一、什么是 ES Nested 嵌套
Elasticsearch 有很多数据类型,大致如下:
- 基本数据类型:
- string 类型。ES 7.x 中,string 类型会升级为:text 和 keyword。keyword 可以排序;text 默认分词,不可以排序。
- 数据类型:integer、long 等
- 时间类型、布尔类型、二进制类型、区间类型等
- 复杂数据类型:
- 数组类型:Array
- 对象类型:Object
- Nested 类型
- 特定数据类型:地理位置、IP 等
注意:tring/nested/array 类型字段不能用作排序字段。因此 string 类型会升级为:text 和 keyword。keyword 可以排序,text 默认分词,不可以排序。

更多Java微服务资料,加我微w信x:bysocket01 (加的人,一般很帅)
2.1 那什么是 Nested 类型?
Elasticsearch 7.x 文档中,这样写到:
The nested type is a specialised version of the object datatype that allows arrays of objects to be indexed in a way that they can be queried independently of each other.
Nested (嵌套)类型,是特殊的对象类型,特殊的地方是索引对象数组方式不同,允许数组中的对象各自地进行索引。目的是对象之间彼此独立被查询出来。
2.2 如何使用 Nested 类型?
在 ES 的 my_index 索引中存储 users 字段。比如说
{"group" : "fans","users" : [{"name" : "John","age" : "23"},{"name" : "Alice","age" : "18"}]
}其实存储看上去跟 Object 类型一样,只不过底层原理对数组 users 字段索引方式不同。设置 users 字段的索引方式 Nested 嵌套类型:
curl -X PUT "localhost:9200/my_index" -H 'Content-Type: application/json' -d'
{"mappings": {"properties": {"users": {"type": "nested" }}}
}
'
二、Nested Query 应用场景或案例
比如小老弟我有一波小粉丝,users 字段类型是 object。存储如下:
{"group" : "bysocket_fans","users" : [{"name" : "John","age" : "23"},{"name" : "Alice","age" : "18"}]
}{"group" : "路人甲_fans","users" : [{"name" : "Alice","age" : "22"},{"name" : "Jeff","age" : "18"}]
}比如 18 岁大姑娘 Alice 是小老弟我的粉丝,她也可能是周杰伦的粉丝。那这边就有一个需求,即应用场景:
如何找到 18 岁大姑娘 Alice {"name" : "Alice","age" : "18"} 关注的所有明星呢?如果用老的查询语句是这样搜索的:
GET /my_index/_search?pretty
{"query": {"bool": {"must": [{"match": {"users.name": "Alice"}},{"match": {"users.age": 18}}]}}
}结果发现结果是不对的,路人甲 这条记录也出现了。因为匹配到了第一个 Alice + 第二个 Jeff 的 18。所以这种查询不满足这个场景
那么需要使用 Nested 类型并用 Nested 查询,即让数组中的对象各自地进行索引。目的是对象之间彼此独立被查询出来。
三、Nested Query 实战
3.1 设置 Nested 类型
根据 2.2 如何使用 Nested 类型,将 users 字段类型从 object 修改为 nested:
curl -X PUT "localhost:9200/my_index" -H 'Content-Type: application/json' -d'
{"mappings": {"properties": {"users": {"type": "nested" }}}
}
'3.2 Nested Query
修改后,对应的 Nested Query ,如下:
GET /my_index/_search?pretty
{"query": {"bool": {"must": [{"nested": {"path": "users","query": {"bool": {"must": [{"match": {"users.name": "Alice"}},{"match": {"users.age": 18}}]}}}}]}}
}
语法很简单就是:
- key 以 "nested" 开头
- path 就是嵌套对象数组的字段名
- 其他
- score_mode (可选的)匹配子对象的分数相关性分数。avg (默认,使用所有匹配子对象的平均相关性分数)
- ignore_unmapped (可选的)是否忽略 path 未映射,不返回任何文档而不是错误。默认为 false,如果 path 不对就报错
这样查询得结果就是对的。
四、Nested Query 性能
这边测试过,给大家一个测试报告和建议。
压测环境:3 个 server ,6 个 ES 节点
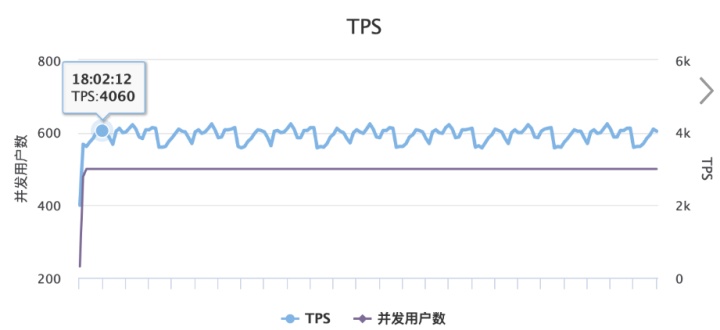
压测结论: 使用上小节查询语句,50 并发情况下,导致千兆网卡被打满了。TPS 4000 左右,如果提高并发,就会增加 RT。所以如果高性能大流量情况下,必须用 Nested 应该从网络流量方向进行优化。二者,尽量减少大数据对象的返回
建议:泥瓦匠建议,你听听看
- 性能:Common Query 远远大于 Nested Query 远远大于 Parent/Child Query
- 性能优化:首先考虑减少后面两种 Query
- 性能优化:Nested Query 业务可以优化下。比如上一小节完全可以多存一个 fanIds 数组。搜索两次,第一次查确定 18 岁大姑娘 Alice 的 fanId,第二次根据 fanId 搜索即可
- 性能优化:实在没办法,高性能大流量情况下,必须用 Nested 应该从网络流量方向进行优化。二者,尽量减少大数据对象的返回
(完)
参考资料:
- https://blog.csdn.net/laoyang360/article/details/82950393
- https://www.elastic.co/guide/en/elasticsearch/reference/7.2/search-aggregations-bucket-reverse-nested-aggregation.html
- 更多Java微服务资料,加我微w信x:bysocket01 (加的人,一般很帅)







的设计灵感和数学表达式)




)






