目录
1.缺失数据处理
1.1 DataFrame自身产生的缺失数据
1.2 缺失数据判断和统计
1.3 缺失数据清理
2. 多源数据操作
2.1 合并函数:merge()
2.2 连接函数:join()
2.3 指定方向合并:concat()
3. 数据分组和聚合运算
3.1 groupby()方法
3.2 聚合:aggregate()方法
3.2.1 一般聚合使用
3.2.2 分组聚合
1.缺失数据处理
1.1 DataFrame自身产生的缺失数据

通过调整列名(reindex), 并增加带缺失值的‘four’列。
M2=M1.reindex(columns=['two','one','three','four'])
1.2 缺失数据判断和统计
 1.3 缺失数据清理
1.3 缺失数据清理
(1)常量替代 :
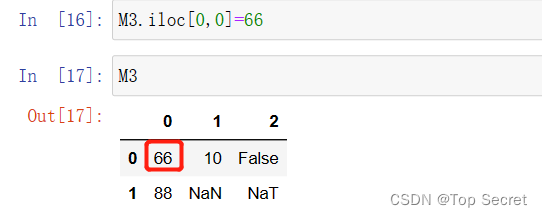
(2)通过fillna()方法替代:

(3)丢弃带缺失值的行或者列 :


(4) 用repalce()方法替换缺失值:
replace(to_replace=None,value=None)用value指定的新值,替换to_replace指定的原值。

2. 多源数据操作
2.1 合并函数:merge()
merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=(’_x’, ‘_y’), copy=True, indicator=False, validate=None)

2.2 连接函数:join()
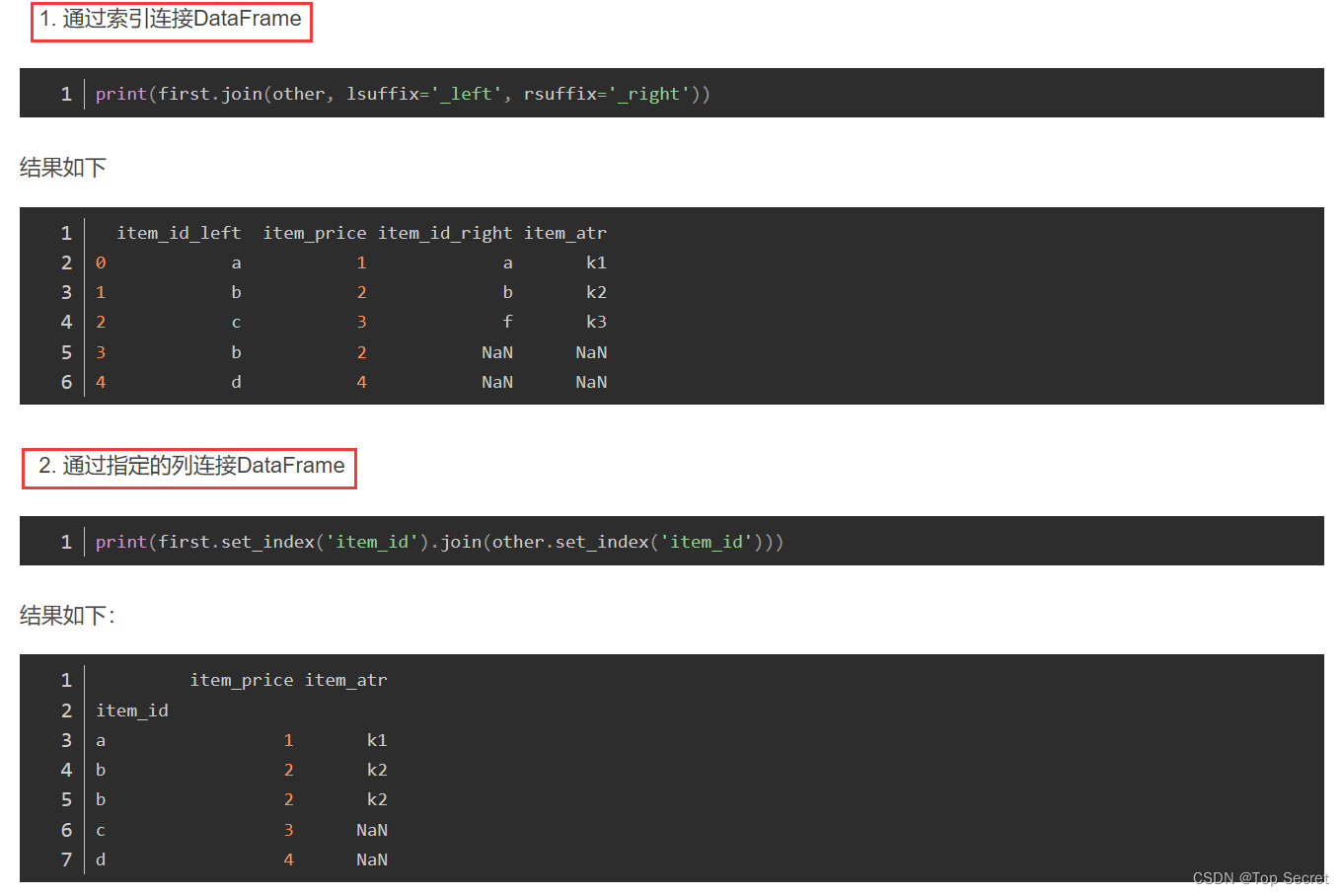
通过索引或者指定的列连接两个DataFrame:
DataFrame.join(other, on=None, how=’left’, lsuffix=”, rsuffix=”, sort=False)
参数说明
other:【DataFrame,或者带有名字的Series,或者DataFrame的list】如果传递的是Series,那么其name属性应当是一个集合,并且该集合将会作为结果DataFrame的列名
on:【列名称,或者列名称的list/tuple,或者类似形状的数组】连接的列,默认使用索引连接
how:【{‘left’, ‘right’, ‘outer’, ‘inner’}, default:‘left’】连接的方式,默认为左连接
lsuffix:【string】左DataFrame中重复列的后缀
rsuffix:【string】右DataFrame中重复列的后缀
sort:【boolean, default
False】按照字典顺序对结果在连接键上排序。如果为False,连接键的顺序取决于连接类型(关键字)。
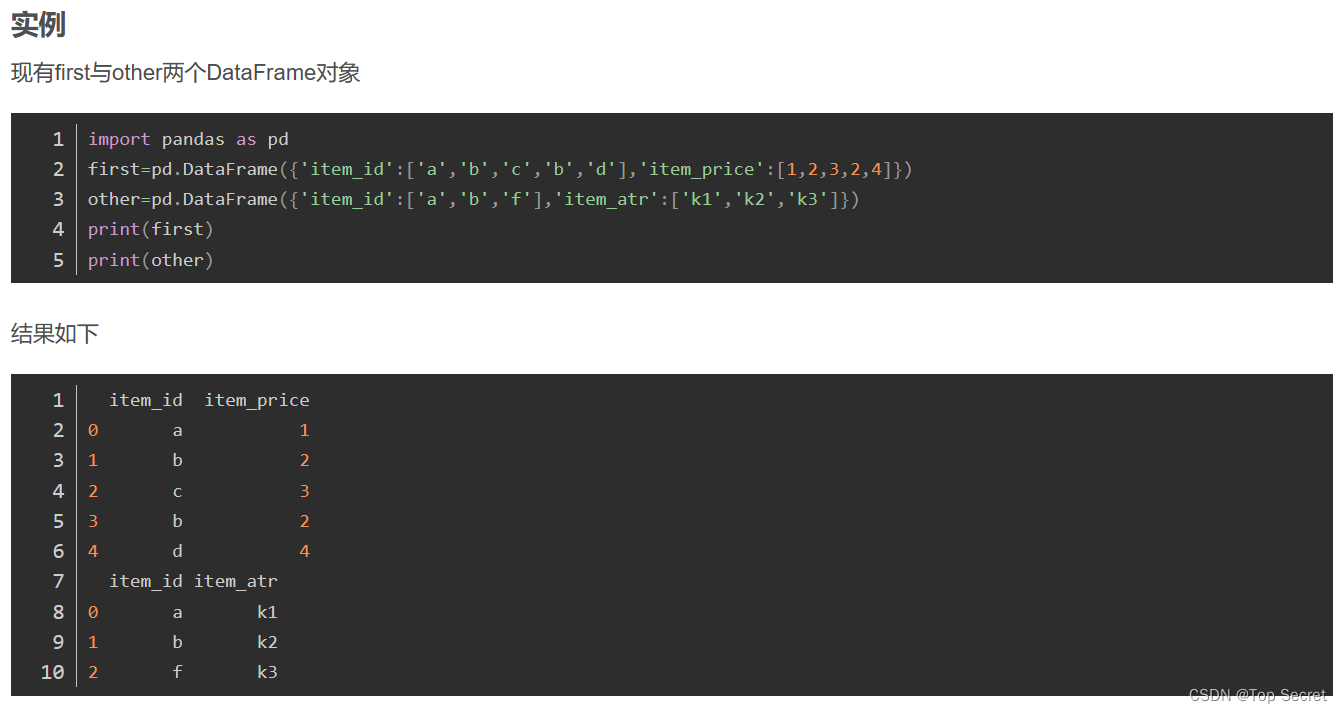
实例:
现有first与other两个DataFrame对象。
2.3 指定方向合并:concat()
通过指定axis方向,进行多数据源合并。
pd.concat()函数可以沿着指定的轴将多个dataframe或者series拼接到一起,这一点和另一个常用的pd.merge()函数不同,pd.merge()函数只能实现两个表的拼接。
pd.concat( objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True,)
参数含义
objs:Series,DataFrame或Panel对象的序列或映射。如果传递了dict,则排序的键将用作键参数,除非它被传递,在这种情况下,将选择值(见下文)。任何无对象将被静默删除,除非它们都是无,在这种情况下将引发一个ValueError。axis:指定合并方向,默认值为0,为竖向合并。1为横向合并。join:{'inner','outer'},默认为“outer”。如何处理其他轴上的索引。outer为联合和inner为交集。ignore_index:boolean,default False。如果为True,请不要使用并置轴上的索引值。结果轴将被标记为0,...,n-1。如果要连接其中并置轴没有有意义的索引信息的对象,这将非常有用。注意,其他轴上的索引值在连接中仍然受到尊重。join_axes:Index对象列表。用于其他n-1轴的特定索引,而不是执行内部/外部设置逻辑。keys:序列,默认值无。使用传递的键作为最外层构建层次索引。如果为多索引,应该使用元组。levels:序列列表,默认值无。用于构建MultiIndex的特定级别(唯一值)。否则,它们将从键推断。names:list,default无。结果层次索引中的级别的名称。verify_integrity:boolean,default False。检查新连接的轴是否包含重复项。这相对于实际的数据串联可能是非常昂贵的。copy:boolean,default True。如果为False,请勿不必要地复制数据。
(4条消息) pandas的连接函数concat()函数_concat pandas_zzpdbk的博客-CSDN博客
3. 数据分组和聚合运算
3.1 groupby()方法
(8条消息) groupby函数详解_.groupby_Vergil_Zsh的博客-CSDN博客
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, group_keys=True, squeeze=False, observed=False, **kwargs)
例子:
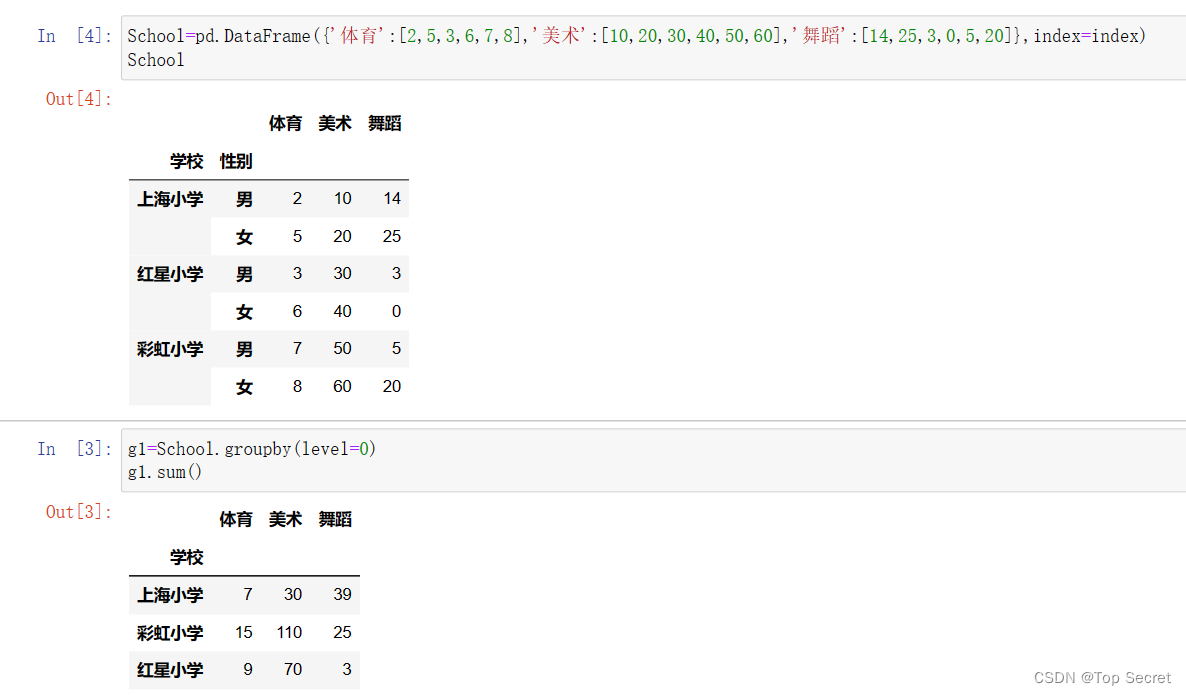
 对School信息按照学校行索引进行分组,然后统计体育、美术、舞蹈的人数。
对School信息按照学校行索引进行分组,然后统计体育、美术、舞蹈的人数。
如下按性别:
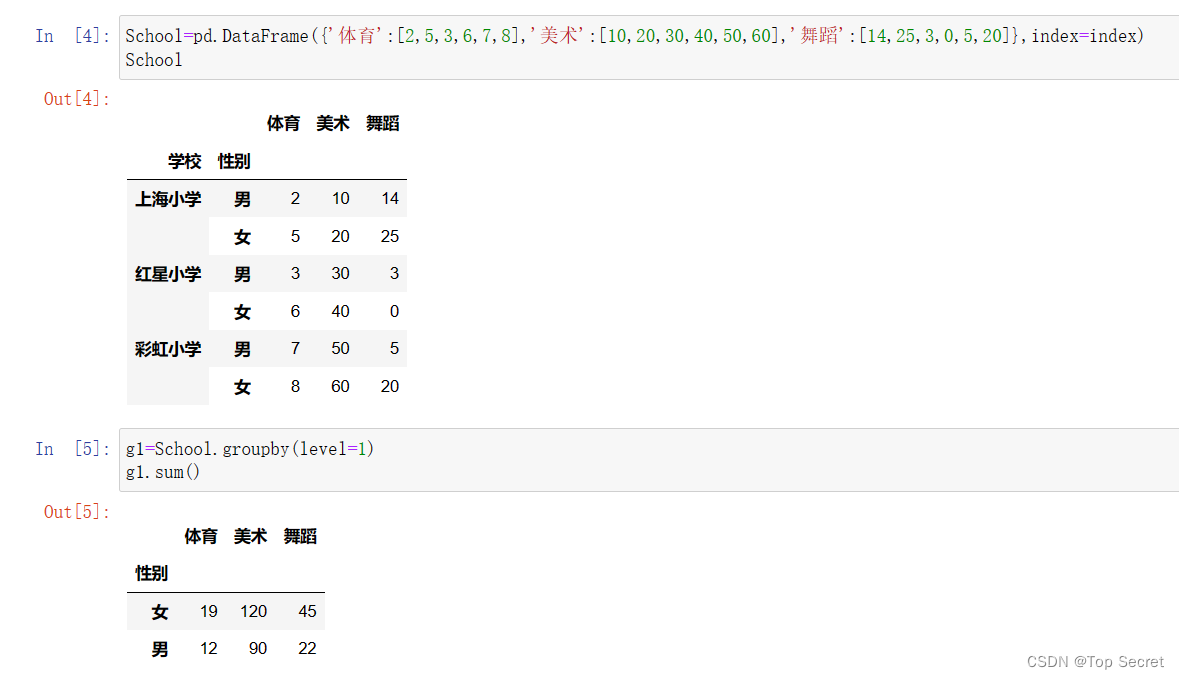 通过如上对比可见是通过level来确定统计标准。
通过如上对比可见是通过level来确定统计标准。

3.2 聚合:aggregate()方法
aggregate(func,axis=0,*arg,**kwargs)
func:指定用于集合运算的函数,具体类型包括自定义函数名,字符串函数名,列表函数名等。
3.2.1 一般聚合使用
(1)内置函数聚合运算
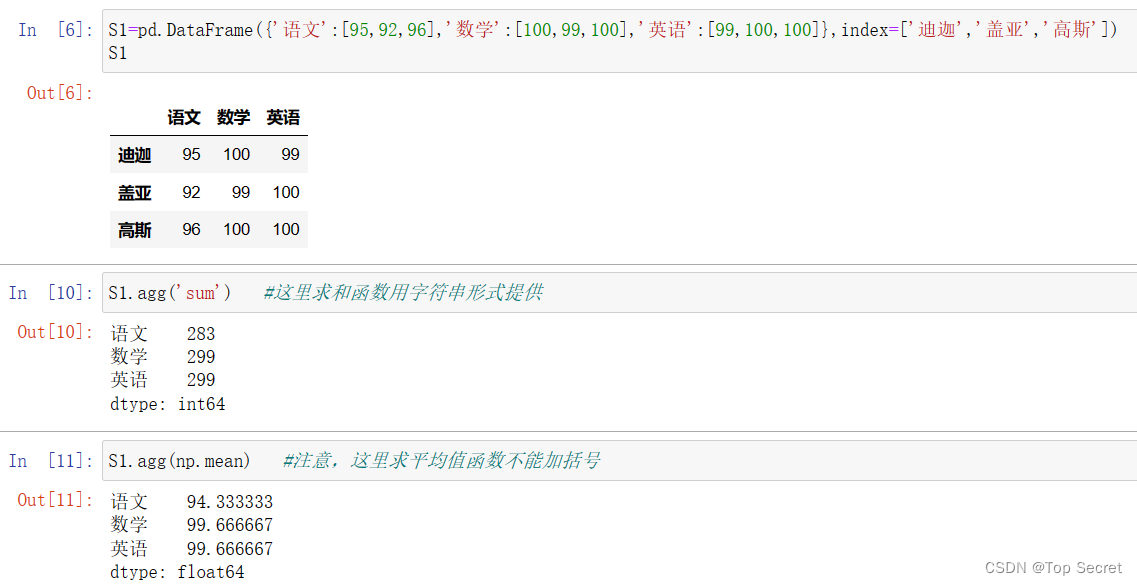
(2)自定义函数聚合运算

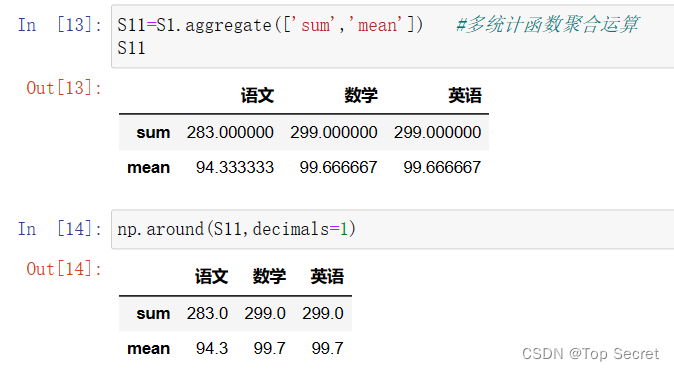
(3)多统计函数聚合运算
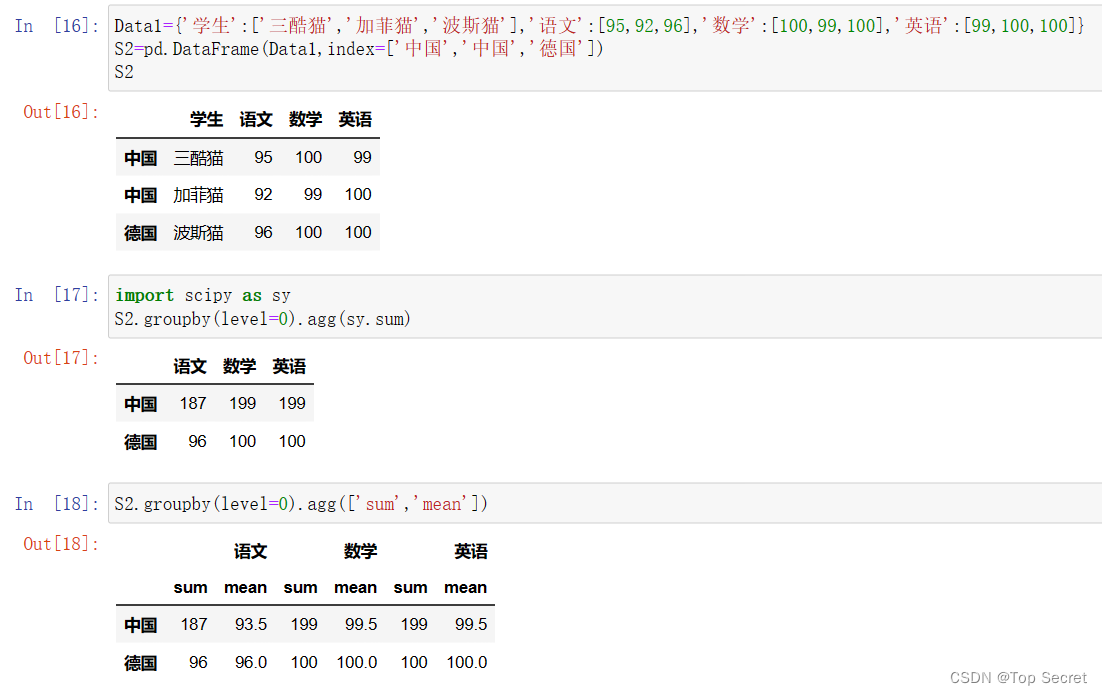
3.2.2 分组聚合
继电器开关)



)














