摘要: 4月17日(巴黎时间)阿里云POLARDB走出国门,亮相ICDE2018,并同步举办阿里云自有的POLARDB技术专场。在会上,阿里云进行了学术成果展示,从而推动Cloud Native DataBase成为行业标准。
4月17日(巴黎时间)阿里云POLARDB走出国门,亮相ICDE2018,并同步举办阿里云自有的POLARDB技术专场。在会上,阿里云进行了学术成果展示,从而推动Cloud Native DataBase成为行业标准。
以下为阿里云资深技术专家蔡松露演讲实录:
现在我给大家介绍一下我们的云原生数据库-POLARDB。
大家可能要问到底什么是“云原生数据库”,云原生数据库的标准是什么,我们是如何定义的以及为何如此定义?现在,我们先把这些问题放一边,我们稍后回答。
现在我们看一下一个云原生的数据库大概是什么样子,门槛是什么,特性是什么,首先,云原生数据库必须有优越的性能,有百万级别的QPS;其次,必须有超大规模的存储,可达到100TB的存储空间;在云上0宕机能力也是非常重要的;最后一个也是最重要的,云是一个生态系统,数据库必须兼容开源生态。
云原生数据库就像一辆跑车,一辆跑车可能有很多特性,比如外观、速度,但是一个有这样外观和速度的车不一定是跑车。所以回到我们的问题,云原生数据库的标准是什么,在回答这个问题之前,我们看一下数据库的发展历史。
我从4个维度来看一下数据库的发展历史,首先,从数据规模上来看,我们生活在一个数据大爆炸的时代;其次,某些数据库理论发生了演变,尤其是CAP理论,我们在算法理论上也有所突破;第三,用户和应用场景也在发生变化;第四,基础设施也在从传统IDC迁移到云上。
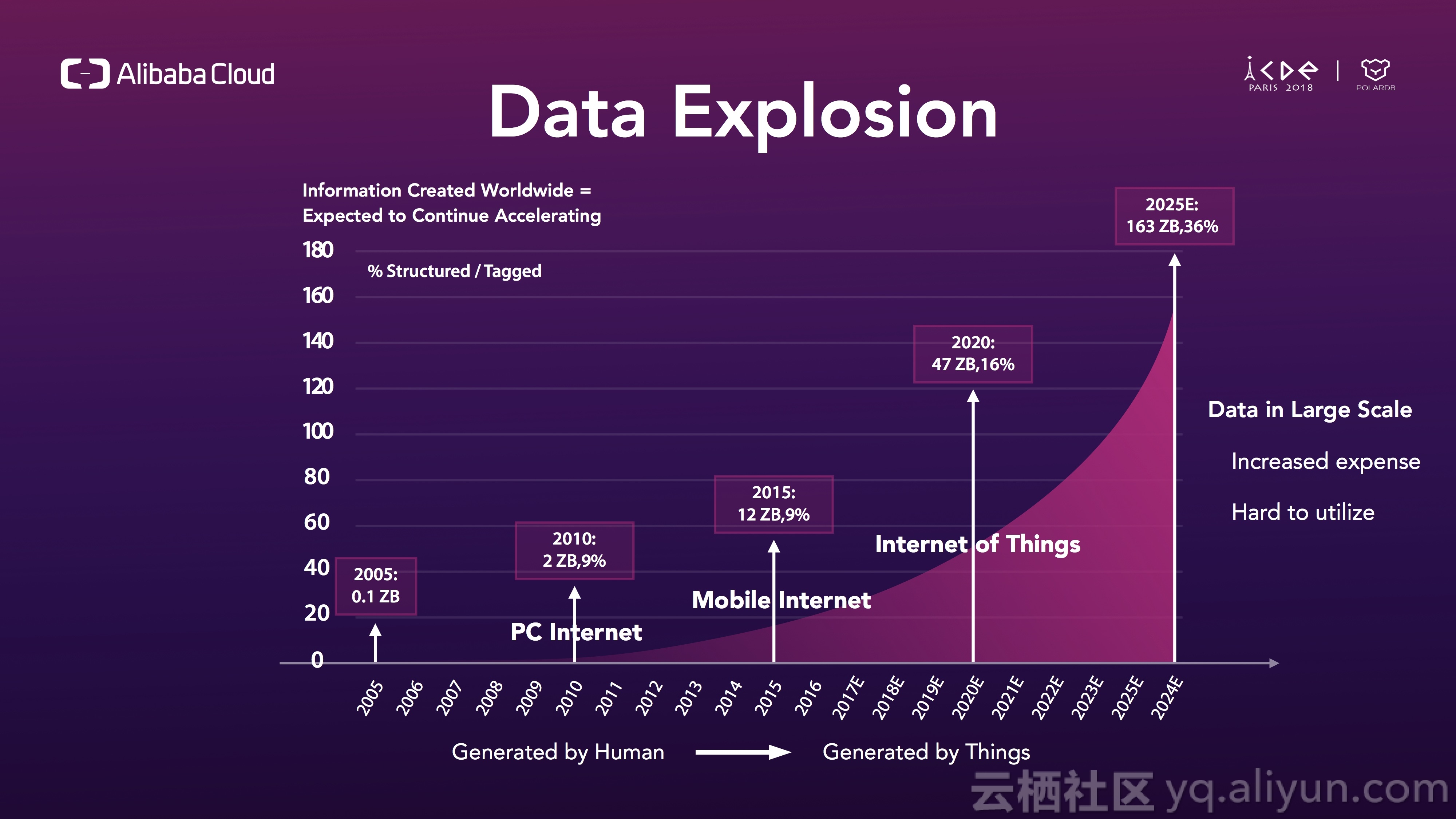
为什么会有数据大爆炸呢?数据是如何爆炸的呢?这是我引用的互联网女王米克尔的报告,你可以看到,互联网历史可以整体分为三个阶段,第一阶段我们称之为PC互联网,数据主要由PC产生,第二个阶段可以称之为移动互联网,数据主要由智能手机产生,第三个阶段是IoT,从现在开始,几乎所有的数据由物联网设备产生,可能是你的手表、冰箱、家里的电灯和汽车,可能是任何设备。
随着数据大爆炸,也带了很多挑战,大规模的数据意味着用于存储和分析数据的成本也大幅上升,搬运和分析数据也变得困难,总之,数据很难被利用。
最近这些年分布式系统的一些理论也有了重大变化,CAP就是其中之一,CAP理论在2000年引入,在这个理论中,C代表一致性,A代表可用性,P代表分区容错性,这个理论的核心观点是在P发生时C和A不可能同时被满足,CAP是一个伟大的理论,但是对CAP理论也存在很多误解,其中一个误解就是C和A是互斥的,所以有些系统选择放弃其中一个来满足另一个,比如很多NoSQL数据库,但是实际上,C和A的关系不是0和1的关系,而是100%和99%的关系。
现在我们也可以把P问题建模成A问题,P问题主要由网卡、交换机、错误的路由配置等故障引起,我们考虑一下这样一个例子,一个节点因为网卡错误而被网络分区,到这个节点的请求会失败,如果我们能够将这个节点自动剔除,那么请求会重试并且会被发送到一个健康的节点,事实上,当一个节点宕机的时候我们也采用同样的处理方式,所以基本上,P和A问题在某些情况下可以看做是一类问题。
我们如何把失败的节点自动剔除并且能够同时保障数据一致性呢?我们可以用PAXOS算法来达到这个目的,PAXOS能够保证一致性,而且PAXOS只需要过半数的操作成功即可,所以当有网络分区、宕机、慢节点出现时,我们可以容忍这些问题节点并做到自动剔除。如果超过半数节点被分成了若干个分区,这时我们选择一致性牺牲可用性,但是在现实世界中这种情况极少发生,所以在大多数情况下,我们可以通过将P问题建模成A问题来同时保证完整的C和A。
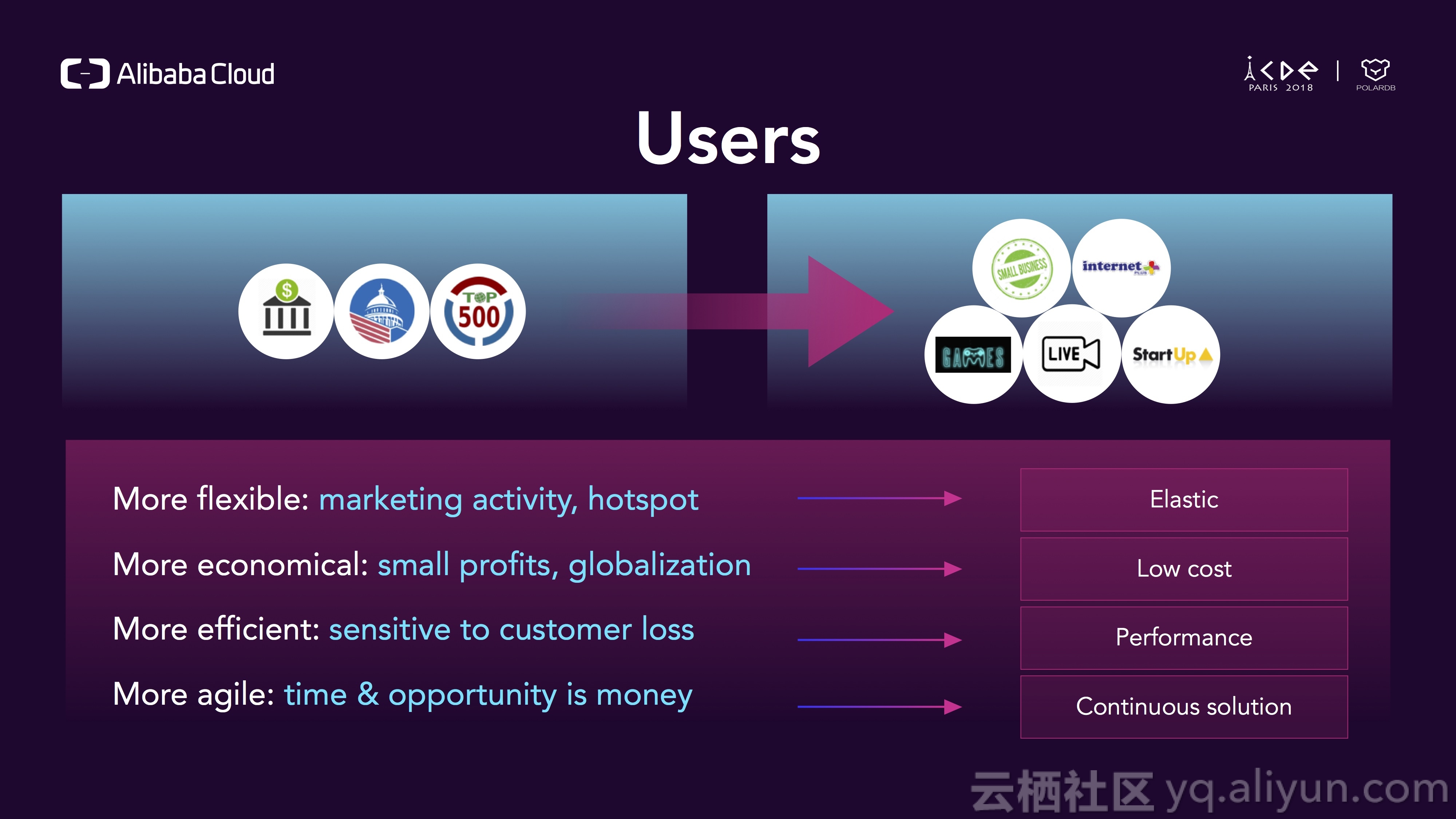
20年前,只有政府和一些巨头公司会选择数据库,现在从巨头到小微企业所有的业务都会跑在数据库上,而且对数据库的需求也在发生变化。
首先,数据库必须灵活,有时我们需要做一个市场活动,比如黑色星期五,我们不知道当天的真实流量,有时会有突发的热点信息,这时流量会有一个飙涨并且是不可预测的,我们希望数据库能够灵活地进行扩展;其次,随着全球化的发展,贸易也越来越透明,很多用户的业务规模比较小,意味着利润也很少,他们需要更经济的解决方案;目前的客户要求也比较严格并且对延迟很敏感,数据库延迟越低带给客户的损失会越小;最后,数据库必须对每一个潜在的问题做到反应迅速,并能从问题状态中快速恢复过来。
总之,目前对数据库的潜在需求是:弹性、低成本、高性能、业务永续。
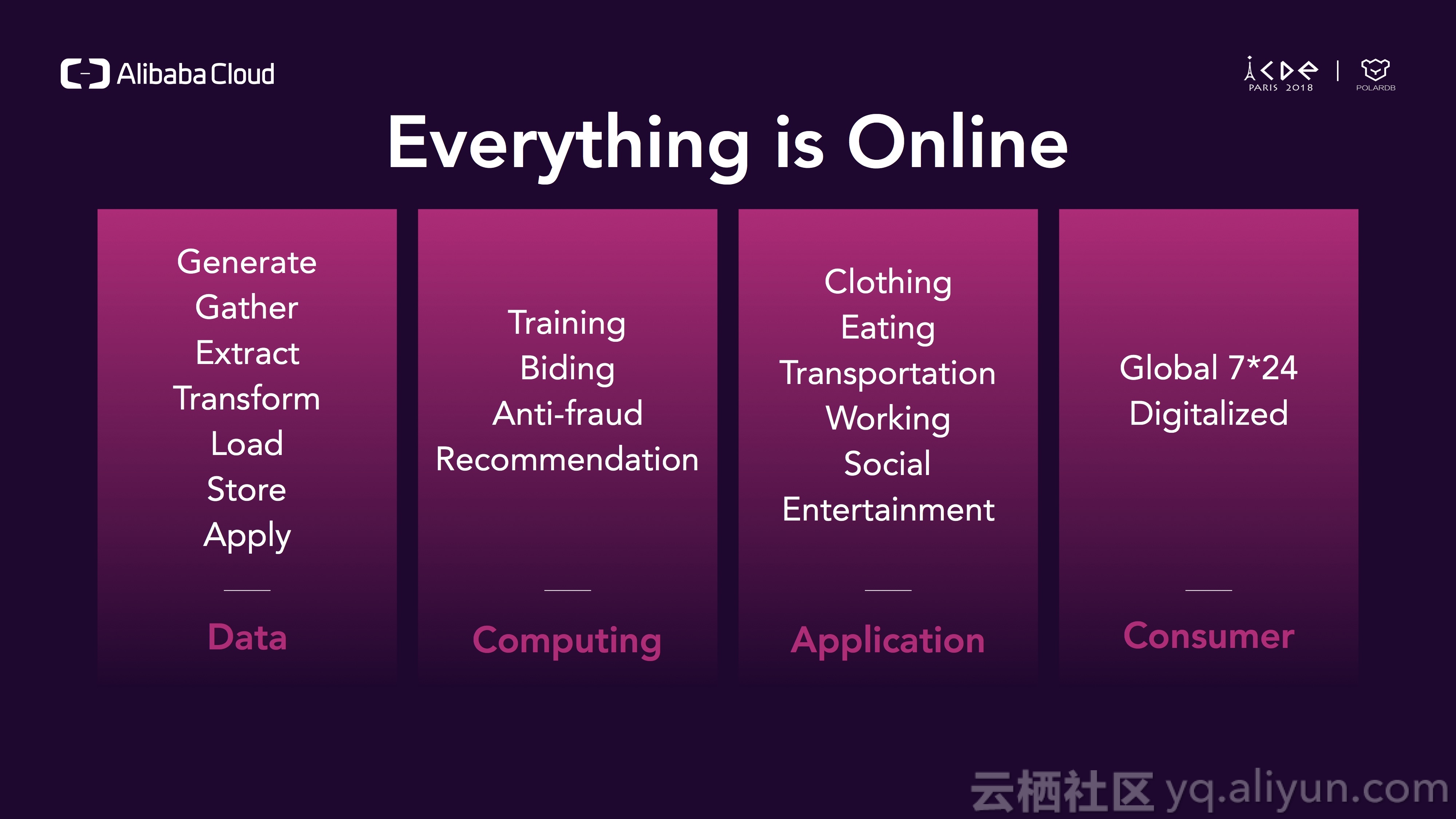
现在,所有的一切都是时刻在线的,在云时代以前,数据散落在IDC中,现在数据都位于数据湖中,数据会在线产生并且同时被应用到训练模型中,所以这些数据是在线产生、在线分析并在线应用;我们的生活现在也是时刻在线的,比如衣食住行、工作、社交、娱乐等都是可以在线解决的,你可以用一部手机足不出户就能活下来;现在你的客户也是时刻在线的,他们遍布世界各地,无论白天还是黑夜,一直在线。
在目前的中国,70%的新型企业都因数据挑战而对业务产生了影响,他们面临的问题主要有:高成本,他们负担不起商业license和专业的工程师;他们有很强的发展的意愿但是数据能力不够强;对他们来说数据备份、数据挖掘和问题排查都是非常困难的事情;他们的数据目前像孤岛一样散落分隔在多个地方,数据无法做到在线并被浪费,但是数据在持续增长爆炸,这些数据很难被存储、转移、分析并使用
根据上述演变趋势和接踵而来的数据挑战,我们认为一个云原生的数据库应该符合以下标准。
首先,一个云原生数据库不仅是一个TP数据库,也是一个AP数据库,TP和AP融合在一起,我们称之为HTAP,我们从这种架构中获益良多;其次,云原生数据库必须是serverless的,有了serverless,我们可以大幅削减成本;最后,云原生数据库必须是智能的,就像一个顾问,可以承担很多诊断和管理工作,通过这些工作我们可以提升用户体验并让用户不必再关心这些枯燥棘手的事情。
接下来我们详细阐述一下。
在HTAP中TP和AP共享一份存储,对于分析来说不存在任何数据延迟,由于不需要数据同步,我们也不必把数据从主节点同步到一个只读节点,这时数据是实时的,对于时延要求比较苛刻的应用来说非常有益;当TP和AP共享一个存储之后,至少会省去1个副本的成本,对于计算层,AP和TP通过容器来进行隔离,所以AP对TP没有任何影响,而且有了这层隔离之后,TP和AP可以轻松做到分别扩展。
有了serverless,产品规格或版本升级时可以做到0成本,计算节点会跑在一个轻量的容器中,客户端会话的生命周期比较短,所以当我们进行滚动升级时,客户端几乎感知不到任何变化;有了serverless可以轻松做到按需使用,按存储付费,计算成本也很低,并且你可以为不同的业务模型指定不同的存储策略,对于忙的业务,可以使用更多的内存和SSD,对于闲置的业务,可以把数据放到HDD盘上,这样可以大幅缩减成本。
提到智能,智能顾问会分析实例产生的如CPU/存储/内存使用率和水位线等数据给你一个SQL或索引优化建议,在外人看来智能顾问就像是一个DBA,并把用户也武装成一个专业的DBA;当数据链路上有问题发生时,由于数据链路又长又复杂,所以我们不清楚问题到底出在哪里,当我们有一个监控和诊断系统后,我们可以轻松地去诊断整个链路并迅速给出根本原因;智能顾问也能负责其他如成本控制、安全、审计等职能。
在上述若干标准和门槛的指导下,我们打造了一个全新的云原生数据库-POLARDB,我会从架构、产品设计、未来工作等几个方面全方位阐述一下POLARDB。
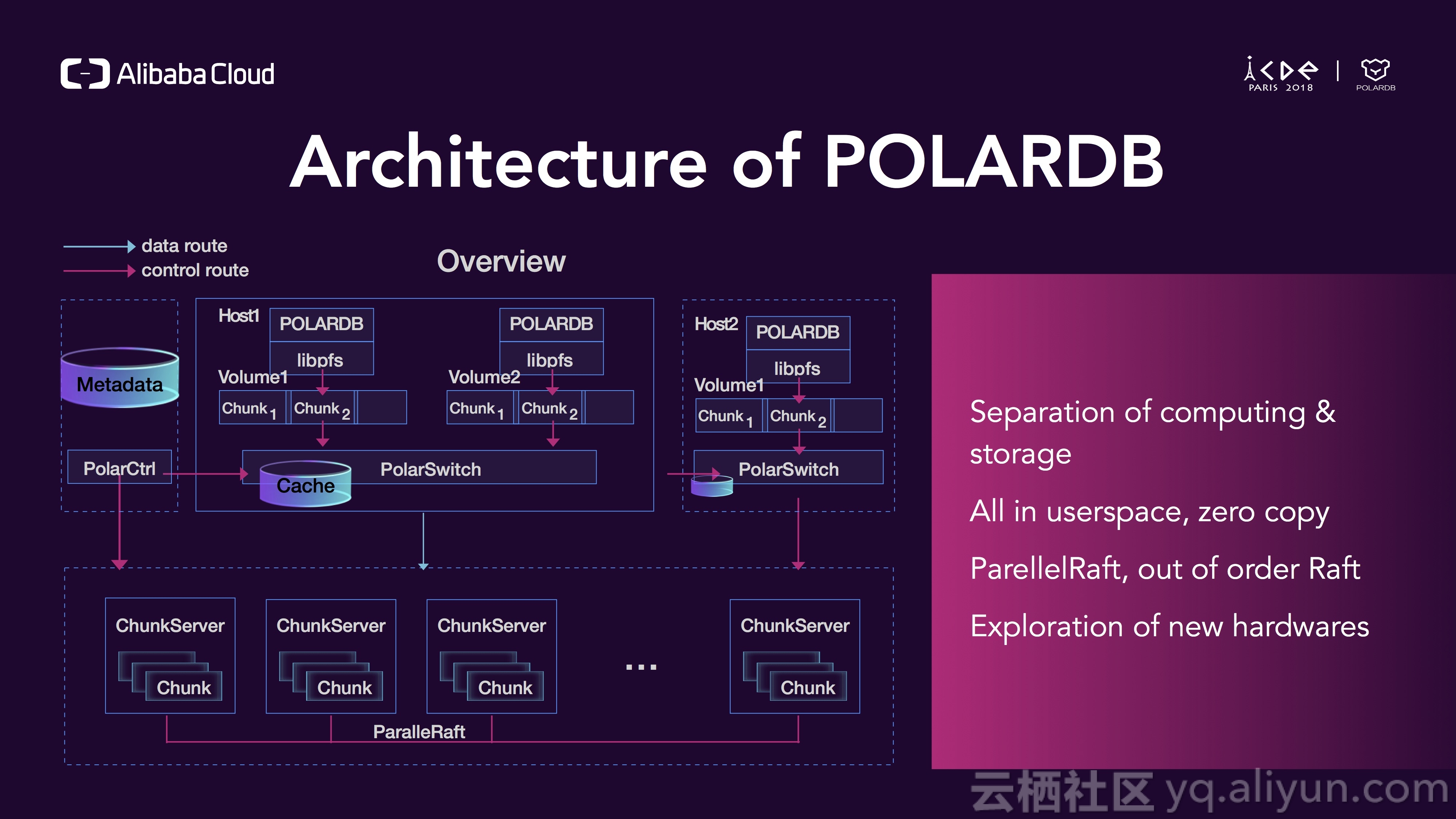
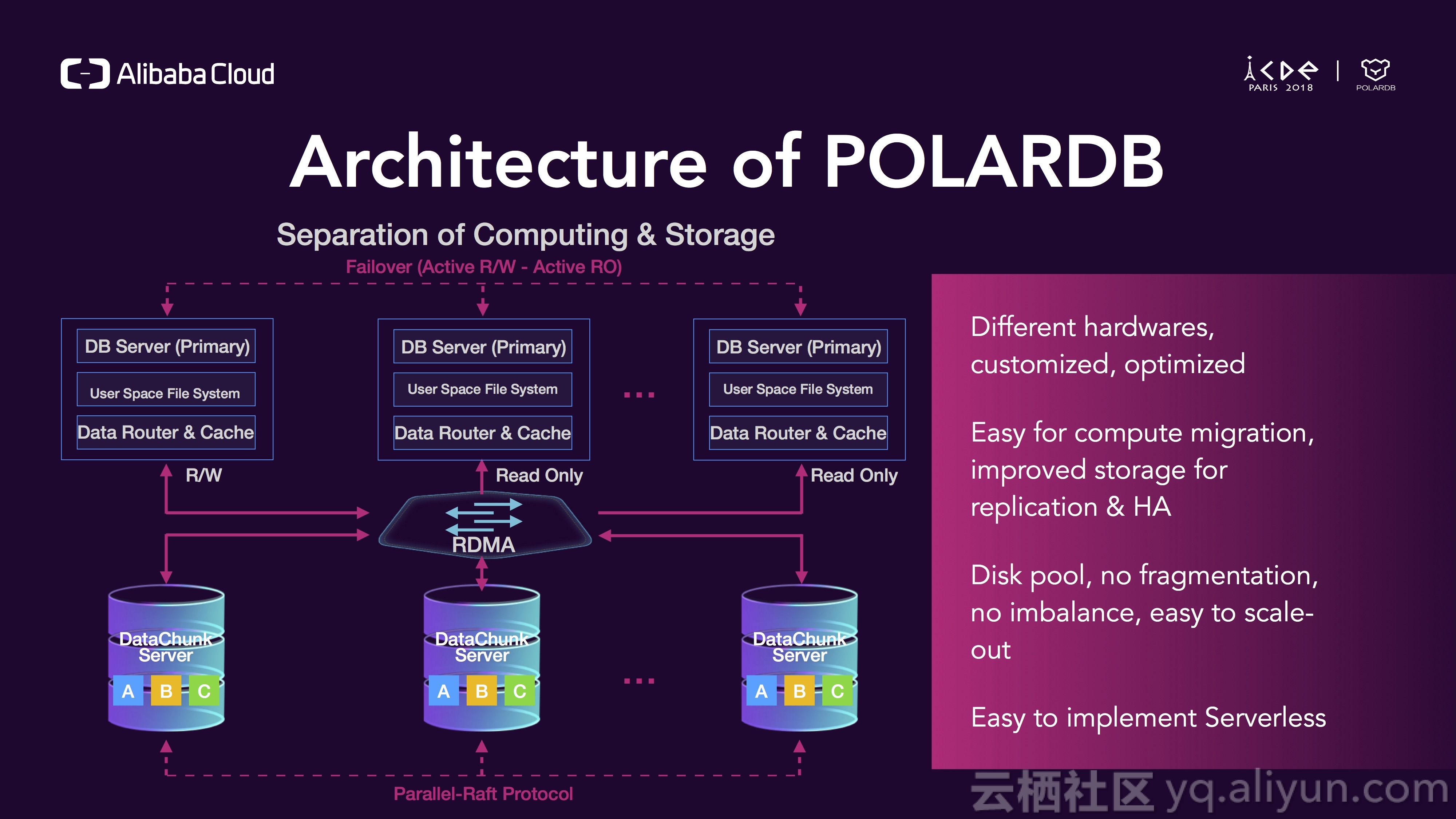
这是一个POLARDB的架构大图,上层是计算层,下层的存储层,存储和计算分离,他们中间通过RDMA高速网络相连接,所有的逻辑都运行在用户态,绕过了linux内核,在用户路径上,我们实现了0拷贝,我们同时实现了一个RAFT的变种ParellelRaft,它支持乱序提交,比传统的Raft速度要快很多;我们同时使用了大量新硬件,既可以提升性能又能降低成本,POLARDB也是面向下一代硬件而设计。
对于计算节点,只有一个写入口,R/W节点负责所有类型的请求,包括读和写请求,其他节点都是只读节点,只能处理读请求,对于存储节点,我们通过ParellelRaft算法来实现三副本一致性写。我们为何要做存储计算分离呢?首先,我们可以为存储和计算阶段选取不同类型的硬件,对于计算层,我们主要关注CPU和内存性能,对于存储层,我们主要关注低成本的存储实现,这样存储和计算节点都能做到定制化和针对性优化;分离之后计算节点是无状态的,变得易于迁移和failover,存储的复制和HA也可以得到针对性的提升;存储现在可以方便地池化,以块为单位进行管理,所以不再会有碎片问题、不均衡问题,并且易于扩展;在这种架构下,也很容易实现serverless,当你的业务比较空闲时你甚至可以不需要任何计算节点。
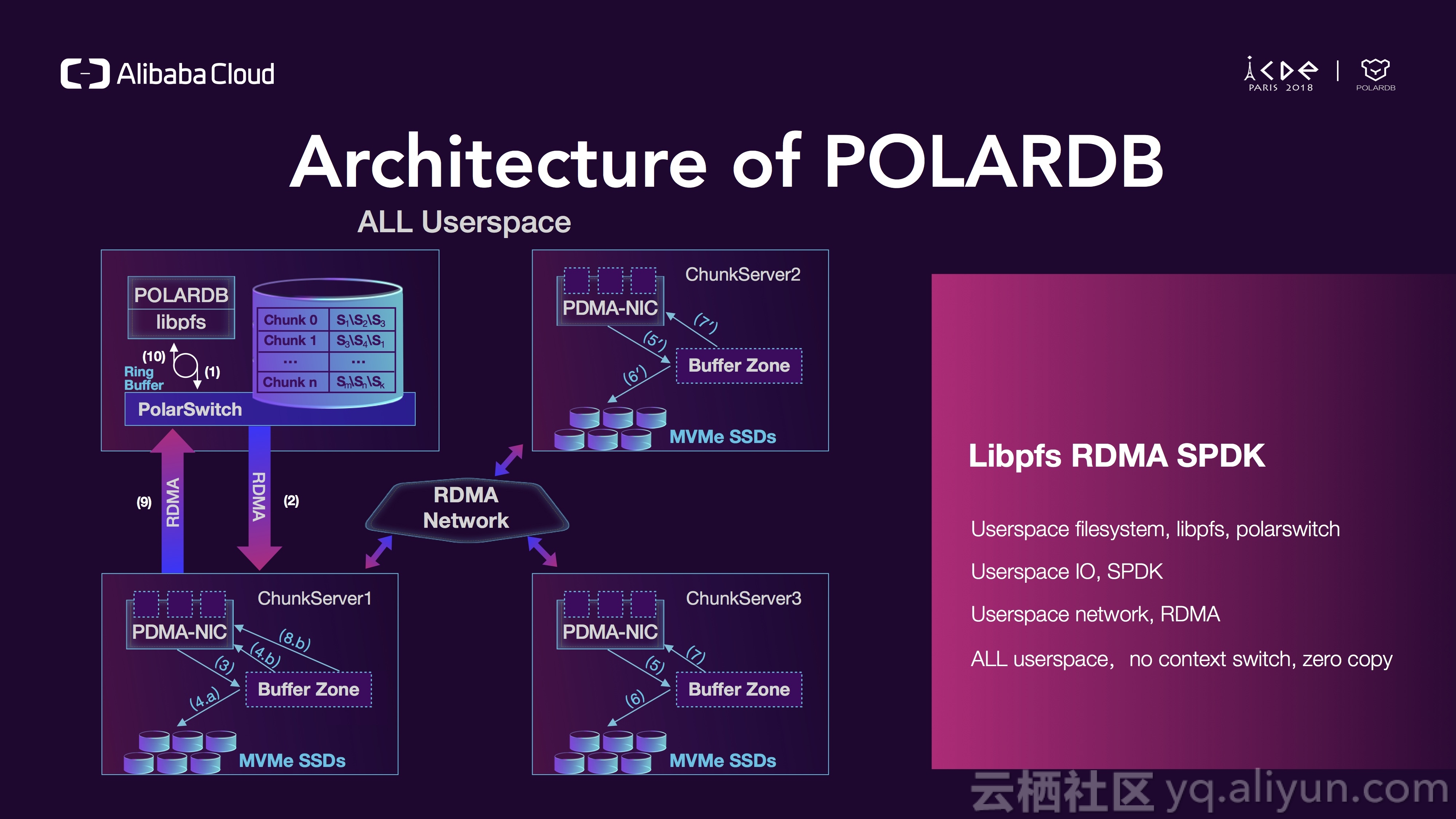
在POLARDB中,任何逻辑都跑在用户态,一个请求从数据库引擎发出,然后PFS会把它映射成一组IO请求,然后PolarSwitch会把这些请求通过RDMA发送到存储层,然后ParellelRaft leader处理这些请求并通过SPDK持久化到磁盘上,同时再通过RDMA同步两份数据到两个followers,在整个路径上没有系统调用,也就没有上下文切换,同时也没有多余的数据拷贝,没有上下文切换加0拷贝使得POLARDB成为一个极快的数据库。
这是POALRDB文件系统-PFS的详细说明,PFS具有POSIX API,对数据库引擎侵入性很低,PFS是一个静态库并被链接到数据库进程中,PFS是一个分布式文件系统,文件系统的元数据通过PAXOS算法进行同步,所以PFS允许并行读写,为了访问加速,在数据库进程中有元数据的缓存,缓存通过版本控制来进行失效操作,为了便于大家理解PFS,这是PFS和传统文件系统的一个类比。
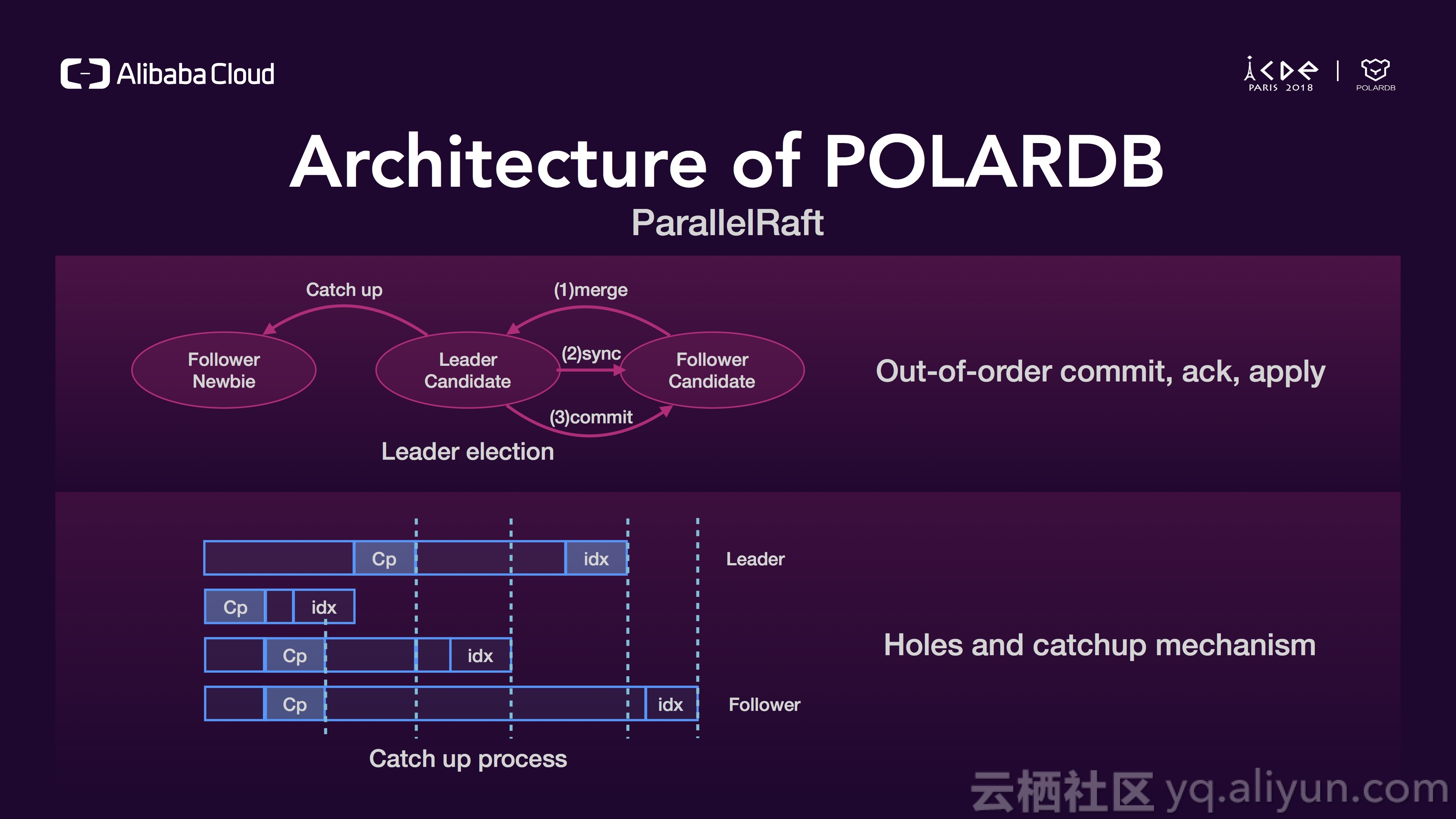
我们使用ParellelRaft来同步三份数据,ParellelRaft是Raft的变种之一,Raft不允许乱序提交和日志空洞,这些限制让Raft性能比较低、吞吐比较小,在ParellelRaft中,我们允许乱序提交、确认、和应用,事务的语义和串行化由数据库引擎层来负责,对于空洞我们有一整套完整的catch-up机制,这是一个非常复杂的过程,在VLDB 2018的论文中,我们有详细论述,这篇论文刚被接收。
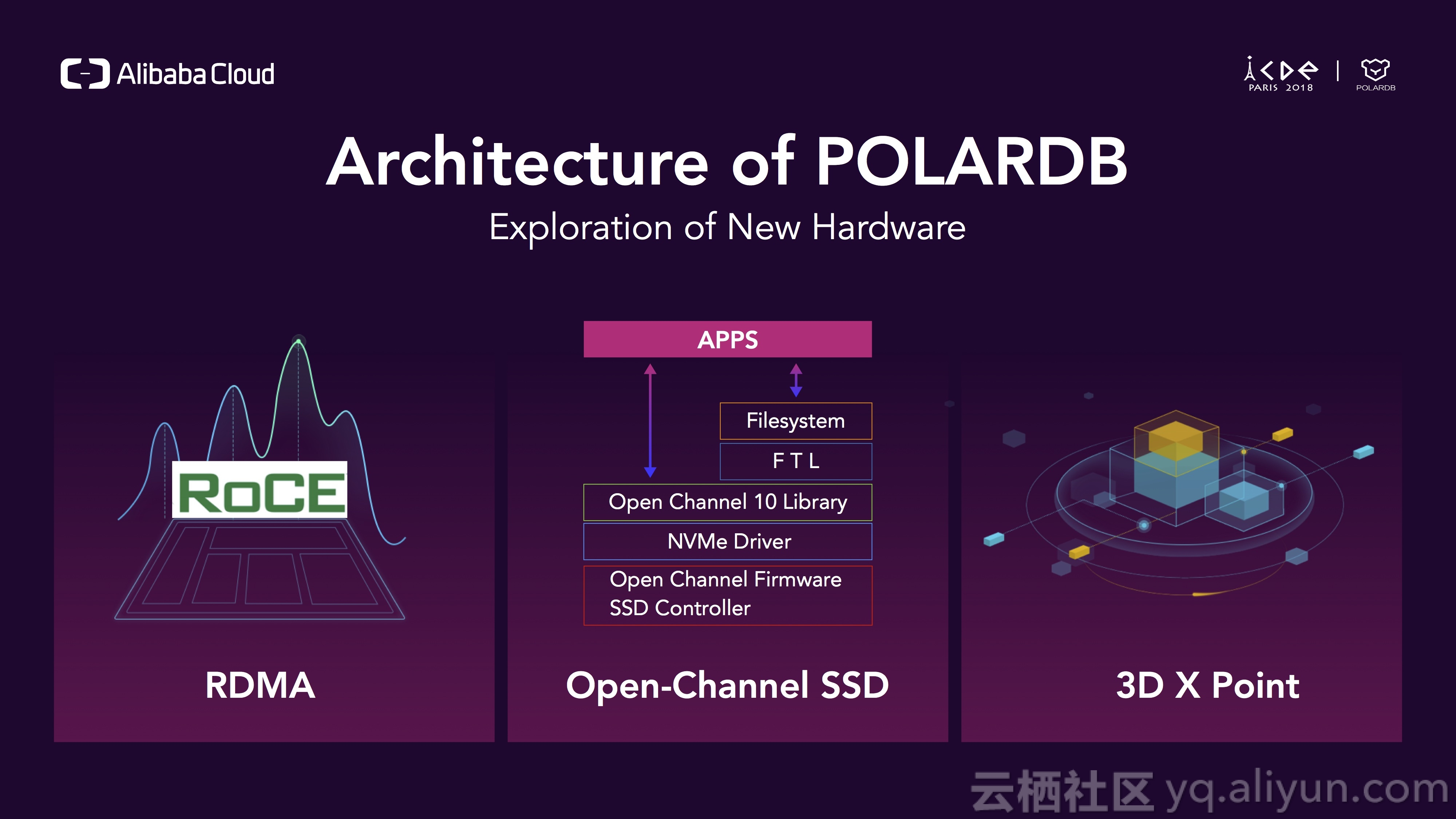
在POLARDB中,我们使用了一些新硬件并最大化利用这些硬件的能力,除了RDMA,我们还在研究open-channel来最大化SSD的价值,我们也在通过3D XPoint技术在加速存储层。
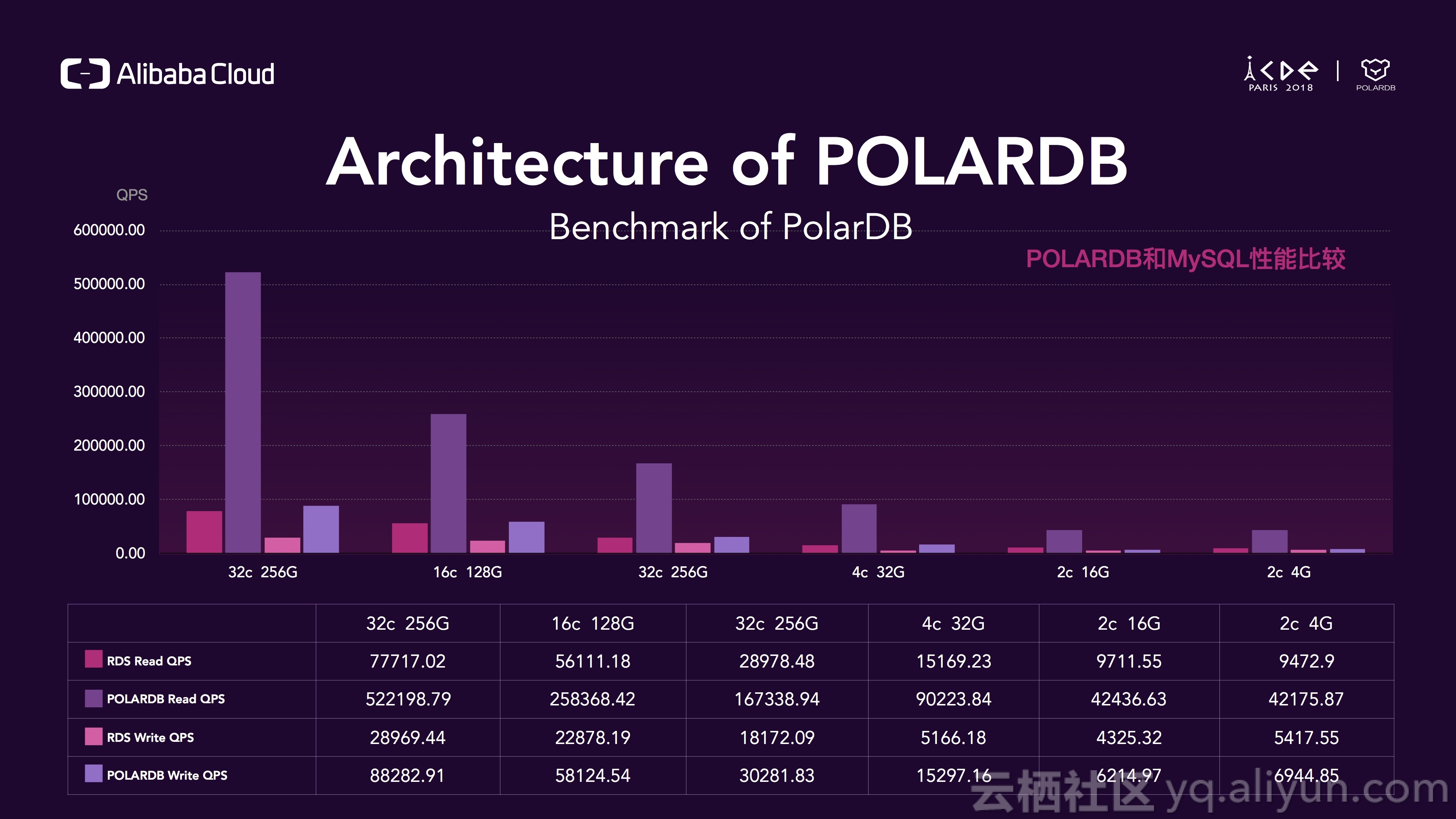
这是POLARDB和RDS的对比压测结果,我们使用sysbench来进行压测,紫色的柱子代表POLARDB,粉色的代表RDS,通过这些数字可以看出,在使用相同资源的情况下,POLARDB的平均读性能是RDS的6倍,平均写性能是RDS的3倍,所以这个提升是巨大的。
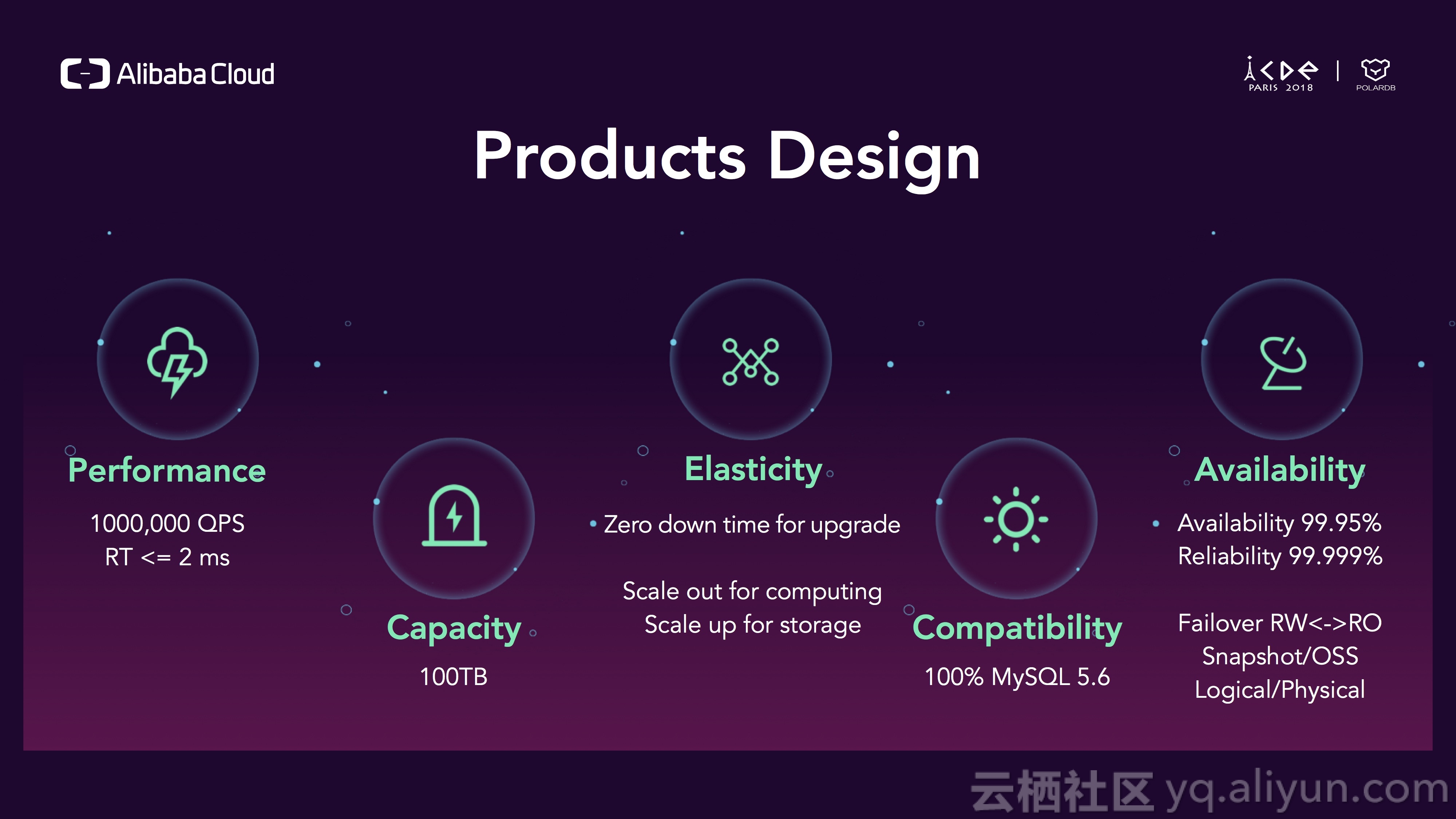
我们接下来看一下POLARDB的产品特点,性能上,很容易扩展到100W QPS,并且延迟小于2ms;存储最大支持100TB;弹性上,可以很方便做横向和纵向扩展,并且在规格升级时0宕机无干扰;对于兼容性,会100%兼容MySQL;在可用性上,当有错误发生时,我们会选择一致性牺牲可用性,所以目前我们承诺3个9的可用性,在数据可靠性上,我们承诺5个9。
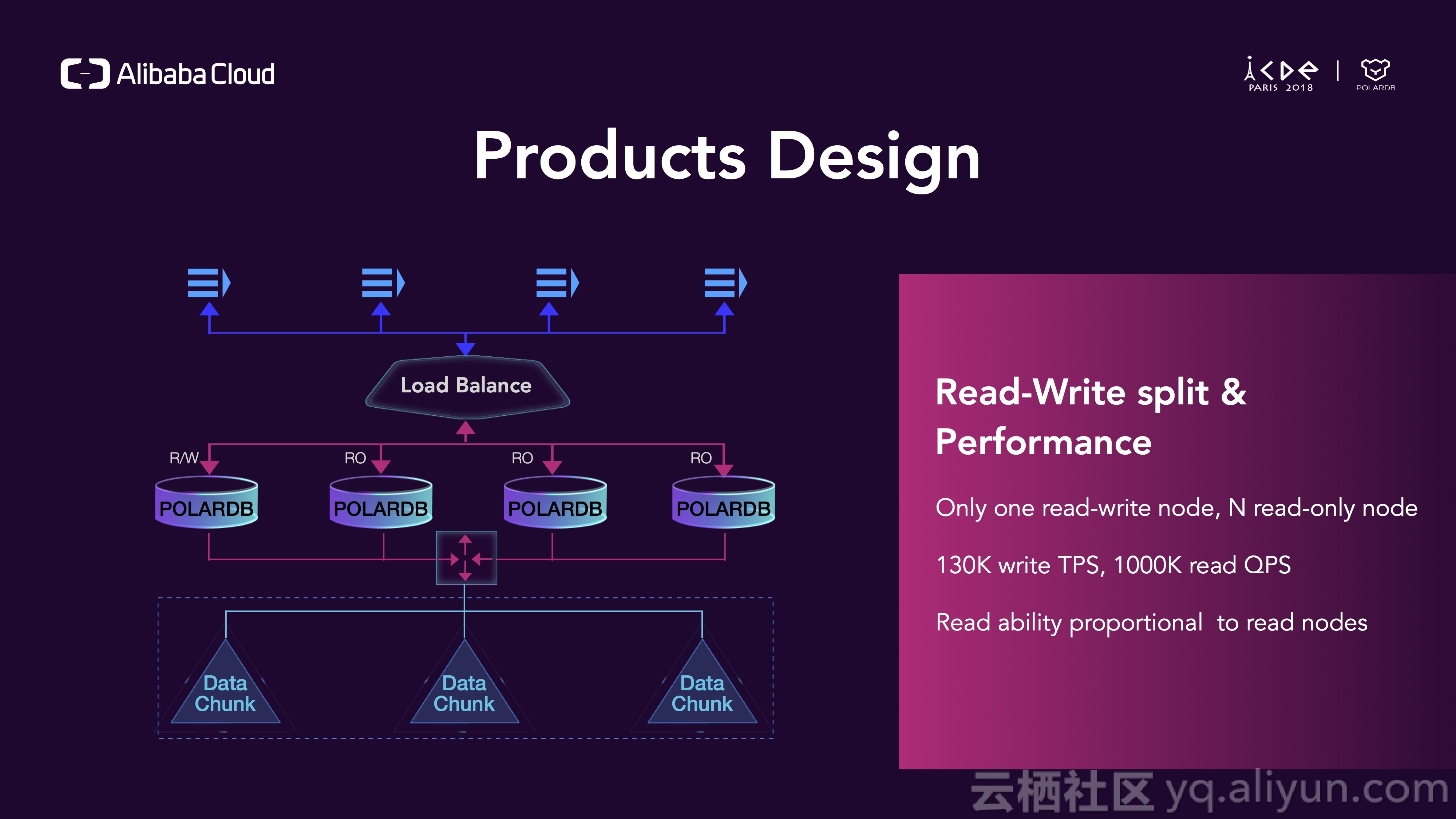
在POLARDB中,读和写被分离到不同的节点上,只有一个写节点,写节点可以处理读写请求,可以有多个只读节点,写QPS最多可达13W,读QPS可以很方便地扩展到几百万。
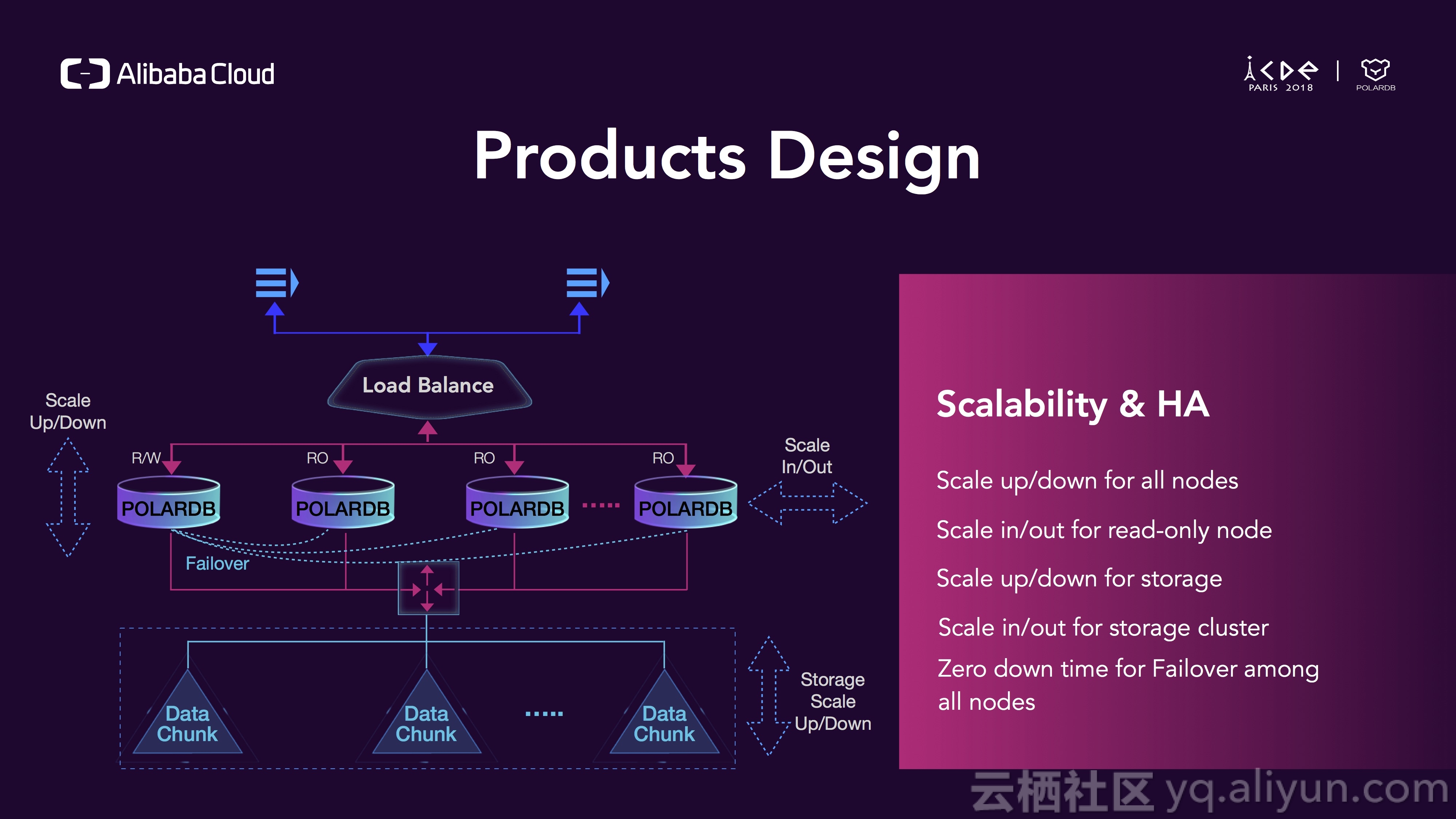
对于可扩展性,所有节点都可以做纵向扩展,只读节点可以做横向扩展,实例的存储可以做纵向扩展,存储集群可以做横向扩展,当读写节点和只读节点之间做failover时可以做到0宕机。
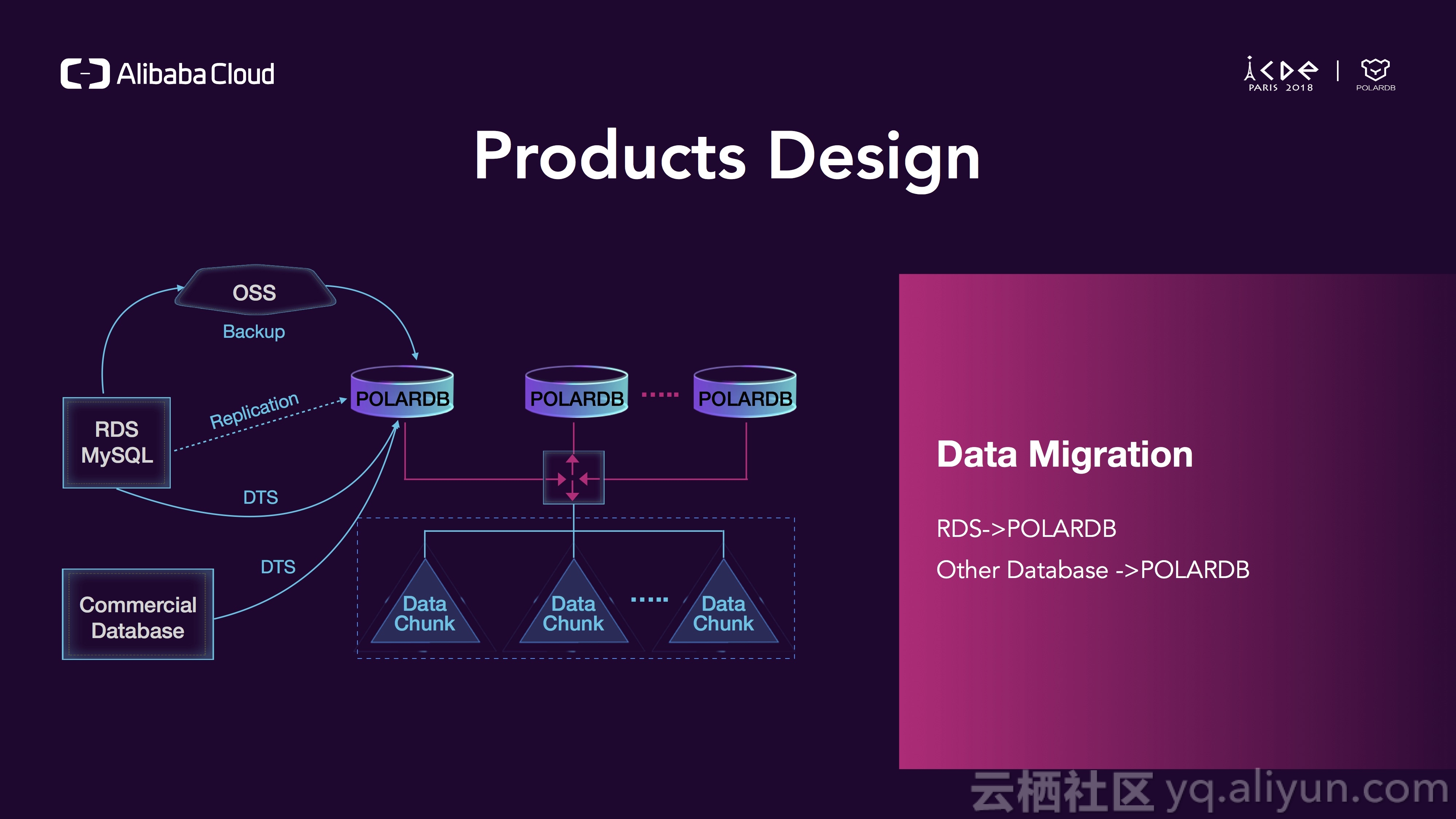
对于数据迁移,你可以通过加载一个OSS(类似AWS S3)上的备份来启动你的数据库,也可以通过将POLARDB当成RDS的slave来从RDS实时复制数据,也可以利用DTS(data transfer service数据传输服务)来从RDS和其他数据库迁移到POLARDB。
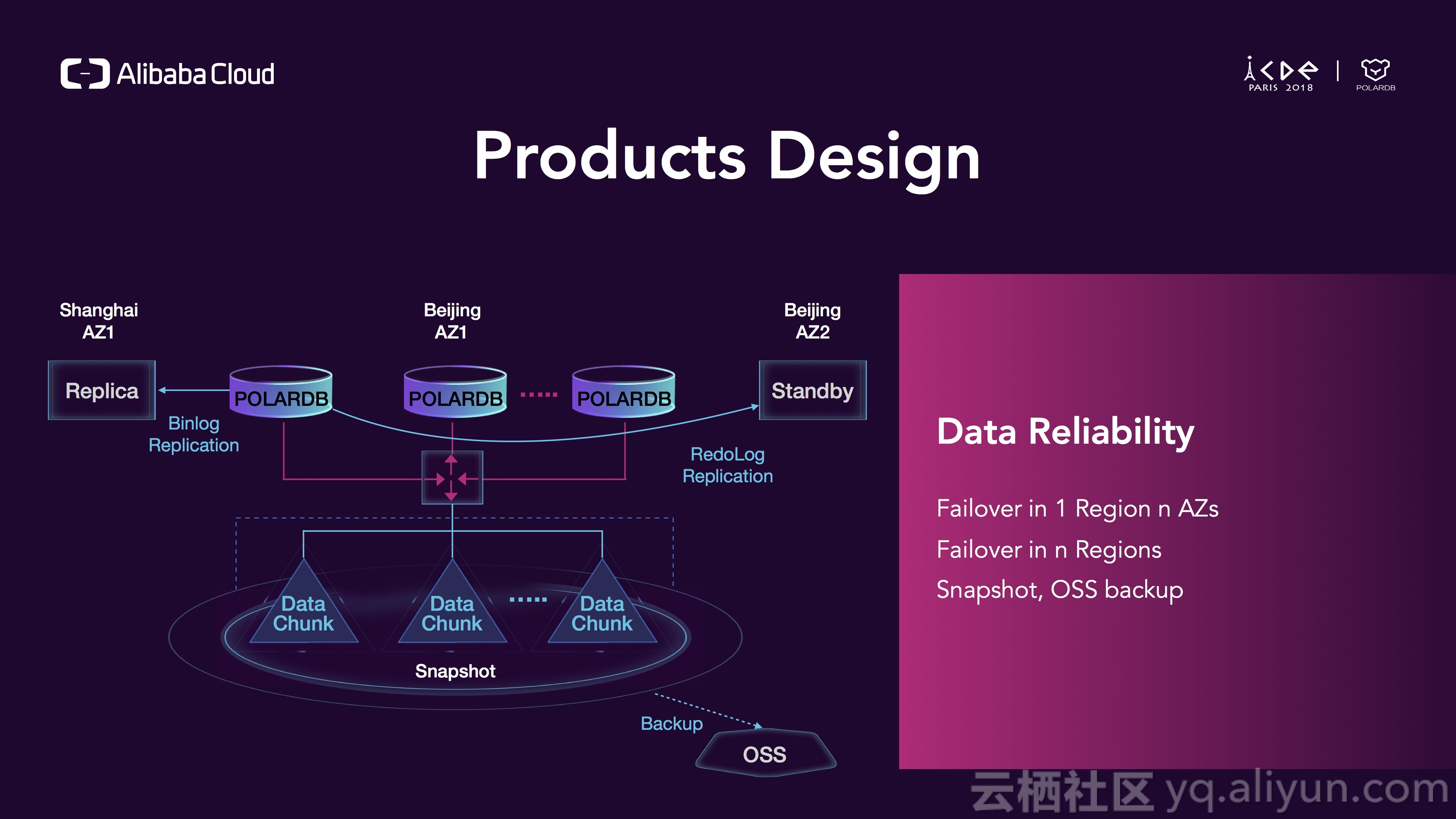
对于数据可靠性,我们可以做到1个region内可用区内多个可用区之间的failover,你可以在其他可用区启动一个standby实例并且使用redolog来进行复制,也可以在多个region之间failover,我们通常使用binlog进行复制,对于备份,我们可以秒级打出一个snapshot然后传输到OSS上。
下面是POLARDB的一些未来工作,目前POLARDB还只是个婴儿,我们仍然有大量工作需要去做,在引擎层我们将会支持多写,目前POLARDB是一个共享磁盘的架构,未来会是一个共享所有资源的架构,比如在计算层我们会引入一个集中化Cache的角色来提升我们的查询性能,我们也在移植更多的数据库到POLARDB,比如更多的MySQL版本、PostgreSQL、DocumentDB等。在存储层,我们会使用3D XPoint技术来提升IO性能,我们也会通过open-channel技术在提升SSD性能,将来我们也会将更多引擎层的逻辑进行下推,尽量减少更多的IO,让计算层更加简单。












关于学术我们的基本思想是:学术要在工程落地,工程要有学术产出,没有单纯的工程或者学术。我们团队已经向Sigmod和VLDB提交了数篇论文,最近这些论文将会出版,大家会看到更多的关于POLARDB和它的分布式存储的详细的信息,我们也正在欧洲进行招聘,我们在巴黎和德国都设有办公室。
原文链接
干货好文,请关注扫描以下二维码:


机制是什么?...)





错误的解决方法)






 - 资源监控)




:日志采集杂谈)