文章目录
- 一、案例需求
- 二、使用案例:
- 2.1. 自定义查询接口
- 2.2. 逻辑处理类
- 2.3. 调用案例
- 2.4. 具体逻辑处理案例
- 三、企业案例
- 3.1. key名称获取
- 3.2. 逻辑类测试
- 3.3.最后一个批次处理方案
- 四、 通用SQL预编译处理
- 4.1. 业务场景
- 4.2. xml形式
- 4.3. 注解形式
- 五、企业案例
- 5.1. sql语句
- 5.2. 大数据流查询接口
- 5.3. 大数据查询结果集处理抽象类
- 5.4. 服务接口
- 5.5. 服务接口实现类
- 5.6. 前端控制器
声明:
大数据流查询解决查询结果集过大的导致内存溢出的问题。
针对查询通用SQL与数据交互的次数加到数据库压力,要使用预编译。
一、案例需求
查询sys_user表中的所有数据,数据库中供3条数据,在实际处理类中我设置了具体处理批次的数量为2条数据为一个批次,那么一个批次就只处理2条数据,处理完成后,继续处理下一个批次(2条数据),直至全部处理完成。
大病项目案例:数据库查询1次查询数量为1000条,在实际的逻辑处理中,我设置了本次批次处理的数据数量为500条,那一个批次就只处理500条,处理完第1个批次500条后,在处理下一次批次的500条。
注:
- 这个根据实际情况动态设置
- 项目中默认1000条查询数据库一次(开发者可忽略)
设计初衷:
为了让大家都按照规范去做,因此抽象此接口,具体实现类去继承,获取对应的实体对象,然后一一获取里面的对象。
局限性:
当在一个类中获取的对象不只是一个,此抽象接口不能使用,需要单独的在自己的实现类中,按照此方式手写对用的mapper,待补充
二、使用案例:
2.1. 自定义查询接口
声明接口作用:只是为了听过一个接口供外部调用服务
package com.gblfy.ly.service;public interface ISDQueryResulService {public void batchSDHandle();
}
注:如果外部不需要调用,此接口可以省略,实现类可不实现此接口
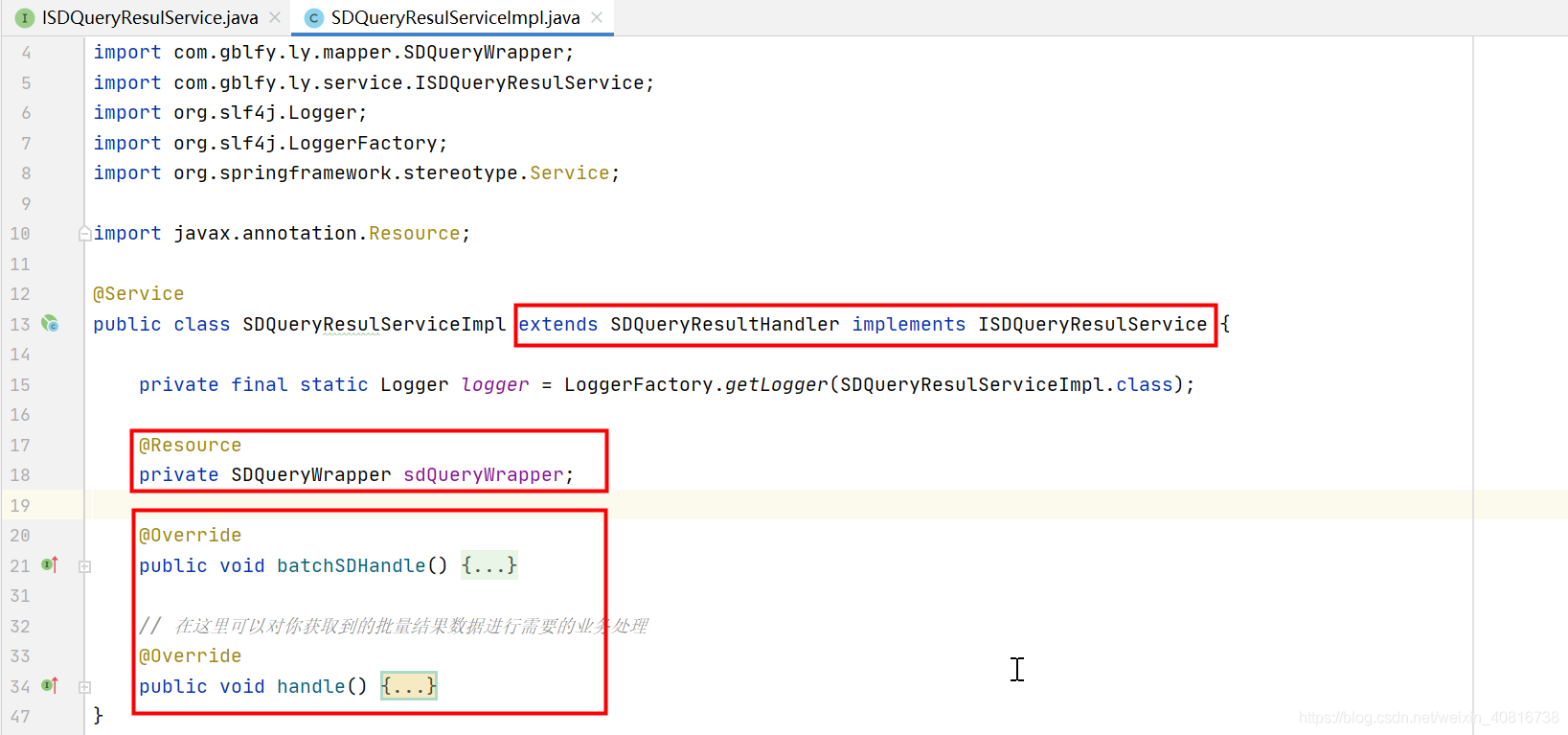
2.2. 逻辑处理类
- 1>继承extends SDQueryResultHandler重新handle方法,实现自己定义的接口
- 2>注入SDQueryWrapper接口
案例处理类路径:
com.gblfy.ly.service.impl. SDQueryResulServiceImpl
如下图所示:
2.3. 调用案例
1.自定义SQL语句
2.new 本身逻辑处理类
3.设置具体处理的批次数据数量
4.把new 好的处理类变量名,放到此方法内部
5.调用lastSDHandle方法注:具体使用请参考,案例代码,已上传gitlab仓库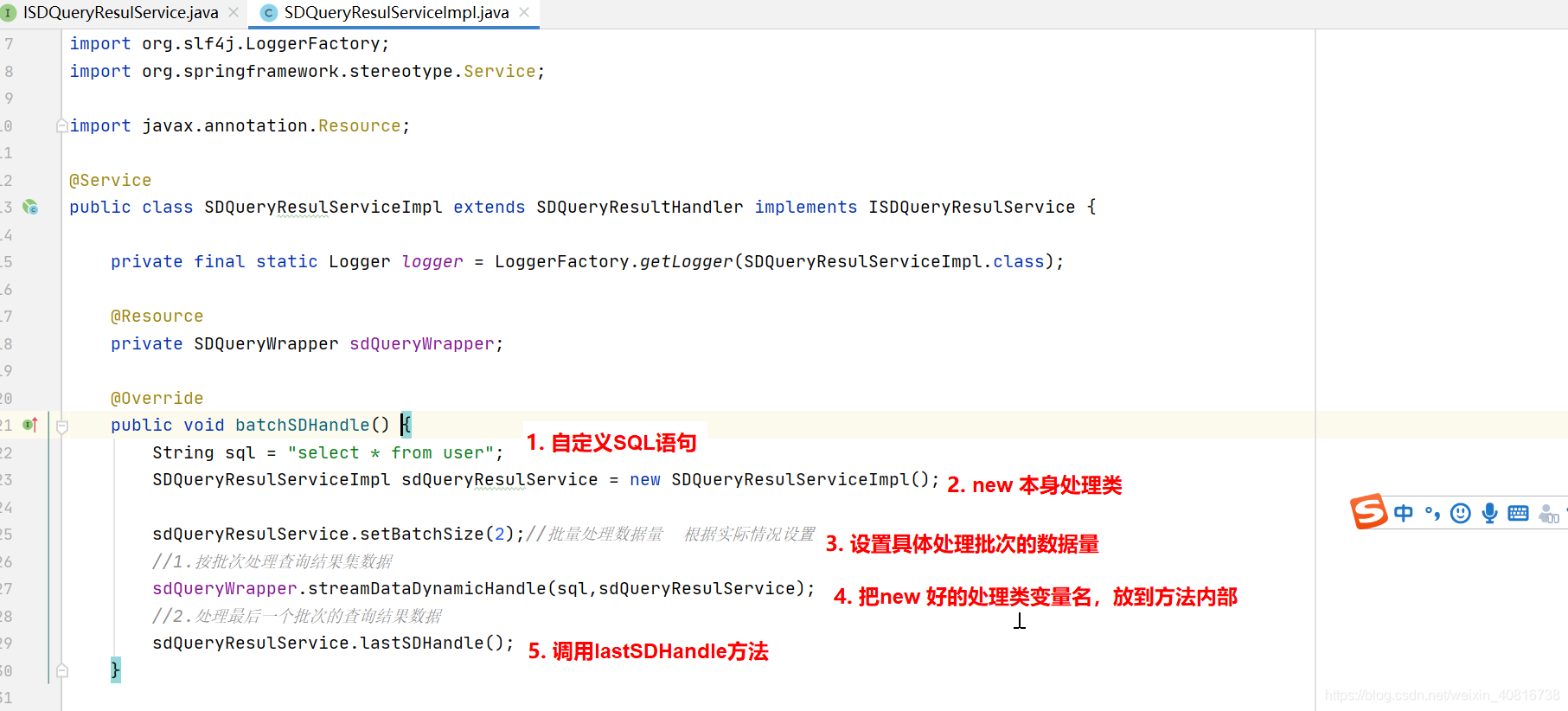
2.4. 具体逻辑处理案例
声明:查询批次的结果集最终返回的数据是一个list
三、企业案例
参数获取方式:根据key获取value,简言之,查询出来的数据放到了map中。
3.1. key名称获取
- 找到此类com.gblfy.ly.config. SDQueryResultHandler
- 在31行和32行打上断点
- debug启动项目
- url请求http://localhost/batchSDHandle
- 进项目,断点跳到32行
所有的key和value就都展示了出来
如下图所示:

3.2. 逻辑类测试
在com.gblfy.ly.service.impl. SDQueryResulServiceImpl类的35行打上断点,满足一个批次的数量就会跳到handle此方法中


注:数据库一共5条数据。
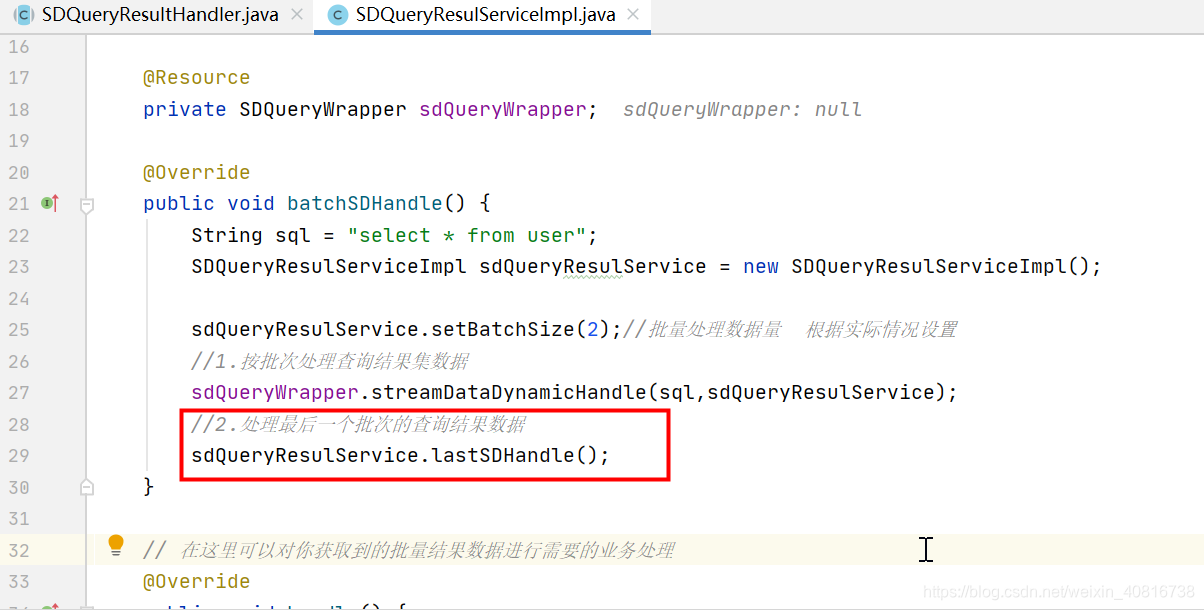
3.3.最后一个批次处理方案
从开始到结束,按照批次依次执行到最后一个批次,会自动调用lastSDHandle方法,因此,我们只需要处理好handle()方法即可。
最后,把获取的数据进行处理根据实际需求自行处理。
四、 通用SQL预编译处理
4.1. 业务场景
相同SQL和数据库交互多次,请按照规范适应预编译处理。
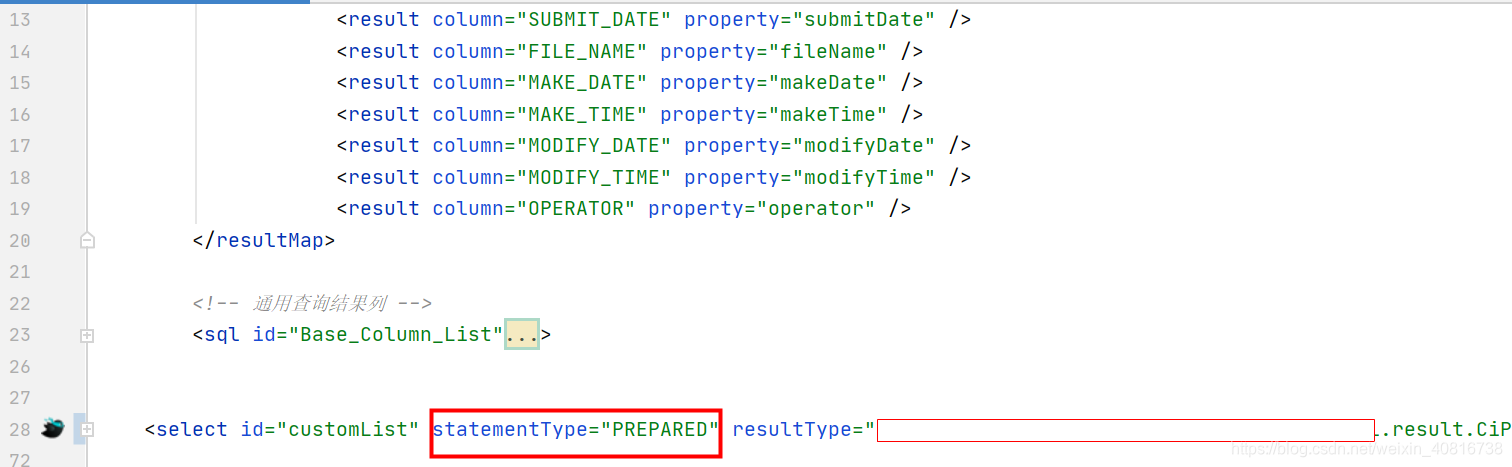
4.2. xml形式
在xml文件中添加statementType="PREPARED"即属性可
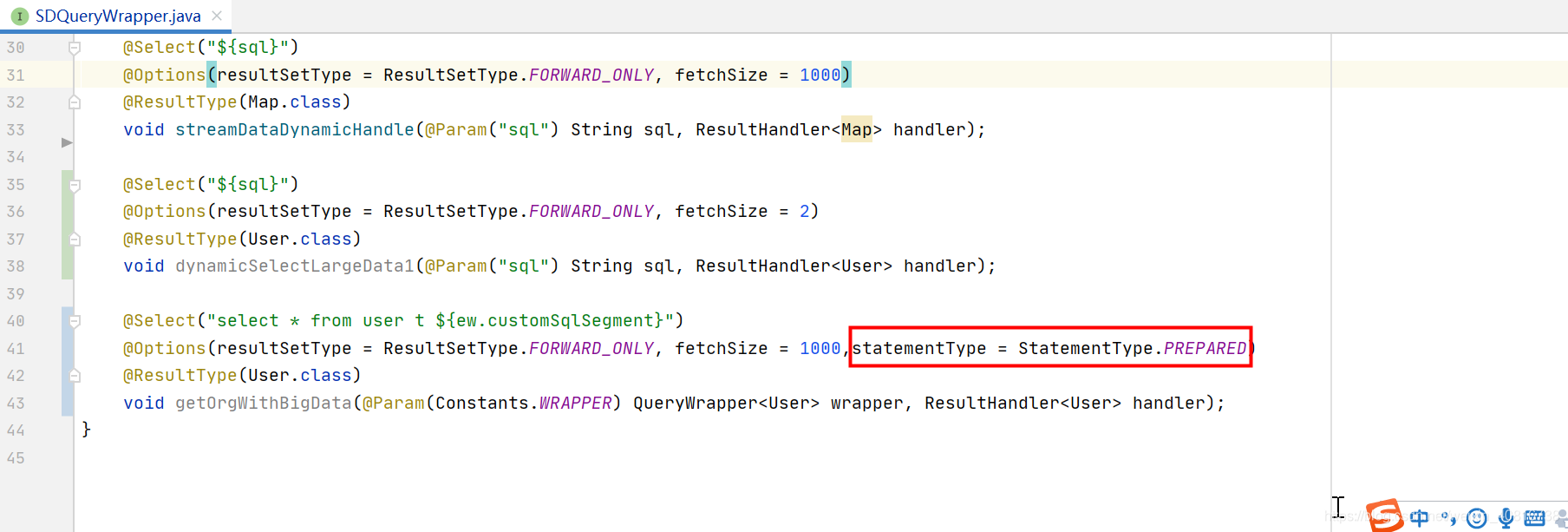
4.3. 注解形式
statementType = StatementType.PREPARED
五、企业案例
5.1. sql语句
-- ----------------------------
-- Table structure for user
-- ----------------------------
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (`id` bigint(20) NOT NULL COMMENT '主键ID',`name` varchar(30) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '姓名',`age` int(11) DEFAULT NULL COMMENT '年龄',`email` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '邮箱',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;-- ----------------------------
-- Records of user
-- ----------------------------
INSERT INTO `user` VALUES ('1', 'Jone', '18', 'test1@baomidou.com');
INSERT INTO `user` VALUES ('2', 'Jack', '20', 'test2@baomidou.com');
INSERT INTO `user` VALUES ('3', 'Tom', '28', 'test3@baomidou.com');
INSERT INTO `user` VALUES ('4', 'Sandy', '21', 'test4@baomidou.com');
INSERT INTO `user` VALUES ('5', 'Billie', '24', 'test5@baomidou.com');
5.2. 大数据流查询接口
package com.gblfy.ly.mapper;import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.core.toolkit.Constants;
import com.gblfy.ly.entity.User;
import org.apache.ibatis.annotations.*;
import org.apache.ibatis.mapping.ResultSetType;
import org.apache.ibatis.mapping.StatementType;
import org.apache.ibatis.session.ResultHandler;import java.util.Map;/*** 处理流数据的公用接口** @author gblfy* @date 2020-11-18*/
@Mapper
public interface SDQueryWrapper {/*** ResultSetType.FORWARD_ONLY 表示游标只向前滚动* fetchSize 每次查询數量* @ResultTyp 定义返回的对象类型** @param sql SQL語句* @param handler 返回处理数据对象*/@Select("${sql}")@Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 1000)@ResultType(Map.class)void streamDataDynamicHandle(@Param("sql") String sql, ResultHandler<Map> handler);@Select("${sql}")@Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 2)@ResultType(User.class)void dynamicSelectLargeData1(@Param("sql") String sql, ResultHandler<User> handler);@Select("select * from user t ${ew.customSqlSegment}")@Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 1000,statementType = StatementType.PREPARED)@ResultType(User.class)void getOrgWithBigData(@Param(Constants.WRAPPER) QueryWrapper<User> wrapper, ResultHandler<User> handler);
}
5.3. 大数据查询结果集处理抽象类
package com.gblfy.ly.config;import org.apache.ibatis.session.ResultContext;
import org.apache.ibatis.session.ResultHandler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.util.ArrayList;
import java.util.List;
import java.util.Map;/*** 大数据查询结果集处理抽象类** @author gblfy* @date 2020-11-18*/
public abstract class SDQueryResultHandler implements ResultHandler<Map> {private final static Logger logger = LoggerFactory.getLogger(SDQueryResultHandler.class);// 这是每一个批处理查询的数量public int batchSize = 1000;//初始值public int size=0;// 存储每批数据的临时容器public List<Map> list = new ArrayList<Map>();public void handleResult(ResultContext<? extends Map> resultContext) {// 这里获取流式查询每次返回的单条结果Map map = resultContext.getResultObject();list.add(map);size++;if (size == batchSize) {logger.info("本批次处理数据量 :{}",size );handle();}}// 1.这个方需要子类重写此接口,处理具体业务逻辑public abstract void handle();//处理最后一批不到 batchSize(查询设定的阀值)的数据public void lastSDHandle() {logger.info("最后批次处理数据量 :{}",size );handle();}public void setBatchSize(int batchSize) {this.batchSize = batchSize;}
}
5.4. 服务接口
package com.gblfy.ly.service;public interface ISDQueryResulService {public void batchSDHandle();
}
5.5. 服务接口实现类
package com.gblfy.ly.service.impl;import com.gblfy.ly.config.SDQueryResultHandler;
import com.gblfy.ly.mapper.SDQueryWrapper;
import com.gblfy.ly.service.ISDQueryResulService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Service;import javax.annotation.Resource;@Service
public class SDQueryResulServiceImpl extends SDQueryResultHandler implements ISDQueryResulService {private final static Logger logger = LoggerFactory.getLogger(SDQueryResulServiceImpl.class);@Resourceprivate SDQueryWrapper sdQueryWrapper;@Overridepublic void batchSDHandle() {String sql = "select * from user";SDQueryResulServiceImpl sdQueryResulService = new SDQueryResulServiceImpl();sdQueryResulService.setBatchSize(2);//批量处理数据量 根据实际情况设置//1.按批次处理查询结果集数据sdQueryWrapper.streamDataDynamicHandle(sql,sdQueryResulService);//2.处理最后一个批次的查询结果数据sdQueryResulService.lastSDHandle();}// 在这里可以对你获取到的批量结果数据进行需要的业务处理@Overridepublic void handle() {try {logger.info("---------------------:{}",list.size());//list 批量查询结果集,对此list进行业务处理for (int i = 0; i < list.size(); i++) {logger.info("---------------------:{}",list.get(i).get("name"));}} finally {// 处理完每批数据后后将临时清空size = 0;list.clear();}}
}
5.6. 前端控制器
package com.gblfy.ly.controller;import com.gblfy.ly.service.ISDQueryResulService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
public class SDQueryResultController {@Autowiredprivate ISDQueryResulService isdQueryResulService;@GetMapping("/batchSDHandle")public void batchSDHandle() {isdQueryResulService.batchSDHandle();}
}





)




作为触发器来触发函数计算)

)



| 博文精选)


