使用Levenshtein计算相似度距离,装下模块,调用下函数就好。
拿idf还得自己去算权重,而且不一定准确度高,一般做idf还得做词性归一化,把动词形容词什么全部转成名词,很麻烦。
Levenshtein.distance(str1,str2)
计算编辑距离(也称Levenshtein距离)。是描述由一个字串转化成另一个字串最少的操作次数,在其中的操作包括插入、删除、替换。如
例如将eeba转变成abac:
① eba(删除第一个e)
② aba(将剩下的e替换成a)
③ abac(在末尾插入c)
所以eeba和abac的编辑距离就是3
备注:

http://www.lfd.uci.edu/~gohlke/pythonlibs/#python-levenshtein
1. Levenshtein.hamming(str1, str2)
计算汉明距离。要求str1和str2必须长度一致。是描述两个等长字串之间对应位置上不同字符的个数。如

2. Levenshtein.distance(str1, str2)
计算编辑距离(也成Levenshtein距离)。是描述由一个字串转化成另一个字串最少的操作次数,在其中的操作包括插入、删除、替换。如

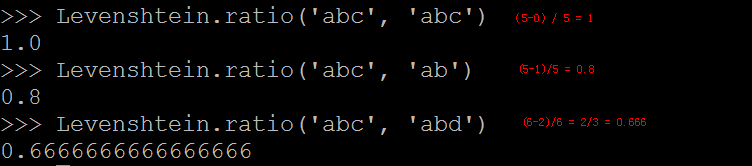
3. Levenshtein.ratio(str1, str2)
计算莱文斯坦比。计算公式 r = (sum - ldist) / sum, 其中sum是指str1 和 str2 字串的长度总和,ldist是类编辑距离
注意:这里的类编辑距离不是2中所说的编辑距离,2中三种操作中每个操作+1,而在此处,删除、插入依然+1,但是替换+2
这样设计的目的:ratio('a', 'c'),sum=2,按2中计算为(2-1)/2 = 0.5,’a','c'没有重合,显然不合算,但是替换操作+2,就可以解决这个问题。
4. Levenshtein.jaro(s1, s2)
计算jaro距离,
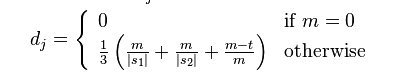
其中的m为s1, s2的匹配长度,当某位置的认为匹配 当该位置字符相同,或者在不超过
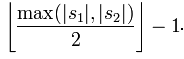
t是调换次数的一半
5. Levenshtein.jaro_winkler(s1, s2)
计算Jaro–Winkler距离
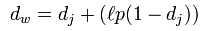


链路负载均衡器...)



)








 简介)

 如何传递多个不同类型的参数)

