JavaArrayList集合学习及集合学习概述
一、Java集合概述
Java 集合, 也叫作容器,主要是由两大接口派生而来:一个是 Collection接口,主要用于存放单一元素;另一个是 Map 接口,主要用于存放键值对。对于Collection 接口,下面又有三个主要的子接口:List、Set 和 Queue。
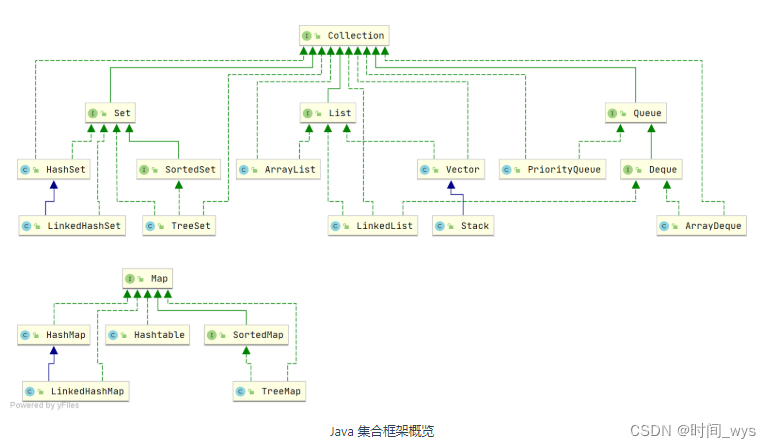
问题1:说说List、Set、Queue、Map四者的区别
- List(对付顺序的好帮手): 存储的元素是有序的、可重复的。
- Set(注重独一无二的性质): 存储的元素不可重复的。
- Queue(实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。
- Map:使用**键值对(key-value)**存储,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值
问题2:什么是ArrayList?简单介绍一下
ArrayList是List接口的实现类,其底层采用Object动态数组实现,不是线程安全的,ArrayList存储的元素是有序的,可重复的,ArrayList 支持插入(add)、删除(remove)、访问(get)等常见操作,并且提供了丰富的 API 操作方法。
问题3:说说ArrayList和Array(数组)的区别?
- 1、ArrayList是基于动态数组实现的创建时不需要指定大小,Array是静态数组创建时必须指定大小。
- 2、ArrayList会根据实际存储的元素动态地扩容,而 Array 被创建之后就不能改变它的长度了。
- 3、ArrayList 允许你使用泛型来确保类型安全,Array 则不可以。
- 4、ArrayList 中只能存储对象,对于基本类型数据,需要使用其对应的包装类(如 Integer、Double 等)。Array 可以直接存储基本类型数据,也可以存储对象。
- 5、ArrayList 支持插入(add)、删除(remove)、访问(get)等常见操作,并且提供了丰富的 API 操作方法。Array 只是一个固定长度的数组,只能按照下标访问其中的元素,不具备动态添加、删除元素的能力。
问题4:ArrayList 和 Vector 的区别?
- ArrayList 是 List 的主要实现类,底层使用 Object[]存储,适用于频繁的查找工作,线程不安全 。
- Vector 是 List 的古老实现类,底层使用Object[] 存储,线程安全。
问题5:Vector和Stack的区别?
- Vector 和 Stack 两者都是线程安全的,都是使用 synchronized 关键字进行同步处理。
- Stack(栈)继承自Vector(列表),栈是先进后出。
问题6:ArrayList 和 LinkedList区别
- 是否线程安全:ArrayList 和 LinkedList都是不同步的,也就是不保证线程安全。
- 底层数据结构:ArrayList 底层使用的是 Object 数组;LinkedList 底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。)
- 是否支持快速随机访问: LinkedList 不支持高效的随机元素访问,而 ArrayList(实现了 RandomAccess 接口) 支持。(注意:虽然LinkedList不支持随机访问,但它也有get方法,可以通过get指定位置的下标来获取到对应的元素,但它是通过遍历双向链表,从头节点开始顺序遍历得到的)
- 插入和删除是否受元素位置的影响:ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。比如:执行add(E e)方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element)),时间复杂度就为 O(n)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。LinkedList 采用链表存储,所以在头尾插入或者删除元素不受元素位置的影响(add(E e)、addFirst(E e)、addLast(E e)、removeFirst()、 removeLast()),时间复杂度为 O(1),如果是要在指定位置 i 插入和删除元素的话(add(int index, E element),remove(Object o),remove(int index)), 时间复杂度为 O(n) ,因为需要先移动到指定位置再插入和删除。
- 内存空间占用: ArrayList 的空间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
问题7:LinkedList 为什么不能实现 RandomAccess 接口?
RandomAccess 是一个标记接口,用来表明实现该接口的类支持随机访问(即可以通过索引快速访问元素)。由于 LinkedList 底层数据结构是链表,内存地址不连续,只能通过指针来定位,不支持随机快速访问,所以不能实现 RandomAccess 接口。
(需要注意虽然LinkedList不支持随机访问,但它也有get方法,可以通过get指定位置的下标来获取到对应的元素,但它是通过遍历双向链表,从头节点开始顺序遍历得到的)
问题8:ArrayList 可以添加 null 值吗?
ArrayList 中可以存储任何类型的对象,包括 null 值。不过,不建议向ArrayList 中添加 null 值, null 值无意义,会让代码难以维护比如忘记做判空处理就会导致空指针异常。
二、ArrayList的扩容机制分析(***)
(一)ArrayList 的构造函数
ArrayList 的初始化方式有三种:
- 方式1:创建无参构造函数
- 方式2:创建带初始化容量参数的构造函数(用户自己指定初始容量
- 方式3:创建包含指定collection集合元素的集合
/*** 集合的初始化方式(三种)*///方式1:创建无参构造函数List list1 = new ArrayList();//方式2:创建带初始化容量参数的构造函数(用户自己指定初始容量)List list2 = new ArrayList<>(5);//方式3:创建包含指定collection集合元素的集合List<Integer> temp = new ArrayList<Integer>();temp.add(1);temp.add(2);temp.add(3);List list3 = new ArrayList(temp);
三种方式具体的源代码如下:
transient Object[] elementData; // non-private to simplify nested class access/*** 默认初始容量大小*/private static final int DEFAULT_CAPACITY = 10;private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};/***默认构造函数,使用初始容量10构造一个空列表(无参数构造,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。)*/public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}/*** 带初始容量参数的构造函数。(用户自己指定容量)*/public ArrayList(int initialCapacity) {if (initialCapacity > 0) {//初始容量大于0//创建initialCapacity大小的数组this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {//初始容量等于0//创建空数组this.elementData = EMPTY_ELEMENTDATA;} else {//初始容量小于0,抛出异常throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);}}/***构造包含指定collection元素的列表,这些元素利用该集合的迭代器按顺序返回*如果指定的集合为null,throws NullPointerException。*/public ArrayList(Collection<? extends E> c) {elementData = c.toArray();if ((size = elementData.length) != 0) {// c.toArray might (incorrectly) not return Object[] (see 6260652)if (elementData.getClass() != Object[].class)elementData = Arrays.copyOf(elementData, size, Object[].class);} else {// replace with empty array.this.elementData = EMPTY_ELEMENTDATA;}}注意:
以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。
(二)ArrayList的扩容机制
这里以无参构造函数的方式创建ArrayList为例。
1、先来看 add 方法
/*** 将指定的元素追加到此列表的末尾。*/public boolean add(E e) {//添加元素之前,先调用ensureCapacityInternal方法//这里size +1 作用:主要是为了确保在数组添加完元素之后仍有足够的容量,//起到一个更加保险的作用ensureCapacityInternal(size + 1); // Increments modCount!!//这里看到ArrayList添加元素的实质就相当于为数组赋值elementData[size++] = e;return true;}2、再来看看 ensureCapacityInternal() 方法
//得到最小扩容量private void ensureCapacityInternal(int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {// 获取默认的容量和传入参数的较大值minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);}ensureExplicitCapacity(minCapacity);}当 要 add 进第 1 个元素时,minCapacity 为 1,在 Math.max()方法比较后,minCapacity 为 10。
3、ensureExplicitCapacity() 方法
//判断是否需要扩容private void ensureExplicitCapacity(int minCapacity) {modCount++;// overflow-conscious codeif (minCapacity - elementData.length > 0)//调用grow方法进行扩容,调用此方法代表已经开始扩容了grow(minCapacity);}这里我们对上述进行概述分析下:
- 当我们要 add 进第 1 个元素到 ArrayList 时,elementData.length 为 0 (因为还是一个空的 list),因为执行了 ensureCapacityInternal() 方法以当前空数组长度0 和 默认值10 进行比较 ,0 < 10 所以 minCapacity 此时为 10。此时,minCapacity - elementData.length > 0成立,所以会进入 grow(minCapacity) 方法。
- 当 add 第 2 个元素时,minCapacity 为 2,此时 elementData.length(容量)在添加第一个元素后扩容成 10 了。此时,minCapacity - elementData.length > 0 不成立,所以不会进入 (执行)grow(minCapacity) 方法。
- 添加第 3、4···到第 10 个元素时,依然不会执行 grow 方法,数组容量都为 10。
- 直到添加第 11 个元素,minCapacity(为 11)比 elementData.length(为 10)要大。进入 grow 方法进行扩容。
4、grow() 方法(***)
/*** 要分配的最大数组大小*/private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;/*** ArrayList扩容的核心方法。*/private void grow(int minCapacity) {// oldCapacity为旧容量,newCapacity为新容量int oldCapacity = elementData.length;//将oldCapacity 右移一位,其效果相当于oldCapacity /2,//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,int newCapacity = oldCapacity + (oldCapacity >> 1);//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,if (newCapacity - minCapacity < 0)newCapacity = minCapacity;// 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,//如果minCapacity大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:elementData = Arrays.copyOf(elementData, newCapacity);}注意:int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右(oldCapacity 为偶数就是 1.5 倍,否则是 1.5 倍左右)! 奇偶不同,比如:10+10/2 = 15, 33+33/2=49。如果是奇数的话会丢掉小数.
我们来详细探究一下grow方法:
- 当 add 第 1 个元素时,oldCapacity 为 0,经比较后第一个 if 判断成立,newCapacity = minCapacity(为 10)。但是第二个 if 判断不会成立,即 newCapacity 不比 MAX_ARRAY_SIZE 大,则不会进入 hugeCapacity 方法。数组容量为 10,add 方法中 return true,size 增为 1。
- 当 add 第 11 个元素进入 grow 方法时,newCapacity 为 15,比 minCapacity(为 11)大,第一个 if 判断不成立。新容量没有大于数组最大 size,不会进入 hugeCapacity 方法。数组容量扩为 15,add 方法中 return true,size 增为 11。以此类推······
5、hugeCapacity() 方法。
从上面 grow() 方法源码我们知道:如果新容量大于 MAX_ARRAY_SIZE,进入(执行) hugeCapacity() 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,如果 minCapacity 大于最大容量,则新容量则为Integer.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 Integer.MAX_VALUE - 8。
private static int hugeCapacity(int minCapacity) {if (minCapacity < 0) // overflowthrow new OutOfMemoryError();//对minCapacity和MAX_ARRAY_SIZE进行比较//若minCapacity大,将Integer.MAX_VALUE作为新数组的大小//若MAX_ARRAY_SIZE大,将MAX_ARRAY_SIZE作为新数组的大小//MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;return (minCapacity > MAX_ARRAY_SIZE) ?Integer.MAX_VALUE :MAX_ARRAY_SIZE;}(三)System.arraycopy() 和 Arrays.copyOf()方法
阅读源码的话,我们就会发现 ArrayList 中大量调用了这两个方法。比如:我们上面讲的扩容操作以及add(int index, E element)、toArray() 等方法中都用到了该方法!
1、System.arraycopy() 方法
// 我们发现 arraycopy 是一个 native 方法,接下来我们解释一下各个参数的具体意义/*** 复制数组* @param src 源数组* @param srcPos 源数组中的起始位置* @param dest 目标数组* @param destPos 目标数组中的起始位置* @param length 要复制的数组元素的数量*/public static native void arraycopy(Object src, int srcPos,Object dest, int destPos,int length);在ArrayList使用场景:在ArrayList中的指定位置添加元素add(int index, E element)
/*** 在此列表中的指定位置插入指定的元素。*先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;*再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。*/public void add(int index, E element) {rangeCheckForAdd(index);ensureCapacityInternal(size + 1); // Increments modCount!!//arraycopy()方法实现数组自己复制自己//elementData:源数组;index:源数组中的起始位置;elementData:目标数组;index + 1:目标数组中的起始位置; size - index:要复制的数组元素的数量;System.arraycopy(elementData, index, elementData, index + 1, size - index);elementData[index] = element;size++;}我们来写一个简单示例:
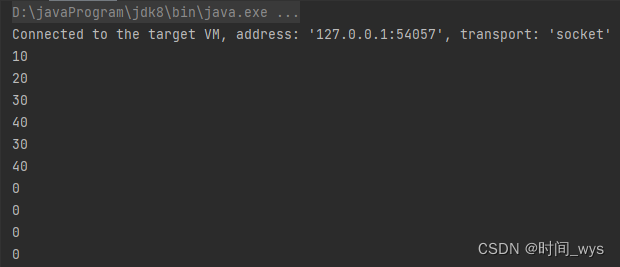
public static void main(String[] args) {int[] a = new int[10];a[0] = 10;a[1] = 20;a[2] = 30;a[3] = 40;System.arraycopy(a, 2, a, 4, 3);for (int i = 0; i < 10; i++) {System.out.println(a[i]);}}
输出结果:
2、Arrays.copyOf()方法
传入一个数组指针,和新数组长度
public static int[] copyOf(int[] original, int newLength) {// 申请一个新的数组int[] copy = new int[newLength];// 调用System.arraycopy,将源数组中的数据进行拷贝,并返回新的数组System.arraycopy(original, 0, copy, 0,Math.min(original.length, newLength));return copy;}在ArrayList中的使用场景:
/**以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素); 返回的数组的运行时类型是指定数组的运行时类型。*/public Object[] toArray() {//elementData:要复制的数组;size:要复制的长度return Arrays.copyOf(elementData, size);}个人觉得使用 Arrays.copyOf()方法主要是为了给原有数组扩容,我么来个例子:
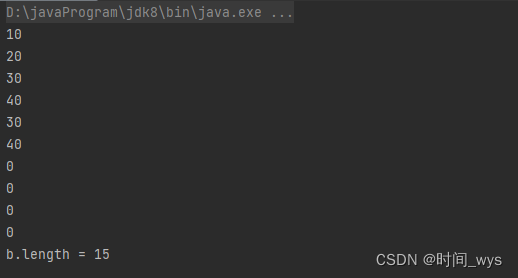
public static void main(String[] args) {int[] a = new int[10];a[0] = 10;a[1] = 20;a[2] = 30;a[3] = 40;System.arraycopy(a, 2, a, 4, 3);for (int i = 0; i < 10; i++) {System.out.println(a[i]);}int[] b = Arrays.copyOf(a, 15);System.out.println("b.length = " + b.length);}
输出结果:
两者联系:
看两者源代码可以发现 Arrays.copyOf()内部实际调用了 System.arraycopy() 方法
两者区别:
System.arraycopy() 需要目标数组,将原数组拷贝到你自己定义的数组里或者原数组,而且可以选择拷贝的起点和长度以及放入新数组中的位置 Arrays.copyOf() 是系统自动在内部新建一个数组,并返回该数组。






经典牛顿法的收敛性分析)












——树Tree 二叉树binary tree 二叉查找树 AVL树 树的遍历)