数据挖掘一般是指从大量的数据中自动搜索隐藏于其中的有着特殊关系性的信息的过程。
•分类和聚类
•分类(Classification)就是按照某种标准给对象贴标签,再根据标签来区分归类,类别数不变。
•聚类(clustering)是指根据“物以类聚”的原理,将本身没有类别的样本聚集成不同的组,这样的一组数据对象的集合叫做簇,并且对每一个这样的簇进行描述的过程。
C4.5算法应该解决的问题有哪些呢?
一、如何选择测试属性构造决策树?
二、对于连续变量决策树中的测试是怎样的呢?
三、如何选择处理连续变量(阈值)?
四、如何终止树的增长?
五、如何确定叶子节点的类?
决策树:

如何选择测试属性构造决策树?
•用信息增益率来选择属性
•这个指标实际上就等于增益/熵,之所以采用这个指标是为了克服采用增益作为衡量标准的缺点,采用增益作为衡量标准会导致分类树倾向于优先选择那些具有比较多的分支的测试,也就是选择取值较多的属性,这种倾向需要被抑制。
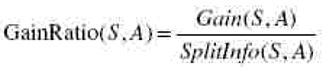
•其中,S1到Sc是c个不同值的属性A分割S而形成的c个样本子集。如按照属性A把S集(含30个用例)分成了10个用例和20个用例两个集合则SplitInfo(S,A)=-1/3*log(1/3)-2/3*log(2/3)

•很明显,我们看到这个例子中对于连续变量,所有连续变量的测试分支都是2条,因此在C4.5算法中,连续变量的分支总是两条,分支其测试分支分别对应着{<=θ,>θ},θ对应着分支阈值,但是这个θ怎么确定呢?
•很简单,把需要处理的样本(对应根节点)或样本子集(对应子树)按照连续变量的大小从小到大进行排序,假设该属性对应的不同的属性值一共有N个,那么总共有N-1个可能的候选分割阈值点,每个候选的分割阈值点的值为上述排序后的属性值链表中两两前后连续元素的中点,那么我们的任务就是从这个N-1个候选分割阈值点中选出一个,使得前面提到的信息论标准最大。举个例子,对于Golf数据集,我们来处理温度属性,来选择合适的阈值。首先按照温度大小对对应样本进行排序如下:

•那么可以看到有13个可能的候选阈值点,比如middle[64,65], middle[65,68]….,middle[83,85]。那么最优的阈值该选多少呢?应该是middle[71,72],如上图中红线所示。为什么呢?如下计算:

•通过上述计算方式,0.939是最大的,因此测试的增益是最小的。(测试的增益和测试后的熵是成反比的,这个从后面的公式可以很清楚的看到)。根据上面的描述,我们需要对每个候选分割阈值进行增益或熵的计算才能得到最优的阈值,我们需要算N-1次增益或熵(对应温度这个变量而言就是13次计算)。能否有所改进呢?少算几次,加快速度。
如何终止树的增长?
•前面提到树的增长实际上是一个递归过程,那么这个递归什么时候到达终止条件退出递归呢?有两种方式,第一种方式是如果某一节点的分支所覆盖的样本都属于同一类的时候,那么递归就可以终止,该分支就会产生一个叶子节点.还有一种方式就是,如果某一分支覆盖的样本的个数如果小于一个阈值,那么也可产生叶子节点,从而终止树的增长。
如何确定叶子节点的类?
•Tree-Growth终止的方式有2种,对于第一种方式,叶子节点覆盖的样本都属于同一类,那么这种情况下叶子节点的类自然不必多言。对于第二种方式,叶子节点覆盖的样本未必属于同一类,直接一点的方法就是,该叶子节点所覆盖的样本哪个类占大多数,那么该叶子节点的类别就是那个占大多数的类。
借鉴于:大数据经典算法c4.5讲解