目录
- 前言
- 一,数据文件结构
-
- 1.1 myava
- 1.2 annotations
- 1.3 annotations文件处理
- 1.4 frame_lists
- 1.5 frames
- 二,预训练模型
- 四,配置文件
-
- 4.1 创建新的yaml文件
- 4.2 yaml文件解释
- 五,训练
- 六,结果查看
前言
b站讲解
ava的数据集非常大,训练起来非常慢,这次我就把ava的数据集缩小到2个视频(原本有299个视频),这样做的目的是观察slowfast是如何训练ava数据集的。也为我后面制作自己的数据集做下铺垫。
一,数据文件结构
首先需要把原有的数据文件的内容进行修改,原来的数据文件针对的是299个视频图片,这次只针对2个视频图片。
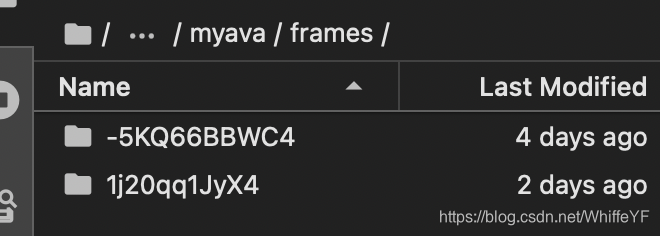
1.1 myava
新建一个文件夹myava,这里存放下图显示的文件夹:annotations、frame_lists、frames。
1.2 annotations
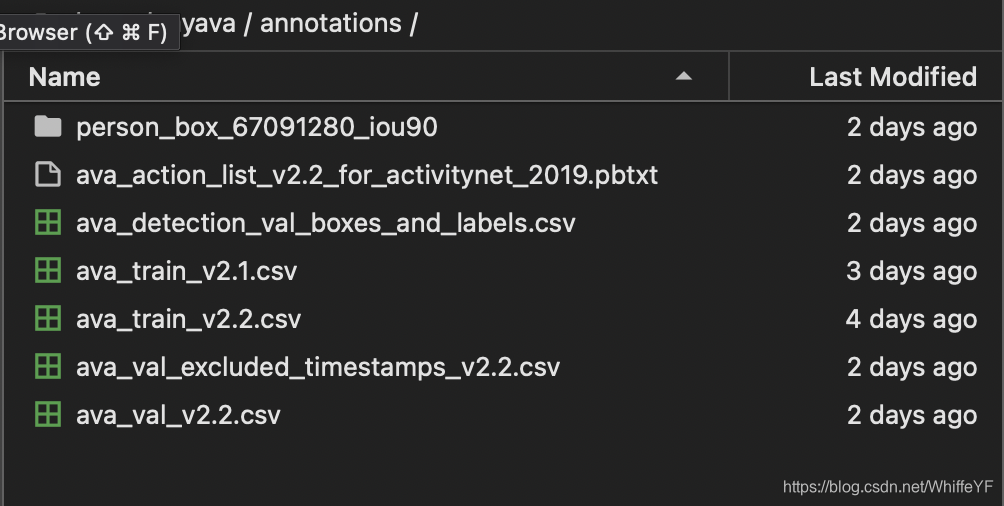
在annotations文件下,有如下文件,这些文件是从官网下载的

这里不要使用官网的默认版本,采用最新的2.2版本,官网有一个下载的链接:https://dl.fbaipublicfiles.com/pyslowfast/annotation/ava/ava_annotations.tar
下载后,解压(我是在ubuntu下解压的),使用tree查看其结构:
├── ava_annotations
│ ├── ava_action_list_v2.1_for_activitynet_2018.pbtxt
│ ├── ava_action_list_v2.2_for_activitynet_2019.pbtxt
│ ├── ava_action_list_v2.2.pbtxt
│ ├── ava_included_timestamps_v2.2.txt
│ ├── ava_test_excluded_timestamps_v2.1.csv
│ ├── ava_test_excluded_timestamps_v2.2.csv
│ ├── ava_test_v2.2.csv
│ ├── ava_train_excluded_timestamps_v2.1.csv
│ ├── ava_train_excluded_timestamps_v2.2.csv
│ ├── ava_train_v2.1.csv
│ ├── ava_train_v2.2.csv
│ ├── ava_val_excluded_timestamps_v2.1.csv
│ ├── ava_val_excluded_timestamps_v2.2.csv
│ ├── ava_val_v2.1.csv
│ ├── ava_val_v2.2.csv
│ ├── person_box_67091280_iou75
│ │ ├── ava_detection_test_boxes_and_labels.csv
│ │ ├── ava_detection_train_boxes_and_labels_include_negative.csv
│ │ ├── ava_detection_train_boxes_and_labels_include_negative_v2.1.csv
│ │ ├── ava_detection_train_boxes_and_labels_include_negative_v2.2.csv
│ │ ├── ava_detection_val_boxes_and_labels.csv
│ │ ├── ava_detection_val_for_training_boxes_and_labels_include_negative.csv
│ │ └── ava_detection_val_for_training_boxes_and_labels_include_negative_v2.2.csv
│ ├── person_box_67091280_iou90
│ │ ├── ava_action_list_v2.1_for_activitynet_2018.pbtxt
│ │ ├── ava_detection_test_boxes_and_labels.csv
│ │ ├── ava_detection_train_boxes_and_labels_include_negative.csv
│ │ ├── ava_detection_train_boxes_and_labels_include_negative_v2.1.csv
│ │ ├── ava_detection_train_boxes_and_labels_include_negative_v2.2.csv
│ │ ├── ava_detection_val_boxes_and_labels.csv
│ │ ├── ava_detection_val_for_training_boxes_and_labels_include_negative.csv
│ │ ├── ava_detection_val_for_training_boxes_and_labels_include_negative_v2.1.csv
│ │ ├── ava_detection_val_for_training_boxes_and_labels_include_negative_v2.2.csv
│ │ ├── ava_train_predicted_boxes.csv
│ │ ├── ava_train_v2.1.csv
│ │ ├── ava_val_excluded_timestamps_v2.1.csv
│ │ ├── ava_val_predicted_boxes.csv -> ava_detection_val_boxes_and_labels.csv
│ │ ├── ava_val_v2.1.csv
│ │ ├── test.csv
│ │ ├── train.csv
│ │ └── val.csv
│ ├── test.csv
│ ├── train.csv
│ └── val.csv
└── ava_annotations.tar这些文件不能全要,只去我们所需的,因为我们用的每一个都是需要进行修改的。
下面是需要的文件:annotations
—person_box_67091280_iou90
------ava_detection_train_boxes_and_labels_include_negative_v2.2.csv
------ava_detection_val_boxes_and_labels.csv
—ava_action_list_v2.2_for_activitynet_2019.pbtxt
—ava_detection_val_boxes_and_labels.csv
—ava_train_v2.1.csv
—ava_train_v2.2.csv
—ava_val_excluded_timestamps_v2.2.csv
—ava_val_v2.2.csv
1.3 annotations文件处理
每一个文件都需要处理,下面开始处理:
1,/annotations/person_box_67091280_iou90/ava_detection_train_boxes_and_labels_include_negative_v2.2.csv:
如下图所示,只要第一列名为: -5KQ66BBWC4的所有行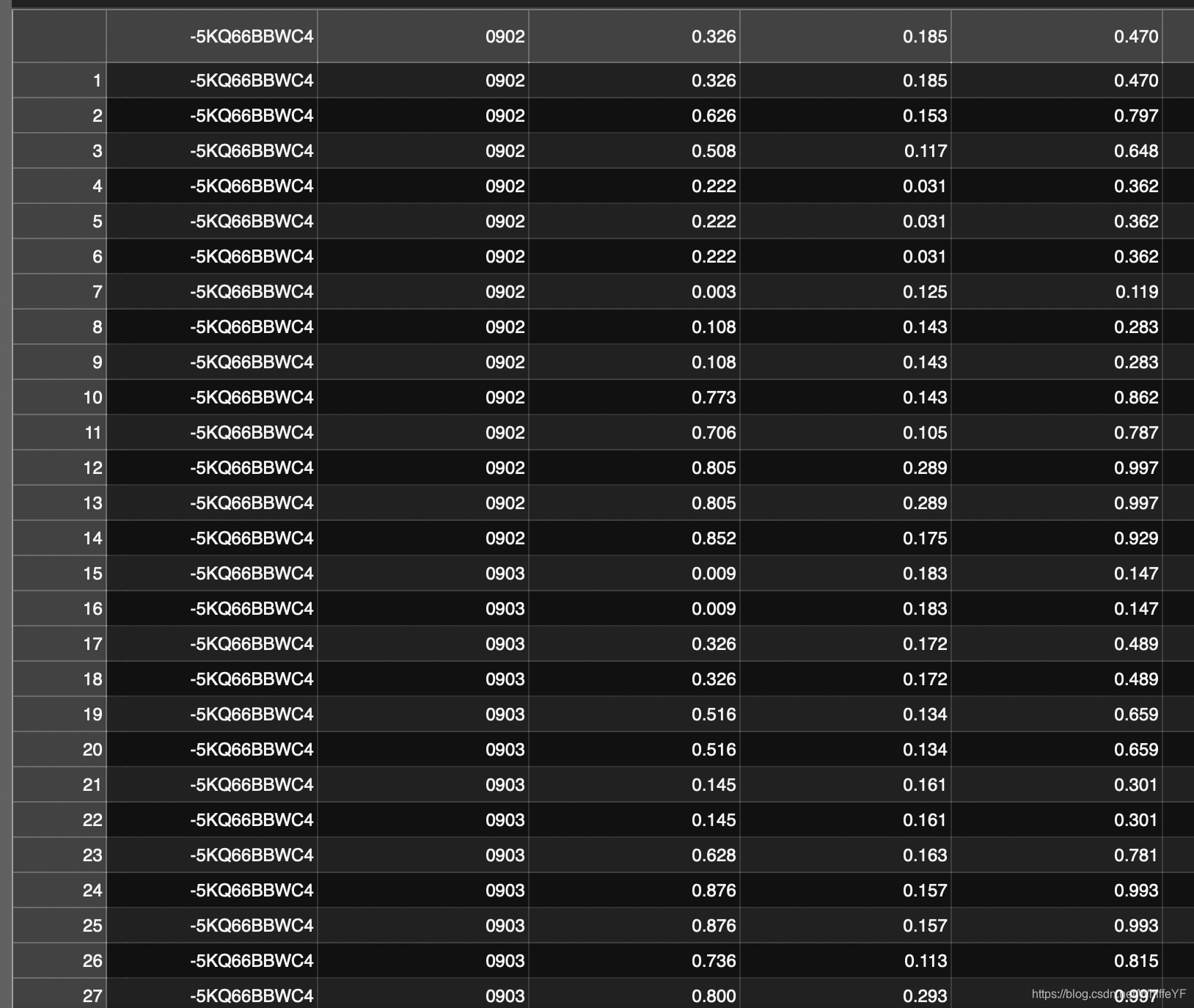
2,/annotations/person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv
如下图所示,只要第一列为:1j20qq1JyX4 的所有行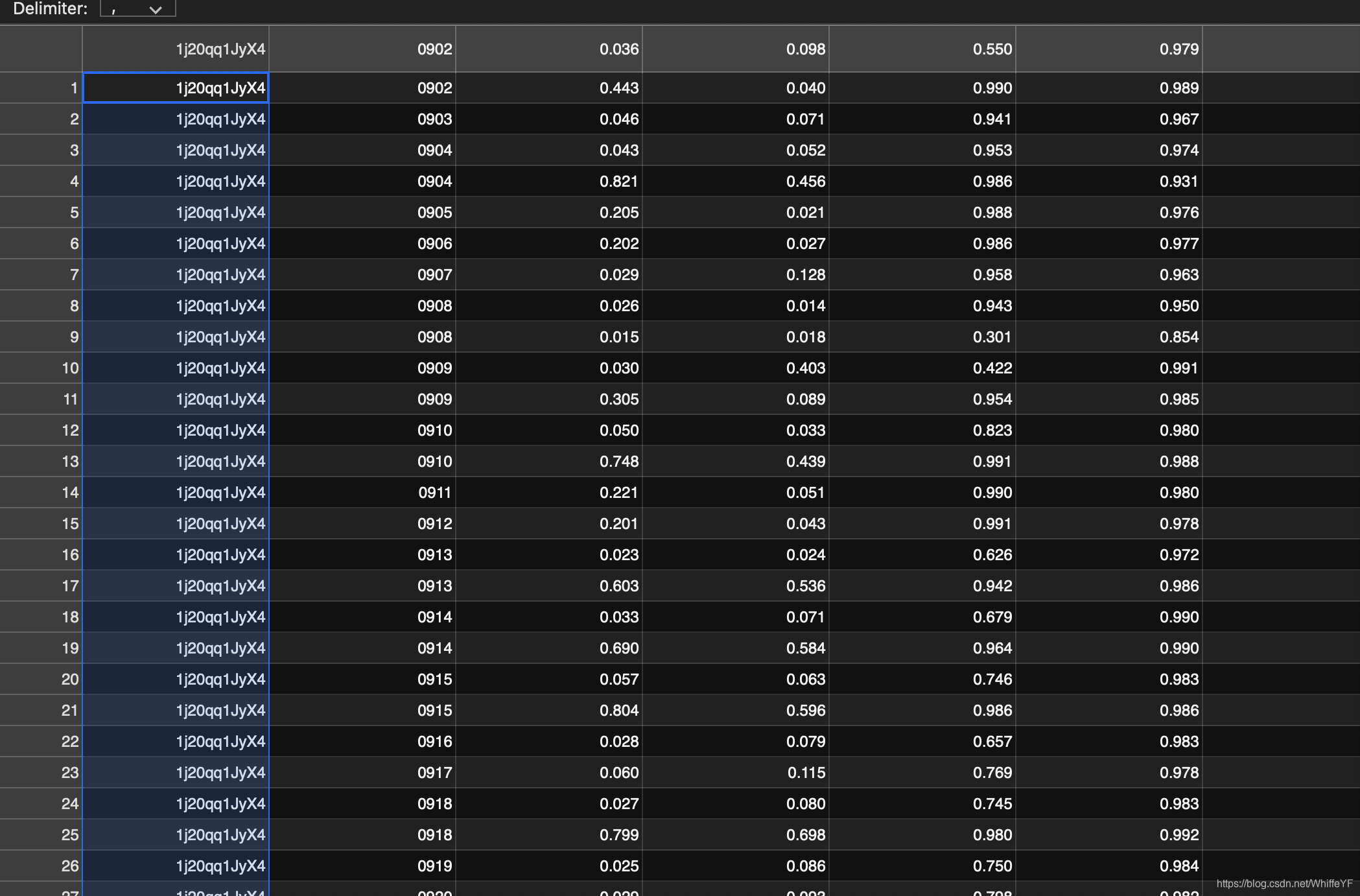
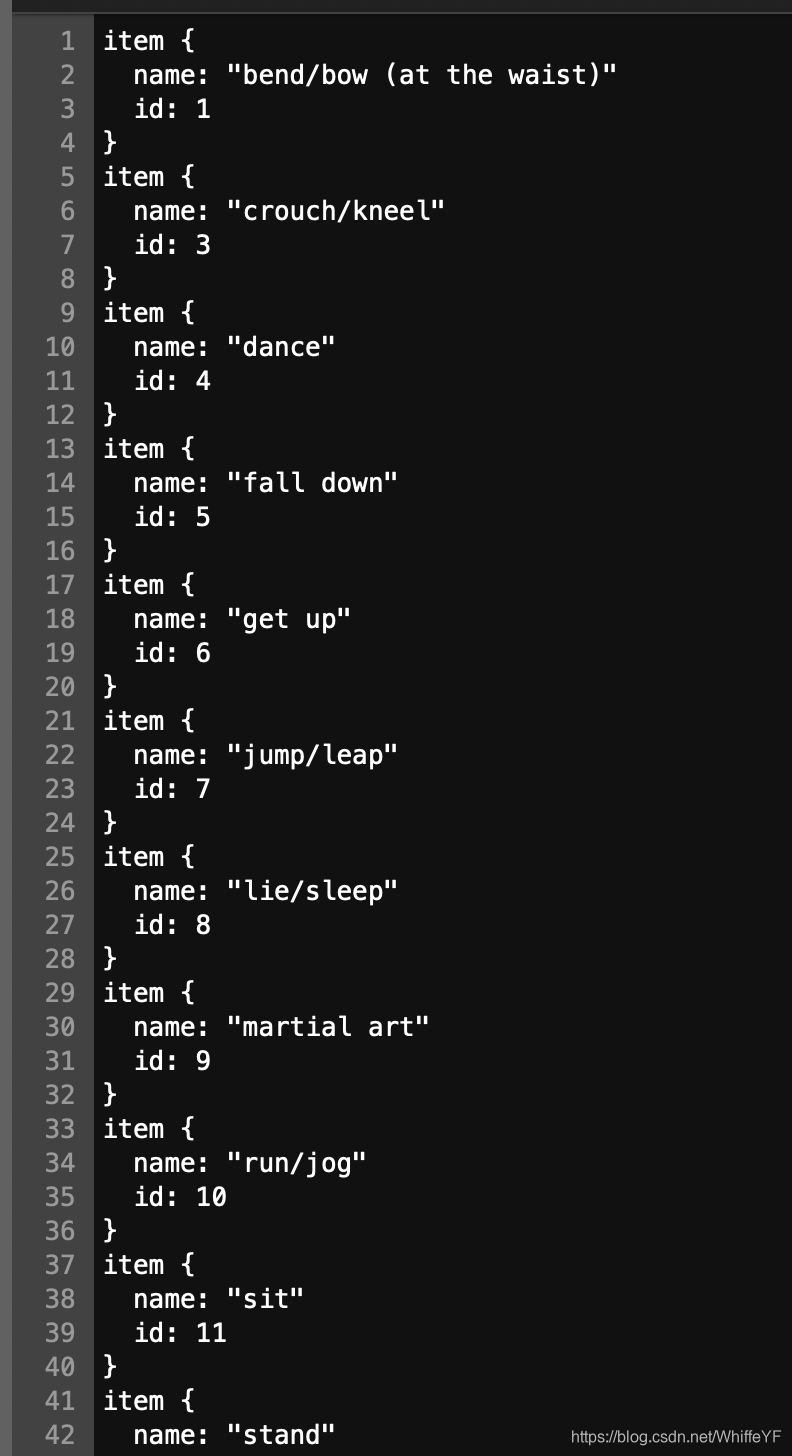
3,/annotations/ava_action_list_v2.2_for_activitynet_2019.pbtxt:
这个文件不改,这是用来记录行为种类的,共有80个
4,annotations/ava_detection_val_boxes_and_labels.csv
如下图所示,只要第一列为:1j20qq1JyX4 的所有行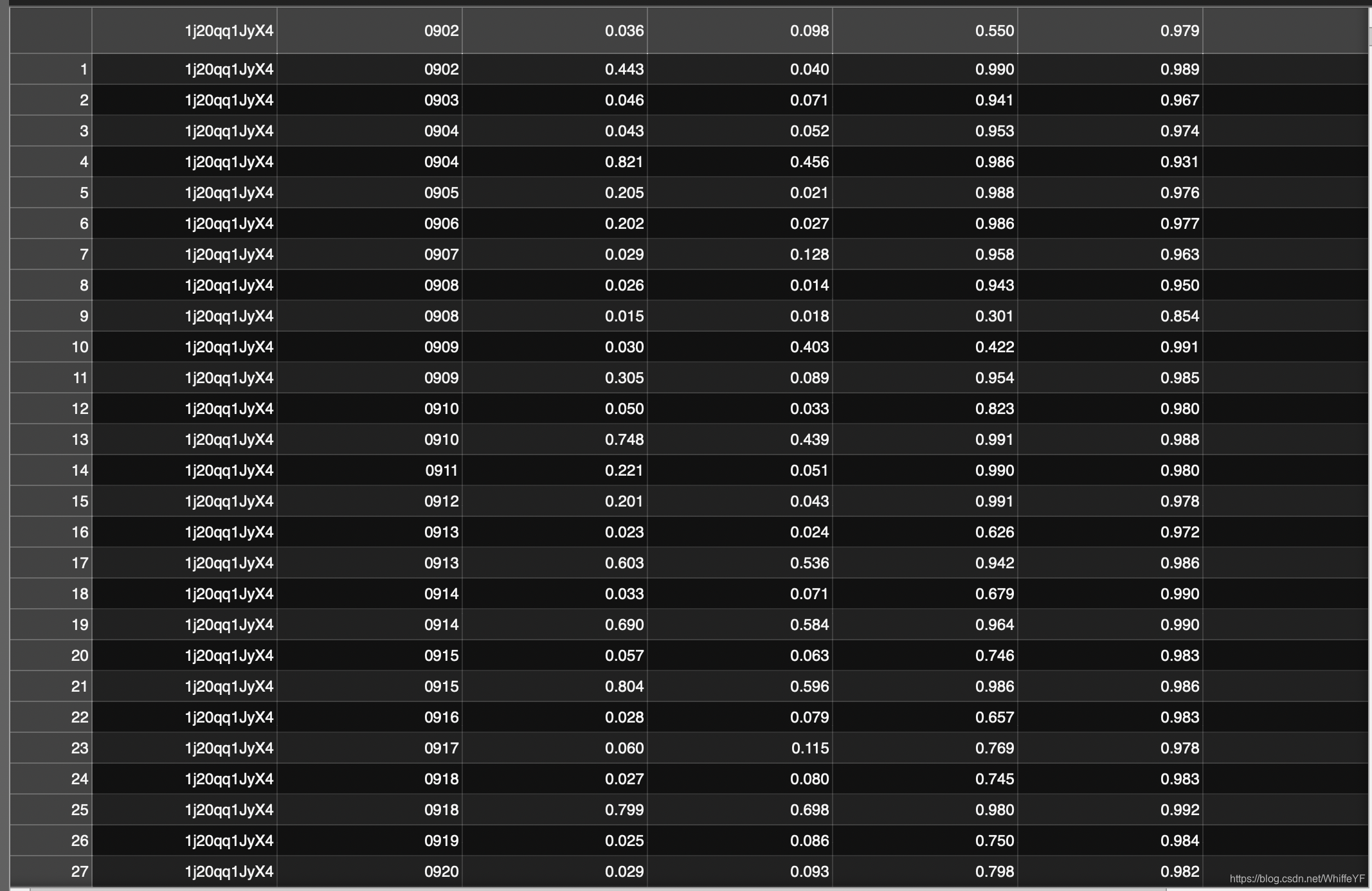
5,/annotations/ava_train_v2.1.csv, /annotations/ava_train_v2.2csv
这两个文件非常类似,处理方法也一样
如下图所示,只要第一列名为: -5KQ66BBWC4的所有行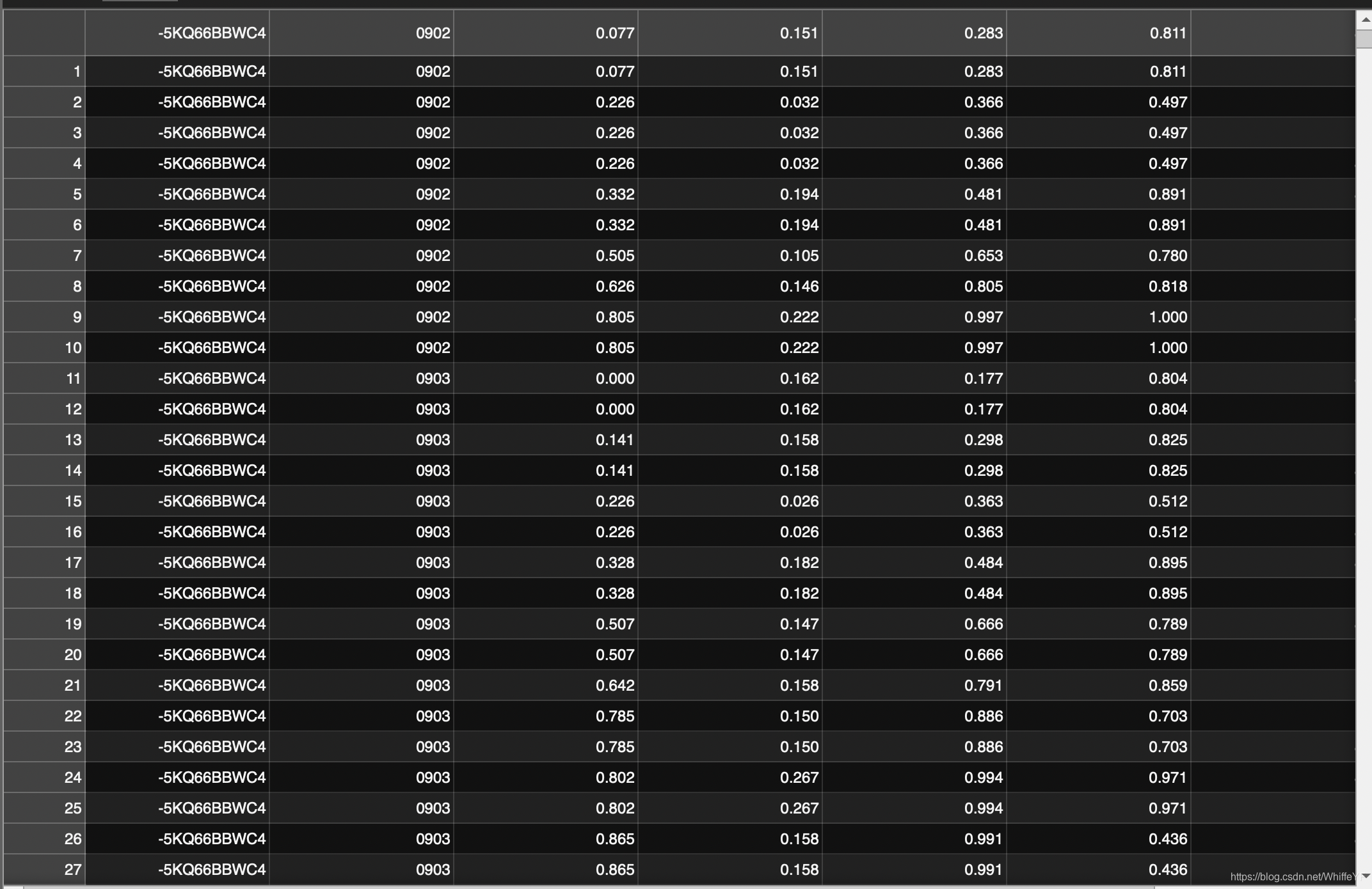
6,/annotations/ava_val_excluded_timestamps_v2.2.csv
这个是空文件,因为在我们所选的视频中,没有需要排除的帧。
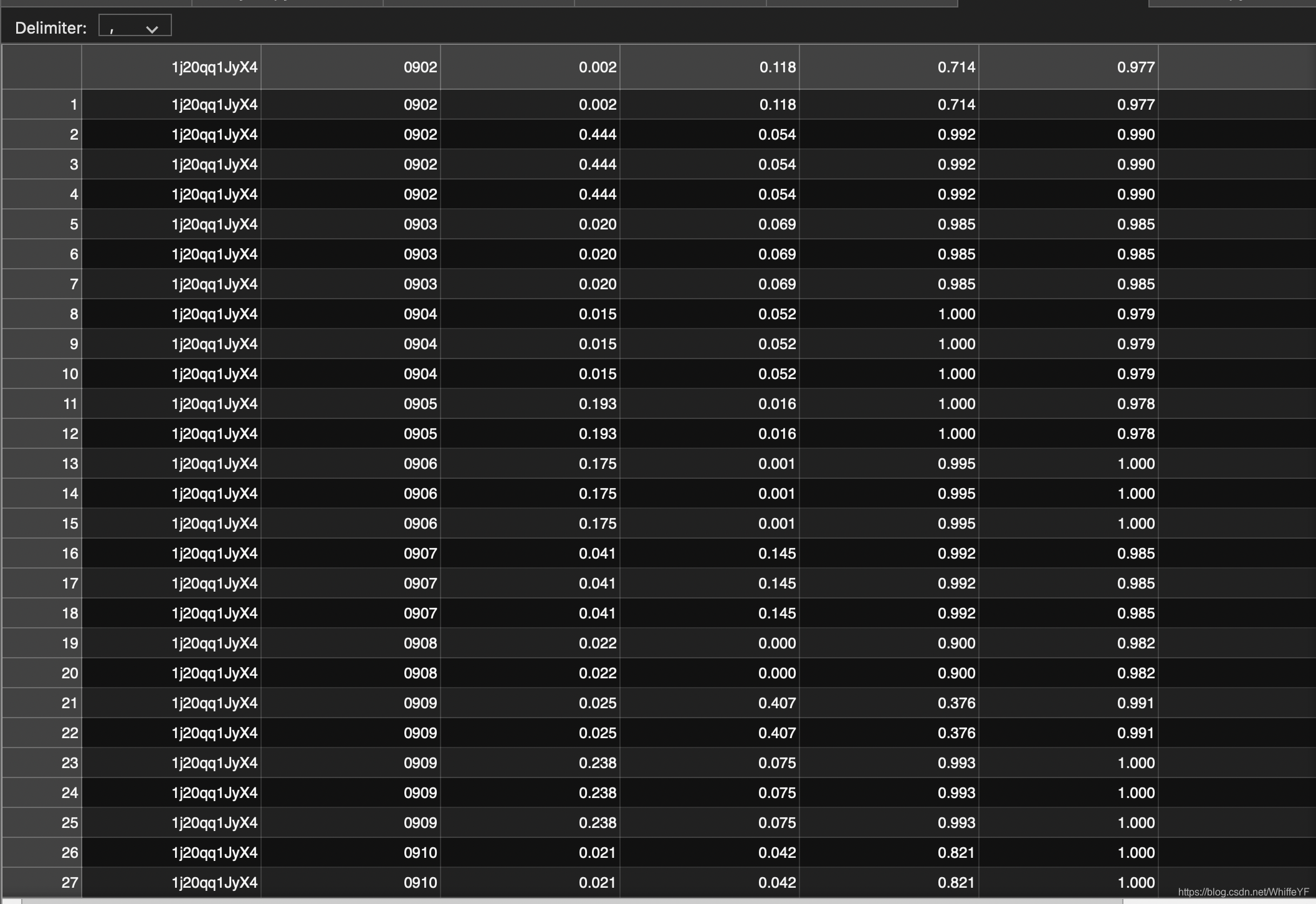
7,/annotations/ava_val_v2.2.csv
如下图所示,只要第一列为:1j20qq1JyX4 的所有行
1.4 frame_lists
在frame_lists目录下,这里只存放了两个文件:train.csv、val.csv
下载地址:train.csv、val.csv
同样需要修改,同上一小节讲的。
1,frame_lists/train.csv
如下图所示,只要第一列名为: -5KQ66BBWC4的所有行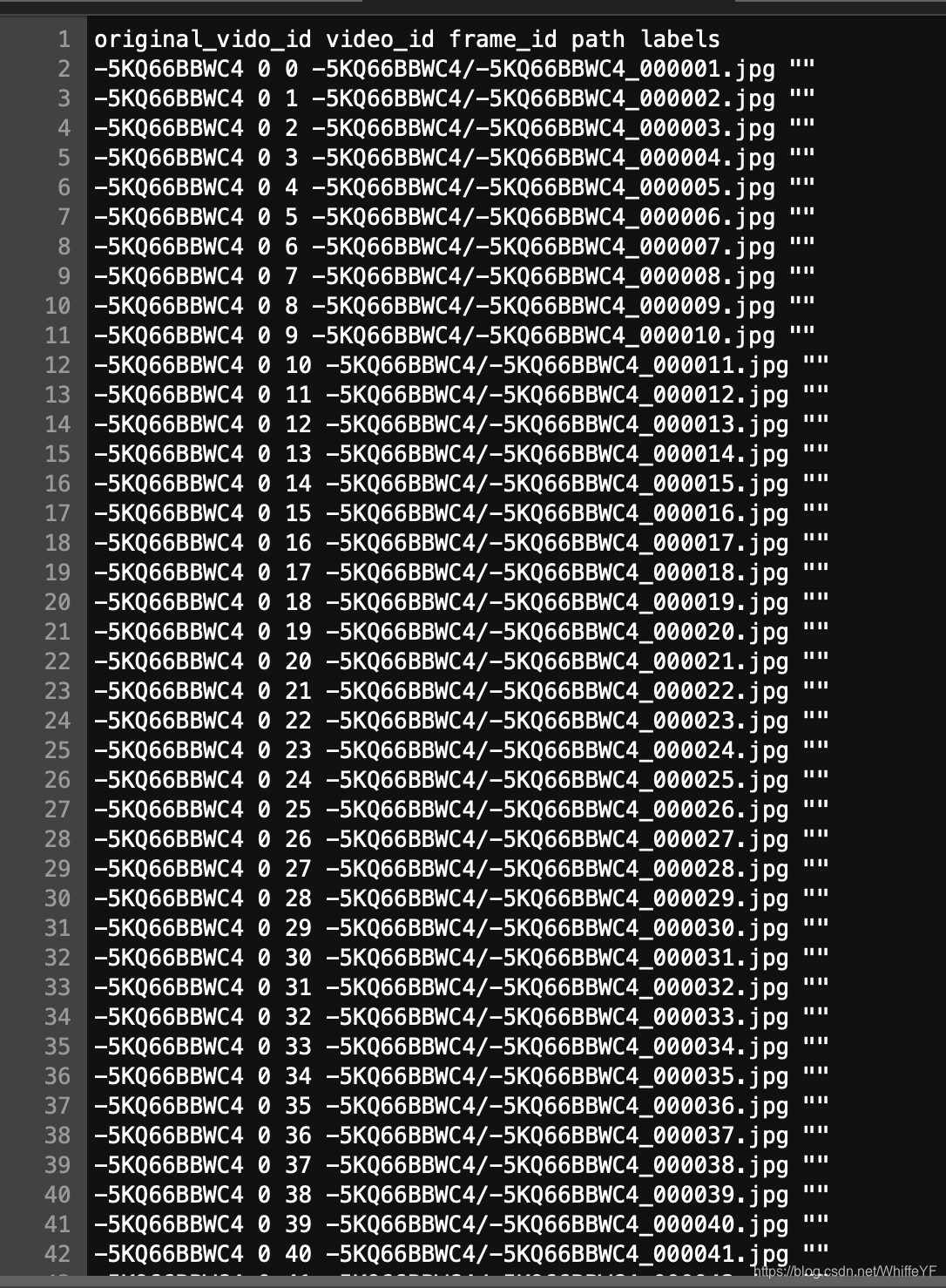
2,frame_lists/val.csv
如下图所示,只要第一列为:1j20qq1JyX4 的所有行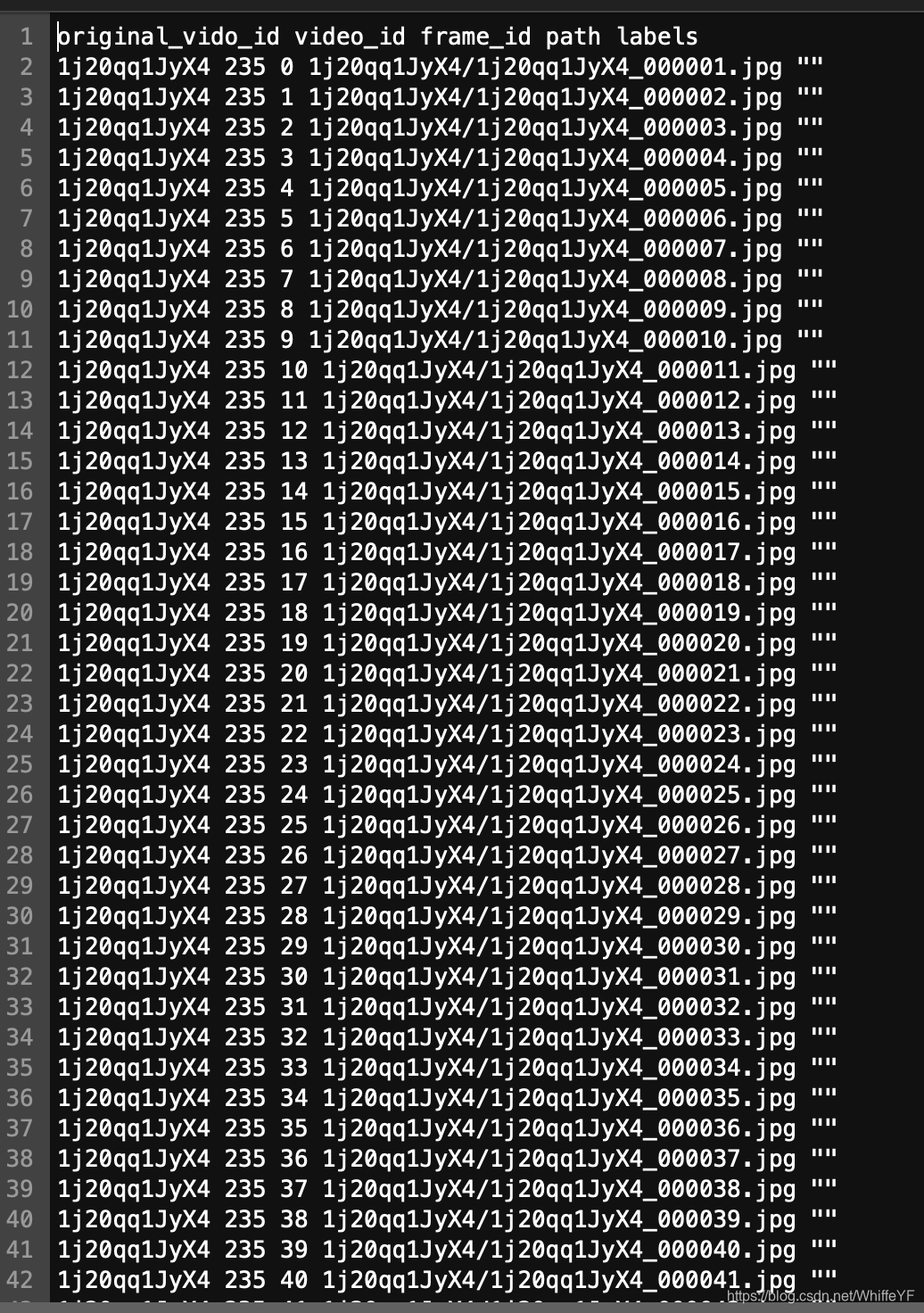
1.5 frames
/frames下有两个文件夹:-5KQ66BBWC4,1j20qq1JyX4
这两个文件夹里存放的就是ava剪辑后的图片,制作过程参考官网
二,预训练模型
最好使用预训练模型,这样可以缩短训练的一个时间,我用的预训练模型如下图
模型下载官网,预训练模型下载链接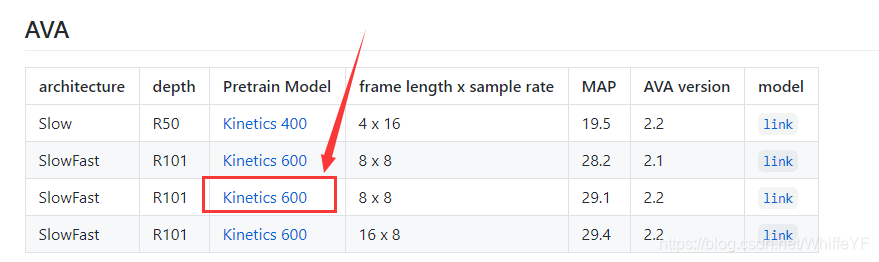
下载下来后,放在文件夹/SlowFast/configs/AVA/c2/下面,如下图(由于下载的预训练模型和之前一个模型重名,所以我在预训练模型后面加了个ss)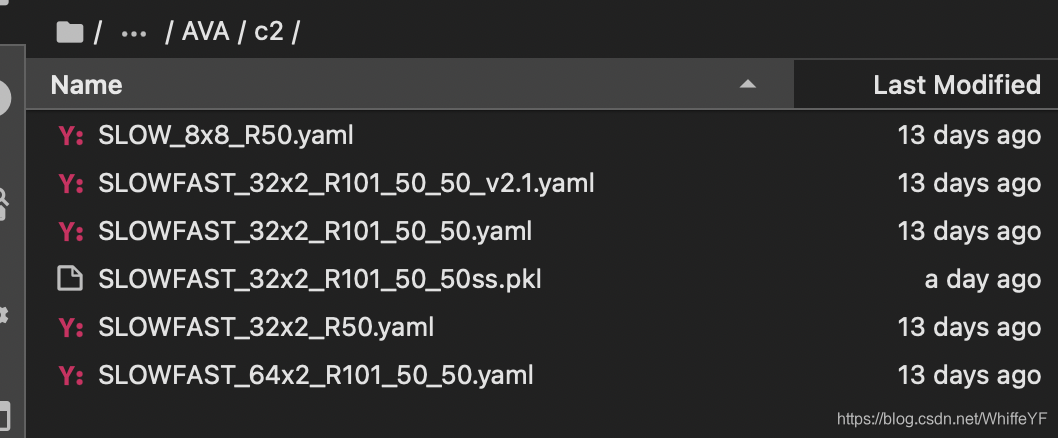
四,配置文件
4.1 创建新的yaml文件
在/SlowFast/configs/AVA/下创建一个新的yaml文件:SLOWFAST_32x2_R50_SHORT4.yaml,如下图
代码如下:
TRAIN:ENABLE: TrueDATASET: avaBATCH_SIZE: 2 #64EVAL_PERIOD: 5CHECKPOINT_PERIOD: 1AUTO_RESUME: TrueCHECKPOINT_FILE_PATH: '/home/lxn/0yangfan/Slowfast2/SlowFast-master/configs/AVA/c2/SLOWFAST_32x2_R101_50_50ss.pkl' #path to pretrain modelCHECKPOINT_TYPE: caffe2
DATA:NUM_FRAMES: 32SAMPLING_RATE: 2TRAIN_JITTER_SCALES: [256, 320]TRAIN_CROP_SIZE: 224TEST_CROP_SIZE: 224INPUT_CHANNEL_NUM: [3, 3]PATH_TO_DATA_DIR: '/disk6T/ava'
DETECTION:ENABLE: TrueALIGNED: True
AVA:FRAME_DIR: '/disk6T/myava/frames'FRAME_LIST_DIR: '/disk6T/myava/frame_lists'ANNOTATION_DIR: '/disk6T/myava/annotations'#LABEL_MAP_FILE: 'ava_action_list_v2.1_for_activitynet_2018.pbtxt'#0GROUNDTRUTH_FILE: 'ava_val_v2.1.csv'#TRAIN_GT_BOX_LISTS: ['ava_train_v2.1.csv']DETECTION_SCORE_THRESH: 0.8TRAIN_PREDICT_BOX_LISTS: ["ava_train_v2.2.csv","person_box_67091280_iou90/ava_detection_train_boxes_and_labels_include_negative_v2.2.csv",]#TRAIN_PREDICT_BOX_LISTS: ["ava_train_predicted_boxes.csv"]TEST_PREDICT_BOX_LISTS: ["person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]#TEST_PREDICT_BOX_LISTS: ["ava_test_predicted_boxes.csv"]#EXCLUSION_FILE: "ava_train_excluded_timestamps_v2.1.csv"SLOWFAST:ALPHA: 4BETA_INV: 8FUSION_CONV_CHANNEL_RATIO: 2FUSION_KERNEL_SZ: 7
RESNET:ZERO_INIT_FINAL_BN: TrueWIDTH_PER_GROUP: 64NUM_GROUPS: 1DEPTH: 50TRANS_FUNC: bottleneck_transformSTRIDE_1X1: FalseNUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:LOCATION: [[[], []], [[], []], [[], []], [[], []]]GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]INSTANTIATION: dot_productPOOL: [[[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]]]
BN:USE_PRECISE_STATS: FalseNUM_BATCHES_PRECISE: 200
SOLVER:BASE_LR: 0.1LR_POLICY: steps_with_relative_lrsSTEPS: [0, 10, 15, 20]LRS: [1, 0.1, 0.01, 0.001]MAX_EPOCH: 20MOMENTUM: 0.9WEIGHT_DECAY: 1e-7WARMUP_EPOCHS: 5.0WARMUP_START_LR: 0.000125OPTIMIZING_METHOD: sgd
MODEL:NUM_CLASSES: 80ARCH: slowfastMODEL_NAME: SlowFastLOSS_FUNC: bceDROPOUT_RATE: 0.5HEAD_ACT: sigmoid
TEST:ENABLE: FalseDATASET: avaBATCH_SIZE: 8
DATA_LOADER:NUM_WORKERS: 2PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: .4.2 yaml文件解释
- TRAIN
1.1. ENABLE: True。这里将TRAIN设置为TRUE,同样的,也要TEST.ENABLE设置为False(我们只需要训练的过程)
1.2 BATCH_SIZE: 2 #64.这里batch_size是由于我的电脑显存不够,只能设置为2,如果大家的显存够大,可以把这个batch_size设置的大一些。
1.3 CHECKPOINT_FILE_PATH: ‘/home/lxn/0yangfan/Slowfast2/SlowFast-master/configs/AVA/c2/SLOWFAST_32x2_R101_50_50ss.pkl’ 这里放的是预训练模型的位置 - DATA
2.1 PATH_TO_DATA_DIR: ‘/disk6T/ava’ 这里是ava文件的位置
其他也比较简单,大家就自己理解了。
五,训练
python tools/run_net.py --cfg configs/AVA/SLOWFAST_32x2_R50_SHORT4.yaml
六,结果查看
这里就要参考之前的博客进行结果的查看:
【SlowFast复现】SlowFast Networks for Video Recognition复现代码 使用自己的视频进行demo检测
使用训练后的权重,对我们的视频进行检测,会发现检测结果很糟糕。毕竟只是用了1个训练视频和1个验证视频
最后检验的视频会上传到B站中。
任何程序错误,以及技术疑问或需要解答的,请添加



)




onnx模型转engine文件)












