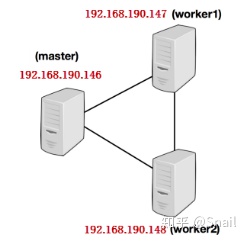
Flink支持完全分布式模式,这时它由一个master节点和多个worker节点构成。在本节,我们将搭建一个如下的三个节点的Flink集群。
一、Flink集群安装、配置和运行
Flink完全分布式集群搭建步骤如下:
1、配置从master到worker节点的SSH无密登录,并保持保节点上相同的目录结构。
2、Flink要求在主节点和所有工作节点上设置JAVA_HOME环境变量,并指向Java安装的目录。
使用如下命令检查Java的安装和版本信息:
$ java -version3、下载Flink安装包。下载地址:https://flink.apache.org/downloads.html。可以选择任何喜欢的Hadoop/Scala组合。

4、将下载的最新版本的Flink压缩包拷贝到master节点的"~/software/"目录下,并解压缩到"~/bigdata/"目录下,步骤如下:
$ cd ~/bigdata/$ tar xzf ~/software/flink-1.10.0-bin-scala_2.11.tgz$ cd flink-1.10.05、在master节点上配置Flink
所有的配置都在"conf/flink-conf.yaml"文件中。在实际应用中,以下几个配置项是非常重要的:
- jobmanager.heap.mb:每个JobManager的可用内存量,以MB为单位。
- taskmanager.heap.mb:每个TaskManager的可用内存量,以MB为单位。
- taskmanager.numberOfTaskSlots:每台机器上可用的cpu数量,默认为1。
- parallelism.default:集群中cpu的总数。
- io.tmp.dirs:临时目录。
首先用编辑器nano打开该配置文件(你也可以用任何你喜欢的编辑器,如vim,都可以)。
$ nano conf/flink-conf.yaml编辑如下内容(注意,冒号后面一定要有一个空格):
jobmanager.rpc.address: master // 指向master节点jobmanager.rpc.port: 6123jobmanager.heap.size: 1024m // 定义允许JVM在每个节点上分配的最大主内存量taskmanager.memory.process.size: 1024mtaskmanager.numberOfTaskSlots: 2parallelism.default: 16、每个节点下的Flink必须保持相同的目录内容。因此将配置好的Flink拷贝到集群中的另外两个节点work01和work02,使用如下的命令:
$ scp -r ~/bigdata/flink-1.10.0 hduser@worker01:~/bigdata/$ scp -r ~/bigdata/flink-1.10.0 hduser@worker02:~/bigdata/7、最后,必须提供集群中所有用作worker节点的列表。在"conf/slaves"文件中添加每个slave节点信息(IP或hostname均可),每个节点一行,如下所示。每个工作节点稍后将运行一个TaskManager:
masterworker01worker028、启动集群:
$ ./bin/start-cluster.sh这个脚本会在本地节点启动一个JobManager并通过SSH连接到所有的worker节点(在slaves文件中列出的) 以启动每个节点上的TaskManager。注意观察启动过程中的输出信息,如下:
Starting cluster.
Starting standalonesession daemon on host master.
Starting taskexecutor daemon on host master.
Starting taskexecutor daemon on host worker01.
Starting taskexecutor daemon on host worker02.可以看出,Flink先在master上启动standalonesession进程,然后依次在master、worker01和worker02上启动taskexecutor进程。
启动以后,分别在master、worker01和worker02节点上执行jps命令,查看各节点上的进程是否正常启动了。
二、执行Flink自带的流处理程序-单词计数
1、首先,启动netcat服务器,运行在9000端口:
$ nc -l 90002、在另一个终端,启动Flink示例程序,监听netcat服务器。它将从套接字中读取文本,并每5秒打印前5秒内每个不同单词出现的次数,即处理时间的滚动窗口。
$ ./bin/flink run examples/streaming/SocketWindowWordCount.jar --hostname master --port 90003、回到第一个终端窗口,在正在运行的netcat终端窗口,随意输入一些内容,单词之间用空格分隔,Flink将会处理它。
good good studyday day up4、分别使用ssh登录master、worker01和worker02节点,并执行以下命令,查看日志中的输出:
$ cd ~/bigdata/flink-1.10.0$ tail -f log/flink-*-taskexecutor-*.out可以看到如下输出结果:
good : 2study : 1day : 2up : 15、还可以检查Flink Web UI来查看Job是怎样执行的。
打开浏览器,输入地址:http://master:8081 ,可查看检查调度程序的web前端。web前端应该报告有三个可用的TaskManager实例,以及正在执行的作业。Flink WebUI包含许多关于Flink集群及其作业(JobGraph、指标、检查点统计、TaskManager状态等)的有用而有趣的信息。
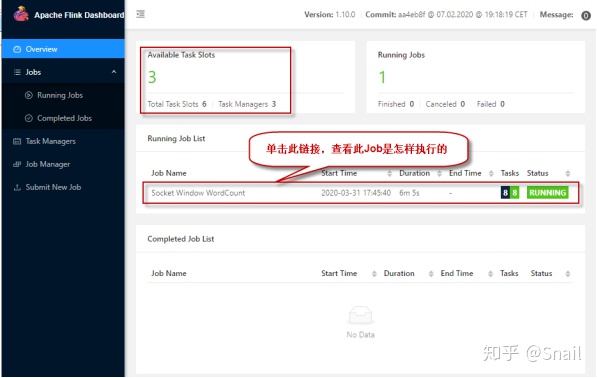
点击正在运行的作业,查看作业运行的详细信息,如下图所示:
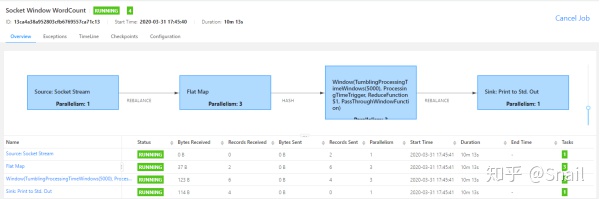
三、运行Flink自带的批处理作业-单词计数
Flink安装包自带了一个以文本文件作为数据源的单词计数程序,位于Flink安装目录下的"example/batch/"子目录下的WordCount.jar包中。
1、可以执行下面的命令来在Flink集群上执行该程序,读取HDFS上的输入数据文件进行处理,并输出计算结果到HDFS上。
注:从flink 1.8开始,Hadoop不再包含在Flink的安装包中,所以需要单独下载并拷贝到Flink的lib目录下。请从Flink官网下载flink-shaded-hadoop2-uber-2.7.5-1.10.0.jar并拷贝到Flink的lib目录下。
$ start-dfs.sh$ ./bin/flink run ./examples/batch/WordCount.jar--input hdfs://hadoop:8020/wc.txt --output hdfs://hadoop:8020/result上面的命令是在运行WordCount时读写HDFS中的文件,其中--input参数指定要处理的输入文件,--output指定计算结果输出到的结果文件。(注:如果不加hdfs://前缀,默认使用本地文件系统)
2、执行以下命令查询输出结果:
$ hdfs dfs -cat hdfs://hadoop:8020/result可以看到以下计算结果:
day 2
good 2
study 1
up 13、要停止Flink集群,在终端窗口输入以下命令:
$ ./bin/stop-cluster.sh
注:停止单个的Job Manager的命令:
./bin/jobmanager.sh stop cluster停止单个的Task Manager命令:
./bin/taskmanager.sh stop cluster




简单应用)








Libgdx应用框架之生命周期)



 GCC环境)
