雷锋网 AI 科技评论按:亚太地区知识发现与数据挖掘国际会议(Pacific Asia Knowledge Discovery and Data Mining,PAKDD)是亚太地区数据挖掘领域的顶级国际会议,旨在为数据挖掘相关领域的研究者和从业者提供一个可自由 分享经验的国际化论坛,该会议在全球数据挖掘领域享有盛誉,一直受到业内各国科学家的高度重视和广泛认可。4 月 15 日至 17 日,第 23 届 PAKDD 2019 在澳门隆重举行,雷锋网(公众号:雷锋网) AI 科技评论前往现场为大家带来报道。
15 日的 PAKDD 2019 开幕式上,南京大学周志华教授的精彩致辞拉开了本次大会的序幕。他提到,今年 PAKDD 在澳门举办承载着两项非凡的意义:一是今年恰逢澳门回归中国 20 周年,这次会议能够让来自世界各国的领域研究者们见证澳门回归中国 20 年以来的发展;二是目前中国在大力推进以深圳、广州、香港以及澳门为中心的粤港澳大湾区建设,在之前的 2001 年以及 2011 年,PAKDD 曾先后选址香港、深圳召开,因此今年选址澳门召开,不仅对于澳门来说意义重大,也是对于粤港澳大湾区中心建设的一种呼应。

PAKDD 2019 整场大会包括 4 场重磅演讲( 3 场 Keynote 演讲+ 1 场 PAKDD 2018 最具影响力论文展示)、20 场 Oral Sessions、5 场 Workshops 及 6 场 Tutorials。下面就让我们盘点一下本次大会需要关注的重点内容。
论文收录情况
今年大会共收到投递论文 567 篇,最终收录论文 137 篇,录用率 24.1%。包括 55 位 Senior PC 及 379 位 PC 参与了审稿流程。

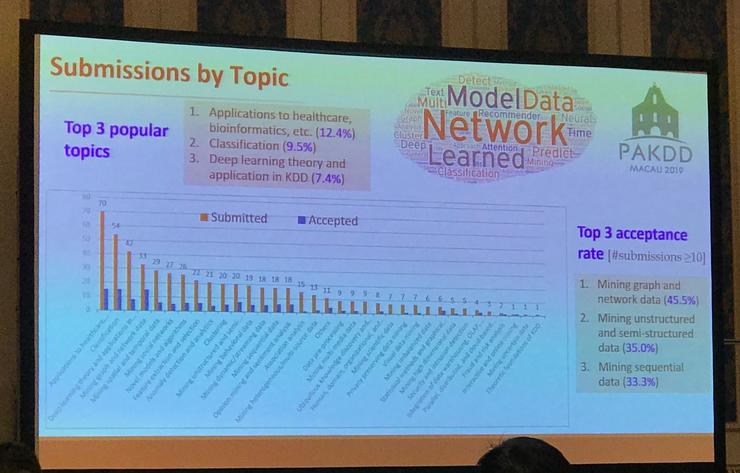
在论文主题上,排在前三的分别为医疗和生物信息学领域的应用(12.4%)、分类(9.5%)以及数据挖掘领域中的深度学习理论和应用(7.4%)。而收录率排在前三的论文主题则分别为网络和图数据挖掘(45.5%)、非结构性和半结构性数据挖掘(35.0%)以及序列数据挖掘(33.3%)。
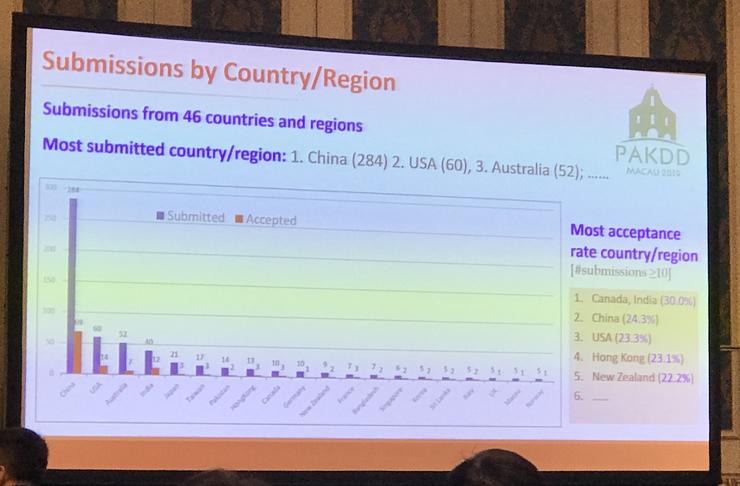
在论文的国家/地区分布上,今年大会收到了来自 46 个国家或地区的的论文投稿,其中排在前三的国家/地区是中国、美国和澳大利亚,分别为 284 篇、60 篇以及 52 篇。而论文收录率最高的国家/地区则是加拿大和印度,收录率都为 30%;其后是中国、美国、中国香港以及新西兰,收录率分别为 24.3%、23.3%、23.1% 以及 22.2%。
4 场重磅演讲
Keynote 演讲
大会首日,普渡大学副教授 Jennifer Neville 带来了主题为《Towards Relational AI -- the good, the bad, and the ugly of learning over networks 》的演讲。

她指出,关系模型通过超越对于更多传统机器学习方法的假设,现在能够成功利用在实体之间关系中常常观察到的附加信息。具体来说,尤其当个体数据稀疏时,网络模型能够使用关系信息来改善关于用户兴趣、行为和交互的预测。然而需要权衡的是,由于目前存在的算法和统计等方面的挑战,大规模网络数据的异构性、部分可观察性和相互依赖性导致研究者难以开发有效且无偏的方法。
在本次演讲中,Jennifer Neville重点讨论了这些问题,并介绍了用于大规模社交和信息网络中的关系学习的几种通用方法,此外,她还分享了关系模型对于隐私、社区两级分化以及错误信息传播的潜在影响,
作为本次大会的第二位 Keynote 演讲者,罗格斯大学大学终身教授、百度人才智库主任熊辉教授在大会第二日带来了主题为《Talent Analytics: Prospects and Opportunities》的演讲。他主要从大数据在人才管理的应用层面展开本次演讲。

他表示,大数据趋势现在已步入人才管理领域,而规模人力资源(HR)数据的可用性则能够为企业领导者提供了了解人才行为并产生有用的人才知识的好机会,从而为工作中的实时决策和有效的人员管理提供智能化协助。
对此,他也向现场嘉宾介绍了为智能人力资源管理开发的一套强大的创新大数据技术,并进行了招聘、绩效评估、人才储备和发展、工作匹配、团队管理、领导力发展和组织文化等方面的详尽分析。 与此同时,,他还现场演示了如何将人才分析应用于市场趋势分析和金融投资等其他业务应用场景中。
大会最后一天,大会迎来了罗维拉·维尔吉利大学名誉教授 Josep Domingo-Ferrer 的演讲,他的演讲主题为《Empowering Subjects, Users and Controllers when Anonymizing Big Data for Knowledge Discovery and Data Mining 》。

大数据在尤其是与人类行为和交互相关的模式、趋势和关联性分析中的应用日益增多。但是,随着《欧洲通用数据保护条例》(GDPR)这一条例逐渐成为现实全球数据的保护标准,个人可识别信息(PII)的任何期望用途都必须进行明确规定且需由数据主体明确许可,除此之外,PII 还不能进行二次使用。因此,用于 PII 的探索性数据几乎无法符合 GDPR 标准。
而使用匿名数据集来代替PII则是一种不错的方法,这是因为匿名数据不属于 GDPR 的范围。然而这一方法也存在其问题,即基于统计公开控制和隐私模型的匿名化技术在使用小数据时间的算法和假设时,必须进行彻底修改、更新甚至需要进行替换来处理大数据。具体包括数据主体如何能够控制它的数据以及如何实现在大量数据收集器、控制器和处理器中的匿名;是否可以合并匿名数据集从而获取大数据集;当前的隐私模型是否能够共享基本规则从而将匿名数据升级为大数据;是否存在可保障所有隐私模型的通用或几乎通用的匿名方法等问题。
在他的这次主题演讲,他不仅介绍了这些问题的当前现状,还分享了该领域未来研究工作方向:一方面,他认为该领域应该致力于改善大数据的匿名技术,从而让数据主体、用户以及控制者都能够将这项技术用起来;另一方面,他也呼吁研究者加强对非结构性或非文本数据的匿名研究等。
PAKDD 2018 最具影响力论文展示
除了三场 Keynote 演讲,PAKDD 2018「最有影响力论文奖 」(Most Influential Paper Award)获奖论文《Support Vector Machine Classifier》的展示也是现场参会者关注的一大焦点。该论文发表于 PAKDD 2008,在十年时间的积淀和考验中,最终拿下 PAKDD 2018「最有影响力论文奖 」,它的作者为刘秋阁、何清、史忠植这三位来自中国科学院的老师。作者之一何清教授带来了本次的精彩论文展示。
与此前利用内核来评估特征空间中数据点的点积 SVM 算法不同,在本论文中,数据点由单个隐藏层前馈网络(SLFN)显式映射到特征空间,同时,它的输入权重是随机生成的。 从理论上讲,这种公式可以解释为正则化网络(RN)的一种特殊形式,它倾向于提供比 SLFNs - 极限学习机(ELM)算法更好的泛化性能,并最终得出一种极其简单和计算快速的非线性 SVM 算法。该算法只需要对一个潜在的、顺序与训练数据集大小无关的小矩阵执行反转。 实验结果表明,本论文所提出的极限 SVM 所产生的泛化性能,基本上都要比 ELM 所产生的更好,并且其运行速度也比其他非线性 SVM 算法快得多。
重要奖项
「卓越贡献奖」(Distinguished Contributions Award)
今年「卓越贡献奖」这一重磅奖项颁给了新加坡管理大学的 Ee-Peng Lim 教授。

「卓越贡献奖」是 PAKDD 于 2005 年创立的具有终身成就奖性质的奖项,旨在表彰亚太地区数据挖掘领域有长期卓越贡献的学者,每年仅奖给一人(其中有两年空缺)。
曾经获得该奖项的华人学者包括:
周志华(2016 年):南京大学教授,计算机系主任,南京大学人工智能学院院长,欧洲科学院外籍院士,ACM、AAAS、AAAI)、IEEE、IAPR、IET/IEE 等学会的会士。
刘欢(2012 年):美国亚利桑那州立大学计算机科学与工程、信息学与决策系统工程系教授,IEEE Fellow 以及 ACM Fellow。
Hongjun Lu(2005 年):生前曾任香港科技大学教授,博士毕业于美国威斯康辛大学麦迪逊分校。
「青年成就奖」(Early Career Award)
今年获得「青年成就奖」的是新加坡管理大学的 Feida Zhu 教授。

「青年成就奖」基于青年学者博士毕业后的前 10 年时间的研究工作进行评选,旨在勉励为亚太地区数据挖掘做出优秀成就的青年学者,每年仅授予一名获奖者。
曾经获得该奖项的华人学者包括:
俞扬(2018 年):南京大学人工智能学院教授,分别于 2004 年和 2011 年获得南京大学计算机科学与技术系学士学位和博士学位。
「最有影响力论文奖 」(Most Influential Paper Award)
今年的「最有影响力论文奖 」授予了《On Link Privacy in Randomizing Social Network》这篇发表于 PAKDD 2009 上的论文,论文作者为西北工业大学殷小玮教授和美国北卡罗来纳大学夏洛特分校 Xintao Wu 教授。

「最具影响力论文奖 」面向 10 年前在 PAKDD上发表的论文,旨在表彰过去 10 年间最具影响力的论文。该奖项采用 Google 学术选取出候选论文,之后由该奖项的委员会审核并衡量各篇论文的引用质量。,其中一项重要标准是:论文必须提出了能够改变人类思维方式的新颖而重大的想法。
曾经第一作者为华人获得该奖项的论文包括:
《Support Vector Machine Classifier.》(2018 年),作者为:刘秋阁(中国科学院),何清(中国科学院),史忠植 (中国科学院)。
《Enhancing Effectiveness of Outlier Detections for Low Density Patterns》(2012 年),作者为:唐杰(清华大学),Zhixiang Chen(普渡大学),Ada Wai-Chee Fu(香港中文大学),David Wai-Lok Cheung(香港大学)。
作为 PAKDD 的重要奖项, 今年「 最佳论文奖」、「 最佳学生论文奖」、「最佳应用论文奖 」三项最佳论文奖的颁布也备受关注。
「 最佳论文奖」(Best Paper Award)
今年的「 最佳论文奖」颁给了香港科技大学张颖华、张宇在杨强教授指导下完成的论文《Parameter Transfer Unit for Deep Neural Networks》。

「 最佳学生论文奖」(Best Student Paper Award)
本次获得的论文是由南京大学的 Heng-Yi Li 和 Ming Li 在周志华教授指导下共同完成的《Towards one reusable model for various software defect mining tasks》。

「最佳应用论文奖 」( Best Application Paper Award)
「最佳应用论文奖 」则由 Jianfei Zhang、 Shengrui Wang、Lifei Chen、Gongde Guo、Rongbo Chen 以及 Alain Vanasse 合作完成的论文《Time-dependent Survival Neural Network for Remaining Useful Life Prediction》摘得。

另外于大会最后一天公布获奖结果的 PAKDD 2019 第 4 届自动机器学习挑战赛(AutoML Challenge)也同样值得关注。
自动机器学习挑战赛(AutoML Challenge)
PAKDD 2019 第 4 届自动机器学习挑战赛(AutoML Challenge)今年的主题是「 AutoML for Lifelong Machine Learning」,本次比赛要求参赛选手自动创建(没有任何人为干预的情况下)预测模型,并在一个终身机器学习(Lifelong Machine Learning)设置中训练和评估该模型。本次本赛共有 127 个队伍参加,最终有 31 个队伍进入决赛,据悉,本次比赛共收到 550 多个方案。
最终获胜的队伍为:
冠军:《DeepBlue AI》,罗志鹏,黄坚强,陈明健(深兰科技)
亚军:《ML Intelligence》,包梦蛟,Hui Xue,Yihuan Mao,Yujing Wang(微软亚洲研究院 & 北航)
季军:《Meta_Learners》,熊铮,蒋继研,张文鹏(清华大学)

以上为 PAKDD 2019 的所有重点内容,后续雷锋网 AI 科技评论还将前往各大国际学术顶会为大家带来现场报道,敬请关注!