presto集群安装 整合hive
张映 发表于 2019-11-07
分类目录: hadoop/spark/scala
标签:hive, presto
Presto是一个运行在多台服务器上的分布式系统。 完整安装包括一个coordinator(调度节点)和多个worker。 由客户端提交查询,从Presto命令行CLI提交到coordinator。 coordinator进行解析,分析并执行查询计划,然后分发处理队列到worker中。
Presto通过使用分布式查询,可以快速高效的完成海量数据的查询。作为Hive和Pig的替代者,Presto不仅能访问HDFS,也能访问不同的数据源,包括:RDBMS和其他数据源(如Cassandra)。虽然Presto可以解析SQL,但它不是一个标准的数据库。不是MySQL、PostgreSQL或者Oracle的代替品,也不能用来处理在线事务(OLTP)
一,presto与hive对比
优点
1.Presto与hive对比,都能够处理PB级别的海量数据分析,但Presto是基于内存运算,减少没必要的硬盘IO,所以更快。
2.能够连接多个数据源,跨数据源连表查,如从hive查询大量网站访问记录,然后从mysql中匹配出设备信息。
3.部署也比hive简单,因为hive是基于HDFS的,需要先部署HDFS。
缺点
1.虽然能够处理PB级别的海量数据分析,但不是代表Presto把PB级别都放在内存中计算的。而是根据场景,如count,avg等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高。但是连表查,就可能产生大量的临时数据,因此速度会变慢,反而hive此时会更擅长。
2.为了达到实时查询,可能会想到用它直连MySql来操作查询,这效率并不会提升,瓶颈依然在MySql,此时还引入网络瓶颈,所以会比原本直接操作数据库要慢。
二,集群服务器说明
bigserver1(10.0.40.237):调度节点(coordinator)
bigserver2(10.0.40.222):worker节点
bigserver3(10.0.40.193):worker节点
Coordinator服务器是用来解析语句,执行计划分析和管理Presto的worker结点。Presto安装必须有一个Coordinator和多个worker。如果用于开发环境和测试,则一个Presto实例可以同时担任这两个角色。
Coordinator跟踪每个work的活动情况并协调查询语句的执行。 Coordinator为每个查询建立模型,模型包含多个stage,每个stage再转为task分发到不同的worker上执行。
Worker是负责执行任务和处理数据。Worker从connector获取数据。Worker之间会交换中间数据。Coordinator是负责从Worker获取结果并返回最终结果给client。
当Worker启动时,会广播自己去发现 Coordinator,并告知 Coordinator它是可用,随时可以接受task。
Coordinator与Worker通信是通过REST API。
三,下载presto
查看复制打印?
- # wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.227/presto-server-0.227.tar.gz
- # tar zxvf presto-server-0.227.tar.gz
- # mv presto-server-0.227 /bigdata
四,调度节点presto配置
1,配置目录介绍
查看复制打印?
- [root@bigserver1 presto-server-0.227]# mkdir etc //创建配置目录
- [root@bigserver1 etc]# tree
- .
- ├── catalog
- │ ├── hive.properties //连接hive
- │ └── jmx.properties //连接jmx
- ├── config.properties //Presto server的配置信息
- ├── jvm.config //JVM的命令行选项
- ├── log.properties //日志配置信息
- └── node.properties //每个节点的环境配置信息
2,调度节点node.properties
查看复制打印?
- [root@bigserver1 etc]# mkdir /bigdata/presto-server-0.227/data
- [root@bigserver1 etc]# cat node.properties
- node.environment=production
- node.id=coordinator1
- node.data-dir=/bigdata/presto-server-0.227/data
node.environment: 环境名字,Presto集群中的结点的环境名字都必须是一样的。
node.id: 唯一标识,每个结点的标识都必须是为一的。就算重启或升级Presto都必须还保持原来的标识。
node.data-dir: 数据目录,Presto用它来保存log和其他数据。
3,调度节点jvm.config
- [root@bigserver1 etc]# cat jvm.config
- -server
- -Xmx16G
- -XX:+UseG1GC
- -XX:G1HeapRegionSize=32M
- -XX:+UseGCOverheadLimit
- -XX:+ExplicitGCInvokesConcurrent
- -XX:+HeapDumpOnOutOfMemoryError
- -XX:+ExitOnOutOfMemoryError
- -XX:OnOutOfMemoryError=kill -9 %p
- -XX:ReservedCodeCacheSize=150M
这份配置文件的格式是:一系列的选项,每行配置一个单独的选项。由于这些选项不在shell命令中使用。 因此即使将每个选项通过空格或者其他的分隔符分开,java程序也不会将这些选项分开,而是作为一个命令行选项处理
4,调度节点config.properties
查看复制打印?
- [root@bigserver1 etc]# cat config.properties
- coordinator=true
- node-scheduler.include-coordinator=false
- http-server.http.port=38080
- query.max-memory=3GB
- query.max-memory-per-node=1GB
- query.max-total-memory-per-node=2GB
- discovery-server.enabled=true
- discovery.uri=http://bigserver1:38080
coordinator: 是否运行该实例为coordinator(接受client的查询和管理查询执行)。
node-scheduler.include-coordinator:coordinator是否也作为work。对于大型集群来说,在coordinator里做worker的工作会影响查询性能。
http-server.http.port:指定HTTP端口。Presto使用HTTP来与外部和内部进行交流。
query.max-memory: 查询能用到的最大总内存
query.max-memory-per-node: 查询能用到的最大单结点内存
query.max-total-memory-per-node:查询执行过程中,用户和系统所使用的最大内存,系统使用的内存包括,读,写,网络缓存
discovery-server.enabled: Presto使用Discovery服务去找到集群中的所有结点。每个Presto实例在启动时都会在Discovery服务里注册。这样可以简化部署,不需要额外的服务,Presto的coordinator内置一个Discovery服务。也是使用HTTP端口。
discovery.uri: Discovery服务的URI。将example.net:8080替换为coordinator的host和端口。这个URI不能以斜杠结尾,这个错误需特别注意,不然会报404错误。
query.max-memory-per-node必须小于query.max-total-memory-per-node,query.max-total-memory-per-node 与memory.heap-headroom-per-node 之和必须小于 jvm max memory .也就是jvm.config 中配置的-Xmx
5,调度节点log.properties
- [root@bigserver1 etc]# cat log.properties
- com.facebook.presto=INFO
日志等级有四个,DEBUG,INFO,WARN,ERROR
6,调度节点jmx.properties
- [root@bigserver1 etc]# cat catalog/jmx.properties
- connector.name=jmx
7,调度节点hive.properties
查看复制打印?
- [root@bigserver1 etc]# cat catalog/hive.properties
- connector.name=hive-hadoop2
- hive.metastore.uri=thrift://bigserver1:9083
- hive.config.resources=/bigdata/hadoop/etc/hadoop/core-site.xml,/bigdata/hadoop/etc/hadoop/hdfs-site.xml
- hive.allow-drop-table=true
6和7的connector.name不是乱写的,不然就会报java.lang.IllegalArgumentException: No factory for connector
8,将调度节点presto复制到worker节点
- # scp -r presto-server-0.227 root@bigserver2:/bigdata
- # scp -r presto-server-0.227 root@bigserver3:/bigdata
五,worker节点presto配置
大部分的配置根调度节点一样,下面只例举出不同的部分。
1,worker节点config.properties
查看复制打印?
- [root@bigserver2 etc]# cat config.properties
- coordinator=false
- http-server.http.port=38080
- query.max-memory=3GB
- query.max-memory-per-node=1GB
- discovery.uri=http://bigserver1:38080
2,worker节点node.properties
- [root@bigserver2 etc]# cat node.properties
- node.environment=production
- node.id=worker1
- node.data-dir=/bigdata/presto-server-0.227/data
每个presto节点的node.id都是不一样的,这一点要注意
六,设置环境变量,并启动
1,设置环境变量
查看复制打印?
- # echo "export PRESTO_HOME=/bigdata/presto-server-0.227" >> ~/.bashrc
- # echo "export PATH=$PRESTO_HOME/bin:$PATH" >> ~/.bashrc
- # source ~/.bashrc
2,每个presto节点都要启动
查看复制打印?
- # launcher start //启动
- # laucher status //查看状态
- # laucher stop //停止
- # jps
- 6065 DFSZKFailoverController
- 5268 QuorumPeerMain
- 17300 HMaster
- 26484 PrestoServer //每个presto节点都有
- 4869 JournalNode
- 5302 Kafka
- 5126 Jps
- 4652 NameNode
- 5150 ResourceManager
启动后,web监控就要以看到了
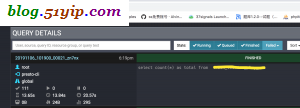
七,Presto命令行工具
查看复制打印?
- # cd $PRESTO_HOME/bin
- # wget -O presto https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.227/presto-cli-0.227-executable.jar
- # nohup hive --service metastore 2>&1 >> /var/log.log & //想要查询连接到hive中查询数据还需要先启动hive的metastore
- [root@bigserver1 etc]# presto --server bigserver1:38080 --catalog hive --schema default --debug
- presto:default> show tables;
- Table
- -------
- (0 rows)
- Query 20191107_073229_00007_zn7nx, FINISHED, 3 nodes
- http://bigserver1:38080/ui/query.html?20191107_073229_00007_zn7nx
- Splits: 36 total, 19 done (52.78%)
- CPU Time: 0.0s total, 0 rows/s, 0B/s, 15% active
- Per Node: 0.0 parallelism, 0 rows/s, 0B/s
- Parallelism: 0.0
- Peak Memory: 0B
- 0:01 [0 rows, 0B] [0 rows/s, 0B/s]
- presto:default> use tanktest;
- USE
--server连接presto调度节点
--catalog连接的数据源
--schema可以理解成数据库
八,presto与hive简单对比
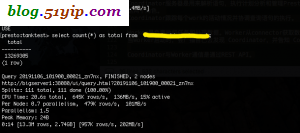
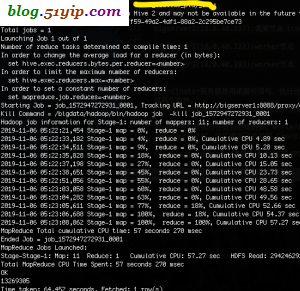
从测试的结果来看,presto比hive要快4-5倍,个人觉得内存够的话,能达到8-10倍,上面的presto集群,是在测试环境,机器是退休的办公用公式机













简单应用)





