一、分治算法:快速排序、归并排序、大整数乘法、二分查找、递归(汉诺塔)
- 基本概念:把一个复杂的问题分成若干个相同或相似的子问题,再把子问题分成更小的子问题… , 知道最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。
看上去有点类似Fork/Join框架,或map-reduce。
排序算法中的快速排序、归并排序都是使用的分治算法。
- 分治算法的适用场景:
1)当问题规模缩小到一定的程度就可以很容易解决
2)该问题可以分解为若干个规模较小的相同问题
3)该问题分解出的若干子问题的解可以合并为该问题的解
4)每个子问题都是独立的,相互之间没有交集。 - 使用分治法的经典场景:
1)二分搜索
2)大整数乘法
3)合并排序
4)快速排序
5)汉诺塔 - 分治算法经典例题:
输入一组整数,求出这组数字子序列和中最大值。也就是求出最大子序列的和,不必求出最大的那个序列。例如:序列:-2, 11, -1, 13, -5, -2 , 则最大子序列的和为20。
public static void main(String[] args) {int[] a = { -2, 11, -4, 13, -5, -2 };// 最大子序列和为20int[] b = { -6, 2, 4, -7, 5, 3, 2, -1, 6, -9, 10, -2 };// 最大子序列和为16System.out.println(maxSubSum1(a));System.out.println(maxSubSum4(b));
}// 最大子序列求和算法一
public static int maxSubSum1(int[] a) {int maxSum = 0;// 从第i个开始找最大子序列和for (int i = 0; i < a.length; i++) {// 找第i到j的最大子序列和for (int j = i; j < a.length; j++) {int thisSum = 0;// 计算从第i个开始,到第j个的和thisSumfor (int k = i; k <= j; k++) {thisSum += a[k];}// 如果第i到第j个的和小于thisSum,则将thisSum赋值给maxSumif (thisSum > maxSum) {maxSum = thisSum;}}}return maxSum;
}// 时间复杂度O(n的平方)
public static int maxSubSum2(int[] a) {int maxSum = 0;for (int i = 0; i < a.length; i++) {// 将sumMax放在for循环外面,避免j的变化引起i到j的和sumMax要用for循环重新计算int sumMax = 0;for (int j = i; j < a.length; j++) {sumMax += a[j];if (sumMax > maxSum) {maxSum = sumMax;}}}return maxSum;
}// 递归,分治策略
// 2分logn,for循环n,时间复杂度O(nlogn)
public static int maxSubSum3(int[] a) {return maxSumRec(a, 0, a.length - 1);
}public static int maxSumRec(int[] a, int left, int right) {// 递归中的基本情况if (left == right) {if (a[left] > 0)return a[left];elsereturn 0;}int center = (left + right) / 2;// 最大子序列在左侧int maxLeftSum = maxSumRec(a, left, center);// 最大子序列在右侧int maxRightSum = maxSumRec(a, center + 1, right);// 最大子序列在中间(左边靠近中间的最大子序列+右边靠近中间的最大子序列)int maxLeftBorderSum = 0, leftBorderSum = 0;for (int i = center; i >= left; i--) {leftBorderSum += a[i];if (leftBorderSum > maxLeftBorderSum)maxLeftBorderSum = leftBorderSum;}int maxRightBorderSum = 0, rightBorderSum = 0;for (int i = center + 1; i <= right; i++) {rightBorderSum += a[i];if (rightBorderSum > maxRightBorderSum)maxRightBorderSum = rightBorderSum;}// 返回最大子序列在左侧,在右侧,在中间求出的值中的最大的return max3(maxLeftSum, maxRightSum, maxLeftBorderSum + maxRightBorderSum);
}public static int max3(int a, int b, int c) {return a > b ? (a > c ? a : c) : (b > c ? b : c);
}// 时间复杂度:O(n); 任何a[i]为负时,均不可能作为最大子序列前缀;任何负的子序列不可能是最有子序列的前缀
public static int maxSubSum4(int[] a) {int maxSum = 0, thisSum = 0;for (int j = 0; j < a.length; j++) {thisSum += a[j];if (thisSum > maxSum)maxSum = thisSum;else if (thisSum < 0)thisSum = 0;}return maxSum;
}
二、动态规划算法
- 基本概念:将待求解的问题分解为若干个子问题,按顺序求解子问题,前一问题的解,为后一问题的求解提供有用的信息。在求解任一子问题时,列出各种可能的局部解,通过决策保留那些有可能达到最优的局部解,丢弃其他局部解。依次解决各种子问题,最后一个子问题就是初始问题的解。
由于动态规划算法解决的问题是有重叠的子问题,为了减少重复计算,对每一个子问题只解一次,将其不同阶段的不同状态保存在一个二维数组中。
动态规划算法以分治算法类似,不同在于:适合于动态规划算法求解的问题,经分解后得到的子问题,往往不是互相独立的,而是下一个子阶段的求解是建立在上一个子阶段的解的基础上,进行进一步求解的。
- 动态规划的适用场景
1)最优化原理:该问题的最优解所包含的子问题的解也是最优的。
2)无后效性:某阶段状态一旦确定,就不受这个状态以后决策的影响。即某状态以后的过程不会影响以前的状态,只与当前状态有关。
3)有重叠子问题:即子问题之间不相互独立,一个子问题的解在下一阶段决策中可能被多次使用到。 - 经典问题:
给定两个字符串str1和str2,返回两个字符串的最长公共子序列,例如:str1=“1A2C3D4B56",str2=“B1D23CA45B6A”,"123456"和"12C4B6"都是最长公共子序列,返回哪一个都行。
分析:这事经典的动态规划问题,假设str1的长度为M, str2的长度为N, 则生成M*N的二维数组dp, dp[i][j]的含义是str1[0…i]与str2[0…j]的最长公共子序列的长度。
dp值的求法如下:
dp[i][j]的值比如和dp[i-1][j], dp[i][j-1]相关,结合下面的代码来看,实际上从第一行和第一列开始计算的,
public static void main(String[] args) {String A = "1A2C3D4B56";String B = "B1D23CA45B6A";System.out.println(findLCS(A, A.length(), B, B.length()));
}public static int findLCS(String A, int Alen, String B, int Blen) {int dp[][] = new int[Alen+1][Blen+1];for (int i = 0; i < Alen; i++) {for (int j = 0; j < Blen; j++) {if (A.charAt(i) == B.charAt(j)) {dp[i + 1][j + 1] = dp[i][j] + 1;} else {dp[i + 1][j + 1] = Math.max(dp[i + 1][j], dp[i][j + 1]);}}}return dp[Alen][Blen];
}
三、贪心算法
贪心算法是通过局部最优解来达到全局最优解。
-
下面是一个可以试用贪心算法解的题目,贪心解的确不错,可惜不是最优解。
[背包问题]有一个背包,背包容量是M=150。有7个物品,物品可以分割成任意大小。
要求尽可能让装入背包中的物品总价值最大,但不能超过总容量。
物品 A B C D E F G
重量 35 30 60 50 40 10 25
价值 10 40 30 50 35 40 30
分析:
目标函数: ∑pi最大
约束条件是装入的物品总重量不超过背包容量,即∑wi<=M( M=150)
1)根据贪心的策略,每次挑选价值最大的物品装入背包,得到的结果是否最优呢?
2)每次挑选重量最小的物品装入背包,是否能得到最优解?
3)每次选取单位重量价值最大的物品,成为解本地的策略?
贪心算法简单易行,但贪心算法需要证明后才能真正运用到算法中。一般来说,贪心算法的证明围绕着整个问题的最优解一定由在贪心策略中存在的子问题的最优解得来的。
对于本题的三种贪心策略,都无法成立,即无法被证明。解释如下:
1)选取价值最大者。
反例:W=30
物品:A B C
重量:28 12 12
价值:30 20 20
根据策略,选A, 但选BC最合适
2)选取重量最小,反例与上述类似
3)选取单位重量价值最大的物品。反例:
W=30
物品:A B C
重量:28 20 10
价值:28 20 10
根据策略,三种物品单位重量价值一样,程序无法依据现有策略作出判断,如果选择A,则答案错误。
2)贪心算法的经典案例:
设有n个正整数,将他们连成一排,组成一个最大的多位整数。
例如:n=3时,3个整数13,312,343,连成的最大整数为34331213。
又如:n=4时,4个整数7,13,4,246,连成的最大整数为7424613。
要求输入:n, N个数
输出:连成的多位数
算法分析:该题很容易想到贪心法,但解题时很多人把整数按从大到小的顺序连接起来,测试题目的例子也都符合,但结果不对。例如:我们很容易找到12, 121应该组成12121而非12112, 但如12, 123呢,就是12312,而不是12123。所以,通过整数排序的方法是不对的。
结论:该题可以用贪心算法,只是刚才采用的贪心策略不对。正确的贪心算法的标准是:先把整数转成字符串,然后再比较a+b和b+a, 如果a+b >= b+a, 就把a排在b前面, 反之把a排在b后面。
四、回溯算法
1.基本概念:回溯算法是一个类似枚举的搜索尝试过程,主要在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径。深度优先。
回溯算法是一种选优搜索法,按选优条件向前搜索,以达到目标。当搜索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术成为回溯法,而满足回溯条件的某个状态的点成为“回溯点”。
对于回溯算法的简单描述是:把问题的解空间转化为图或树的结构,然后使用深度优先进行遍历,遍历过程中寻找所有可行解,从而找到最优解。
其基本思想类似于:图的深度优先搜索;二叉树的后序遍历。
回溯法的详细描述为:回溯法按深度优先搜索解空间树。首先从根节点出发,当搜索到解空间数的某一节点时,先利用剪枝函数判断该节点是否可行(即能得到问题的解)。如果不可行,则跳过对该节点为根的子树的搜索,逐层向其祖先节点回溯;否则,进入该子树,继续按深度优先策略搜索。
2. 回溯算法的实现:递归和迭代
1.回溯算法的经典问题:0-1背包问题
有n种物品和一个背包,第i种物品的重量是wi,其价值为pi,背包的容量为c. 问:怎样把物品装入背包,背包中的物品的总价值最大。
分析:从n种物品中选择部分物品,这样的题目解空间是子集树。例如,当物品的种类数为3是,其解空间如下图:
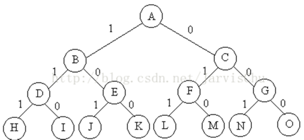
边1表示选择该物品,边0表示不选择该物品。这样,这个树从根节点到叶子节点,包含了把物品放入背包的所有可能性。
回溯搜索过程,如果来到了叶子节点,表示一条搜索路径结束,如果该路径上存在更优的解,则保存下来,如果不是叶子节点,是中间的节点(如B), 就遍历其子节点(D和E), 如果子节点满足剪枝条件,就继续回溯搜索子节点。
五、分支限界算法
- 基本概念
类似于回溯法,也是一种在问题的解空间树T上搜索问题解的算法。但在一般情况下,分支限界法与回溯法的求解目标不同。回溯法的求解目标是找出解空间树中满足约束条件的所有解,而分支限界法的求解目标则是满足约束条件的一个解,或是从满足约束条件的解中找出使某一目标函数值达到极大或极小的解,即在某种意义下的最优解。
分支限界法的基本思想是对有约束条件的最优化问题的所有可行解(数目有限)空间进行搜索。该算法在具体执行时,把全部可行的解空间不断分割为越来越小的自己(成为分支),并为每个自己内的解的值计算一个下界或上界(成为界定)。
在每次分支后,对凡是界限超出已知可行解值的那些子集不再做进一步分支。这样,解的许多子集(即搜索树上的许多节点)就可以不必考虑了,从而缩小了搜索范围。这一过程一直进行到找出可行解为止,该可行解的值不大于任务子集的界限,因此这种算法一般可以求得最优解。
将问题分支为子问题,并对这些子问题定界的步骤称为分支定界法。
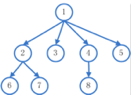
知识附录:深度优先搜索和广度优先搜索
1)广度优先搜索:使用队列的先进先出
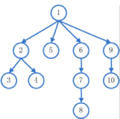
2)深度优先搜索:
2. 分支限界法的经典问题:旅行售货员问题
1)问题描述:某售货员要到若干城市去卖商品,已知各城市之间的路程。他要选定一条从驻地出发,经过每个城市一次,最后回到驻地的路线,使总的路程最小。
下图为1,2,3,4 四个城市及路线图,任意两个城市之间不一定都有路可达。
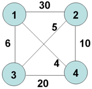
2)问题理解:
分支限界法利用:广度优先搜索和最优值策略
利用二位数组保存图信息,一旦一个城市没有通向另外城市的路,则不可能有回路,不用再找下去了。
我们任意选择一个城市,作为出发点(因为最后都是一个回路,从哪出发都一样)
3)关键思路:
想象一下,我们就是旅行员,从城市1出发,根据广度优先搜索的思路,我们要把从城市1能到达的下一个城市,都要作为一种路径走一下试试。可在程序里面怎样实现这种“试试”呢?
答案是:可以利用一种数据结构,保存我们每走一步后,当前的一些状态参数。比如,我们已经走过的城市数目(这样就知道,我们有没有走完,比如上图,当我们走了四个城市之后,无论从第四个城市是否能回到起点城市,都意味着我们走完了,只是这条路径合不合约束以及能不能得到最优解的问题)。我们把这种保存状态参数的数据结构定义成Node。需要另一个数据结构用来保存我们每次试出来的路径,这就是MiniHeap
Node{int s; //结点深度,即当前走过了几个城市int x[MAX_SIZE]; //保存走到这个结点时的路径信息
}
MiniHeap{//保存所有结点并提供一些结点的操作
}

















![matlab怎么画二维热力图_[原创]Day3.箱线图和热力图的绘制](http://pic.xiahunao.cn/matlab怎么画二维热力图_[原创]Day3.箱线图和热力图的绘制)

