OB君:蚂蚁金服资深技术专家虞舜将在本文为大家分享蚂蚁金服数据库所面对的业务挑战,解读OceanBase的自治数据库体系,解密OceanBase在天猫双11大促期间的稳定性解决方案,探索OceanBase在蚂蚁金服的智能运维实践之路。本文整理自OceanBase TechTalk技术沙龙杭州站上虞舜的演讲视频以及PPT。
前言
OceanBase是一款通用的分布式关系数据库,有很多独特的特点。比如数据库的多租户、高可用、极致弹性伸缩能力。如果把OceanBase当作单库使用,就没有办法把OceanBase的分布式能力发挥到极致。
近几年来,传统数据库的基础领域方面突破越来越少,而在人工智能和机器学习所驱动的自治数据库方面却屡屡获得重大进展。在今年的数据库顶级峰会SIGMOD中,有多篇优秀论文都与自治数据库领域关系密切,我们能越来越清晰地感受到,人工智能与数据库的结合已经成为了大势所趋。其实,不仅学术界如此,越来越多的商业数据库巨头也已经将重心转移到了自治化数据库之上。
关于OceanBase
OceanBase为何被称为金融级数据库呢?在蚂蚁,OceanBase部署在非常廉价并且经常发生故障的服务器上,而正是在这些不可靠的服务器上,建立了支撑支付宝、网商银行以及整个蚂蚁金服如此巨大业务量的OceanBase数据库,在出现机器宕机时能够在极短时间内恢复。2017年的天猫双11当天,蚂蚁每秒钟需要处理大约25.6万笔交易支付以及4200万次SQL请求。
OceanBase Milestone
那么首先我们一起来回顾一下OceanBase这几年的重要里程碑事件:2010年6月,OceanBase正式立项;2011年,淘宝收藏夹上线;2014年,支付宝交易系统上线;2016年,支付宝账务系统上线;2017年,OceanBase开始商业银行推广,至今已在多家商业银行上线运行。
OceanBase至今已成功应用于支付宝全部核心业务:交易、支付、会员和账务等系统,网商银行和印度Paytm以及阿里巴巴淘宝收藏夹、P4P广告报表等业务。从2017年开始,OceanBase开始服务外部客户,包括南京银行、浙商银行、人保健康险平台等。

目前,OceanBase技术团队正在如上图所示的几个方向上开展研究工作,包括HTAP、全局快照、兼容性等等。本文分享的主题则是其中一个重要的研究方向——智能化数据库。
蚂蚁数据库的挑战和应对之道
对于蚂蚁金服而言,数据库方面的挑战可以主要分为5个方面:高并发交易、低成本交易、精细化高可用、国际化以及高效的研发运维支撑。
智能驱动的Self-Driving Database

为了应对上述数据库方面的挑战,蚂蚁需要更加智能的自治数据库来提升整体的效率和稳定性。在蚂蚁我们做了几个方面的实践,比如数据库配置的自调优(Self/Auto Tuning),遇到故障时候的自愈(Self/Auto Healing)以及面对容量、利用率以及成本问题的自伸缩(Self/Auto Scaling)。其实,智能驱动的自治数据库就像是自动驾驶汽车一样,目标是希望让大部分的事情都由数据库自己完成,让DBA、SRE、业务研发能够更加专注地做好业务。
SIGMOD以及业界趋势
自治数据库近年来无论是在学术界还是工业界都是比较火的,学术界的SIGMOD 2018里的两篇论文:“Query-based Workload Forecasting for Self-Driving Database Management Systems”和“P-Store: An Elastic Database System with Predictive Provisioning”和蚂蚁目前正在做的工作比较接近。此外,在工业界, Oracle将Autonomous Database作为一个重要的方向,提升Oracle在数据库市场上的竞争力。
智能化数据库系统的架构

如上图,这是蚂蚁定义的智能化数据库系统的架构,包括感知、决策、执行等模块,其实,简单而言它是一个典型的控制系统。站在数据库的角度来看,整个系统的目标就是让Response Time最小、吞吐量最高、RT时间最小。
智能化数据库系统的输入可能是负载模型或者系统事件,这两者就构成了系统所需要感知的元素。举例而言,比如OceanBase系统感知到了一次SSD磁盘IO抖动,因为蚂蚁数据库系统中有海量的SSD,这样的抖动每天都会发生,有些抖动只发生一次就会恢复,而另外一些抖动可能因为SSD固件Bug、物理故障等因素无法自动恢复,可能会Hung死系统。智能化的数据库系统首先将会通过数据和算法感知到IO问题,然后将信息同步给决策系统——数据库大脑,数据库大脑会决策这样的问题出现之后应该如何解决。例如,在蚂蚁,当系统感知到业务异常时,大脑会快速的根据数据和算法判断异常的根因以及可行的方案,当识别到SSD有问题时就会做出剔除SSD或者OceanBase Server的决策,实现Response Time的快速恢复。
在上图所示的智能化数据库系统架构设计中,系统层面使用了很多的机器学习算法,OceanBase层面也做了大量的能力扩展和防护措施,比如上面谈到的SSD或Server的剔除能力,OceanBase在执行操作之前会进行leader切换以及副本完整性检测,避免影响业务。智能数据库系统的优化策略与人的决策过程非常相似,比如DBA优化SQL时会先判断哪里存在问题,这就完成了第一步“感知”,之后再进行第二步“决策”,根据经验判断应该执行的操作,第三步,是执行这个操作从而达到优化系统或者恢复故障的目的。
智能化数据库系统的三大组件
智能化基石
要建立上述的智能数据库系统,需要坚实、灵活的基础能力支撑,包括一下几个方面:
第一点是灵活可扩展、可定制的OceanBase,例如,开放数据库内核的能力,使得平台或者工具可以任意干预SQL的计划和执行策略,任意切换主节点并修改资源配置,通过精心设计和实现这些内核能力,避免决策错误时对系统产生不良的影响。
第二点是自动化、稳定并且具备强大数据处理能力的平台。举例而言,如果数据库通过对历史数据的分析和计算,确定在未来三天内或三个月内将会出现容量不足的情况,那么就可以决策自动进行容量,而这一点建立在资源“池”化的基础上比如容器,如果数据库建立在物理机上,这就使得扩容变得异常困难。
在蚂蚁,数据库建立在容器之上,需要时调用API直接扩容容器即可,不需要时调用API归还容器即可,OceanBase自动对数据进行迁移和均衡,整个过程业务系统无感知,这样的容量伸缩方式也已经经历了多次双11的实战检验。此外,蚂蚁的数据库平台能够处理2017双11每秒4200万的SQL采集和计算,而每条SQL都会被记录到系统中,之后通过机器学习算法可以识别出SQL执行情况的变化。
最后就是数据库专家的经验,无论国内外,阿里和蚂蚁的数据库工程师的经验和能力都是很强的,不断将这些经验转化成为自治数据库需要的规则和算法,来提升整体系统的能力,让蚂蚁OceanBase的数据库体系逐步提升,逼近一个经验丰富的数据库工程师。
感知
具备了智能化基石之后,我们再来深入讨论构建智能化数据库系统的三个组件。首先,是感知系统,对于感知系统而言,它目标是理解数据库上运行了什么样的业务,并对上面的工作负载(Workload)进行建模,负载建模常用的一些算法,比如随机过程、回归以及RNN等在上述的论文中有所介绍,完成负载建模后,可以通过模型预测未来工作负载的变化,比如是否存在流量的突增(导致的容量不足)等,让数据库系统提前作出反应,比如建立索引、增加资源等。
另外一点就是“统一事件”,这一点较为抽象,“统一事件”用来建模数据库系统里面真实发生的事情、所处的状态,比如有没有Server宕机、有没有Partition发生迁移,或者某些关键指标的是否发生了变化等,为了感知这些事件,智能数据库系统中使用Anomaly Detection相关的算法(例如LSTM、ARIMA、HoltWinters以及Ensemble等算法)来识别这些变化并生成相应的事件。
决策
在智能数据库系统中,决策是使用AI或机器学习的一个非常重要的场景。决策的本质是给定一个输入,比如系统里面发生的事件、Metric Data以及Workload等,输出就是Action Plan,而优化的目标就是使得RT时间最小、TPS时间最大和成功率最高,这一点无论是在银行还是在蚂蚁金服内部都是一样的。
蚂蚁数据库目前所采用的策略主要有两种,一种是基于经验的决策,依靠蚂蚁DBA专家的经验建立一颗决策树,在判断当前的情况符合决策树中的分支时,决策执行提前设定好的预案。另外一种是基于学习的决策,这部分可以使用聚类或者控制理论算法来实现,在蚂蚁我们使用了最朴素的策略。这方面最大的挑战就是如何积累学习所需要的数据,因为机器学习的很多算法需要大量数据进行训练,蚂蚁为了积累这些数据开发了DB风险回归平台,其能够以95%的程度仿真线上系统的工作负载,通过自动的在这些工作负载上注入的异常和优化策略,达到积累数据的目的。
执行器
除了执行决策产生的Action Operator,执行器模块还有两个目标,就是实现幂等以及最小化系统影响。蚂蚁金服技术团队对于执行器做了抽象,将其抽象为Operator模型,这个模型中具有可免疫和可回滚的特点,也就是说在Operator或Action执行的时候就能够知道预期产生的结果,并且保证产生预期的结果,其背后就是基于数据或者规则进行的分析判断。
智能化的最佳实践案例
智能化大促
接下来结合蚂蚁金服的两个具体场景为大家分享智能化的具体实践。第一个场景是智能化大促,如下图所示的是蚂蚁金服的简化架构图。可以看出整个链路非常复杂,支付的核心链路需要经过很多的系统,之前都是通过人工方式判断大促场景有几个核心链路,并人工计算每个系统大约需要处理多少SQL以及需要多少机器,这样非常容易出现计算错误或者遗漏。
此外,还有一些系统可能并不重要,但是还是占用了很多机器,这其实是不合理的。因此在618大促过程中,蚂蚁金服实现了通过智能方式计算出到底哪些系统和链路是与大促相关的,在计算出精细化的容量之后就能够实现机器的自动扩容,之后系统就可以自动实现重新负载均衡。

智能化大促的第二点工作就是持续优化。每年在蚂蚁内部都会上线很多新系统,对于大促相关的业务系统,需要驱动其持续进行优化,而由于业务迭代太快,所以这一点无法靠人工完成,需要能够自动识别整个系统的瓶颈和问题,并提供优化建议。
第三点就是用户无感知压测,蚂蚁的线上系统在运行真实业务流量的同时,也会运行用于检测系统容量的测试流量。由于双11的流量压力非常大,因此在进行线上压测的时候很容易造成故障,故障随着RPC的传导可能会造成整条链路出现问题,进而影响用户体验。针对这个问题,通过对历史数据的学习和建模,计算下一次再增加压力是否会造成失败,从而避免压测影响到用户。
第四点是资源利用率的提升,蚂蚁将数据库放到容器里面之后也就形成了一个非常大的分布式系统。该系统的部分业务和双11相关,另外一些则没有关系,与双11有关系的业务系统的CPU会非常忙绿,而没有关系的业务系统的CPU将会非常空闲,想要将系统的资源利用率提升上去就需要rebalance等智能化方法。
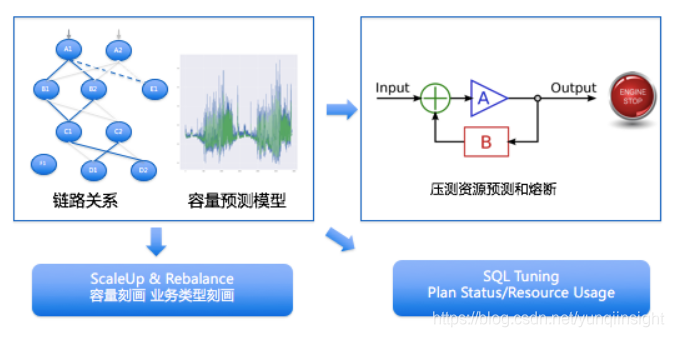
蚂蚁金服针对于复杂的链路实现了容量预测模型,与此同时还会对于业务类型进行刻画,判断链路是否与双11相关,以及其属于IO密集型还是CPU密集型。当将这些业务模型刻画好之后,就能够清楚地了解业务情况,进而可以实现很多事情,比如从全局的角度将与双11相关与不相关的业务合并部署到同一台机器上,更合理的利用资源,而且这些都是系统自动化实现的,无需人工参与。
另外一点就是持续进行优化,这包括资源优化和计划状态,蚂蚁的数据库系统采集了线上运行的所有SQL以及SQL的运行数据,对每条SQL都进行了参数化以及分库分表归一化建模,从而了解每条SQL大概会访问多少数据,访问了哪条索引,最优策略应该是什么样的。其效果就是对于线上运行的所有核心业务的每一条SQL,都可以判断哪条SQL不是最优的,或者数据库访问资源过多需要修改,并通过钉钉“@”具体相关人员进行改进。
稳定性

第二个具体场景就是稳定性,这里列举了支付宝经常使用的三个场景:移动支付、乘公交地铁以及购买理财产品,而在这些场景对实效性、成功率等要求时非常高,在蚂蚁金服这样的体量下,任何一点点异常都会影响非常多的用户,促使蚂蚁对稳定性的要求越来越高,既要具备城市级容灾能力,也要具备精细化的异常恢复能力。
蚂蚁金服OceanBase的容灾机制
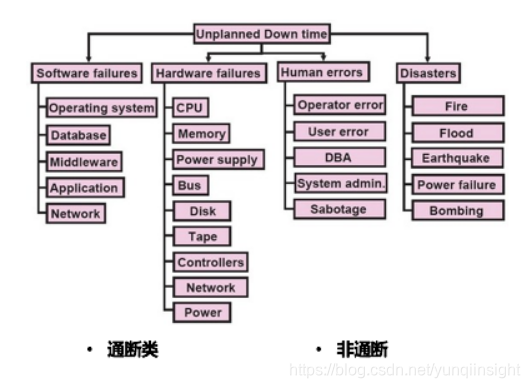
下图来自于Google,其大概列举了系统中经常会出现的异常类别。在过去的几年里,蚂蚁金服投入了大量的资源,进行架构改造升级,实现机房、网络等基础设施层面故障的快速恢复能力。蚂蚁金服也正在设计系统来发现非通断式异常,并快速、自动的将这些异常修复。
Zone/Region级别容灾
如下图所示的是蚂蚁金服的数据架构,在业务和数据库中间件的数据架构层能够保证当某一个机房挂掉可以立即切换到另外一个机房。左侧的图则是OceanBase的“三地五中心”的设计,即使某个城市故障都不会影响服务使用,这样的架构现在依旧在不断进行优化和打磨。

Self-Healing-精细化异常恢复
精细化异常恢复的主要目的是自动化解决数据库系统的异常。这里列举了几个例子,比如下图列举了三个非通断异常:Bad SQL、IO Hung以及Software Bug。目前,蚂蚁内部的目标就是在5分钟之内恢复这些异常,这显然无法通过人工完成,而需要自动化手段,比如基于专家经验的决策树和机器学习决策。Self-healing会引入一个问题,那就是如何防止自动化决策错误导致问题恶化,而目前蚂蚁能够做到了切主不杀事务、幂等控制和柔性强切以及其他系统防护的工作。
下一步计划
对于未来的计划而言,首先要让蚂蚁的所有业务域都运行在自治的数据库中,不再需要DBA进行日常维护,希望能够通过智能数据库解决90%以上的问题,而让DBA和架构师更加专注于架构发展和平台设计。此外,蚂蚁还希望将经过内部验证的功能和服务来赋能蚂蚁金融云和更多银行等金融机构。
原文链接
本文为云栖社区原创内容,未经允许不得转载。



















