目前大部分的互联网企业基本上都有搭建自己的大数据集群,为了能更好让我们的大数据集群更加高效安全的工作,一个优秀的监控方案是必不可少的;所以今天给大家带来的这篇文章就是讲阿里云TSDB在上海某大型互联网企业中的大数据集群监控方案中的实战案例,希望能为感兴趣的同学提供一些帮助。
背景和需求
阿里云时序时空数据库 (原阿里云时间序列数据库, 简称 TSDB) 是一种高性能,低成本,稳定可靠的在线时序数据库服务;提供高效读写,高压缩比存储、时序数据插值及聚合计算,广泛应用于物联网(IoT)设备监控系统 ,企业能源管理系统(EMS),生产安全监控系统,电力检测系统等行业场景。 TSDB 提供百万级时序数据秒级写入,高压缩比低成本存储、预降采样、插值、多维聚合计算,查询结果可视化功能;解决由于设备采集点数量巨大,数据采集频率高,造成的存储成本高,写入和查询分析效率低的问题。
Elastic MapReduce(EMR)是阿里云提供的一种大数据处理的系统解决方案。EMR基于开源生态,包括 Hadoop、Spark、Kafka、Flink、Storm等组件,为企业提供集群、作业、数据管理等服务的一站式企业大数据平台。
上海某大型互联网企业是阿里云EMR的Top客户,在阿里云上购买的EMR实例有近千台hadoop机器,这些机器目前除了阿里云本身ECS级别的监控以外,没有一套成熟的这对大数据的监控运维告警系统,对大数据业务来讲存在很大的风险。现在客户的需求是对购买的EMR集群做监控和告警,单台有20多个监控指标,采集精度可以根据客户需求调整,另外还要求对原有的业务无侵入,不需要业务层做太多的配置重启类操作。
痛点和挑战
该大型互联网企业客户最初计划采用的是Prometheus作为监控和告警解决方案,并且基于Prometheus的监控方案也在该企业内部其他系统应用了。
这里提到了Prometheus,就多说几句。随着业内基于Kubernetes的微服务的盛行,其生态兼容的开源监控系统Prometheus也逐渐被大家热捧。
Prometheus是一个开源监控系统,它前身是SoundCloud的监控系统,在2016年继Kurberntes之后,加入了Cloud Native Computing Foundation。目前许多公司和组织开始使用Prometheus,该项目的开发人员和用户社区非常活跃,越来越多的开发人员和用户参与到该项目中。
下图就是prometheus方案的架构:
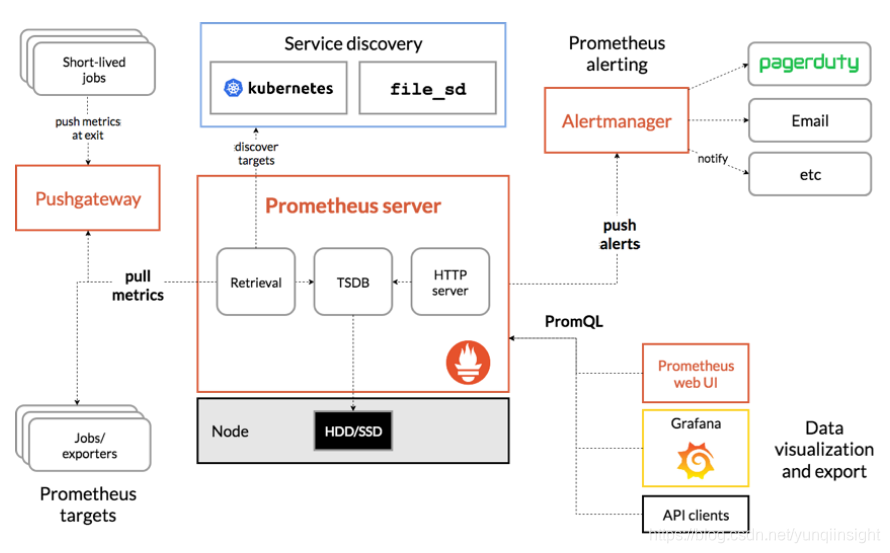
这个方案在实际部署过程中发现Prometheus在存储和查询上存在性能的问题,主要是Prometheus本身采用的local storage方案在大数据量下的扩展性写入查询性能存在瓶颈。
另外在这个方案的适配性不强,要改很多参数重启才行,这对于线上正在运行的业务来说,是不可接受的,需要重新设计解决方案。
阿里云TSDB解决方案
监控和告警整体上来说包括三个环节:
1.采集指标
2.存储指标
3.查询告警
因此基本方案就可以简化为:采集工具 + 数据库 + 查询告警。其中,数据库可以通过阿里云TSDB来解决存储和查询上的性能问题,查询告警可以通过成熟的开源工具Grafana。由于该互联网企业客户的要求对原有的业务无侵入,不需要业务层做太多的配置重启类操作,因此解决方案的调研就重点落在了采集工具的调研上了。
对于采集工具而言,结合该互联网企业客户已经部署的Prometheus,且阿里云TSDB兼容开源时序数据库OpenTSDB的写入和查询协议,因此从减少成本和工作量的角度来看,可以考虑的方式是有两种:
1. 使用Prometheus官方提供的开源的OpenTSDB Adapter 对接原生的Prometheus ,实现数据写入到TSDB。基本架构为:
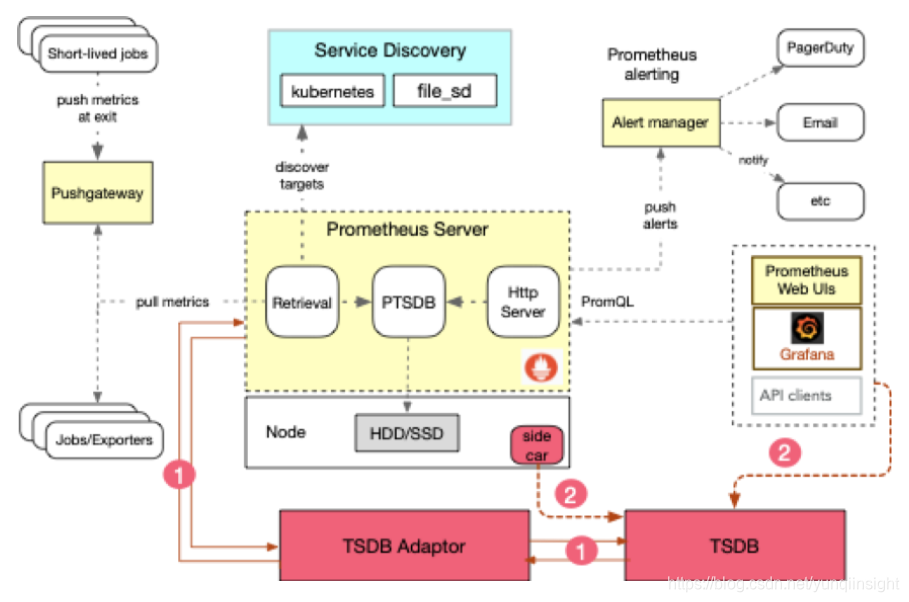
这种方案和该互联网企业客户的开发同学沟通后,发现满足不了对业务无侵入,不重启的需求,因此选择放弃;
2. 采用其他开源工具,实现数据采集写入到TSDB。开源社区较为活跃,已经提供了不少开源的采集工具,因此我门评估了以下几个开源的采集工具:
- Collectd,https://collectd.org
- telegraf, https://github.com/influxdata/telegraf
- statsd, https://github.com/etsy/statsd
- tcollector, http://opentsdb.net/docs/build/html/user_guide/utilities/tcollector.html
从开发语言、部署方式以及是否支持定制开发等角度,我们初步选择tcollector作为采集工具。tcollector是一个客户端程序,用来收集本机的数据,并将数据发送到OpenTSDB。tcollector可以为你做下面几件事:
- 运行所有的采集者并收集数据;
- 完成所有发送数据到TSDB的连接管理任务;
- 不必在你写的每个采集者中嵌入这些代码;
- 是否删除重复数据;
- 处理所有有线协议,以后今后的改进;
因此,基于tcollector + TSDB + Grafana的监控告警架构如下,其中tcollector以http协议从目标结点上拉取监控指标,并以http的OpenTSDB协议将指标推送至阿里云TSDB。
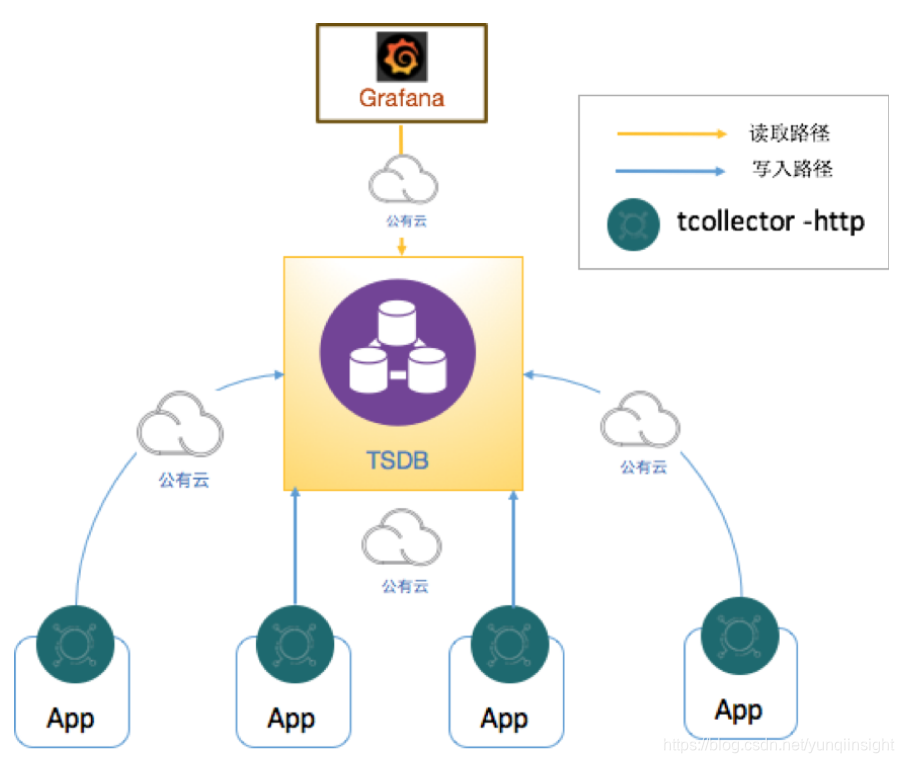
这个方案在不修改tcollector源码的基础上,能够满足客户对hadoop的监控。但是在PoC后,客户增加了对EMR实例中其他大数据组件的监控需求,如Hive, Spark, Zookeeper, HBase, Presto, Flink, azkaban, kafka, storm等。
经过我们调研,tcollector对于这些组件的支持程度如下:
- 原生支持:hbase;
- 需定制化开发,不重启实例:Hive, Spark, Zookeeper;
- 需定制化开发,需重启实例:Flink, azkaban, kafka, storm;
经过一定工作量的制化开发,基于tcollector的方案基本可以满足用户的需求。最终我们在该互联网企业客户的EMR大数据集群的监控告警方案架构为:
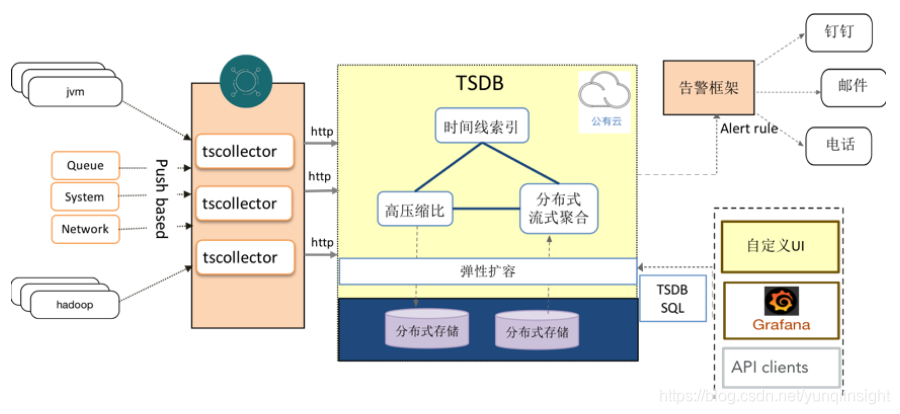
tcollector非常简单易部署,可以简单高效地完成了客户的需求。而且配置部署时,可以不用区分大数据组件的角色,解决了之前开源采集工具需要针对不同角色,来手动配置并启动相应插件的问题。
至此,TSDB完美得解决了该互联网企业客户大数据集群监控接入TSDB的案例,让TSDB在迈向完善生态的路上更进一步了。另外值得一提的是,为了解决目前广泛使用的Prometheus开源系统在大量时序数据的存储、写入和查询存在性能瓶颈问题,阿里云TSDB也已经开始兼容了Prometheus生态,并且已经在多个客户场景进行了实战。后面我们会推出针对Prometheus的系列文章,对Prometheus感兴趣或者已经是Prometheus用户但是遇到性能问题的同学可以持续关注我们。
原文链接
本文为云栖社区原创内容,未经允许不得转载。
异常:java.lang.SecurityException: JCE cannot authenticate the provider BC办法)














)



