Hadoop再火,火得过Spark吗?今天我们继续关于Spark的精华问答吧。
 1
1Q:影响性能的主要因素是什么?
A:网络传输开销大
硬件资源利用率低
同一资源的复用率低
2Q:优化的方向有哪些?
A:设置数据本地化,减少跨节点跨机架的网络传输开销
设置合适的存储格式,推荐orc,缩短查询时间
设置内存计算的大小和task数量,根据集群内存和磁盘大小调整
调整分区数量,提高查询性能
减少RDD的重复创建,同时尽可能复用已存在的RDD
减少使用shuffle类算子(reduceByKey,join,distinct,repartition)
选择可替代的最佳算子,reduceByKey替代groupByKey,mapPartitions替代map
避免数据倾斜,如map端Join,对数据深入理解的前提修改key调整reduce端的数据倾斜
提高spark最大的瓶颈-内存
3Q:优化的手段
A:调优参数虽名目多样,但最终目的是提高CPU利用率,降低带宽IO,提高缓存命中率,减少数据落盘。 (以下参数主要用于Spark Thriftserver,仅供参考)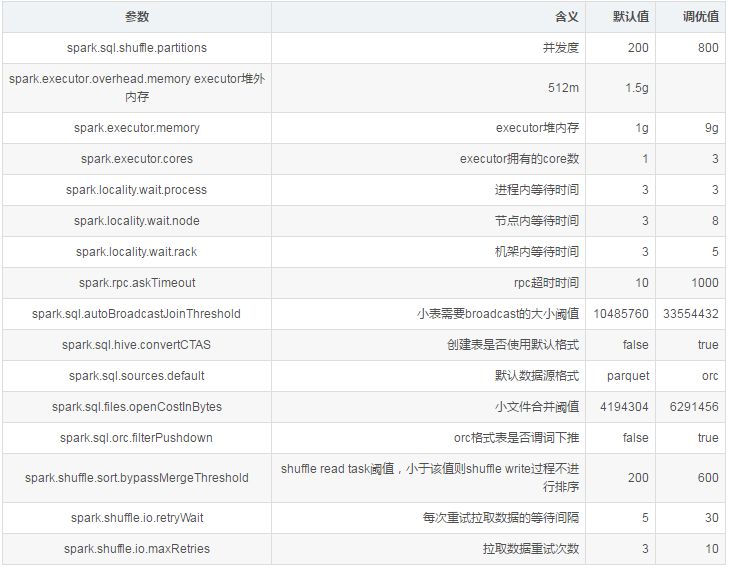
4Q:Spark生态圈介绍
A:Spark力图整合机器学习(MLib)、图算法(GraphX)、流式计算(Spark Streaming)和数据仓库(Spark SQL)等领域,通过计算引擎Spark,弹性分布式数据集(RDD),架构出一个新的大数据应用平台。
Spark生态圈以HDFS、S3、Techyon为底层存储引擎,以Yarn、Mesos和Standlone作为资源调度引擎;使用Spark,可以实现MapReduce应用;基于Spark,Spark SQL可以实现即席查询,Spark Streaming可以处理实时应用,MLib可以实现机器学习算法,GraphX可以实现图计算,SparkR可以实现复杂数学计算。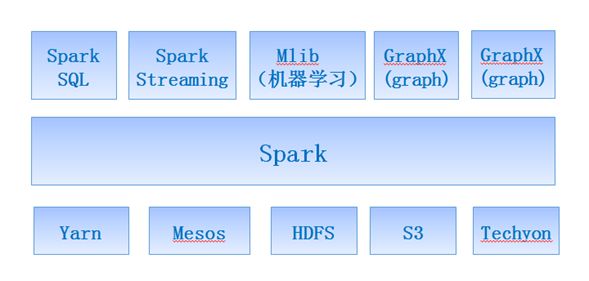
5Q:Spark SQL
A:基于HiveQL与Spark交互的API接口,将一个数据库表看作一个RDD进行操作
数据类型为DataFrame,支持结构化的数据文件,Hive表和已存在的RDD
兼容性好,支持nosql数据库
通过内存列存储技术和字节码生成技术实现空间占用量,读取吞吐率和SQL表达式的优化,查询性能高

小伙伴们冲鸭,后台留言区等着你!
关于Spark,今天你学到了什么?还有哪些不懂的?除此还对哪些话题感兴趣?快来留言区打卡啦!留言方式:打开第XX天,答:……
同时欢迎大家搜集更多问题,投稿给我们!风里雨里留言区里等你~
福利
1、扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!

2、公众号后台回复:白皮书,获取IDC最新数据白皮书整理资料!
推荐阅读:
三十四载Windows崛起之路: 苹果、可视做过微软“铺路石”
面试官:你简历中写用过docker,能说说容器和镜像的区别吗?
2019年技术盘点容器篇(二):听腾讯云讲讲踏入成熟期的容器技术 | 程序员硬核评测
C++、Python、Rust、Scala构建编译器的差异性究竟有多大?
想换行做 5G 的开发者到底该咋办?
如何在标准的机器学习流程上玩出新花样?
独家 | Vitalik Buterin:以太坊2.0之跨分片交易
滴滴章文嵩:不仅软件开源,还向学界开放数据
真香,朕在看了!