摘要: 提到Envoy就不得不提Service Mesh,说到Service Mesh就一定要谈及微服务了,那么我们就先放下Envoy,简单了解下微服务、Service Mesh以及Envoy在Service Mesh中处于一个什么样的角色。
背景
最近因工作原因开始了解Service Mesh与Envoy,为系统性梳理所学内容,因此沉淀了此文档,但由于所知有限,如文档中有描述不当之处,希望不吝赐教。
提到Envoy就不得不提Service Mesh,说到Service Mesh就一定要谈及微服务了,那么我们就先放下Envoy,简单了解下微服务、Service Mesh以及Envoy在Service Mesh中处于一个什么样的角色。
过去几年间,架构领域最火的方向非微服务莫属,那么微服务架构到底为我们带来了什么样的好处呢?下面通过一张图说明架构的演进,如下:

伴随着业务规模的变大,微服务的好处显而易见,例如它本身所具备的可扩展性、易维护性、故障和资源隔离性等诸多特性使得产品的生产研发效率大大提高,同时,基于微服务架构设计,研发人员可以构建出原生对于“云”具备超高友好度的系统,让产品的持续集成与发布变得更为便捷。
然而没有所谓的银弹,微服务带来很多好处的同时也引入了很多问题。在云原生模型里,一个应用可以由数百个服务组成,每个服务可能有数千个实例,每个实例的状态可能持续的发生变化,此时,服务间的通信不仅异常复杂,而且都是运行时的行为,管理好服务间通信对于保证端到端的性能与可靠性来说无疑成为重中之重。在Service Mesh没有出现之前,微服务框架之间的通讯大多采用SDK方案,但该方式短板也非常明显,例如对业务有侵入性、无法做到SDK升级对业务透明等。
基于以上种种复杂原因催生了服务间通讯层的出现,这个层即不应该与应用程序的代码耦合,又能捕获到底层环境的动态变化并作出适当的调整,避免业务出现单点故障;同时也可以让开发者只关注自身业务,将应用云化后带来的诸多问题以不侵入业务代码的方式提供给开发者。
上述所说的这个服务间通讯层就是Service Mesh(国内通常翻译为服务网格),它可以提供安全、快速、可靠的服务间通讯。如果用一句话来解释什么是Service Mesh,可以将其比作微服务间的TCP/IP层,负责服务之间的调用、限流、熔断和监控等。
读到这里大家一定仍然存在这样的疑惑,Service Mesh到底是什么呢?这是一个全新的东西吗?它的演进过程是什么样的呢?下面使用一张图来说明其演进过程,如下:
从上图可以看到最初的Service Mesh始于一个网络代理,在2016年1月业界第一个开源项目Linkerd发布,同年9 月 29 日的 SF Microservices 大会上,“Service Mesh”这个词汇第一次在公开场合被使用,随后Envoy也发布了自己的开源版本,但此时的Service Mesh更多停留在Sidecar层面,并没有清晰的Sidecar管理面,因此属于Service Mesh的第一代。此时虽然Service Mesh尚不成熟,但一个初具雏形的服务间通讯层已然出现,如下图:
随后Google联合IBM、Lyft发起了Istio项目,从架构层面明确了数据平面、控制平面,并通过集中式的控制平面概念进一步强化了Service Mesh的价值,再加上巨头背书的缘故,因此Service Mesh、Istio概念迅速火爆起来。此时已然进入到了第二代的Service Mesh,控制平面的概念及作用被大家认可并接受,而更重要的一点是至此已经形成了一个完整意义上的SDN服务通讯层。此时的Service Mesh架构如下图:
至此Service Mesh的背景信息基本介绍完毕,接下来开始进入正题说说Envoy相关的内容。其在完整的Service Mesh体系中处于一个什么位置呢?继续看图:


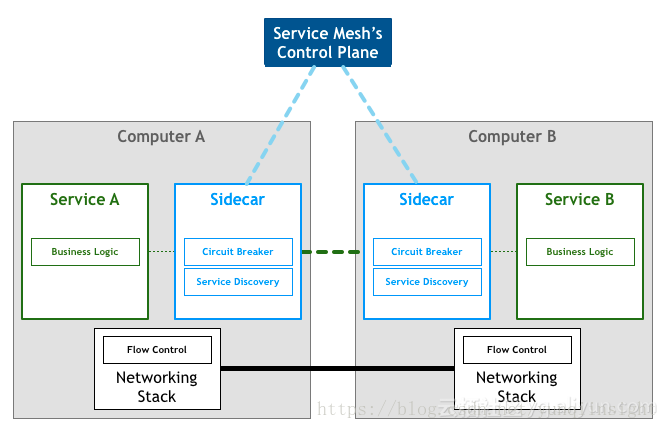
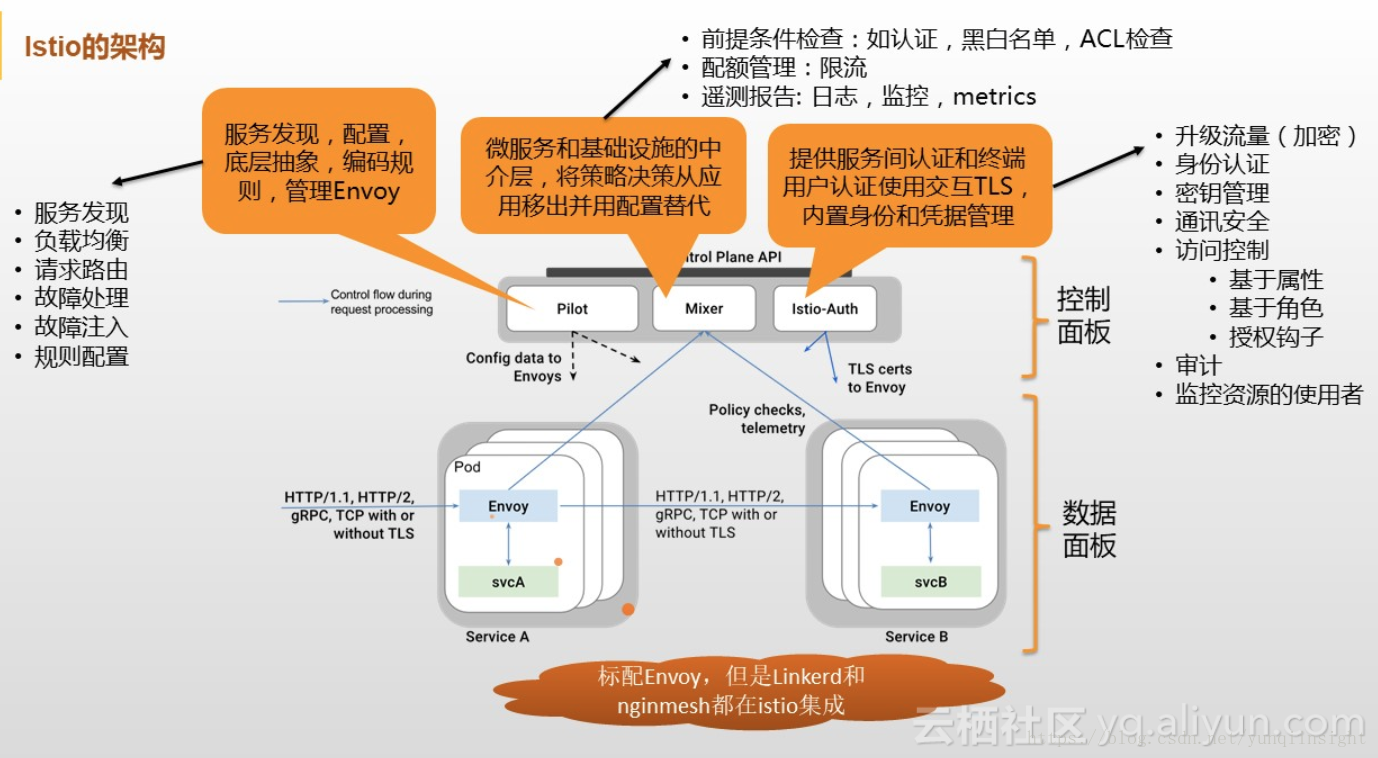
Envoy是Istio中的Sidecar官方标配,是一个面向服务架构的高性能网络代理,由C++语言实现,拥有强大的定制化能力,通过其提供的Filter机制基本可以对请求转发过程中超过50%的流程做定制化,在性能方面由于其实现参考了Nginx,也处于主流水平,当然还有很多特性,在这里就不做一一介绍了。
从一份配置了解Envoy主流程
任何软件架构设计,其核心都是围绕数据展开的,基本上如何定义数据结构就决定了其流程的走向,剩下的不外乎加上一些设计手法,抽离出变与不变的部分,不变的部分最终会转化为程序的主流程,基本固化,变的部分尽量保证拥有良好的扩展性、易维护性,最终会转化为主流程中各个抽象的流程节点。
对于Envoy也不例外,作为一个网络代理程序,其核心职责就是完成请求的转发,在转发的过程中人们又希望可以对其做一定程度的微处理,例如附加一个Header属性等,否则就没必要使用代理程序了。那么Envoy是如何运作的呢?它是如何定义其数据结构,并围绕该数据结构设计软件架构、程序流程,又是如何抽象出变得部分,保证高扩展性呢?
带着这些疑问,试想Envoy作为一个高度可定制化的程序,其定制化的载体必然是配置信息,那么我们下面就试着从Envoy的一份配置来解读其架构设计与程序流程。
在查看其配置前,我们不妨先脑补一下网络代理程序的流程,比如作为一个代理,首先要能获取请求流量,通常是采用监听端口的方式实现,其次拿到请求数据后需要对其做些微处理,例如附加Header头或校验某个Header字段内容等,这里针对来源数据的层次不同,就可以分为L3L4L7,然后将请求转发出去,转发这里又可以衍生出如果后端是一个集群,需要从中挑选出一台机器,如何挑选又涉及到负载均衡等。脑补下来大致流程应该就是这个样子,接下来我们看看Envoy是如何组织其配置信息的。
Envoy配置的简单配置信息如下: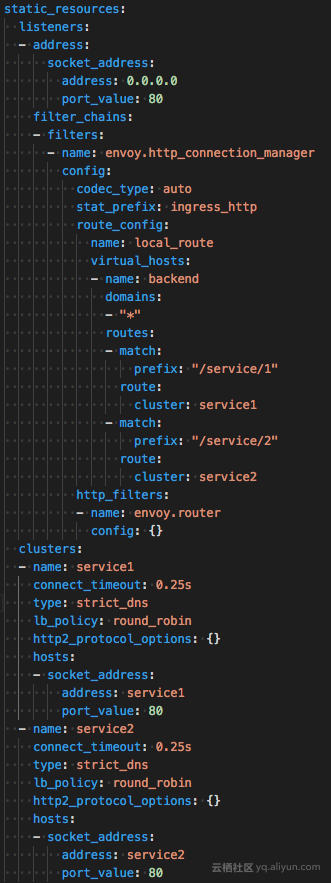
关键字段说明:
Listener: 服务(程序)监听者。就是真正干活的。 Envoy 会暴露一个或者多个listener监听downstream的请求。
Filter: 过滤器。在 Envoy 中指的是一些“可插拔”和可组合的逻辑处理层。是 Envoy 核心逻辑处理单元。
Route_config: 路由规则配置,即请求路由到后端那个集群(cluster)。
Cluster: 服务提供方集群。Envoy 通过服务发现定位集群成员并获取服务。具体请求到哪个集群成员是由负载均衡策略决定。通过健康检查服务来对集群成员服务状态进行检查。
根据上面我们脑补的流程,配合上这份配置的话,Envoy大致处理流程如下图: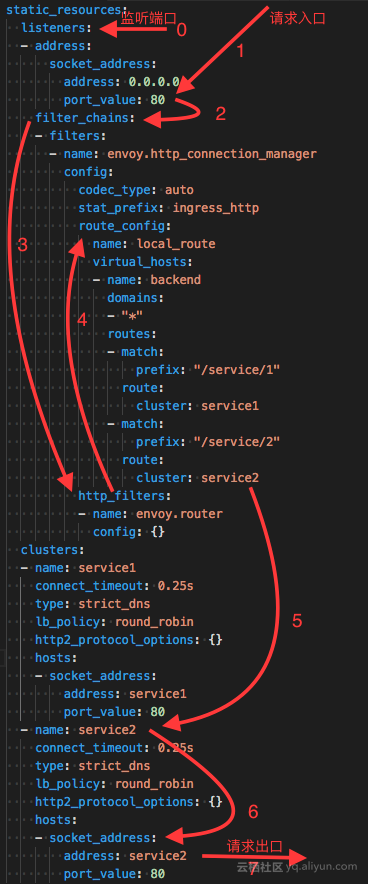
Envoy内部对请求的处理流程其实跟我们上面脑补的流程大致相同,即对请求的处理流程基本是不变的,而对于变化的部分,即对请求数据的微处理,全部抽象为Filter,例如对请求的读写是ReadFilter、WriteFilter,对HTTP请求数据的编解码是StreamEncoderFilter、StreamDecoderFilter,对TCP的处理是TcpProxyFilter,其继承自ReadFilter,对HTTP的处理是ConnectionManager,其也是继承自ReadFilter等等,各个Filter最终会组织成一个FilterChain,在收到请求后首先走FilterChain,其次路由到指定集群并做负载均衡获取一个目标地址,然后转发出去。
浅谈Envoy架构
聊完了基本流程后,本节会试着分析其架构设计,希望从其架构设计中获得一些益处。
先卖个关子,在本节开始之前我们不妨先思考一个有趣的问题:Envoy本身采用C++开发的,普遍认可C++程序执行性能会更好,那么延伸下来可以想到Envoy的设计目标似乎是在追求高性能,那么真是如此吗?
在探究Envoy架构设计之前,我们先来看看Envoy自身是怎么描述其设计目标的,如下:
Envoy并不是很慢(我们已经花了相当长的时间来优化关键路径)。基于模块化编码,易于测试,而不是性能最优。我们的观点是,在其他语言或者运行效率低很多的系统中,部署和使用Envoy能够带来很好的运行效率。
非常有意思的表述,Envoy并没有把追求极致性能作为目标,那么其架构设计会弱化性能这块吗?
目前业内公认代理程序性能最好的是Nginx,其采用了per thread one eventloop模型,这种架构被业内普遍借鉴,那么Envoy呢?我们先看看下面的架构图: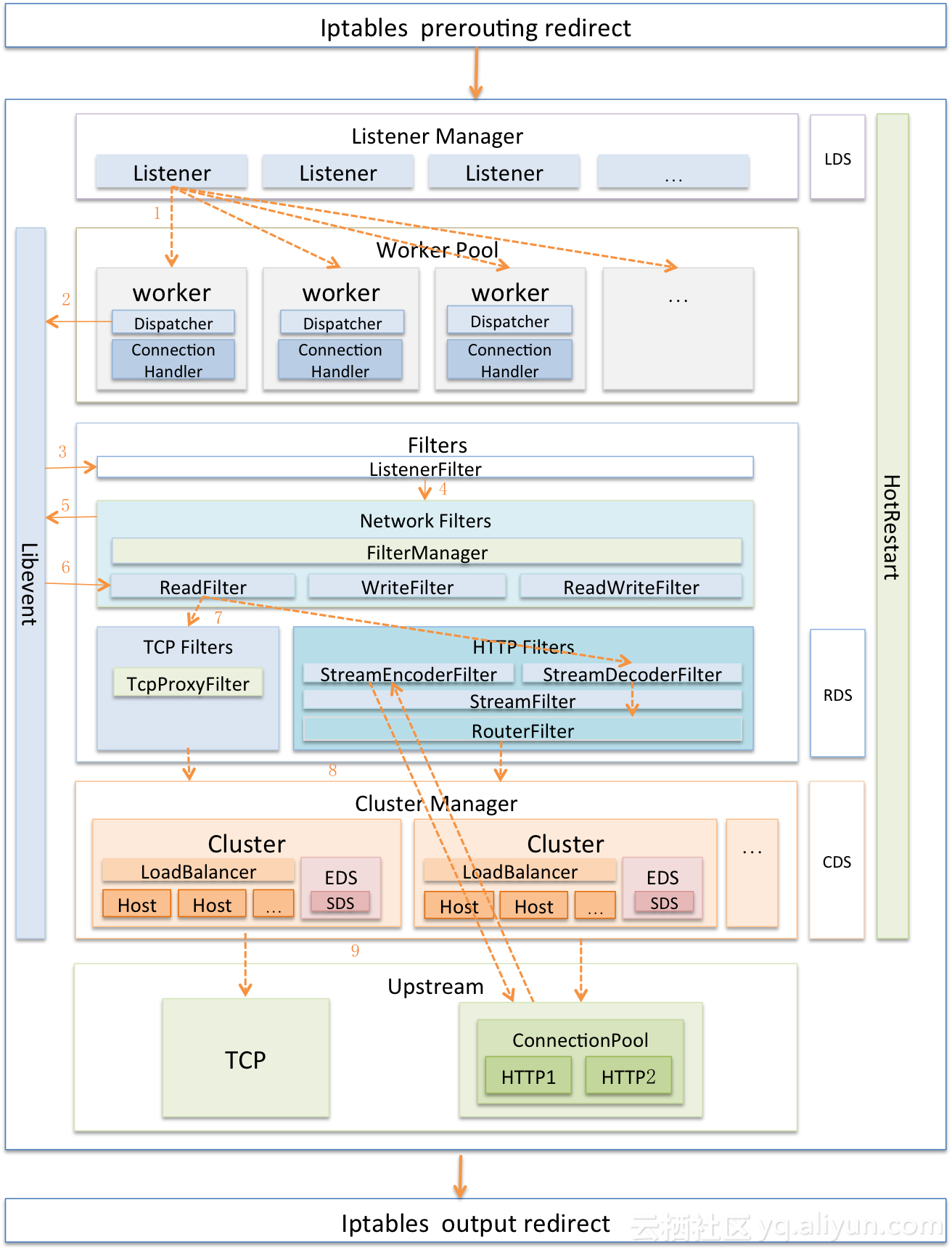
看到里面Worker的工作方式是不是很熟悉,会不会有一点点困惑呢?呵呵,没错,Envoy也采用了类Nginx的架构,方式是:多线程 + 非阻塞 + 异步IO(Libevent),虽然Envoy没有把极致性能作为目标,但不等于没有追求,只不过是相对于扩展性而言级别稍微低一点而已。
Envoy的另一特点是支持配置信息的热更新,其功能由XDS模块完成,XDS是个统称,具体包括ADS(Aggregated Discovery Service)、SDS(Service Discovery Service)、EDS(Endpoint Discovery Service)、CDS(Cluster Discovery Service)、RDS(Route Discovery Service)、LDS(Listener Discovery Service)。XDS模块功能是向Istio的Pilot获取动态配置信息,拉取配置方式分为V1与V2版本,V1采用HTTP,V2采用gRPC。
Envoy还支持热重启,即重启时可以做到无缝衔接,其基本实现原理是:
- 将统计信息与锁放到共享内存中。
- 新老进程采用基本的RPC协议使用Unix Domain Socket通讯。
- 新进程启动并完成所有初始化工作后,向老进程请求监听套接字的副本。
- 新进程接管套接字后,通知老进程关闭套接字。
- 通知老进程终止自己。
Envoy同样也支持Lua编写的Filter,不过与Nginx一样,都是工作在HTTP层,具体实现原理都一样,不做赘述了。
到此为止我们看完了上面的架构图,如果你对其内部实现也有兴趣的话,可以看看下面的内部实现类图: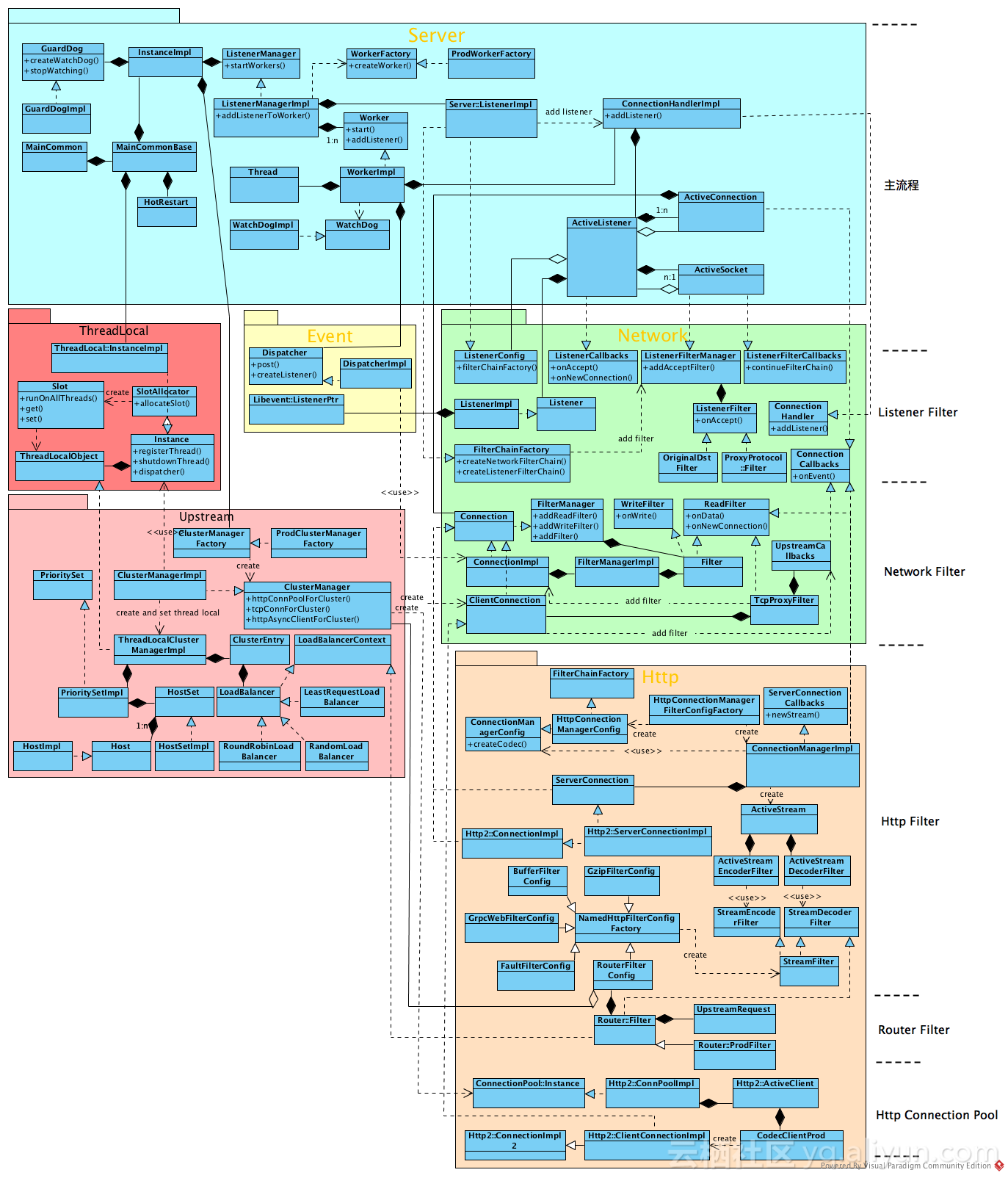
其内部实现为了灵活性,做了很多抽象封装,但基本上可以拆分为几个大的功能模块,具体如上图,不再赘述。
Envoy性能谈
软件的世界从来就不存在什么银弹,虽然ServiceMesh优势很明显,甚至被尊称为服务间的通讯层,但不可否认的是ServiceMesh的到来确实对应用的性能带来了损耗,可以从两个方面看待此问题:
- 数据面板中Sidecar的加入增加了业务请求的链路长度,必然会带来性能的损耗,由此延伸可知请求转发性能的高低必然会成为各个Sidecar能否最终胜出的关键点之一。
- 控制面板采用的是集中式管理,统一负责请求的合法性校验、流控、遥测数据的收集与统计,而这要求Sidecar每转发一个请求,都需要与控制面板通讯,例如对应到Istio的架构中,这部分工作是由Mixer组件负责,那么可想而知这里必然会成为性能瓶颈之一,针对这个问题Istio官方给出了解决方案,即将Mixer的大部分工作下放到Sidecar中,对应到Envoy中就是新增一个MixerFilter来承担请求校验、流控、数据收集与统计工作,MixerFilter需要定时与Istio通讯以批量上报数据与拉取最新配置数据。这种方式在Istio之前微博的Motan、华为Mesher、唯品会的OSP中已经这么做了。
本节主要谈论Envoy在性能方面的努力及社区在性能方面呼声较高的一些内容。
Envoy作为Sidecar其提供的核心功能可以简单总结为以下三点:
- 对业务透明的请求拦截。
- 对拦截请求基于一定规则做校验、认证、统计、流量调度、路由等。
- 将请求转发出去,在ServiceMesh中所有的流量出入都要经过Sidecar,即由Sidecar承担起所有的网络通讯职责,由此可知请求转出后的下一个接收方也必然是Sidecar,那么Sidecar之间通讯协议的高效与否对ServiceMesh整体性能也会产生较大影响。
从上述三点中我们试着分析下性能优化的关键点,其中第1、3点是与业务基本无关的,属于通用型功能,而第2点的性能是与业务复杂度呈现相关性的,比如请求校验规则的多与少、遥测数据的采集精细度、数据统计的维度多样性等,因此最有可能提升Sidecar性能的点就是对请求的拦截与Sidecar之间通讯协议的高效性。
针对请求的拦截,目前常规的做法是使用iptables,在部署Sidecar时配置好iptables的拦截规则,当请求来临后iptables会从规则表中从上至下顺序查找匹配规则,如果没遇到匹配的规则,就一条一条往下执行,如果遇到匹配的规则,那就执行本规则并根据本规则的动作(accept, reject, log等),决定下一步执行的情况。为了更直观的展示iptables的执行过程,请看下图: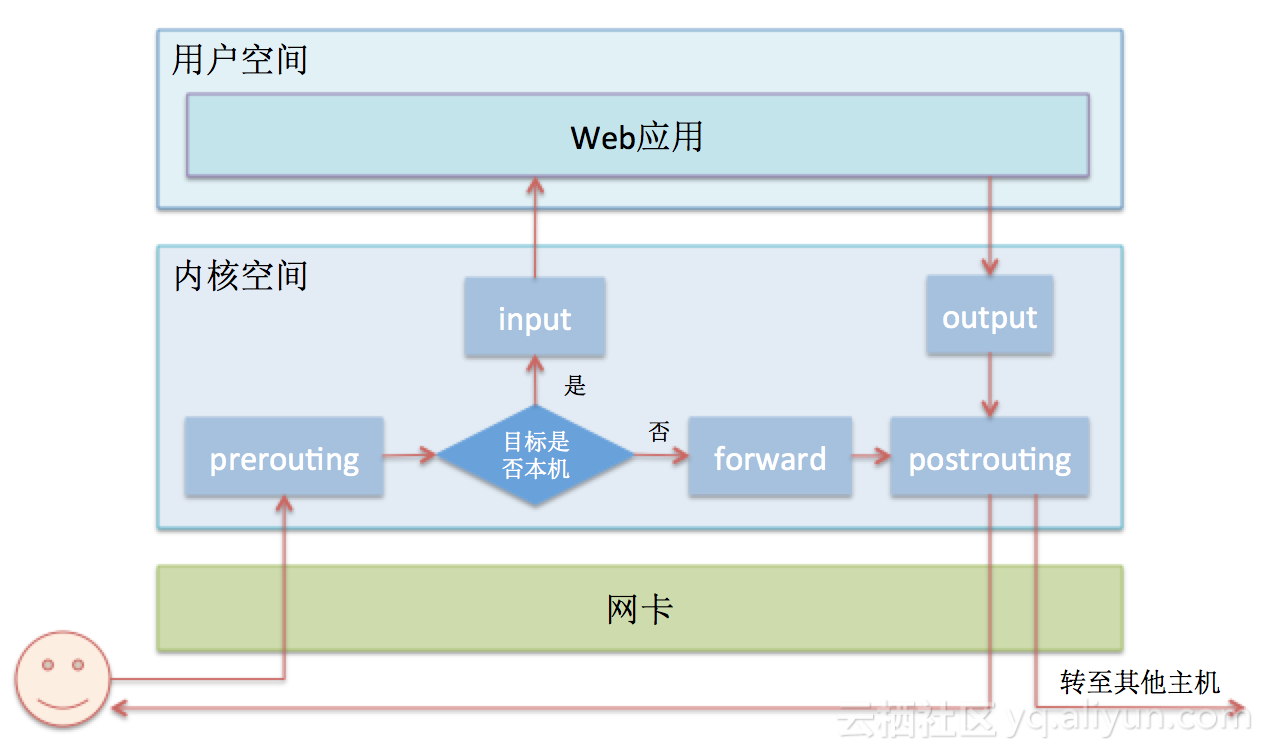
了解iptables的基本流程后,不难发现其性能瓶颈主要是两点:
- 在规则配置较多时,由于其本身顺序执行的特性,性能会下滑严重。
- 每个request的处理都要经过内核态--->用户态--->内核态的过程,这其中会带来数据从内核态拷贝到用户态的,再拷贝到内核态的性能消耗,单次请求来看这种消耗很少,但是作为流量进出的守门人,可想而知每秒进出的请求量必然是一个很高的数字,其累积的消耗也必然很高,再进一步分析由于网络中大量数据包的到来,会产生频繁的硬件中断、上下文切换,甚至是一个数据包在多个CPU核之间切换处理,这些因素叠加起来会对性能造成更大的损耗。
既然知道了iptables的缺陷,那么优化手段不外乎从这两点下手,而Linux社区与Envoy社区也正在计划对此做优化,具体如下:
- Linux内核社区最近发布了bpfilter,一个使用Linux BPF提供的高性能网络过滤内核模块,计划用来替代netfilter作为iptables的内核底层实现,实现Linux用户向BPF过渡的换心手术。
- Envoy社区目前正在推动官方重构其架构,目的是为了支持自定义的network socket实现,当然最终目的是为了添加VPP(Vector Packet Processing)、Cilium扩展支持,无论使用VPP或Cilium都可以实现数据包在纯用户态或者内核态的处理,避免内存的来回拷贝、上下文切换,且可以绕过Linux协议栈,以提高报文转发效率,进而达到提升请求拦截效率的目的。
为什么规避Linux正常协议处理过程中内核态与用户态的转换如此重要呢?就以对我们最直观的内存拷贝为例,正常情况下,一个网络数据包从网卡到应用程序需要经过如下的过程:数据从网卡通过 DMA 等方式传到内核开辟的缓冲区,然后从内核空间拷贝到用户态空间,在 Linux 内核协议栈中,这个耗时操作甚至占到了数据包整个处理流程的 57.1%。为了更直观的对内存拷贝消耗有所了解,画了一张简图,如下: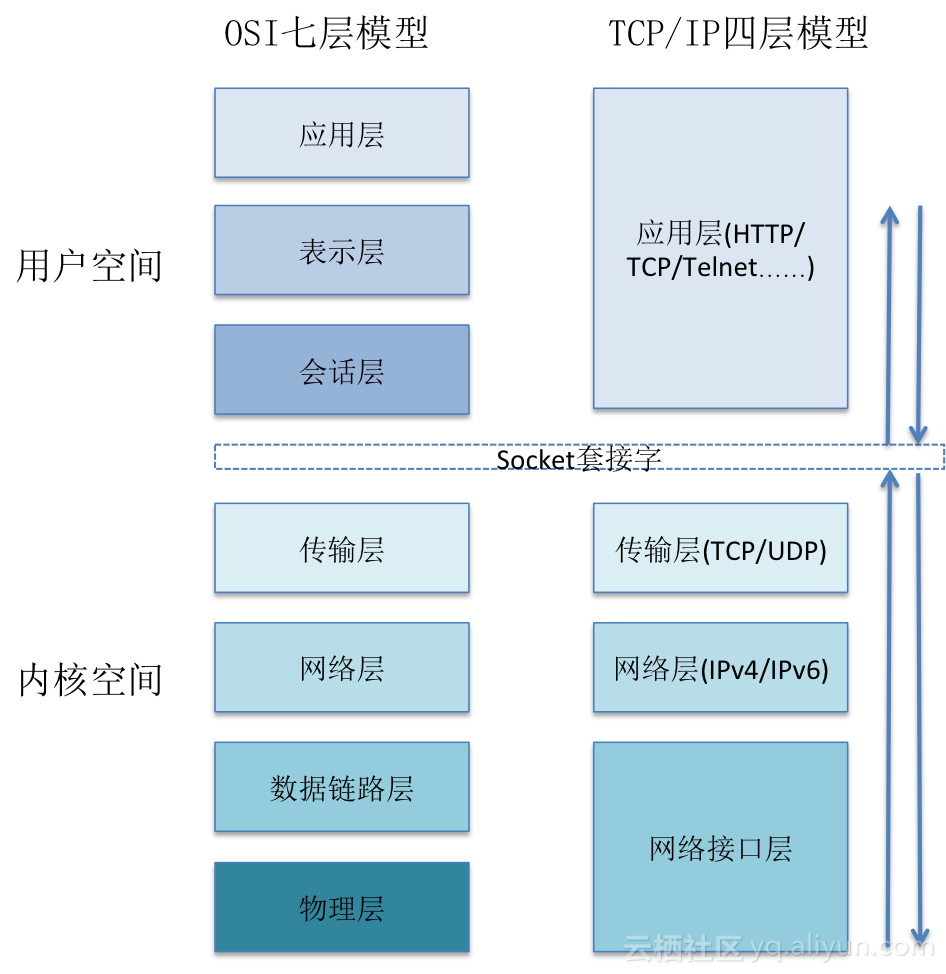
简说DPDK
DPDK全称Intel Data Plane Development Kit,是Intel提供的数据平面开发工具集,为Intel Architecture(IA)处理器架构下用户空间高效的数据包处理提供库函数和驱动的支持,它不同于Linux系统以通用性设计为目的,而是专注于网络应用中数据包的高性能处理,它将数据包处理、内存管理、处理器调度等任务转移到用户空间完成,而内核仅仅负责部分控制指令的处理。这样就解决了处理数据包时的系统中断、上下文切换、系统调用、系统调度等问题。
VPP是the vector packet processor的简称,是一套基于DPDK的网络帧处理解决方案,是一个可扩展框架,提供开箱即用的交换机/路由器功能。是Linux基金会下开源项目FD.io的一个子项目,由思科贡献的开源版本,目前是FD.io的最核心的项目。
整个DPDK还是非常复杂的,通过一两篇文章很难说清楚,且本文重点也不在DPDK,因此下面只简单介绍下其基本原理,让我们大致清楚为什么Envoy引入VPP后可以大幅提升请求处理转发效率。
为了说清楚DPDK是如何大幅提升了数据包的处理性能,我们先看一下普通的数据包在Linux中的收发过程,如下图:

通过上面两张图我们可以大致清楚数据包的一个完整的收发过程,可以看到整个处理链路还是比较长的,且需要在内核态与用户态之间做内存拷贝、上下文切换、软硬件中断等。虽然Linux设计初衷是以通用性为目的的,但随着Linux在服务器市场的广泛应用,其原有的网络数据包处理方式已很难跟上人们对高性能网络数据处理能力的诉求。在这种背景下DPDK应运而生,其利用UIO技术,在Driver层直接将数据包导入到用户态进程,绕过了Linux协议栈,接下来由用户进程完成所有后续处理,再通过Driver将数据发送出去。原有内核态与用户态之间的内存拷贝采用mmap将用户内存映射到内核,如此就规避了内存拷贝、上下文切换、系统调用等问题,然后再利用大页内存、CPU亲和性、无锁队列、基于轮询的驱动模式、多核调度充分压榨机器性能,从而实现高效率的数据包处理。说了这么多,接下来我们看下在DPDK中数据包的收发过程,如下图: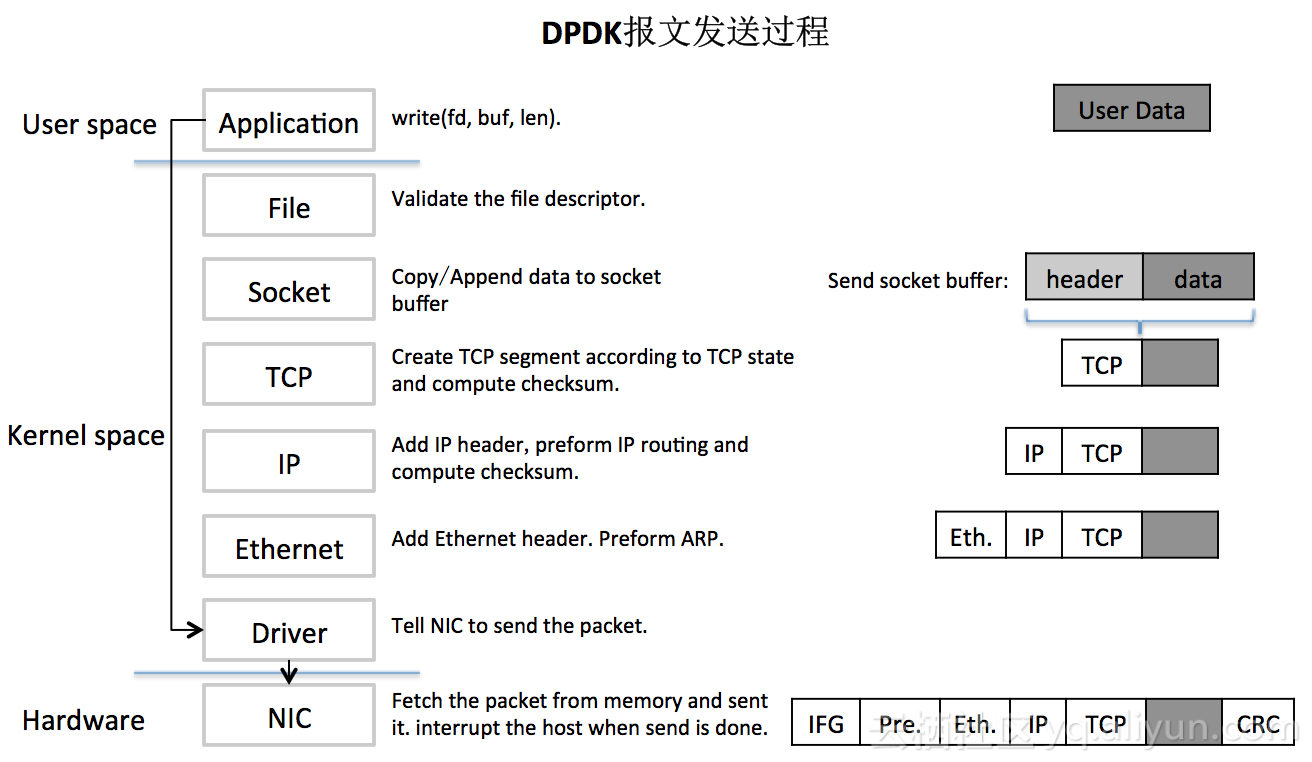

通过对比得知,DPDK拦截中断,不触发后续中断流程,并绕过内核协议栈,通过UIO(Userspace I/O)技术将网卡收到的报文拷贝到应用层处理,报文不再经过内核协议栈。减少了中断,DPDK的包全部在用户空间使用内存池管理,内核空间与用户空间的内存交互不用进行拷贝,只做控制权转移,减少报文拷贝过程,提高报文的转发效率。
DPDK能够绕过内核协议栈,本质上是得益于 UIO 技术,UIO技术也不是DPDK创立的,是内核提供的一种运行在用户空间的I/O技术,Linux系统中一般的驱动设备都是运行在内核空间,在用户空间用的程序调用即可,UIO则是将驱动的很少一部分运行在内核空间,绝大多数功能在用户空间实现,通过 UIO 能够拦截中断,并重设中断回调行为,从而绕过内核协议栈后续的处理流程。
那么UIO是如何拦截中断的呢?我们先看看作为一个设备驱动的两个主要职责:
- 存取设备的内存。UIO 核心实现了mmap可以处理物理内存、逻辑内存、虚拟内存。UIO驱动的编写是就不需要再考虑这些繁琐的细节。
- 处理设备产生的中断。设备中断的应答是必须在内核空间的,因此UIO只把非常小的一部分代码逻辑放在内核,剩余逻辑全部留给用户空间进程处理。
UIO的实现机制其实是对用户空间暴露文件接口,比如当注册一个 UIO 设备 uioX,就会出现文件 /dev/uioX,对该文件的读写就是对设备内存的读写。除此之外,对设备的控制还可以通过 /sys/class/uio 下的各个文件的读写来完成。UIO架构及流程图如下,不再赘述。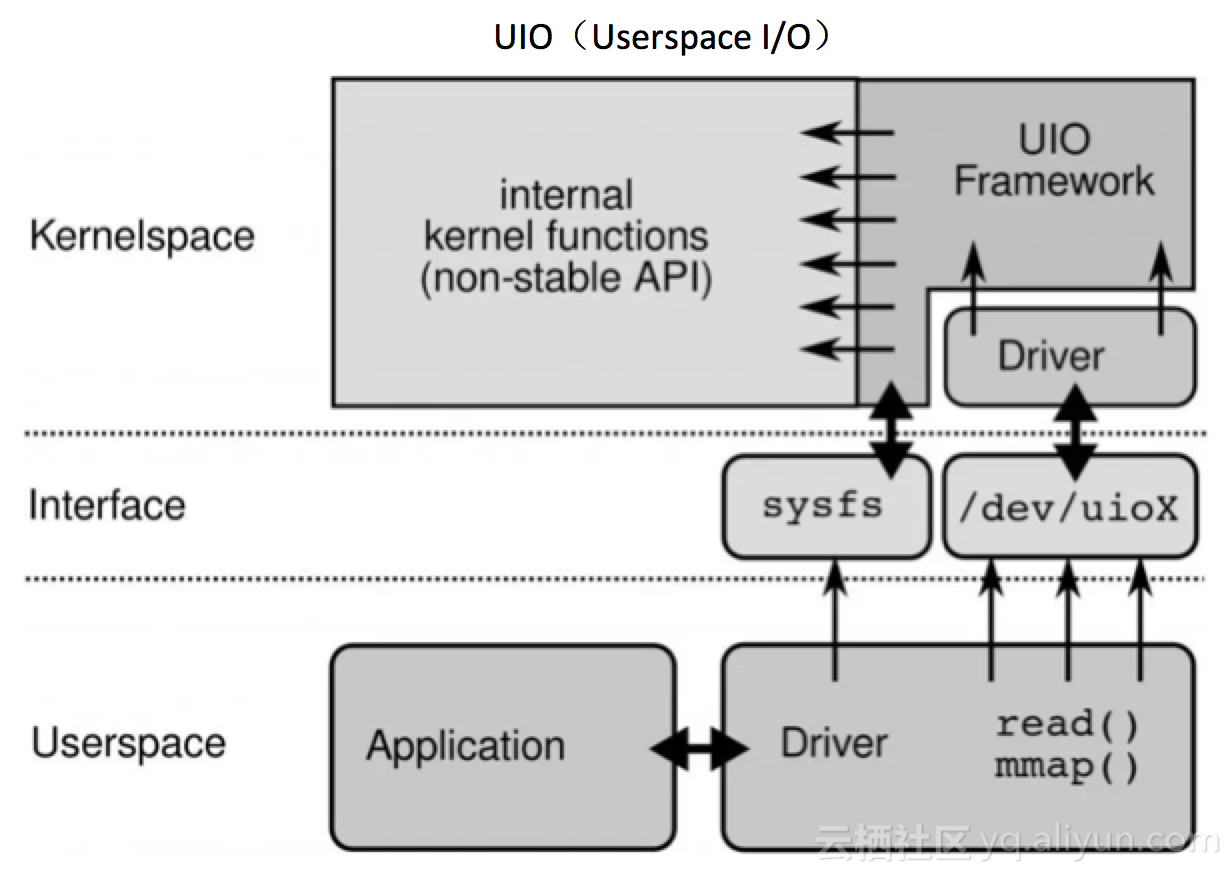
说完了DPDK,那么Cilium又是如何提高报文转发效率呢?既然Cilium 是基于 eBPF 和 XDP 实现的,而XDP归根结底也是利用eBPF为Linux内核提供高性能、可编程的网络数据路径框架,既然核心是eBPF,那么我们先了解下eBPF是什么。
简说eBPF与XDP
eBPF(extended Berkeley Packet Filter)起源于BPF,它提供了内核的数据包过滤机制。Linux 3.15 开始引入 eBPF。其扩充了 BPF 的功能,丰富了指令集。它在内核提供了一个虚拟机,用户态将过滤规则以虚拟机指令的形式传递到内核,由内核根据这些指令来过滤网络数据包。直白地讲就是我们可以让内核按照我们的规则来对数据包进行处理,包括未进入协议栈之前的处理哦,有没有瞬间觉得eBPF很牛逼,既然都这么强大了,有没有什么最佳实践或者应用呢?请看下图: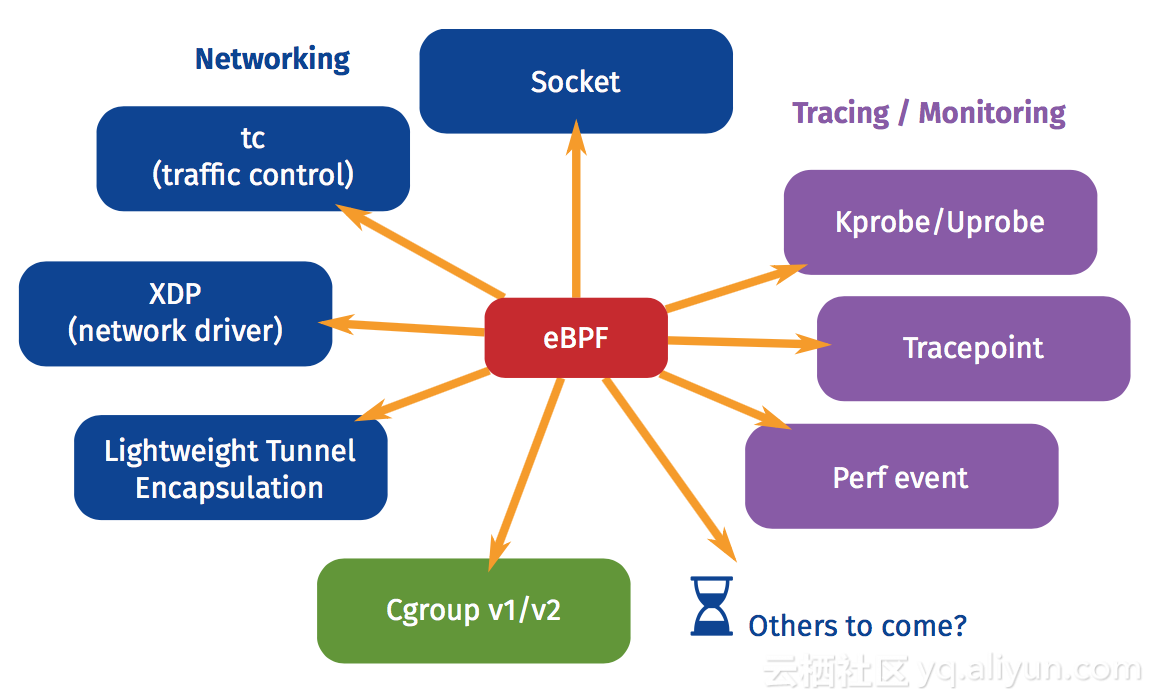
我们可以看到XDP本身就是一个eBPF的最佳实践,由于其他内容跟本文档讨论内容无关,不再展开。作为eBPF是如何工作以提供强大的能力呢?请看下图: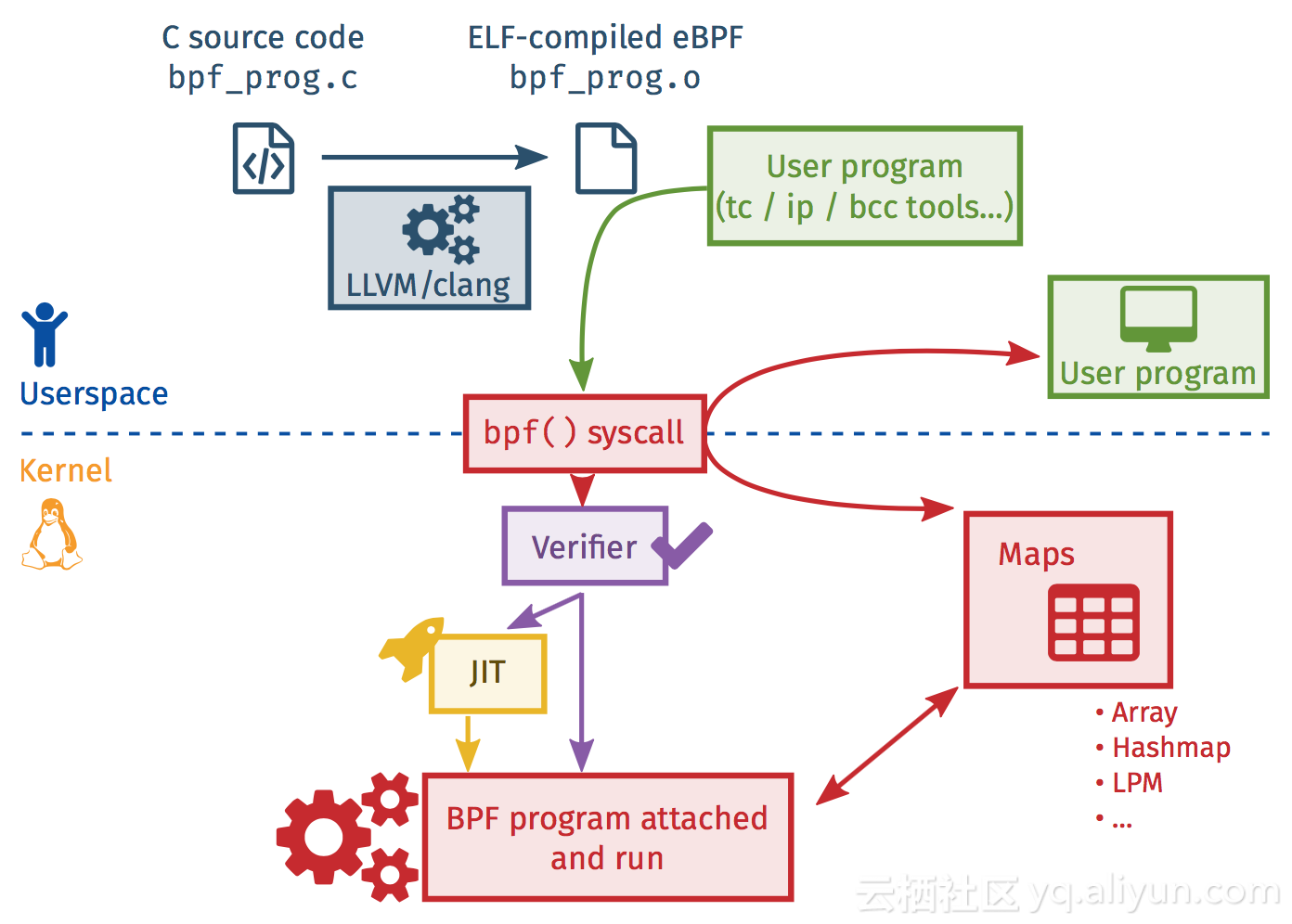
首先是将用户的.c文件编译后自动生成eBPF 字节码文件,也就是一堆的指令集合,其次通过系统调用将字节码注入到内核,然后内核验证合法性,通过校验后使用JIT将其run起来,用户程序与run起来的eBPF程序使用内核提供的标准Maps做数据交换。
与DPDK的内存全部在用户空间来避免内存拷贝、上下文切换、系统调用等不同,eBPF都是在内核空间执行的。但两者的核心都是通过避免数据包在内核态与用户态之间的往复来提升转发效率。
说完了eBPF,接下来该XDP粉墨登场了。XDP(eXpress Data Path)为Linux内核提供了高性能、可编程的网络数据路径。由于网络包在还未进入网络协议栈之前就处理,它给Linux网络带来了巨大的性能提升(性能比DPDK还要高)。
XDP在Linux内核4.8中引入,在数据包到达协议栈、分配sk_buff之前拦截,不同于DPDK的是XDP是作为内核功能的一部分,是与内核协同工作的。其基本处理流程如下图: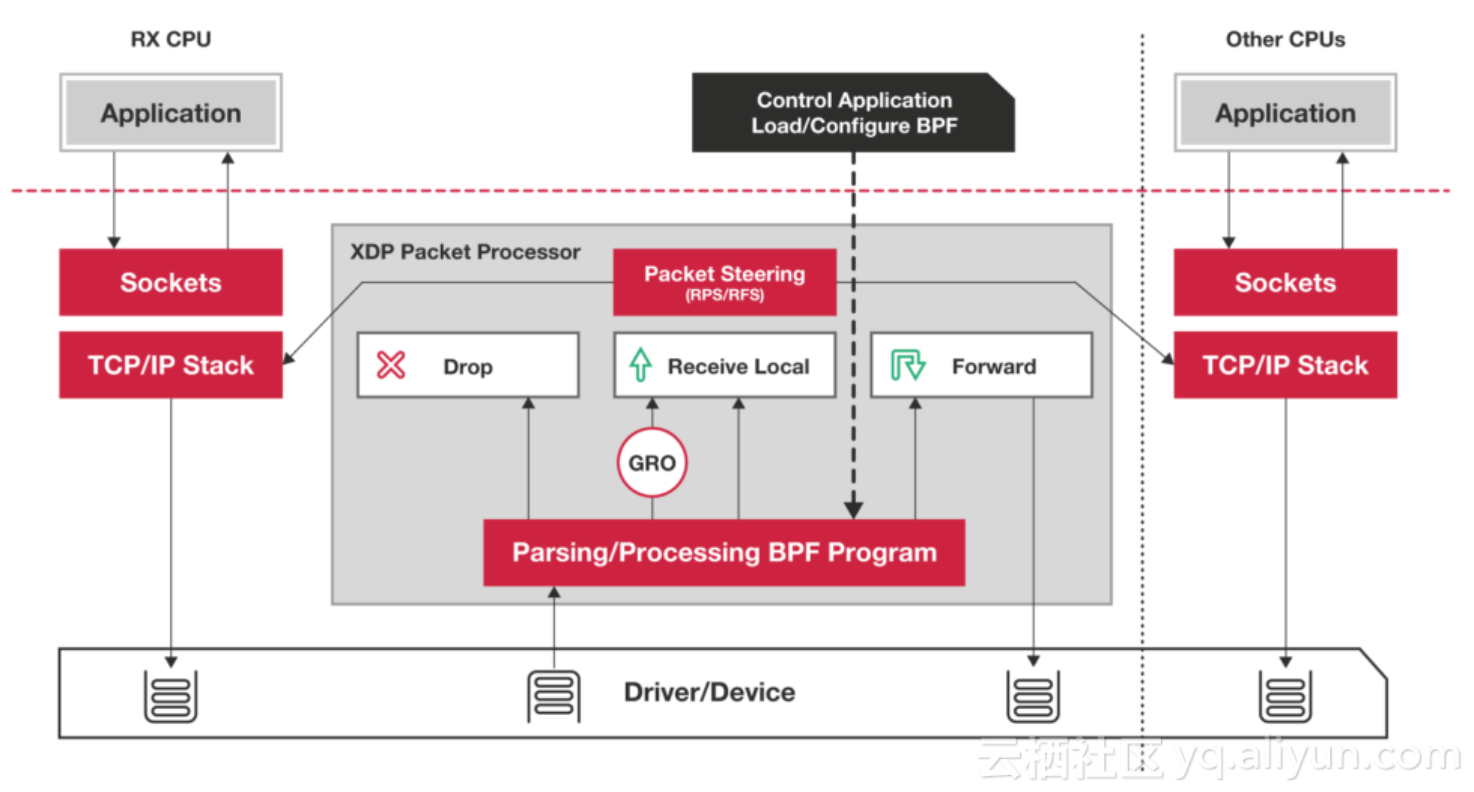
XDP同样将用户程序编译后生成eBPF字节码文件,注入内核执行包过滤。XDP包过滤是在数据包进入内核协议栈之前,如果判断数据包不需进一步处理可直接在内核态转发数据包,如果判断TX设备来不及处理会直接丢包,如果判断数据包需再处理则转给协议栈。
而为什么会有XDP比DPDK更高效的结论呢?也许通过下面这张图你可以自己找到答案。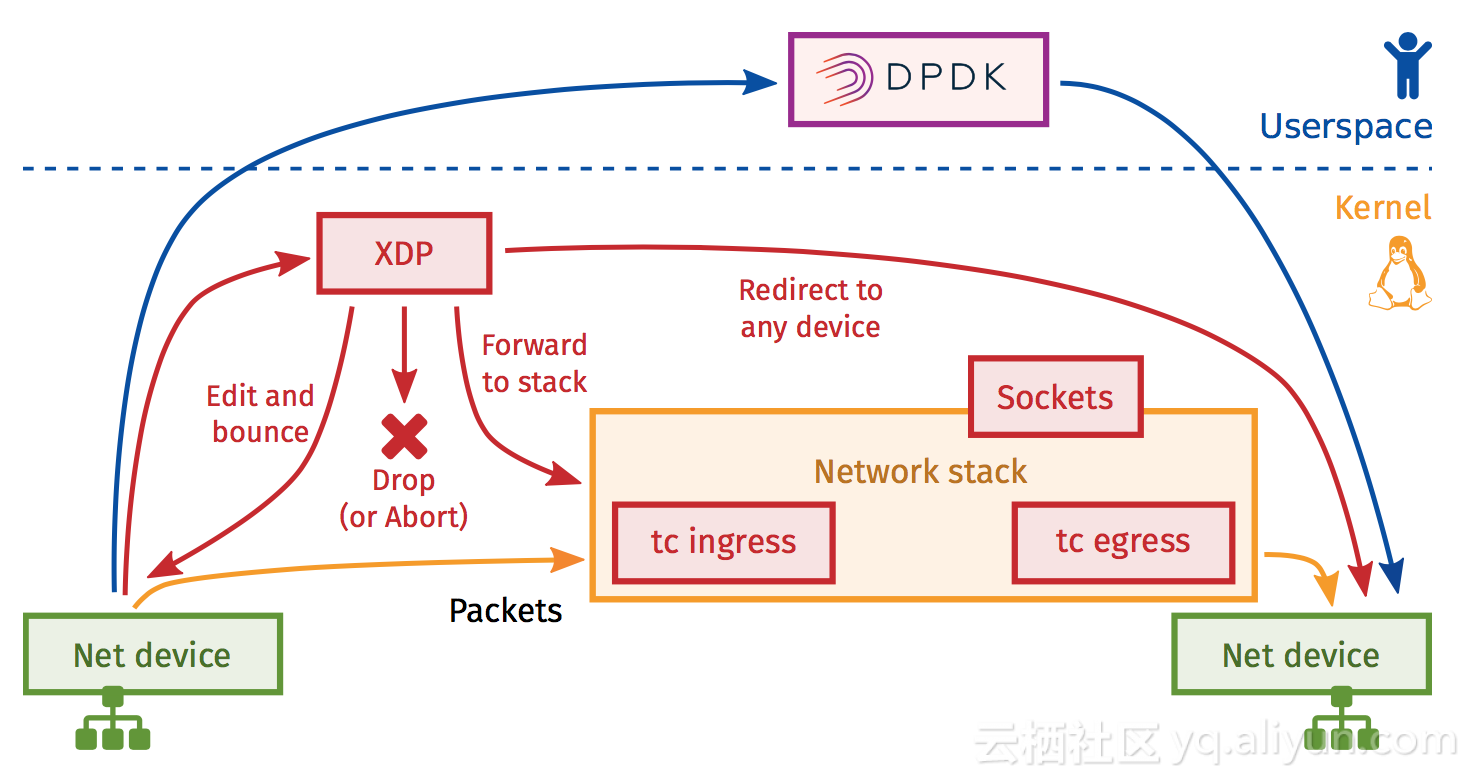
作为数据报文处理的新贵,其带来的性能优势是不言而喻,但XDP真的那么完美吗?答案一定是否定的,其缺点有二:
- XDP不提供缓存队列(qdisc),TX设备太慢时直接丢包,因而不要在RX比TX快的设备上使用XDP。
- XDP程序是专用的,不具备网络协议栈的通用性。
聊了那么多关于eBPF与XDP的内容,其在业界存在最佳实践吗?是的,目前facebook开源的katran项目,使用的正是这两项技术,据称其从IPVS转到eBPF后,使其性能提高了10倍。Linux社区中有人用XDP编写的一个简单的入口防火墙就可以轻松实现每秒处理1100万个数据包的性能。
简说QUIC协议
说完了如何高效的转发请求,接下来我们聊聊Sidecar之间如何高效的通讯。
提到通讯那就一定要提及通讯协议了,作为我们耳熟能详的两大基本通讯协议TCP与UDP的优缺点这里就不再赘述了,那么我们是否能整合TCP与UDP两者的优点呢,这样既保证了TCP的可靠与安全性,又兼具UDP的速度与效率,不可否认的是往往正是出于人们对美好事物的向往,才持续不断的推动我们前进的脚本。QUIC在这种期许下诞生,旨在创建几乎等同于TCP的独立连接,但有着低延迟,并对类似SPDY的多路复用流协议有更好的支持。
QUIC协议本身就内置TLS栈,实现自己的传输加密层,而没有使用现有的TLS 1.2。同时QUIC还包含了部分HTTP/2的实现,因此QUIC的地位看起来是这样的: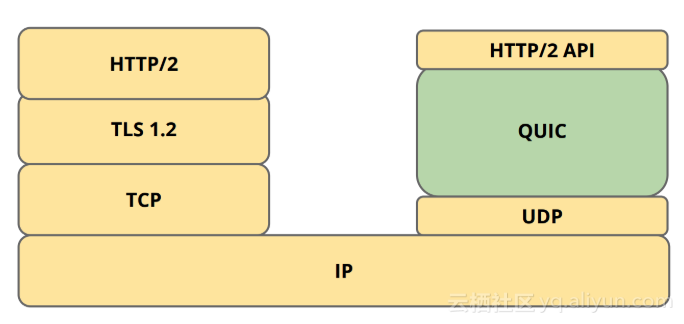
QUIC协议的诞生就是为了降低网络延迟,开创性的使用了UDP协议作为底层传输协议,通过多种方式减少了网络延迟。因此带来了性能的极大提升,且具体的提升效果在Google旗下的YouTube已经验证。
既然QUIC协议相比现有其他的协议更具优势 ,那是否也可以将其应用到Envoy中呢?Envoy社区正在推动官方重构其架构的目的之一就是为了QUIC,最终目的是希望使用QUIC作为Sidecar之间的通讯协议。
试想一下如果Envoy应用了上述技术,性能会有怎样的提升呢?这个就留给各位看官自行脑补吧。
读到这里不知各位是否会产生这样的疑问,目前作为ServiceMesh中数据面板的Sidecar有好几个,为什么只有Envoy社区在性能方面呼声最高呢?这就牵扯到一个老掉牙的话题了,因为Envoy是C系语言编写的,在应用OS特性时有着先天优势。
杂谈
上节内容提到目前有与Envoy同类的几个程序,包括Linkerd、Conduit、NginMesh,下面就以个人所知简单描述下各自的特点,仅供诸位参考。
就个人而言,其实挺希望Conduit的壮大,正如其设计初衷说的那样:轻量化,相比Istio这种重部署模式来讲,非常适合小规模业务的快速上手,且Conduit与Linkerd系出同门,足以保证其设计理念的先进性,虽然Buoyant公司宣称Conduit与Linkerd的目标不同,但细想下来未尝Buoyant公司没有存在一丝不甘,希望推出一个完整的Service Mesh方案来颠覆Istio一家独大的局面,夺回Service Mesh开创者的殊荣。
下面是各自的特性简述。
NginMesh:
- Golang实现。
- Sidecar实现模式:agent + nginx,agent负责监听Istio的配置变化(例如路由规则、集群信息、服务发现等),并将其转换为nginx的配置,然后通过重启nginx应用配置。
- 与istio、k8s强绑定,使用k8s的Initializer机制实现sidecar的自动注入。
- 目前尚未在生产环境验证。
- 虽然nginx也可以使用ngixscript/lua进行扩展,但大多局限于http处理上,对于L3L4的过滤上就无能无力了。
- 部署图如下:
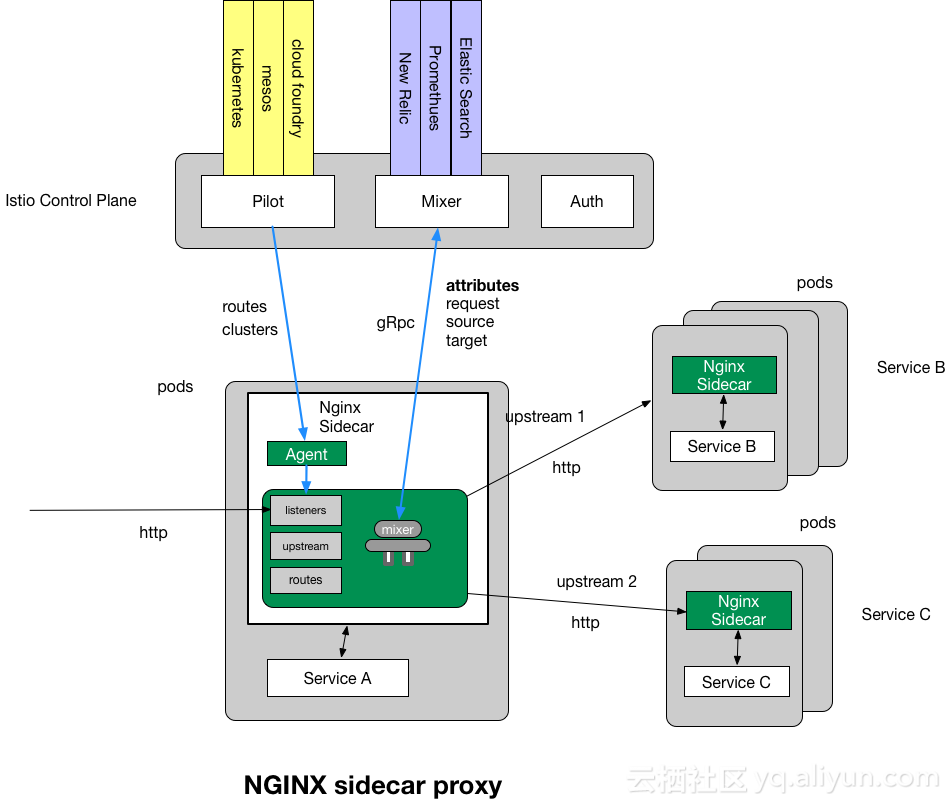
NginMesh给人的感觉更多的像是做了一个Istio的桥接器,只负责把Istio的配置信息翻译成Nginx所知的,通过重启Nginx的方式应用配置。给我的感觉仅仅是为了搭上ServiceMesh的顺风车而临时推出的一个方案。
Linkerd:
- Scala语言开发,运行在Java虚拟机上,“Service Mesh”概念的缔造者,经生产环境验证可靠的。
- 构建基于Netty、Finagle上,工作于RPC层。
- 插入式的服务发现,例如File-based、Zookeeper、k8s。
- 由于工作在RPC层,可根据实时观测到的RPC延迟、要处理请求队列大小决定如何分发请求,优于传统启发式负责均衡算法,例如LRU、TCP活动请求等。
- 提供多种负载均衡算法如:Power of Two Choices (P2C): Least Loaded、Power of Two Choices: Peak EWMA、Aperture: Least Loaded、Heap: Least Loaded以及Round-Robin。
- 数据流程图如下:
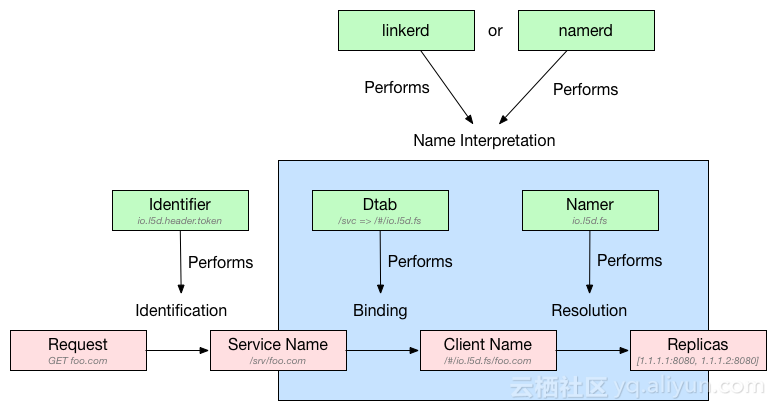
作为“Service Mesh”概念的缔造者、布道者,最终却在Service Mesh的大潮中,被由Google、IBM、Lft联手打造的Istio + Envoy打败,不得不感叹巨头的强大与初创公司的弱小与艰辛,由衷的希望看到Conduit的崛起,逆杀Istio。话说这是不是典型的弱者心态啊,哈哈。
Conduit:
- 脱胎于Linkerd,针对Linkerd部署模型太重的问题,其秉承的设计目标是成为最快、最轻、最简单的Service Mesh,使用Rust构建数据平面,使用Go构建控制平面。与Linkerd同出Buoyant公司。
- 不同于Envoy、Linkerd是数据平面,Istio是控制平面,Conduit中既包括数据平面,也包括控制平面,控制平面提供API,用户通过Conduit CLI与Web UI使用。
- 只能运行在K8s上。
- 目前发布了0.3版本,仍然处于初期开发阶段。
- 对经过Conduit proxy的流量,产生一系列的监控指标,指标格式是Prometheus的,内容存放在proxy监控端口的metrics路径下面,Prometheus可以直接抓取指标内容,做聚合展示。
- 利用Rust本身的语言安全特性来保证自身的安全性。
原文链接
本文为云栖社区原创内容,未经允许不得转载。


SSM集成RabbitMQ 关键代码讲解、开发、测试)





SSM集成RabbitMQ 路由模式关键代码讲解、开发、测试)





SSM集成RabbitMQ 通配符模式 关键代码讲解、开发、测试)




,该如何规划职业路线?)