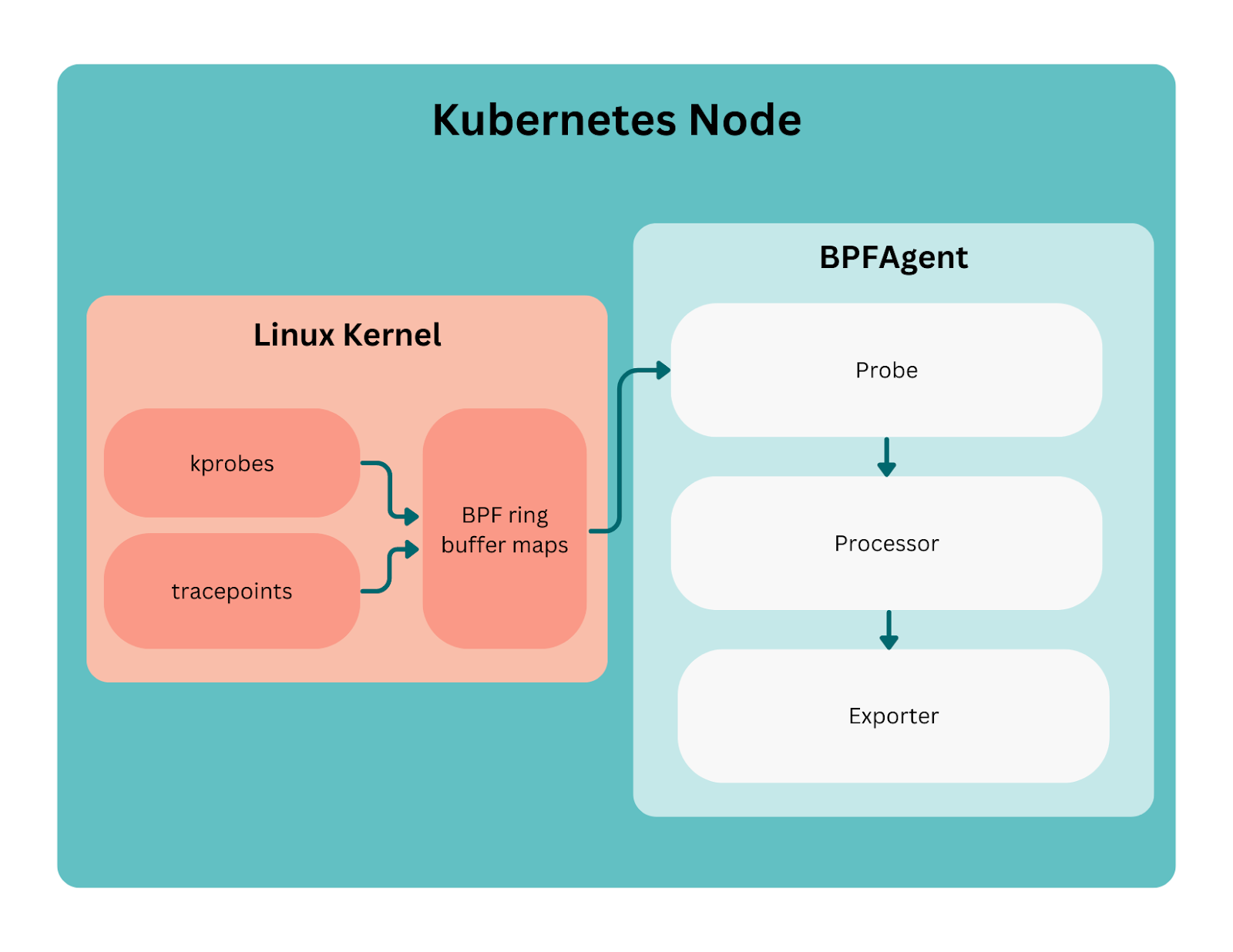
让我们深入了解如何构建和维护探针。每个探针都是一个Go模块,包含三个主要组件: eBPF C代码及其生成的工件、探针执行器和事件类型。
探针执行器遵循标准模式。在初始探针创建期间,通过生成的代码(下面代码片段中的loadBpfObjects函数)加载BPF代码,并为事件创建管道,这些事件将被发送给bpfagent的处理器和导出函数进行处理。
type Probe struct {
objs bpfObjects
link link.Link
rdr *ringbuf.Reader
events chan Event
}
func New(bufferLimit int) (*Probe, error) {
var objs bpfObjects
if err := loadBpfObjects(&objs, nil); err != nil {
return nil, err
}
events := make(chan Event, bufferLimit)
return &Probe{
objs: objs,
events: events,
}, nil
}
然后,该对象作为BPFagent Attach()过程的一部分被注入内核。探针被加载、附加并链接到所需的Linux系统调用(如skb_consume_udp)。成功后,将创建一个新的环形缓冲区读取器,并引用我们的BPF环形缓冲区。最后,启动程序来轮询要解析并发布到管道的新事件。
func (p *Probe) Attach() (<-chan *Event, error) {
l, err := link.Kprobe("skb_consume_udp", p.objs.KprobeSkbConsumeUdp, nil)
// ...
rdr, err := ringbuf.NewReader(p.objs.Events)
// ...
p.link = l
p.rdr = rdr
go p.run()
return p.events, nil
}
func (p *Probe) run() {
for {
record, err := p.rdr.Read()
// ...
var event Event
if err = event.Unmarshal(record.RawSample, binary.LittleEndian); err != nil {
// ...
}
select {
case p.events <- event:
continue
default:
// ...
}
}
...
}
事件本身很简单。例如,DNS探测是一个仅包含网络命名空间id (netns)、进程id (pid)和原始数据包数据的事件。我们通过一个解析函数,将内核中的原始字节转换为我们的数据结构。
type Event struct {
Netns uint64
Pid uint32
Pkt [4084]uint8
}
func (e *Event) Unmarshal(buf []byte, order binary.ByteOrder) error {
if len(buf) < 4096 {
return fmt.Errorf("expected input too small, len([]byte) = %d", len(buf))
}
e.Netns = order.Uint64(buf[0:8])
e.Pid = order.Uint32(buf[8:12])
copy(e.Pkt[:], buf[12:4096])
return nil
}
我们一开始使用编码/二进制来解码。然而通过profiling,不出所料的发现大量CPU时间用于解码。这促使我们创建一个自定义的数据解码过程来代替基于反射的数据解码。基准测试改进验证了这一决定,并帮助我们保持BPFAgent的轻量。
pkg: github.com/doordash/bpfagent/pkg/tracing/dns
cpu: Intel(R) Core(TM) i9-8950HK CPU @ 2.90GHz
BenchmarkEventUnmarshal-12 8289015 127.0 ns/op 0 B/op 0 allocs/op
BenchmarkEventUnmarshalReflect-12 33640 35379 ns/op 8240 B/op 3 allocs/op
接下我们来讨论eBPF探针本身。探针大多数是kprobe,提供了跟踪Linux系统调用的优化访问。使用kprobe,我们可以拦截特定系统调用并检索提供的参数和执行上下文。在此之前,我们使用的是fentry版本的探针,但由于我们用的是基于ARM的Kubernetes节点,而当前的Linux内核版本不支持基于ARM架构优化的入口探测,所以改用kprobe。
对于网络监控,探针可以捕获以下事件:
-
DNS -
kprobe/skb_consume_udp
-
-
TCP -
kprobe/tcp_connect -
kprobe/tcp_close
-
-
Exit -
tracepoint/sched/sched_process_exit
-
为了捕获DNS查询和响应,由于大多数DNS流量都是通过UDP传输的,因此可以通过skb_consume_udp探针拦截UDP数据包。
struct sock *sk = (struct sock *)PT_REGS_PARM1(ctx);
struct sk_buff *skb = (struct sk_buff *)PT_REGS_PARM2(ctx);
// ...
evt->netns = BPF_CORE_READ(sk, __sk_common.skc_net.net, ns.inum);
unsigned char *data = BPF_CORE_READ(skb, data);
size_t buflen = BPF_CORE_READ(skb, len);
if (buflen > MAX_PKT) {
buflen = MAX_PKT;
}
bpf_core_read(&evt->pkt, buflen, data);
如上所示,skb_consume_udp可以访问套接字和套接字缓冲区,然后可以使用BPF_CORE_READ等辅助函数从结构中读取所需数据。这些帮助程序特别重要,因为它们支持跨多个Linux版本使用相同的编译探针,并且可以处理跨内核版本内存中的任何数据重定位。
对于TCP,我们使用两个探针来跟踪连接何时启动和关闭。为了创建连接,我们探测tcp_connect,它同时处理TCPv4和TCPv6连接。该探针主要用于隐藏对套接字的引用,以获取有关连接源的基本上下文信息。
struct source {
u64 ts;
u32 pid;
u64 netns;
u8 task[16];
};
struct {
__uint(type, BPF_MAP_TYPE_LRU_HASH);
__uint(max_entries, 1 << 16);
__type(key, u64);
__type(value, struct source);
} socks SEC(".maps");
为了获取TCP连接事件,我们等待与tcp_connect相关联的tcp_close调用。我们用struct sock *作为键查询bpf_map_lookup_elem。这么做的目的是因为来自bpf_get_current_comm()等bpf帮助程序的上下文信息在tcp_close探测中并不总是准确。
struct sock *sk = (struct sock *)PT_REGS_PARM1(ctx);
if (!sk) {
return 0;
}
u64 key = (u64)sk;
struct source *src;
src = bpf_map_lookup_elem(&socks, &key);
在捕获连接关闭事件时,我们需要获取连接发送和接收的字节数。为此,我们根据套接字的网络族将套接字转换为tcp_sock (TCPv4)或tcp6_sock (TCPv6)。这些结构包含RFC 4898[2]中描述的扩展TCP统计信息,因此有可能让我们获取到需要的统计数据。
u16 family = BPF_CORE_READ(sk, __sk_common.skc_family);
if (family == AF_INET) {
BPF_CORE_READ_INTO(&evt->saddr_v4, sk, __sk_common.skc_rcv_saddr);
BPF_CORE_READ_INTO(&evt->daddr_v4, sk, __sk_common.skc_daddr);
struct tcp_sock *tsk = (struct tcp_sock *)(sk);
evt->sent_bytes = BPF_CORE_READ(tsk, bytes_sent);
evt->recv_bytes = BPF_CORE_READ(tsk, bytes_received);
} else {
BPF_CORE_READ_INTO(&evt->saddr_v6, sk, __sk_common.skc_v6_rcv_saddr.in6_u.u6_addr32);
BPF_CORE_READ_INTO(&evt->daddr_v6, sk, __sk_common.skc_v6_daddr.in6_u.u6_addr32);
struct tcp6_sock *tsk = (struct tcp6_sock *)(sk);
evt->sent_bytes = BPF_CORE_READ(tsk, tcp.bytes_sent);
evt->recv_bytes = BPF_CORE_READ(tsk, tcp.bytes_received);
}
最后,我们用tracepoint探针跟踪进程何时退出。tracepoint由内核开发人员添加,用于hook内核中发生的特定事件。因为不需要绑定到特定系统调用,因此其设计比kprobe更稳定。该探针的事件用于从内存缓存中取出数据。
所有探针都在CI流水线中基于cilium/ebpf并用clang编译。
所有原始事件都必须添加有用的识别信息。由于BPFAgent是部署在节点进程ID命名空间中的Kubernetes守护进程,因此可以直接从/proc/:id/cgroup中读取进程cgroup。因为节点上运行的大多数进程都是Kubernetes pod,所以大多数cgroup标识符看起来像这样:
/kubepods.slice/kubepods-pod8c1087f5_5bc3_42f9_b214_fff490864b44.slice/cri-containerd-cedaf026bf376abf6d5c4200bfe3c4591f5eb3316af3d874653b0569f5208e2b.scope.
基于约定,我们可以提取pod的UID(在/kubepods-pod和.slice之间)以及容器ID(在cri-containerd-和.scope之间)。
有了这两个id,我们就可以检查Kubernetes pod信息的内存缓存,找到绑定连接的pod和容器。每个事件都用容器、pod和命名空间名称进行注释。
最后,使用google/gopacket库对前面提到的DNS事件进行解码。通过解码数据包,可以导出事件,其中包括DNS查询类型、查询问题和响应代码。在此处理过程中,我们使用DNS数据创建(netns, ip)到(hostname)的内存缓存映射。此缓存用于使用与连接关联的可能主机名进一步丰富TCP事件中的目标IP。简单的IP到主机名查找是不实际的,因为单个IP可能由多个主机名共享。
BPFAgent导出的数据被发送到可观测Kafka集群,在那里每个数据类型被分配一个topic。然后,这些大批量的数据被储存到ClickHouse集群中。团队可以通过Grafana仪表板与数据进行交互。
使用BPFAgent的好处
可以看到,到目前为止,上面所介绍的数据是有帮助的,eBPF数据在提供独立于所部署的应用程序的见解方面确实表现出色。以下是DoorDash团队如何使用BPFAgent数据的一些示例:
-
在我们向单一服务所有权推进的过程中,我们的存储团队使用这些数据来调查共享数据库。可以根据常见的数据库端口(如PostgreSQL的5432)进行TCP连接过滤,然后根据目标主机名和Kubernetes命名空间进行聚合,以检测多个命名空间使用的数据库。这些数据可以使他们避免将不同服务的指标混淆起来,因为指标可能有一样的命名约定。 -
我们的流量团队使用这些数据来检测发夹(hairpin)流量,即在从公共互联网重新进入虚拟私有云之前退出的内部流量,这会产生额外的成本和延迟。BPF数据使我们能够快速找到针对面向外部主机名(如api.doordash.com)的内部流量,一旦能够消除这种流量,团队就能自信的建立流量策略,禁止未来的发夹流量。 -
我们的计算团队用DNS数据来更好的理解DNS流量的峰值。虽然以前也有节点级的DNS流量指标,但并没有基于特定的DNS问题或源pod分解。有了BPF数据,就能够找到行为不良的pod,并与团队一起优化DNS流量。 -
产品工程团队使用这些数据来支持向市场分片Kubernetes集群的迁移。这种迁移需要服务的所有依赖项都采用 基于Consul的服务发现 [3]。BPF数据是一个重要的事实来源,可以突出显示任何意外交互,并验证所有客户端都已转移到新的服务发现方法。
结论
实现BPFAgent使我们能够理解网络层的服务依赖关系,并更好的控制微服务和基础设施。我们对新的见解感到兴奋,这促使我们扩展BPFAgent,以支持网络流量监视之外的其他用例。首先要做的是构建探针以从共享配置卷中捕获对文件系统的读取,从而在所有应用程序中推动最佳实践。
我们期待加入更多用例,并推动平台在未来支持性能分析和按需探测。我们还希望探索新的探测类型以及Linux内核团队创建的任何新钩子,以帮助开发人员更深入了解他们的系统。
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。为了方便大家以后能第一时间看到文章,请朋友们关注公众号"DeepNoMind",并设个星标吧,如果能一键三连(转发、点赞、在看),则能给我带来更多的支持和动力,激励我持续写下去,和大家共同成长进步!
参考资料
BPF Portability and CO-RE: https://nakryiko.com/posts/bpf-portability-and-co-re
[2]RFC 4898: TCP Extended Statistics MIB: https://www.rfc-editor.org/rfc/rfc4898.html
[3]Consul: https://www.consul.io
本文由 mdnice 多平台发布


)
数据类型-复合类型)




)

)





)


